本文主要是介绍Java中的浅拷贝和深拷贝有什么区别?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在Java中,浅拷贝和深拷贝是两种不同的对象拷贝方式,它们的主要区别在于是否复制对象的引用类型以及如何处理这些引用类型。
1:浅拷贝:
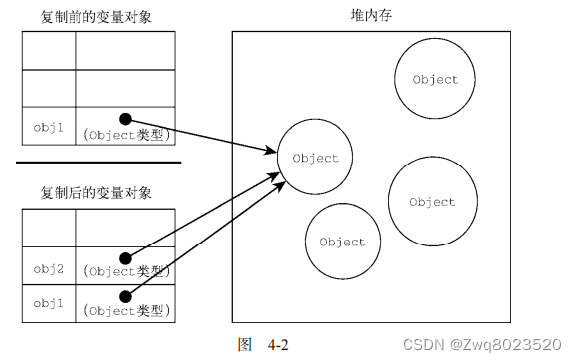
- 浅拷贝是指只复制对象本身(包括对象中的基本变量),而不复制对象包含的引用所指向的对象。这意味着被复制对象的所有变量都含有与原来的对象相同的值,而所有的对其他对象的引用仍然指向原来的对象。
- 浅拷贝通常是通过Object类的clone()方法来实现的,但默认情况下,clone()方法是浅拷贝。如果需要实现深拷贝,可以通过覆写clone()方法来实现域对象的深度遍历式拷贝。
2:深拷贝:
- 深拷贝是指不仅复制对象本身及其属性,还包括对象所引用的所有对象。这意味着新对象和原对象是完全独立的,即使源对象的值发生变化,拷贝对象的值也不会改变。
- 深拷贝通常需要重新分配内存,创建一个新的对象,并且将源对象中的所有元素以递归的方式拷贝到新对象中。实现深拷贝的方法包括使用构造函数、序列化反序列化、反射等。
总结来说,浅拷贝只是复制了对象的引用地址,而深拷贝则是复制了对象本身及其引用的对象,确保新对象与原对象完全独立。
Java中clone()方法的具体实现机制是什么?
在Java中,clone()方法的具体实现机制涉及以下几个关键步骤:
1:继承和接口:首先,对象的类必须实现java.lang.Cloneable 接口。这是因为在调用clone()方法时,系统会检查对象是否实现了该接口。
2:公共方法声明:为了能够调用clone()方法,类中的clone()方法必须是公开的(public)。这意味着任何其他类都可以调用这个方法来创建一个对象的副本。
3:调用超类的克隆方法:在派生类中覆盖clone()方法时,通常会调用super.clone ()来获取原始对象的一个引用。这样可以确保在复制过程中,所有基本数据类型的成员变量都被正确复制。
4:内存分配和复制:当调用clone()方法时,系统会为新对象分配与源对象同样大小的内存空间,并在这个空间中创建一个新的对象实例。然后,通过调用super.clone (),将源对象的内容复制到新对象中。
5:深克隆与浅克隆:根据需要,clone()方法可以实现浅克隆或深克隆。浅克隆仅复制对象的基本数据类型成员变量,而引用类型成员变量仍然指向同一个对象;深克隆则会复制所有引用类型成员变量中的对象,确保每个引用类型成员变量都拥有独立的对象副本。
总结来说,Java中的clone()方法通过实现Cloneable接口、声明公共的clone()方法、调用超类的克隆方法以及在内存中分配和复制对象内容来实现对象的复制。
如何在Java中实现深拷贝,并确保新对象与原对象的独立性?
