本文主要是介绍达梦8 通过SF_INJECT_HINT解决新排序机制下失控语句影响其他SQL执行的问题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
达梦数据库有两种排序机制。当SORT_FLAG设置0时,采用旧排序机制;当SORT_FLAG=1时,采用新排序机制。详见《达梦新老排序机制的对比》
两种排序机制各有优缺点。
新排序机制引入了全局排序区概念,虽然避免了内存溢出导致系统OOM,但却引入了另外一个问题:个别编写不好的语句可能会占满整个排序区,导致后续所有正常语句无法执行。
例如insert into a1 select a.a from a,b where a.a=b.a order by a.a;就是那条耗光全局排序区的语句。会话A中执行该语句。
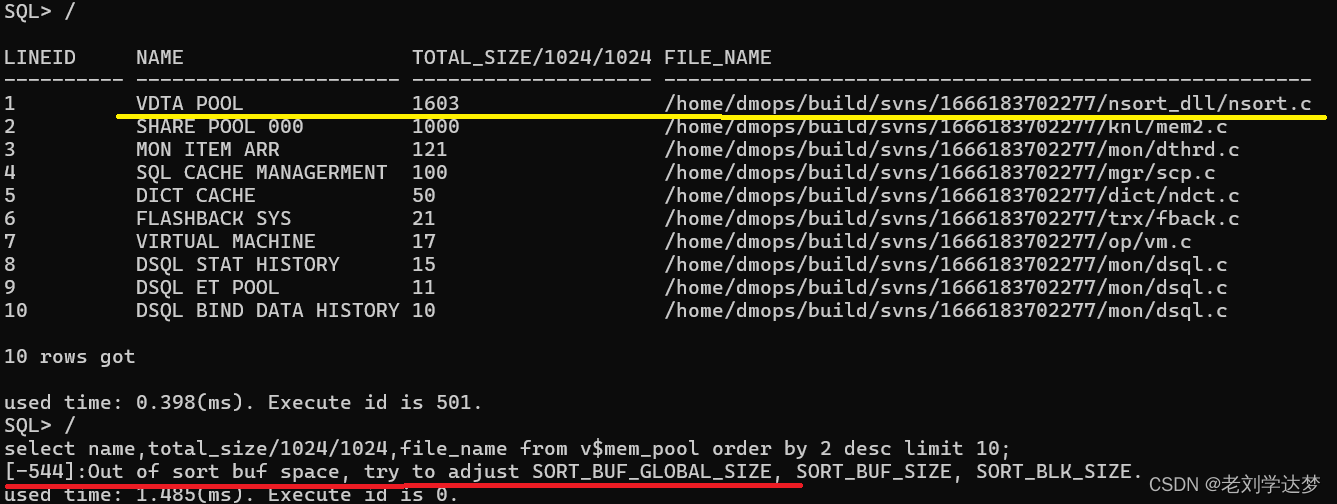
会话B中按照TOTAL_SIZE倒排序查看内存池的使用情况
如上可见,全局排序区(VDTA POOL)使用了1603M。再次查询就报了[-544]out of sort buf space错误。这是因为全局排序区随着系统中各会话SQL的运行,达到了参数SORT_BUF_GLOBAL_SIZE定义的上限,后续排序语句都将失败。
那么避免新排序机制的这种现象呢?
方法有一个:通过SF_INJECT_HINT强制“捣乱者”使用旧排序机制。
通过如下方法强制让它使用旧排序机制
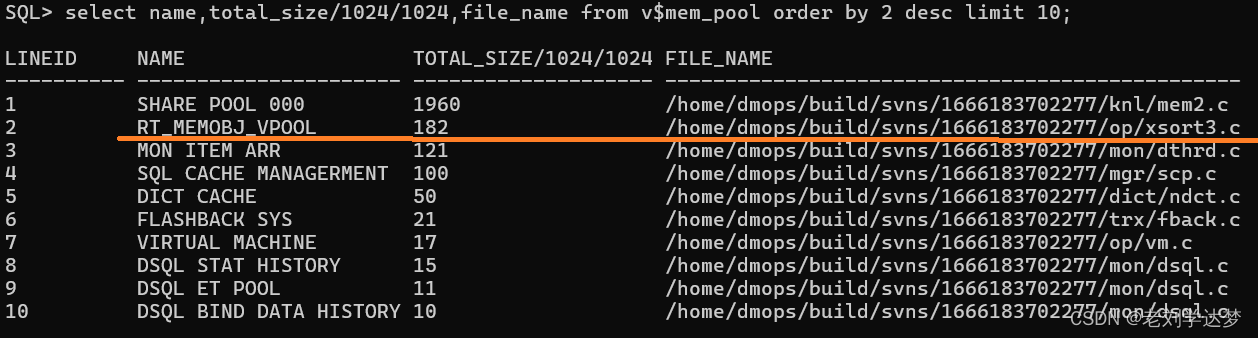
SF_INJECT_HINT('insert into a1 select a.a from a,b where a.a=b.a order by a.a;','SORT_FLAG(0)','HINT1','',TRUE,TRUE);以后上面那条编写不好的语句再不能耗光全局排序区了。现在它使用的本地排序区(RT_MEMOBJ_VPOOL)。SORT_BUF_SIZE参数定义本地排序区的上限,实测中上限是SORT_BUF_SIZE的2倍( --03134283938-20221019-172201-20018版本)。
SQL优化参见往期文章《达梦执行计划的选择与优化思路》
这篇关于达梦8 通过SF_INJECT_HINT解决新排序机制下失控语句影响其他SQL执行的问题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





