本文主要是介绍linux使用docker部署kafka集群,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1、拉取kafka
docker pull wurstmeister/kafka
docker pull wurstmeister/zookeeper2、创建网络
docker network create app-kafka3、启动zookeeper
docker run -d \--name zookeeper \-p 2181:2181 \--network app-kafka \--restart always \wurstmeister/zookeeper 4、启动kafka
docker run -d \--name kafka1 \-p 9091:9092 \-e KAFKA_BROKER_ID=1 \-e KAFKA_ZOOKEEPER_CONNECT=192.168.58.131:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.58.131:9091 \-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \-v /etc/localtime:/etc/localtime \wurstmeister/kafkadocker run -d \--name kafka2 \-p 9092:9092 \-e KAFKA_BROKER_ID=2 \-e KAFKA_ZOOKEEPER_CONNECT=192.168.58.131:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.58.131:9092 \-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \-v /etc/localtime:/etc/localtime \wurstmeister/kafkadocker run -d \--name kafka3 \-p 9093:9092 \-e KAFKA_BROKER_ID=3 \-e KAFKA_ZOOKEEPER_CONNECT=192.168.58.131:2181 \-e KAFKA_ADVERTISED_LISTENERS=PLAINTEXT://192.168.58.131:9093 \-e KAFKA_LISTENERS=PLAINTEXT://0.0.0.0:9092 \-v /etc/localtime:/etc/localtime \wurstmeister/kafka5、使用图形界面
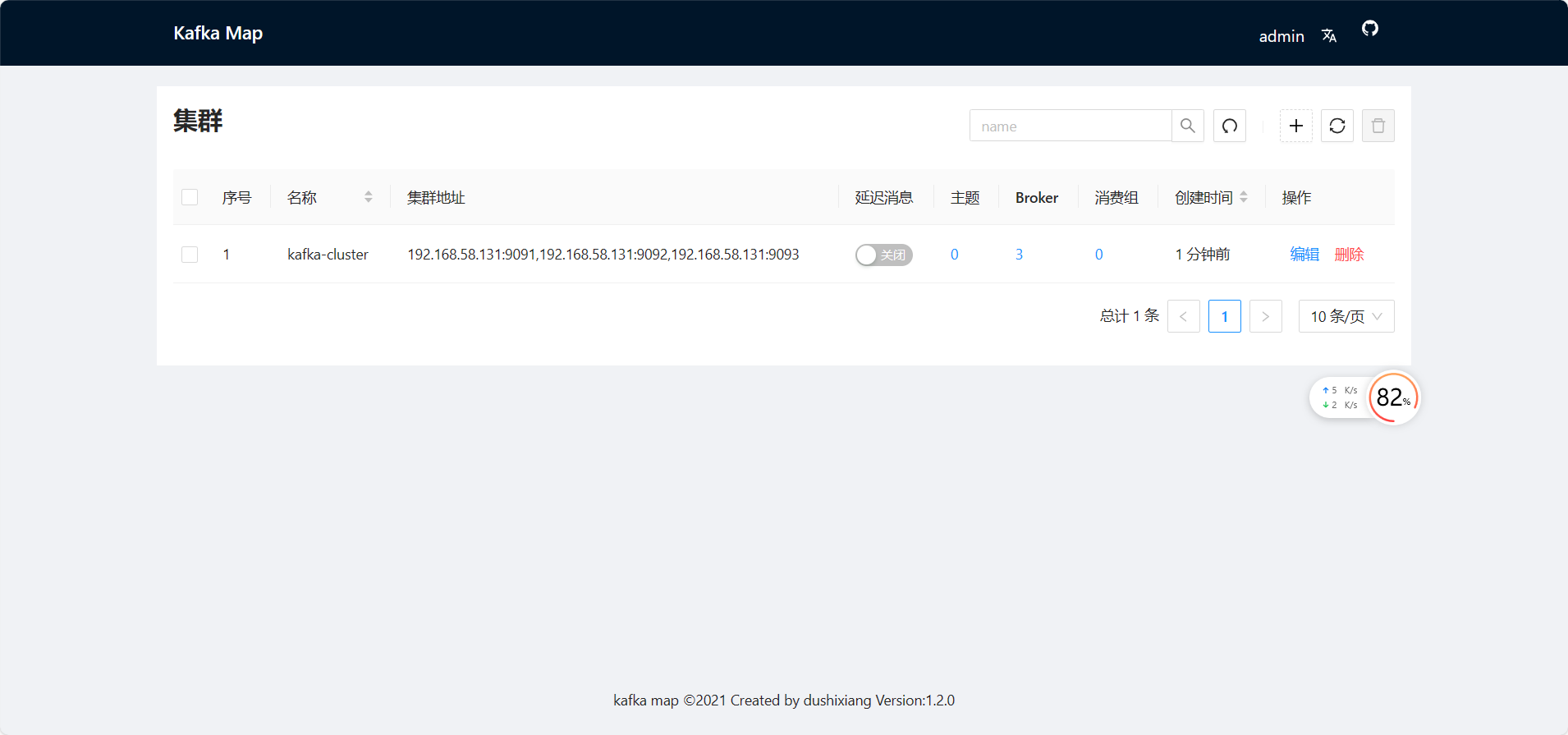
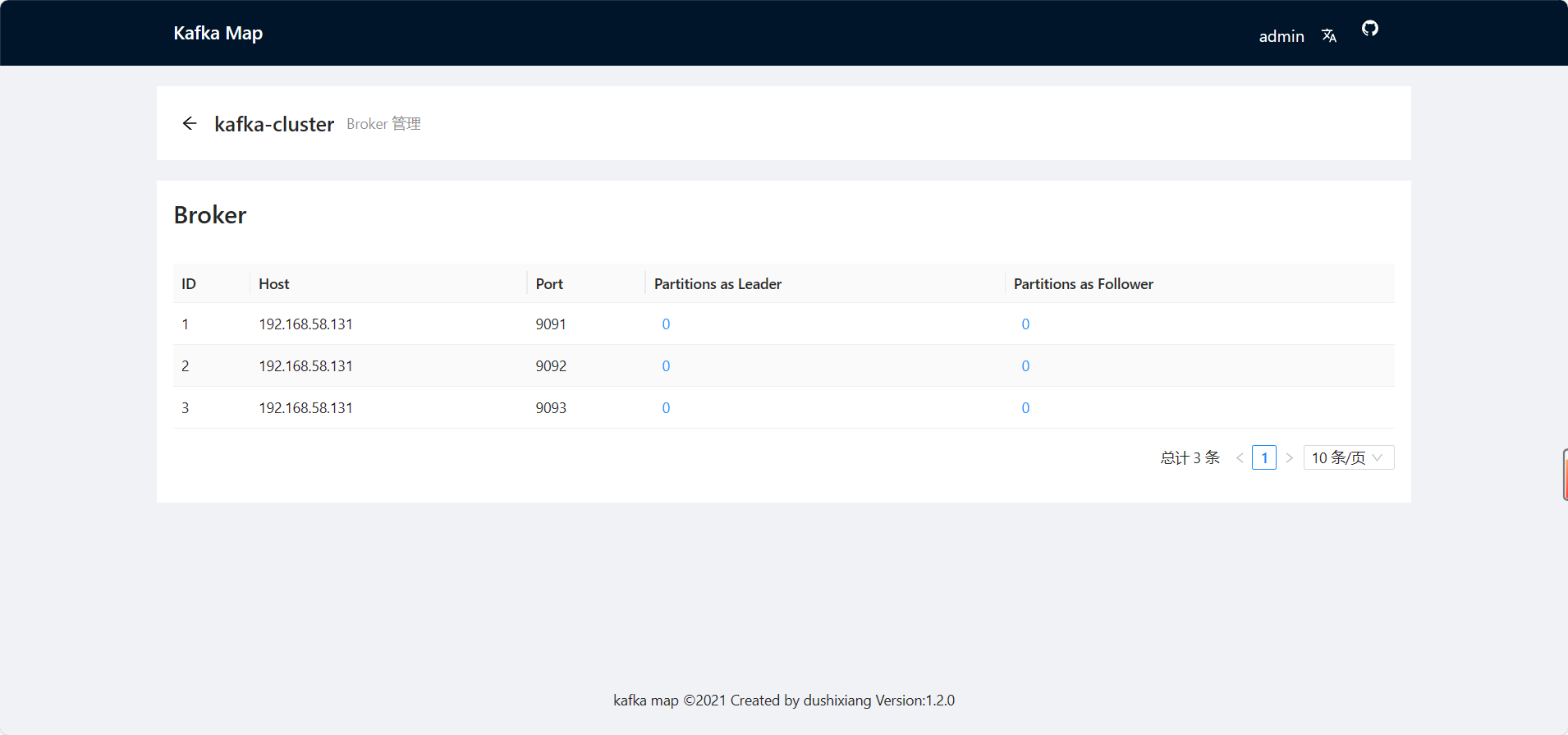
docker run -d --name kafka-map \--network app-kafka \-p 9101:8080 \-v /docker/kafka-map/data:/usr/local/kafka-map/data \-e DEFAULT_USERNAME=admin \-e DEFAULT_PASSWORD=admin \--restart always dushixiang/kafka-map:latest- 图形化管理工具
- 访问地址:http://服务器IP:9101/
- DEFAULT_USERNAME:默认账号 admin
- DEFAULT_PASSWORD:默认密码 admin
这篇关于linux使用docker部署kafka集群的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






