本文主要是介绍五十八周:文献阅读,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
摘要
Abstract
文献阅读:使用 Transformer 进行长期预测-PatchTST
一、现有问题
二、提出方法
三、相关知识
1、Patch
2、Vanilla Transformer
四、提出的方法
1、模型结构
2、表征学习
3、模型优点
五、研究实验
1、数据集
2、评估指标
3、基线模型
4、实验过程
5、实验结果
六、代码实现
七、总结
摘要
本周阅读的论文《A TIME SERIES IS WORTH 64 WORDS: LONG-TERM FORECASTING WITH TRANSFORMERS》提出了一种高效的时间序列预测模型设计,即PatchTST,专门针对多变量时间序列预测及自我监督表示学习任务,是目前基于深度学习的时间序列预测在数据输入创新方向的代表作。该设计围绕两大核心构建:一是将时间序列分割为子序列级别的块(patches),作为Transformer的输入令牌,从而保留局部语义信息;二是实现通道独立性,每通道仅包含单一的单变量时间序列,且共享相同的嵌入和Transformer权重。PatchTST通过这种分块设计,在保留局部信息的同时,显著降低了注意力映射的计算量和内存占用,使模型能够处理更长的历史数据,并提高了长期预测的准确性。与当前的基于Transformer的模型相比,PatchTST在长序列预测方面取得了显著提升。此外,该模型在自我监督预训练任务中也表现出色,特别是在大型数据集上,通过预训练得到的掩码表示比直接监督训练的模型表现更优。
Abstract
The paper I read this week, "A TIME SERVES IS WORTH 64 WORDS: LONG-TERM FORECASTING With TRANSFORMERS," proposes an efficient time series prediction model design, PatchTST, specifically designed for multivariate time series prediction and self supervised representation learning tasks. This design revolves around two core constructions: firstly, dividing the time series into sub sequence level blocks (patches) as input tokens for the Transformer, thereby preserving local semantic information; The second is to achieve channel independence, where each channel only contains a single univariate time series and shares the same embedding and Transformer weights. PatchTST, through this block design, significantly reduces the computational