本文主要是介绍【pytorch05】索引与切片,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
索引
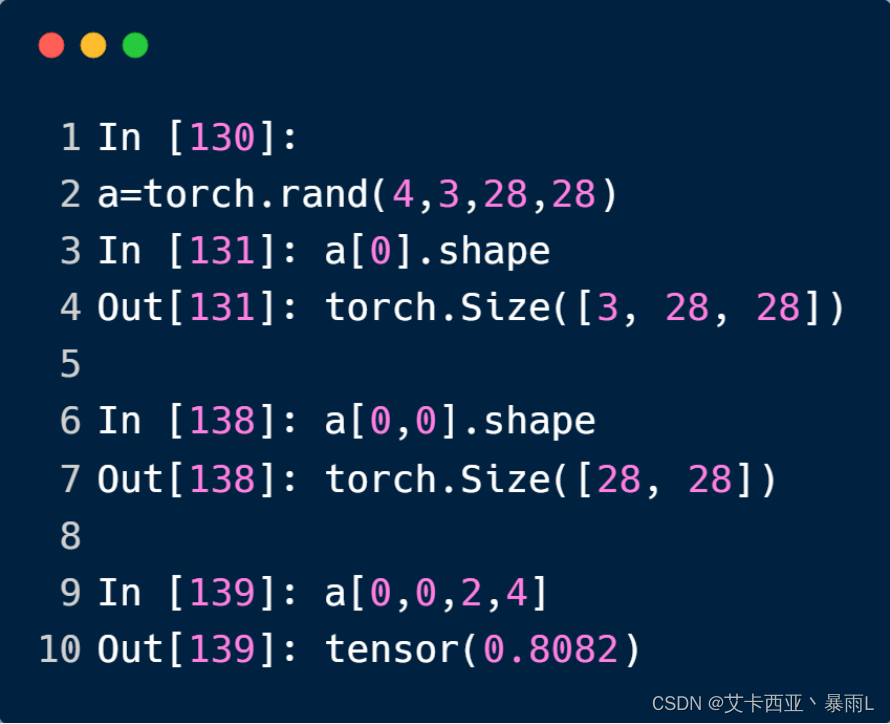
a[0,0]第0张图片的第0个通道
a[0,0,2,4]第0张图片,第0个通道,第2行,第4列的像素点,dimension为0的标量
选择前/后N张图片
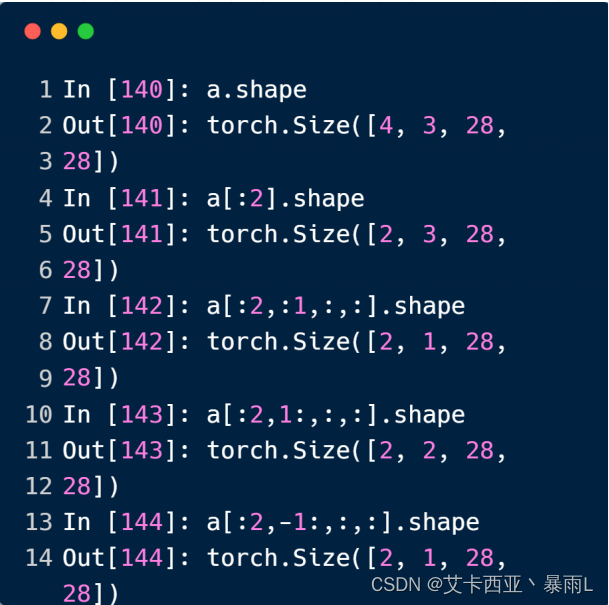
a[:2,:1,:,:].shape前两张图片,第1个通道上的所有图片的数据
a[:2,1:,:,:].shape前两张图片,取第一个通道开始,也就是G,B通道,通道的索引为[0,1,2],我们是从1开始到最末尾,所以取得是1通道和2通道即G和B
a[:2,-1:,:,:].shape前两张图片,从最后一个通道开始取到最后一个通道
选择步长
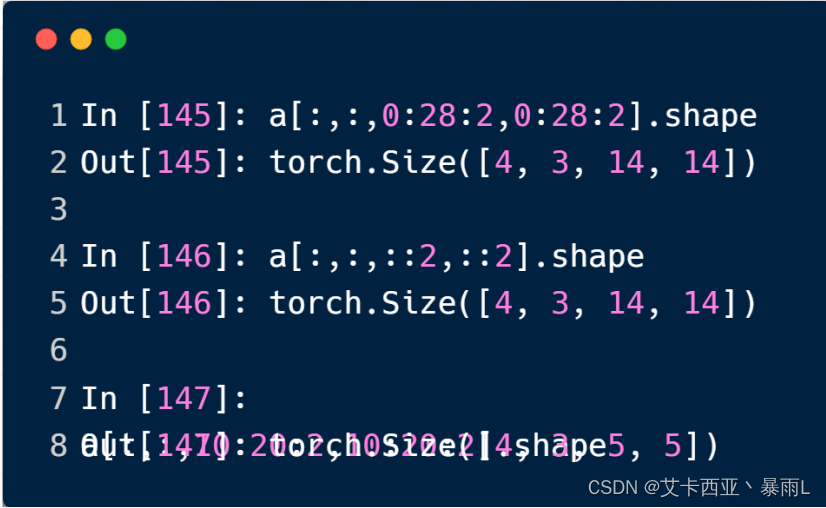
选择具体的索引
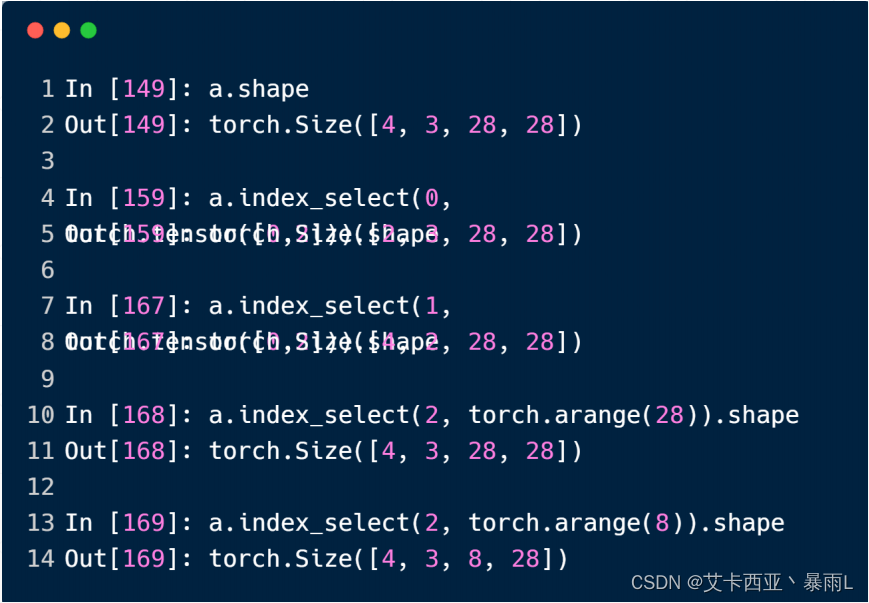
a.index_select(0,torch.tensor([0,2])).shape第一个参数为对哪一个维度进行操作,第二个参数给的是索引号不能直接以list的方式给,必须把list转化为tensor
a.index_select(1,torch.tensor([1,2])).shape
