本文主要是介绍29 哈希,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
- unordered系列关联式容器
- 底层结构
- 模拟实现
1. unordered系列关联式容器
在c++98中,STL提供了底层为红黑树结构的一系列关联式容器,在查询时效率可达到 l o g 2 N log_2N log2N,即最差情况下需要比较红黑树的高度次,当树中的结点非常多时,查询效率也不理想。最好的查询是,进行很少的比较次数就能将元素找到,因此在c++11中,stl又提供了4个unordered系列的关联式容器,这四个容器与红黑树结构的关联式容器使用方式基本类似,只是底层机构不同
1.1 unordered_map
1.1.1 文档介绍
unordered_map在线文档说明
1.unordered_map是存储<key, value>键值对的关联式容器,其允许通过key快速的索引到与其对应的value
2.键值对通常用于唯一的标识元素,而映射值是一个对象,其内容与此键关联。键和映射值的类型可能不同
3.在内部,没有对<key, value>按照任何特定的顺序排序,为了能在常数范围内找到key对应的value,将相同哈希值的键值对放在对应的桶中
4.通过key访问单个元素比map快,但它通常在遍历元素子集的范围迭代方面效率较低
5.实现了直接访问操作符[],允许使用key作为参数直接访问value
6.它的迭代器至少是前向迭代器
1.1.2 unordered_map的接口说明
1.unordered_map的构造
| 函数声明 | 功能介绍 |
|---|---|
| unordered_map | 构造不同格式的对象 |
2.容量
| 函数声明 | 功能介绍 |
|---|---|
| bool empty() const | 检测是否为空 |
| size_t size() const | 获取有效元素个数 |
3.迭代器
| 函数声明 | 功能介绍 |
|---|---|
| begin | 返回第一个元素的迭代器 |
| end | 返回最后一个元素下一个位置的迭代器 |
| cbegin | 返回第一个元素的const迭代器 |
| cend | 返回第一个元素的迭代器 |
4.元素访问
| 函数声明 | 功能介绍 |
|---|---|
| operator[] | 返回与key对应的value,没有一个默认值 |
注意:该函数中实际调用哈希桶的插入操作,用参数key与V()构造一个默认值往底层哈希桶中插入,如果key不在哈希桶中,插入成功,返回V(),插入失败,说美国key已经在hash桶中,将key对应的value返回
5.查询
| 函数声明 | 功能介绍 |
|---|---|
| iterator find(const K& key) | 返回key在哈希桶中的位置 |
| size_t count(const K&key) | 返回哈希桶中关键码为key的键值对的个数 |
| 注意:key是不能重复的,因此count函数的返回值最大为1 |
6.修改操作
