本文主要是介绍正则表达式,linux文本三剑客,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
正则表达式匹配的是文本内容,linux的文本三剑客都是针对文本内容,按行进行匹配
文本三剑客:
grep 过滤文本内容
sed 针对文本内容进行增删改查
awd 按行取列
一.grep命令
作用就是使用正则表达式来匹配文本内容
-m +数字:匹配几次之后停止
![]()
-v :取反

-n :显示匹配的行号
![]()
-c :只统计匹配的行数
![]()
-o :仅显示匹配的结果

-q :静默模式,不输出任何信息
![]()
-A +数字 :显示包括匹配行的后几行

-B +数字 :显示包括匹配行的前几行

-C +数字 :显示包括匹配行的前后各几行

-e :或者

-E :匹配扩展正则表达式
-f :匹配两个文件相同的内容,以第一个文件为准

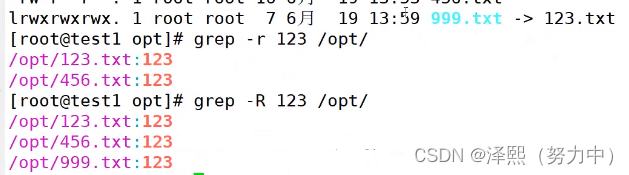
-r :递归目录,目录下的文件内容,软连接不包含在内
-R :递归目录,目录下的文件内容,包含软连接
sort
排序:
以行为单位,对文件的内容进行排序
sort 选项 参数
cat file | sort 选项
-f :忽略大小写,默认会把大写字母排在前面
-b :忽略每行之前的空格(不是把空格删除,只是依然按照数字和字母的顺序排列)
-n :按照数字进行排序
-r :反向排序
-u :表示相同的数据仅显示一行
-o :把排序后的结果转存到指定的文件
uniq
去除连续重复的行
-c :统计连续重复的行的次数,合并连续重复的行

-u :显示仅出现一次的行(包括不是连续出现的重复行)

-d :仅显示连续重复的行(不包括非连续出现的行)
![]()
tr
用来对标准输出字符进行替换,压缩和删除
tr 选项 参数
-c :保留字符集1的字符,其他字符用字符集2来进行替换
![]() 默认会多输出一次替换的字符集2
默认会多输出一次替换的字符集2
-d :删除字符集中一部分
![]()
-s :①把连续重复出现的字符压缩成一个,②把字符集1的部分替换成字符集2的部分
![]()
![]()
cut
快速裁剪,对字段进行截取和裁剪
-d :指定分割符(默认的分割符是tab键)
-f :对字段进行截取,指定输出段的内容
截取字段1到3段:

截取字段1和3段:
![]()
-complement :输出的时候排除指定的字段
截取除第二段外字段:
![]()
截取除第1到第6字段外字段
![]()
截取除第1和第3字段外字段
![]()
-output-delimiter :更改输出内容的分割符
将截取的1到5字段中分割符: 替换成@
![]()
-b :以字节为单位进行截取
-c :以字符为单位进行截取
文件的拆分:
split
大文件拆分成若干小的文件
-l :按行进行拆分
将文件test2.txt按每20行拆分,拆分后文件前缀名为xy102