…任意多维度
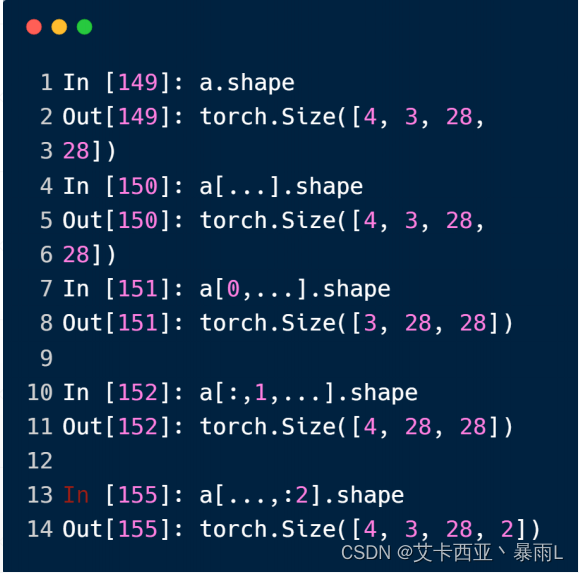
[B,C,H,W]
a[0,...,::2]根据推测3个点代表任意长,从0维度开始,::2表示最后一个维度,当有…出现时,右边的索引需要理解为最右边,因此…表示的是C维度和H维度,所以这里想要表示的是,第0个图片取所有的channel和height,列每隔一个单位取一个会变成[3,28,14]
…仅仅是为了方便
掩码索引
x.ge(0.5)大于等于0.5的元素的位置置为1,得到这样的一个掩码,虽然显示的是torch.uint8类型但实际是ByteTensor类型,然后根据掩码来取,把掩码为1的元素取出来,因此会得到3个大于等于0.5的元素,通过mask_select得到的tensor的shape跟原来的tensor是没有关系的,之所以打平是因为大于0.5的元素个数是根据内容确定的
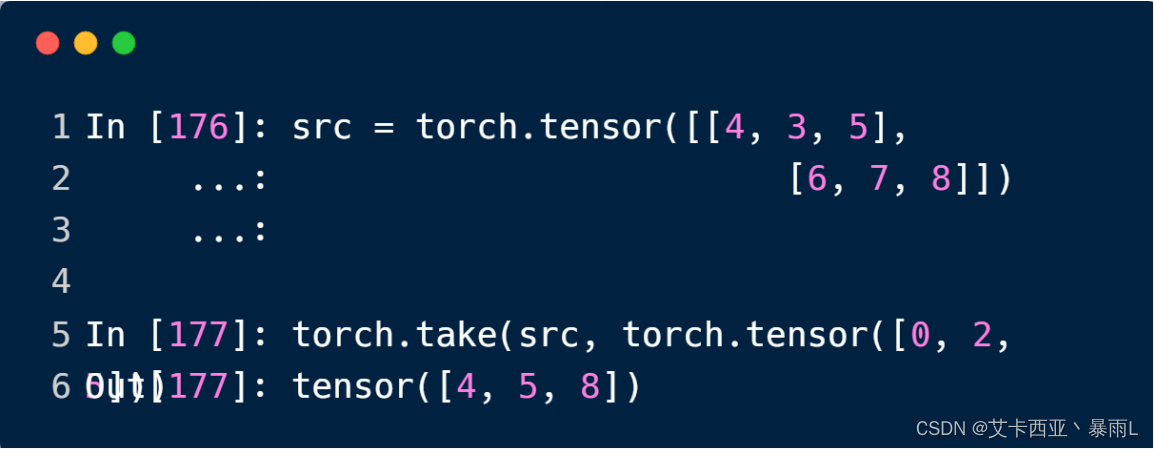
torch.take(src,torch.tensor([0,2,5]))先把tensor打平,比如把这里的[2,3]打平成[6]变成dimension为1,size为6的tensor,再去打平以后的编码
这篇关于【pytorch05】索引与切片的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