在Java中实现深拷贝并确保新对象与原对象的独立性,可以通过以下几种方式:
通过对象的序列化和反序列化来实现深拷贝。具体步骤如下:
- 实现
Serializable接口。 - 在类中定义一个无参的构造函数。
- 重写
readObject方法,使用ObjectInputStream读取原对象的状态,并调用super.readObject ()恢复状态。 - 重写
writeObject方法,使用ObjectOutputStream将当前对象的状态保存到流中。
示例代码:
import java.io.Serializable ;public class Car implements Serializable {private static final long serialVersionUID = 1L;public Car() {}protected Car(ObjectInputStream in) throws IOException,ClassNotFoundException {in.readObject ();}public void writeObject(ObjectOutputStream out) throws IOException {out.writeObject (this);}}
这种方法可以确保对象及其内部所有嵌套对象的独立性。
通过重写clone()方法来实现深拷贝。具体步骤如下:
- 实现
Cloneable接口。 - 重写
clone()方法,在其中创建一个新的对象,并递归地复制对象及其引用的所有对象。
示例代码:
import java.lang.Cloneable ;public class Car implements Cloneable {private static final long serialVersionUID = 1L;@Overrideprotected Car clone() throws CloneNotSupportedException {return (Car) super.clone ();}}
这种方法也可以实现深拷贝,但需要手动处理引用类型的复制。
通过使用ObjectInputStream和ObjectOutputStream,可以实现不破坏类封装、无需了解被复制对象内部结构的深拷贝。具体步骤如下:
- 使用
ObjectInputStream读取原对象的状态。 - 使用
ObjectOutputStream将新对象的状态写入流中。
示例代码:
import java.io.FileInputStream ;import java.io.FileOutputStream ;import java.io.IOException ;import java.io.ObjectInputStream ;import java.io.ObjectOutputStream ;public class DeepCopyUsing streams {public static void main(String[] args) throws IOException, ClassNotFoundException {Car original = new Car();FileOutputStream fos = new FileOutputStream("car.ser ");ObjectOutputStream oos = new ObjectOutputStream(fos);oos.writeObject (original);oos.close ();FileInputStream fis = new FileInputStream("car.ser ");ObjectInputStream ois = new ObjectInputStream(fis);Car copy = (Car) ois.readObject ();ois.close ();fos.close ();System.out.println (copy.equals (original));}}
这种方法的优点是不破坏类的封装,代码复用性高。
Java中的序列化反序列化是如何工作的,以及它如何用于实现深拷贝?
在Java中,序列化和反序列化是将对象的状态转换为字节流的过程。具体来说,序列化是将对象转换为字节流的过程,以便可以将对象保存到磁盘上、传输到网络上或存储在内存中。Java通过实现java.io.Serializable 接口来实现对象的序列化,该接口没有任何方法,只是一个标记接口,用于标识类是否可以被序列化 。
反序列化则是将这些字节流重新转换为对象的过程。在进行反序列化时,JVM会比较传来的字节流中的serialVersionUID与本地相应实体类的serialVersionUID,如果相同则认为版本一致,可以进行反序列化;否则会出现序列化版本不一致的异常。
序列化和反序列化在实现深拷贝方面有重要应用。深拷贝是指复制一个对象及其所有嵌套对象的副本。通过序列化,可以将一个对象的状态保存为字节流,然后将这个字节流作为新对象的初始状态,从而实现深拷贝。例如,可以先将原始对象序列化为字节流,然后将这个字节流解码为一个新的对象实例,这样就得到了一个与原对象完全相同的副本。
在Java中,反射技术是如何被用来进行深拷贝的?
在Java中,反射技术可以通过以下步骤来实现对象的深拷贝:
1:获取目标类的信息:首先,通过反射机制获取目标类的所有属性和方法。这可以通过System.Reflection命名空间中的相关类来实现。
2:创建目标类的对象:利用反射机制创建一个目标类的新实例。这通常通过调用目标类的构造函数来完成,可以使用Constructor.newInstance ()方法。
3:复制属性值:接下来,遍历源对象的所有属性,并将这些属性的值复制到目标对象的相应属性中。这需要对源对象和目标对象进行双重循环,确保每个属性都被正确复制。
4:处理嵌套对象:如果源对象包含嵌套对象(如数组或复杂对象),则需要递归地对这些嵌套对象进行深拷贝。这意味着在复制嵌套对象时,也需要重复上述步骤。
通过上述步骤,反射技术能够有效地实现对象的深拷贝,确保不仅复制了表面属性,还复制了内部结构和嵌套对象的所有层次。
浅拷贝和深拷贝在性能上有何差异?
浅拷贝和深拷贝在性能上有显著差异。相比之下,深拷贝创建了一个全新的对象,包含与原始对象相同的值和结构,这会导致更多的计算和内存使用,从而使得深拷贝的性能较差。
在实际应用中,Python的深拷贝由于需要处理相互引用的情况,通常会牺牲大部分时间来确保少数情况下的正确性,导致整体性能下降。此外,不同的深拷贝方法在性能上也有所不同,例如使用Expression表达式树的方法性能大幅领先于反射方法。
浅拷贝在性能上优于深拷贝,特别是在处理大型对象时更为高效。
这篇关于Java中的浅拷贝和深拷贝有什么区别?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!