| 函数声明 | 功能介绍 |
|---|---|
| insert | 向容器中插入键值对 |
| erase | 删除容器中的键值对 |
| void clear() | 清空容器中有效元素个数 |
| void swap(unordered_map&) | 交换两个容器的元素 |
7.桶操作
| 函数声明 | 功能介绍 |
|---|---|
| size_t bucket _count() const | 返回哈希桶中桶的总个数 |
| size_t bucket_size(size_t n) const | 返回n号桶中有效元素的总个数 |
| size_t bucket(const K& key) | 返回元素key所在的桶号 |
1.2 unordered_set
unordered_set在线文档说明
2. 底层结构
unordered系列的关联式容器之所以效率高,是因为底层用了哈希结构
2.1 哈希概念
顺序结构以及平衡树中,元素关键码与其存储位置之间美欧对应的关系,因此在查找一个元素时,必须要经过多次关键码的比较,顺序查找时间复杂度为O(N),平衡树中为树的高度,即O( l o g 2 N log_2N log2N),搜索的效率取决于搜索过程中的元素比较次数
理想的搜索方法:不经过任何比较,一次直接从表中得到需想要搜索的元素
如果够一种存储结构,通过某种函数(hashFunc)使元素的存储位置与它的关键码之间建立一一映射关系,那么在查找时通过该函数可以很快找到该元素
当向结构中:
- 插入元素
根据待插入元素的关键码,以此函数计算出该元素的存储位置并按此为止存放
- 搜索元素
对元素的关键码进行同样的计算,把求得的函数值当做元素的存储位置,在结构中按此为止取元素比较,若关键码相等,则搜索成功
该方式为哈希(散列)方法,哈希方法中使用的转换换函数称为哈希(散列)函数,构造出来的结构称为哈希表(Hash Table)(或者散列表)
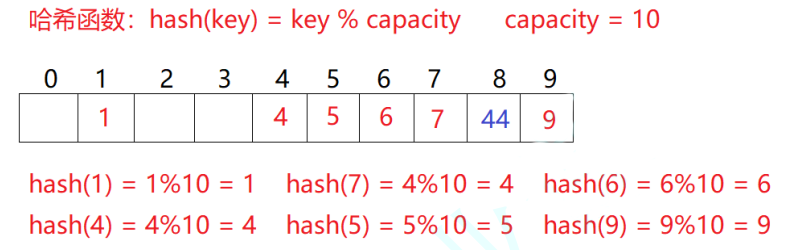
例如:数据集合{1, 7, 6, 4, 5, 9}
哈希函数设置为:hash(key)=key%capcity,capacity为存储元素底层空间的总大小
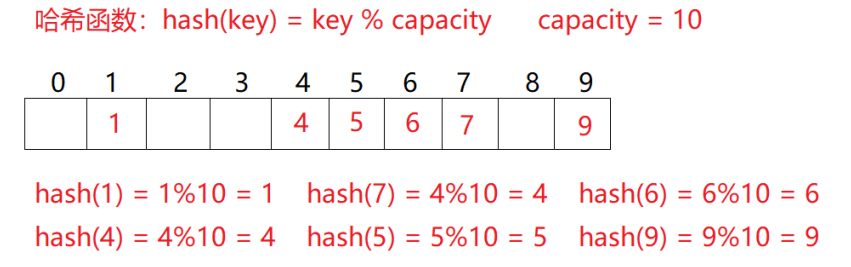
用该方法进行搜索不必进行多次关键码的比较,因此搜索速度比较快
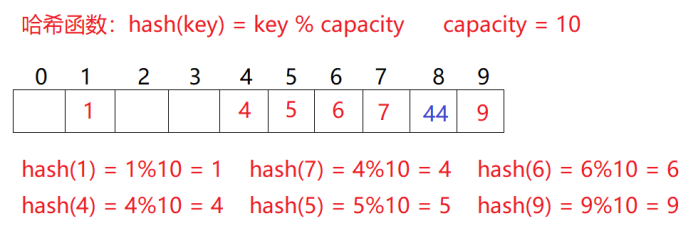
问题:按照上述方式向集合中插入44,会出现什么问题
哈希/散列:映射,关键字和另一个值建立关联关系
哈希表/散列表:映射,关键码和存储位置建立一个关联关系
2.2 哈希冲突
对于两个数据元素的关键字字 k i k_i ki和 k j k_j kj(i != j),有 k i k_i ki != k j k_j kj,但有:Hash( k i k_i ki) == Hash( k j k_j kj),即:不同关键字通过相同哈希计算出相同的哈希地址,该种现象称为哈希冲突或哈希碰撞
把具有不同眼见吗而具有相同哈希地址的数据元素称为"同义词"
发生哈希冲突如何处理呢?