complexity and memory usage of attention mapping while retaining local information, enabling the model to process longer historical data and improving the accuracy of long-term predictions. Compared with current Transformer based models, PatchTST has achieved significant improvements in long sequence prediction. In addition, the model also performs well in self supervised pre training tasks, especially on large datasets, where the mask representation obtained through pre training performs better than the directly supervised trained model.
文献阅读:使用 Transformer 进行长期预测-PatchTST
[2211.14730] A Time Series is Worth 64 Words: Long-term Forecasting with Transformers (arxiv.org)![]() https://arxiv.org/abs/2211.14730https://doi.org/10.48550/arXiv.2211.14730
https://arxiv.org/abs/2211.14730https://doi.org/10.48550/arXiv.2211.14730
一、现有问题
尽管深度学习模型在时间序列分析,特别是预测任务上取得了显著进展,但传统Transformer模型在处理长时序预测时面临挑战。主要问题包括点对点注意力机制忽视了数据块(patch)的重要性,导致局部语义信息的丢失,以及随着观察窗口(look-back window)增大,计算复杂度和内存需求呈平方级增长。此外,大多数模型未能充分挖掘不同通道间的关联性,限制了模型在复杂场景中的表现。
二、提出方法
针对上述问题提出了PatchTST模型,该设计围绕两大核心构建:
- 时间序列分段(Patching):将时间序列分割成多个子序列(或patch),每个patch作为一个整体输入到Transformer,这样保留了时间序列中的局部语义信息。
- 通道独立性(Channel-Independence):模型中的每个通道对应一个单变量时间序列,所有通道共享相同的嵌入和Transformer权重,这简化了模型结构并促进了跨通道的潜在信息交流。
三、相关知识
1、时间序列中的Patch
类似自然语言处理(NLP)领域BERT模型对子词进行分词处理,以及计算机视觉(CV)领域Vision Transformer将图像切分为小块,时间序列分析也开始利用patch概念来捕捉局部特征,以提高模型对序列局部结构的理解能力。时间序列预测的目的是了解每个不同时间步长的数据之间的相关性,然而单个时间步长不像句子中的词那样具有语义意义,因此提取局部语义信息对于分析它们之间的联系是至关重要的。以前的大多数研究只使用点式输入令牌,或者仅仅是手动制作的序列信息。