-b :按照大小来进行拆分
将文件xshell7.rar已每份21M大小拆分,拆分后文件名前缀为xshell
![]()
面试题:现在有一个日志文件,5G,能不能快速的打开
答:拆分,两种方法 split -l按行拆分和 split -b按大小拆分
这种文件推荐使用按大小拆分,split -b
文件合并
paste
cat
面试题:cat合并和paste合并之间的区别
答:cat是上下合并,paste是左右合并
面试题:统计当前主机的连接状态
答:ss -antp | grep -v 'State' | cut -d ' ' -f 1 | sort | uniq -c
正则表达式:
由一类特殊字符以及文本字符所编写的一个模式,模式又来匹配文件当中内容(字符)
校验我们输入的内容是否满足规定,格式,长度等待要求
主要用来匹配文件内容,命令的结果
通配符:只能用于匹配文件名的目录名,不能匹配文件的内容和命令结果
正则表达式分为:
1.基本正则表达式
元字符(字符匹配)
. 任意单个字符,也可以是一个汉字
\ 转义符 恢复其本意
[] 匹配指定范围内的任意单个字符或数字
[^] 取反
^ 匹配开头
*匹配前面的字符任意次,0次也可以
.* 匹配前面的任意字符,至少要有一次
\? 匹配前面的字符0次或1次,可有可无
\ + 匹配前面的字符,至少要出现一次
\ {n\ } 匹配前面的字符=n次,可以小于n,但是不能大于n,而且前面的字符必须要是连续出现
\ (m,n\ )匹配前面的字符至少m次 ,最多n次,必须的连续出现,超出的不在匹配范围
\ {,n\ } 匹配前面的字符最多n次
\ {n,\ } 匹配前面的字符最少n次
位置锚顶:
^ :以什么开始,行尾锚定
$ :以什么为结尾,行尾锚定
\ <或\b 词首锚定,匹配单词的左侧(连续的数字,字母,下划线都算单词内部)
\ > 或\b 词尾锚定,用于匹配单词的右侧
\broot\b 匹配整个单词,空格隔开的也算整个单词
^root$ 整个一行只有这个单词
区别
分组和逻辑关系
分组 :()
或者 : \ |
扩展正则表达式
grep -E ,不用加\号,其他与正则表达式基本一样
二.sed命令
sed是一种流编器,一次处理一行内容,针对文本内容进行增删改查
如果只是展示,会放在缓冲区(模式空间),展示结束之后,会从模式空间把操作结果删除
一行一行处理,处理完当前行,才会处理下一行,直到文件末尾
sed的命令格式和操作选项:
-e :表示可以跟多个操作符,只有一个操作符 -e 可以省略
sed -e '操作符' -e '操作符' 文件1 文件2
sed -e '操作符1;操作符2;'文件1 文件2
选项
-e :用于执行多个操作命令
-f : 在脚本中定义好了操作符,然后根据脚本内容的操作符对文件进行操作
-i : 直接修改目标文件(慎用)
-n :仅显示script处理后的结果(不加 -n,sed会有两个输出结果,加了 -n后会把默认输出屏蔽,只显示一个结果)
操作符:
p :打印结果
r :使用扩展正则表达式
s :替换,替换字符串
c :替换,替换指定行
y :替换,替换单个字符;多个字符必须和替换内容的字符长度保持一致
d :删除,删除行
a :增加,在指定行的下一行插入内容
i :增加,在指定行的上一行插入内容
r :读取其他文件的内容,在行后增加文本内容
$a :在最后一行插入新的内容
$i :在倒数第二行插入新的内容
$r :读取其他文件的内容,插入到目标文件的最后一行
打印功能:
寻址打印,按照指定行打印
sed -n '$p' 文件名 :,打印最后行
sed -n '数字p' 文件名 :打印指定行
sed -n '数字p;数字p' 文件名 :打印指定的两行
sed -n '2,4p' :打印2-4行
sed -n 'p;n' :打印奇数行
sed -n 'n;p' :打印偶数行 ‘n’的作用,跳过一行,打印下一行
sed -n ‘/a/p’ : 过滤并打印包含a的行
使用正则表达式对文本内容进行过滤
sed -n '/^root/p' /etc/passwd :打印出以root开头的所有行
sed -n '42,/bash$/p' /etc/passwd :从指定42行打印到第一个以bash结尾的行
sed -rn '/(99:){2,}/p' /etc/passwd :
sed -rn '/^root|bash$/p' /etc/passwd :打印出要么以root开头要么以bash结尾的行
面试题
如何免交互删除文件:
答:两种方法
①cat /dev/null > test1.txt
②sed -i 'd' test1.txt
sed的删除操作
sed -n ‘3d;p’ 文件名 :删除第三行,打印剩余的行
sed -n '4d;6d;p' 文件名 :删除第四和第六行,打印剩余行
匹配字符串删除行
sed '/o/d' :删除所有包含o的行
ed '/222/,/444/d' :删除包含222到444中间的所有行
ed '/222/!d' :删除除了包含222的所有行
面试题:
如何用免交互方式删除空行
grep -v ‘^$’
cat test.txt | tr -s ‘\n’
sed ‘/^$/d’ test.txt
s替换字符串
sed -n 's/root/test/p' /etc/passwd :每行第一个root替换成test
sed -n ’s/root/test/2p‘ /etc/passwd :每行第二个root替换成test
sed -n ’s/root/test/gp‘ /etc/passwd:所有的root替换成test
sed -n '4,6s/^/#/p' test.txt :注释第4到6行
sed -n '4s/^/#/p;6s/^/#/p' test.txt :注释第4和第6行
sed 's/[a-z]/\u&/' test.txt:转换首字母小写为大写
sed 's/[a-z]/\u&/g' test.txt:所有的小写变为大写
u&:转换首字母为大写的特殊符号。
ed 's/[A-Z]/\l&/' test1.txt :转换首字母大写为小写
sed 's/[A-Z]/\l&/g' test1.txt :所有的大写变为小写
l& :转换首字母为小写的特殊符号。
整行替换
sed '/a/c shuai' test.txt :把a开头的行 替换成 shuai
y单字符替换
sed '/abc/123/' test.txt :将文件内字符abc分别替换成123,
位置替换
使用sed对字符串和字符的位置进行互换
echo wenzeshao | sed -r 's/(wen)(ze)(shao)/\3\1\2/'
对单个字符的位置进行互换
echo oahs | sed -r 's/(.)(.)(.)(.)/\4\3\2\1/'
sed主要作用是对文本的内容进行增删改查
最好用的是:改和增功能
这篇关于正则表达式,linux文本三剑客的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