2.3 哈希函数
引起哈希冲突的一个原因是:哈希函数设计不够合理
哈希函数设计原则:
- 哈希函数的定义域必须包含需要存储的全部关键码,而如果散列表允许有m个地址时,其值域必须在0到m-1之间
- 哈希函数计算出来的地址能均匀分布在整个空间中
- 哈希函数应该比较简单
常见哈希函数
1.直接定址法(常用)
去关键字的某个线性函数为散列地址:Hash(Key)= A*Key + B
优点:简单、均匀
缺点:需要事先知道关键字的分布情况
使用场景:适合查找比较小且连续的情况
2.处留余数法(常用)
设散列表中允许的地址整数为m,取一个不大于m,但最接近或等于m的质数作为除数,按照哈希函数:Hash(Key)= Key % p(p<=m),将关键码转换成哈希地址
3.平方取中法(了解)
假设关键字为1234,对它平方就是1522756,抽取中间的3位227作为哈希地址;
再比如关键字为4321,平方是18671041,抽取中间3位就是671(或710)作为哈希地址
适合:不知道关键字的分布,而位数又不是很大的情况
4.折叠法(了解)
将关键字从左到右分割成位数相等的几部分(最后一部分位数可以短些),然后将这几部分叠加求和,并按散列表表长,取后几位作为散列地址
折叠法适合事先不知道关键字的分布,适合位数较多的情况
5.随机数法
选择一个随机函数,取关键字的随机函数作为它的哈希地址,即H(key)=random(key),其中,random为随机函数
应用于关键字长度不等时
6.数学分析法(了解)
设有n个d位数,每一位可能有r种不同的符号,这r种不同的符号在各位上出现的频率不一定相同,可能在某些位上分布俊宇,每种符号出现的机会均等,在某位上分布不均与的某几种符号经常出现,可根据散列表的大小,选择其中各种符号分布均匀的若干位作为散列地址,例如:
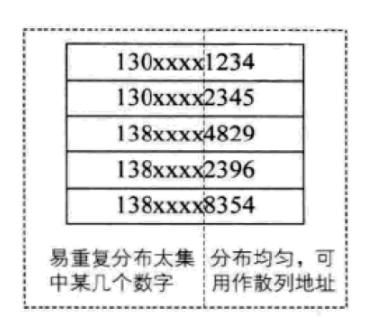
例如要存储某家公司员工登记表,如果手机号作为关键字,那么极有可能前7位都是相同的,那么可以选择后面的4位座位散列地址,如果这样的抽取工作还容易出现冲突,可以对抽取出来的数字翻转(1234改为4321),右环位移(1234改为4123),左环卫移,前两数与后两数叠加(1234改为12+34=46)等方法
数字分析法适合处理关键字位数比较大的情况,如果事先知道关键字的分布且关键字的若干位分布均匀的情况
注意:哈希函数设计的越精妙,产生哈希冲突的可能性就越低,但是无法避免哈希冲突
2.4 哈希冲突解决
结局哈希冲突两种常见的方法:闭散列和开散列
2.4.1 闭散列
开放定制法,当发生哈希冲突时,如果哈希表未被装满,说明哈希表中必然还有空位置,可以把key存到冲突位置的下一个空位置去
1.线性探测
2.1的场景,现在需要插入44,通过哈希函数计算哈希地址,hashaddr是4,44理论上应该插在4,但是已经有了4,发生哈希冲突
从冲突的位置,依次向后探测,直到寻找到下一个空位置为止
- 插入
通过哈希函数获取待插入元素在哈希表中的位置
如果该位置没有原则直接插入,如果有就探测找到下一个空位置插入
- 删除
采用闭散列处理哈希冲突时,不能随便删除哈希表中已有的元素,若直接删除元素会影响到其他元素搜索,比如删除4,44找起来可能会受到影响,因此采用标记的伪删除法删除一个元素
2.4.2 负载因子
载荷因子定义为:α = 填入表中的元素个数/散列表的长度
衡量散列表(如哈希表)填充程度的参数。它表示在散列表中,当插入一个新的键值对时,可以允许的最大填充程度。负载因子越大,散列表的填充程度越高,查找和插入操作的性能可能会受到影响。相反,产生冲突可能性越小,负载因子越小,散列表的填充程度越低,插入和查找操作的性能可能会更好,但空间利用率会降低
哈希表本质是一个数组,负载因子控制填充到多少扩大容量,如果太小,空间得不到利用。如果太大,插入和删除的效率会降低
对于开放定制法,载荷因子特别重要,应严格限制在0.7-0.8以下,超过0.8,查表时CPU缓存不命中(cache missing)按照指数曲线上升。y8inci一些采用开放定制法的hash库,如jiava的系统库限制载荷因子为0.75,超过此值resize散列表
3. 实现
3.1 线性探测实现
1.枚举一个元素状态,存在、删除和空

2.节点结构,数据类型为kv,上面的枚举类型

3.哈希的转换用模板函数,整形key直接返回,字符串特化,用bkdr方法
//hash int
template <class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//字符串模板特化,string
template <>
struct HashFunc<std::string>
{size_t operator()(const std::string& key){//BKDR方法size_t hash = 0;for (auto ch : key){hash = hash * 31 + ch;}return hash;}
};
4.类成员
一个哈希表,一个n记录存储的元素个数

5.查找
传入key,先计算下标,从下标位置寻找,直到下一个空说明没有该数据。防止下标越界需要取模
node* find(const K& key)
{Hash hf;//线性探测,字符串需要转整数size_t hashi = hf(key) % _table.size();while (_table[hashi]._sta != EMPTY){//删除状态不能判断为找到if (_table[hashi]._sta == EXIST && _table[hashi]._kv.first == key){return &_table[hashi];}hashi++;hashi %= _table.size();}return nullptr;
}
6.删除
伪删除法,找到元素,将状态改为删除
//伪删除法
bool erase(const K& key)