时间序列数据具有时序性,各个时间步之间存在着相关性和依赖关系。在时间序列预测任务中,我们需要从过去的时间步中提取信息,以预测未来的时间步。而传统的逐点计算注意力机制只关注当前时间步,无法充分考虑到时间序列中前后时间步的联系。PatchTST模型通过将时间步长聚合为子系列级别的补丁来增强局部性并捕获在点级别上不可用的全面语义信息。
Patching的优点
- 通过patche,模型可以通过查看一组时间步骤,而不是查看单个时间步骤来提取局部语义。
- 大大减少了被输入到transformer编码器的令牌数量,大大降低了模型的空间和时间复杂性,意味着可以给模型提供更长的输入序列以提取有意义的时间关系。
2、Vanilla Transformer
Vanila Transfommer是一种基于Transfommer架构的模型。与原始的Transformer相比,Vanila Transfommer只使用了Transformer中解码器部分的结构,即带有mask的attention层和前馈神经网络层。它在网络深度上做了一些改进,导致在训练过程中更难收敛。为了达到收敛目的,作者使用的一些小trick,即引入辅助的loss进行训练。
1、Multiple Positions
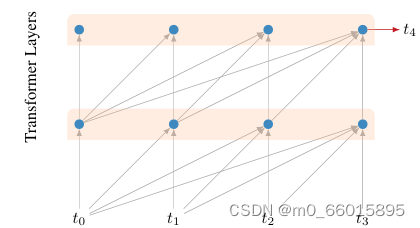
预测时不是指预测最后一个位置,而是序列的每个位置都进行预测,例如上图中t1~t4, 4个位置都会产生预测然后都会计算loss。训练时,t1~t4产生的loss都不会decay,都是同等重要的。
【这一类loss贯穿整个train的全部阶段,不发生衰减】
2、Intermedia Layer Losses
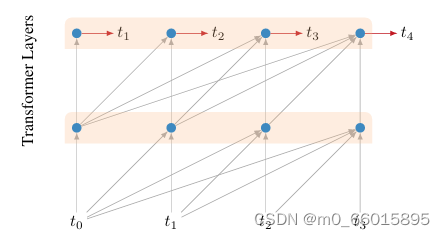
不仅最后一层会计算loss,对序列中所有中间位置的也添加了预测并也参与计算loss。 随着训练的进展,低层被加权,对损失的贡献越来越小。 如果总共有n层,那么第1个中间层在完成 的训练后停止贡献任何损失。 在训练完成一半后,这个schedule会drop所有中间损失。
【中间层的loss并不贯穿整个train始终,而是随着训练进行,逐渐衰减,衰减的方式是,一共有n层网络,当训练进行到时停止计算第k层loss。也就是说当训练进行到一半的时候,所有的中间层都不再贡献loss】
3、Multiple Targets
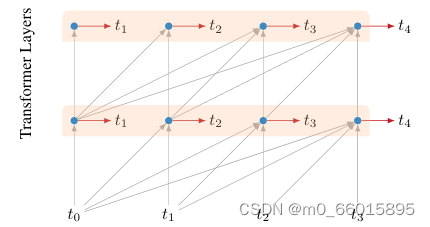
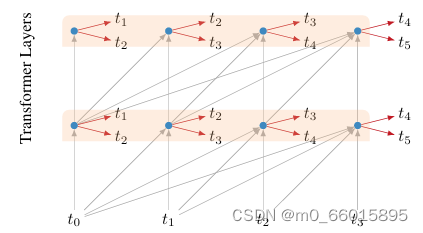
在序列的每个位置,模型不仅对下一个token做预测,还会对下下一个token做预测。
【但对于下下步的预测结果产生的loss是要发生衰减的,论文中该loss乘以0.5后再加入到整体的loss中】
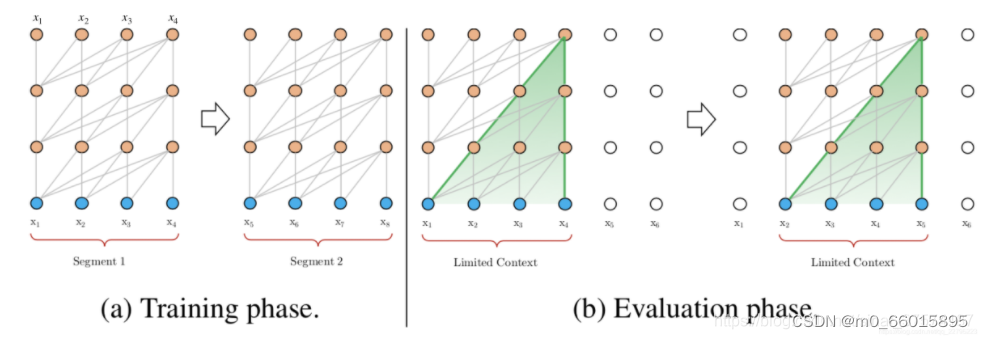
Vanilla Transformer的论文中使用64层模型,并仅限于处理 512个字符这种相对较短的输入,因此它将输入分成段,并分别从每个段中进行学习,如上图所示。 在测试阶段如需处理较长的输入,该模型会在每一步中将输入向右移动一个字符,以此实现对单个字符的预测。
Vanilla Transformer的缺点:
