本文主要是介绍Git 中 pull 操作和 rebase 操作的不同,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
由于在开发过程中,pull 操作和 rebase 操作都是用来合并分支的,所以我就常常分不清这两个操作具体有什么区别,所以才有了这篇博客来做个简单区分,具体细致差别还请移步到官方文档:Git - Reference (git-scm.com)
1)pull 操作明确来说,实际是分为了两步操作:fetch + merge
fetch:进行 pull 操作的时候,git 首先会将远程仓库中的所有远程分支的最新一次提交内容拉取到本地仓库中对于远程仓库的跟踪分支中,相当于进行一次更新。但是这次更新并不会进行远程分支和本地分支的合并。
本地仓库中对于远程仓库的跟踪分支,简称为远程跟踪分支。远程跟踪分支是远程分支的本地副本,它们以 远程仓库(一般都为 origin ) / 远程分支名 的形式存在。fetch 会更新这些远程跟踪分支,使其与远程仓库中的分支同步。
merge:紧接着,会将当前的工作分支和已经建立了联系的对应的远程分支进行一次合并。又或者在 pull 操作的后续选项中指定了分支名,也会将指定的远程分支和当前本地的工作分支进行合并。
根据官方文档给出的示例,我们就能看出 pull 操作在 git 历史提交记录长什么样:
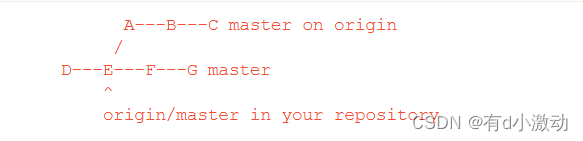
假设第二行中的 master 分支是我们当前本地的 master,提交历史为:D-E-F-G 。且本地的 master 分支最新一次与远程分支进行同步的节点为 E 。
第一行为远程仓库中的远程 master 分支,提交历史为:A-B-C
此时我们进行 pull 操作,就相当于将远程分支中的最新一次提交 C 同步到本地分支:

H 节点就为 pull 操作的第二步 merge 操作所产生的一次提交。可以看到,进行 pull 操作,由于默认第二步操作是使用了 merge 操作,因此会保留完整的提交记录。
2)rebase 操作称为变基操作,之所以叫做变基,是因为该操作改变了" 基础 ",实际作用就是改变提交的原本(" 基 ")位置。
还是借助官方文档给出的例子来进行解释:

假设新增本地有两个分支,master 和 topic ,现在在 topic 分支上进行 rebase master 的操作
此时 git 相当于会将 topic 分支的所有提交记录进行摘除,然后安接到 master 分支的最新一次分支,就相当于原本是基于 master 分支 E 节点所进行修改的 topic 上的所有记录,现在变成了基于 master 分支上的最新一次提交进行的修改似的:

可以看到,rebase 操作会将提交历史变得更加简洁整齐,呈线性的提交记录,不会出现明显的合并痕迹。
因此,其实 pull 操作和 rebase 之间并没有直接关联,真正关联的是 merge 操作和 rebase 操作。
二者所呈现的提交历史是不同的,具体需要哪个操作就需要看实际场景:
如果需要保持整齐的提交历史,那么就选择 rebase 操作;
如果想要保留完整的提交历史,那么就选择 merge 操作。
在 pull 操作中,默认第二步是使用 merge 操作,但是我们也可以指定使用 rebase 操作来合并分支,通过设置 git config --global pull.rebase true 来配置 rebase 选项来实现。
这篇关于Git 中 pull 操作和 rebase 操作的不同的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