{node* del = find(key);if (del != nullptr){del->_sta = DELETE;_n--;return true;}return false;
}
7.插入
负载因子设置为0.7,因为整形除不出小数,所以扩大十倍。超出负载因子扩容到原来2倍,因为新表的映射关系也改变了,需要重新计算存储,遍历旧表调用新对象的插入,交换两个表。插入元素,线性探测法,先计算下标,如果该位置已有元素,不断往后探测,找到空位置插入
bool insert(const std::pair<K, V>& kv)
{if (find(kv.first)){return false;}//负载因子,整数不会出小数,扩大十倍if (_n * 10 / _table.size() == 7){//扩容size_t newsize = _table.size() * 2;HashTable<K, V, Hash> newhash;newhash._table.resize(newsize);for (int i = 0; i < _table.size(); i++){if (_table[i]._sta == EXIST)newhash.insert(_table[i]._kv);}//交换数组_table.swap(newhash._table);}//线性探测Hash hf;size_t hashi = hf(kv.first) % _table.size();while (_table[hashi]._sta == EXIST){hashi++;hashi %= _table.size();}_table[hashi]._kv = kv;_table[hashi]._sta = EXIST;_n++;return true;
}
全
#pragma once
#include <vector>
#include <iostream>enum State
{EMPTY,EXIST,DELETE
};template <class K, class V>
struct HashNode
{std::pair<K, V> _kv;State _sta; //状态
};//hash int
template <class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//字符串模板特化,string
template <>
struct HashFunc<std::string>
{size_t operator()(const std::string& key){//BKDR方法size_t hash = 0;for (auto ch : key){hash = hash * 31 + ch;}return hash;}
};template <class K, class V, class Hash = HashFunc<K>>
class HashTable
{typedef HashNode<K, V> node;
public:HashTable(){_table.resize(10);}bool insert(const std::pair<K, V>& kv){if (find(kv.first)){return false;}//负载因子,整数不会出小数,扩大十倍if (_n * 10 / _table.size() == 7){//扩容size_t newsize = _table.size() * 2;HashTable<K, V, Hash> newhash;newhash._table.resize(newsize);for (int i = 0; i < _table.size(); i++){if (_table[i]._sta == EXIST)newhash.insert(_table[i]._kv);}//交换数组_table.swap(newhash._table);}//线性探测Hash hf;size_t hashi = hf(kv.first) % _table.size();while (_table[hashi]._sta == EXIST){hashi++;hashi %= _table.size();}_table[hashi]._kv = kv;_table[hashi]._sta = EXIST;_n++;return true;}node* find(const K& key){Hash hf;//线性探测,字符串需要转整数size_t hashi = hf(key) % _table.size();while (_table[hashi]._sta != EMPTY){//删除状态不能判断为找到if (_table[hashi]._sta == EXIST && _table[hashi]._kv.first == key){return &_table[hashi];}hashi++;hashi %= _table.size();}return nullptr;}//伪删除法bool erase(const K& key){node* del = find(key);if (del != nullptr){del->_sta = DELETE;_n--;return true;}return false;}void print(){for (size_t i = 0; i < _table.size(); i++){if (_table[i]._sta == EXIST){std::cout << "[" << i << "]->" << _table[i]._kv.first <<":" << _table[i]._kv.second << std::endl;}else if (_table[i]._sta == EMPTY){printf("[%d]->\n", i);}else{printf("[%d]->D\n", i);}}}private:std::vector<node> _table;size_t _n = 0; //个数
};
3.2 总结
线性探测优点:实现简单
缺点:一旦发生冲突,所有的冲突连在一起,容易产生数据堆积,不同关键码占据了可利用的空位置,使得寻找某关键码的位置需要许多次比较,导致搜索效率降低
3.3 二次探测
线性探测的缺点是产生冲突的数据堆积在一起,与其找下一个空位置有关,因为找空位置的方法是挨着往后逐个查找,二次探测为了避免这个问题,找下一个空位置的方法: H i H_i Hi = ( H 0 H_0 H0 + i 2 i^2 i2 )% m, 或者: H i H_i Hi = ( H 0 H_0 H0 - i 2 i^2 i2 )% m。其中:i = 1,2,3…, H 0 H_0 H0是通过散列函数对关键码key计算得到的位置,m是表的大小
下面的解决:
研究表明:当表的长度为质数切装在因子不超过0.5时,新的表项一定能够插入,而且任何一个位置都不会被探查两次,因此只要表中有一半的空位置,就不会存在表满的问题,在搜索时可以不考虑装满的情况,但在插入时必须确保表的装在因子不超过0.5,如果超出必须考虑增容
因此,比散列最大的缺陷是空间利用率低,也是哈希的缺陷
3.4 开散列
1.概念
有叫链地址法(开练法,拉链法),首先对关键码集合用散列函数计算散列地址,具有相同地址的关键码归于同一个子集合,每一个子集合称为一个桶,各个桶中的元素通过一个单链表连接起来,各链表的头节点存储在哈希表中
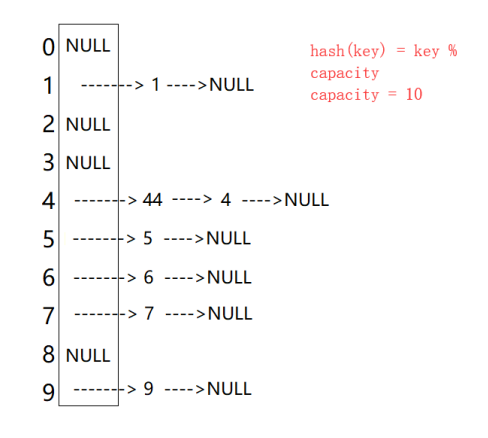
从上图可以看出,开散列每个桶中放的都是发生哈希冲突的元素
3.4.1 开散列实现
1.节点
kv的数据和下一个节点地址

哈希转换方法和上面一样
2.成员

3.查找
计算hash下标,不断遍历桶,直到空
4.删除
找到删除位置,上一个数据连接到删除数据的下一个
//删除
if (cur->_kv.first == key)
{if (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;
5.扩容
桶的个数是一定的,随着元素的不断插入,每个桶中的个数不断增多,极端情况下,可能导致一个桶中链表节点非常多,影响性能,因此在一定条件下需要对哈希表增容,那该条件怎么确认?开散列最好的情况是:每个哈希桶刚好挂一个节点,再继续插入元素时,每一次都会发生哈希冲突,因此,在元素个数刚好等于桶的个数时,增容
扩容后新表的映射变了,但没必要再次申请节点,只需要将旧表的结点挂到新表中,将旧表置空就好了
6.除留余数法
采用除留余数法最好模一个素数,如何每次快速取一个类似两倍关系的素数
size_t GetNextPrime(size_t prime){const int PRIMECOUNT = 28;static const size_t primeList[PRIMECOUNT] ={53ul, 97ul, 193ul, 389ul, 769ul,1543ul, 3079ul, 6151ul, 12289ul, 24593ul,49157ul, 98317ul, 196613ul, 393241ul, 786433ul,1572869ul, 3145739ul, 6291469ul, 12582917ul,
25165843ul,50331653ul, 100663319ul, 201326611ul, 402653189ul,
805306457ul,1610612741ul, 3221225473ul, 4294967291ul};size_t i = 0;for (; i < PRIMECOUNT; ++i){if (primeList[i] > prime)return primeList[i];}return primeList[i];}
字符串哈希算法
全
#pragma once
#include <string>
#include <iostream>
#include <vector>template <class K, class V>
struct HashNode
{std::pair<K, V> _kv;HashNode<K, V>* _next;HashNode(const std::pair<K, V> kv):_kv(kv), _next(nullptr){}
};//hash int
template <class K>
struct HashFunc
{size_t operator()(const K& key){return (size_t)key;}
};//字符串模板特化,string
template <>
struct HashFunc<std::string>
{size_t operator()(const std::string& key){//BKDR方法size_t hash = 0;for (auto ch : key){hash *= 31;hash += ch;}return hash;}
};template <class K, class V, class Hash = HashFunc<K>>
class HashBucket
{typedef HashNode<K, V> node;
public:HashBucket(){_table.resize(10);}bool insert(const std::pair<K, V>& kv){if (find(kv.first)){return false;}Hash hf;//负载因子,1if (_n == _table.size()){//扩容size_t newsize = _table.size() * 2;std::vector<node*> newtable;newtable.resize(newsize, nullptr);//遍历旧表for (size_t i = 0; i < _table.size(); i++){node* cur = _table[i];while (cur){node* next = cur->_next;//挪动到新表size_t hashi = hf(cur->_kv.first) % newtable.size();cur->_next = newtable[hashi];newtable[hashi] = cur;cur = next;}//旧表还指向节点,置空_table[i] = nullptr;}_table.swap(newtable);}//Hash hf;size_t hashi = hf(kv.first) % _table.size();node* newnode = new node(kv);//头插newnode->_next = _table[hashi];_table[hashi] = newnode;_n++;return true;}node* find(const K& key){Hash hf;//线性探测,字符串需要转整数size_t hashi = hf(key) % _table.size();node* cur = _table[hashi];while (cur){if (cur->_kv.first == key){return cur;}cur = cur->_next;}return nullptr;}bool erase(const K& key){Hash hf;size_t hashi = hf(key) % _table.size();node* prev = nullptr;node* cur = _table[hashi];while (cur){//删除if (cur->_kv.first == key){if (prev == nullptr){_table[hashi] = cur->_next;}else{prev->_next = cur->_next;}delete cur;return true;}prev = cur;cur = cur->_next;}return false;}void print(){for (size_t i = 0; i < _table.size(); i++){if (_table[i]){node* cur = _table[i];while (cur){std::cout << "[" << i << "]->" << cur->_kv.first <<":" << cur->_kv.second << " ";cur = cur->_next;}std::cout << std::endl;}else{printf("[%d]->\n", i);}}}~HashBucket(){for (size_t i = 0; i < _table.size(); i++){node* del = _table[i]; while (del){node* next = del->_next;delete del;del = next;}_table[i] = nullptr;}}//桶情况void some(){/*size_t bucketsize = 0;size_t maxbucketlen = 0;size_t sum = 0;double averagebucketlen = 0;for (size_t i = 0; i < _table.size(); i++){if (_table[i]){node* cur = _table[i];int len = 0;while (cur){cur = cur->_next;len++;}if (maxbucketlen < len){maxbucketlen = len;}sum += len;bucketsize++;}}averagebucketlen = (double)sum / (double)bucketsize;printf("哈希表大小:%d\n", _table.size());printf("桶大小:%d\n", bucketsize);printf("最大桶:%d\n", maxbucketlen);printf("平均桶:%lf\n", averagebucketlen);*/size_t bucketSize = 0;size_t maxBucketLen = 0;size_t sum = 0;double averageBucketLen = 0;for (size_t i = 0; i < _table.size(); i++){node* cur = _table[i];if (cur){++bucketSize;}size_t bucketLen = 0;while (cur){++bucketLen;cur = cur->_next;}sum += bucketLen;if (bucketLen > maxBucketLen){maxBucketLen = bucketLen;}}averageBucketLen = (double)sum / (double)bucketSize;printf("插入数据:%d\n", _n);printf("all bucketSize:%d\n", _table.size());printf("bucketSize:%d\n", bucketSize);printf("maxBucketLen:%d\n", maxBucketLen);printf("averageBucketLen:%lf\n\n", averageBucketLen);}public:std::vector<node*> _table;size_t _n = 0; //个数
};
3.5 开散列闭散列比较
应用连地址法处理溢出,需要增设连接指针,似乎增加了开销,事实上:由于开地址发必须保持大量的空闲空间以确保搜索效率,如二次探查发要求装在因子小于0.7,而表项所占空间又比指针大的多,所以使用链地址法反而比开地址法节省存储空间
这篇关于29 哈希的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!