- 上下文长度受限:字符之间的最大依赖距离受输入长度的限制,模型看不到出现在几个句子之前的单词。
- 上下文碎片:对于长度超过512个字符的文本,都是从头开始单独训练的。段与段之间没有上下文依赖性,会让训练效率低下,也会影响模型的性能。
- 计算速度慢:在测试阶段,每次预测下一个单词,都需要重新构建一遍上下文,并从头开始计算,这样的计算速度非常慢。
四、提出的方法
1、模型结构
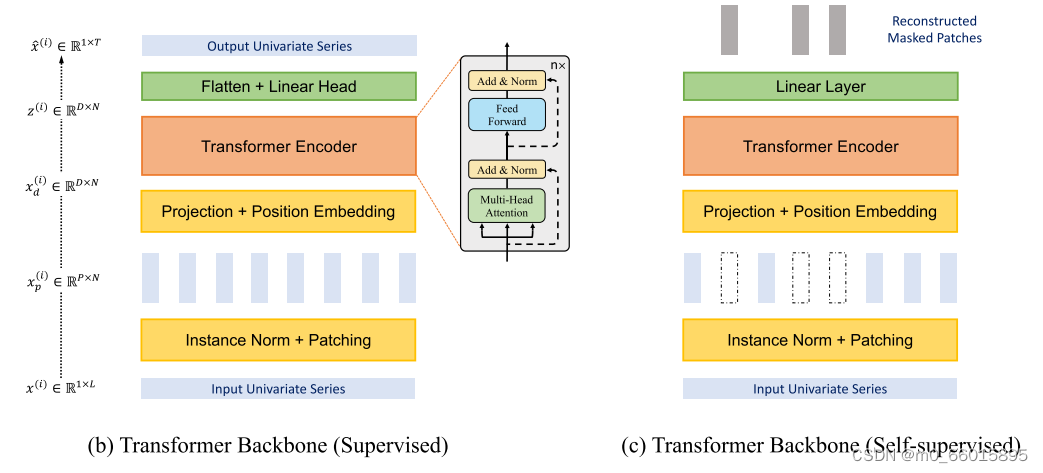
PatchTST模型的基本架构围绕着经典的Transformer编码器构建,输入是经过分段的时间序列patch。前向传播过程中,每个单变量序列被分段处理,并共享嵌入和Transformer权重,这一过程既保留了局部信息,又降低了计算复杂度。
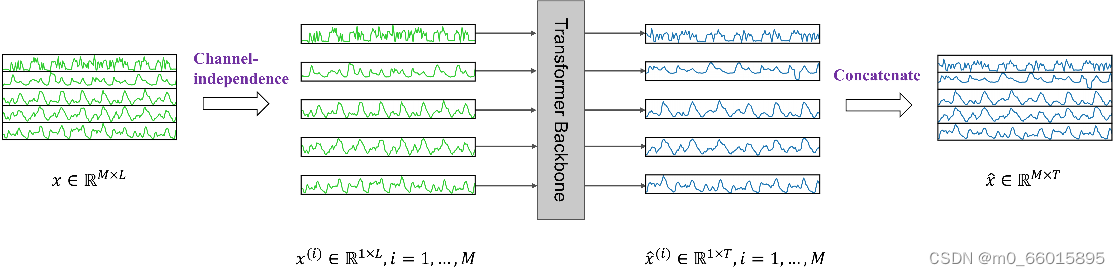
一、多变量时间序列被认为是一个多通道信号。每个时间序列基本上都是一个包含信号的通道。PatchTST模型真正强调的是通道独立的实现,即每个输入到Transformer骨干网的标记只包含一个通道的信息,或一个时间序列。多变量时间序列数据被分成不同的通道,它们共享相同的Transformer主干,但转发过程是独立的。通过使用patch,输入标记的数量可以从L减少到大约L/S(S为步长),这意味着注意图的内存使用量和计算复杂度以S的二次曲线减少。因此,在训练时间和图形处理器内存的约束下,补丁的设计可以让模型看到更长的历史序列,这可以显著提高预测性能。
在下图中,我们看到一个多变量的时间序列是如何被分离成单个序列的,并且每个序列作为一个输入标记被送入Transformer主干网。然后,对每个系列进行预测,并将结果串联起来以获得最终的预测结果。
这里,patches可以是重叠的或不重叠的。patche的数量取决于patches的长度P和步长S。在这里,步长就像卷积一样,它只是连续patche的开始之间有多少个时间步长。下图假设有一个15个时间步长的序列,patches长度为5,步长也是5,结果是三个patches。
PatchTST模型使用Vanilla Transformer编码器作为其核心架构。每个输入序列都被划分为多个patche,这些patche是来自原始序列的较短序列,产生了多个补丁(垂直的矩形),然后被发送到Transformer编码器。这些patch用作Transformer输入token,使用Vanilla Transformer编码器将观察到的信号映射到潜在表示。通过可训练线性投影将块映射到D维的Transformer潜在空间,并应用可学习的加性位置编码来监视块的时间顺序。然后,多头注意中的每个头部将输入分别转换为查询矩阵、密钥矩阵和值矩阵,然后使用定标乘积来获得注意输出,多头注意块还包括BatchNorm层和具有剩余连接的前馈网络,如图所示。最后,使用具有线性头部的Flatten层来获得预测结果。
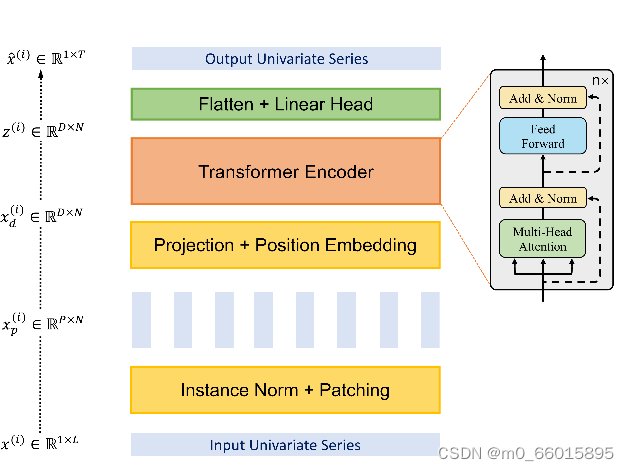
模型计算过程:

2、表征学习
该论文的作者建议通过使用表征学习对模型进行另一种改进。在自我监督预训练阶段,使用PatchTST的掩蔽自监督表示学习,其中随机选择面片并将其设置为零,该模型将重建遮罩的面片。这个过程相当简单,因为随机斑块将被屏蔽,也就是说,它们将被设置为0。然后,模型被训练来重新创建原始斑块,这就是图中顶部的灰色垂直矩形的输出。
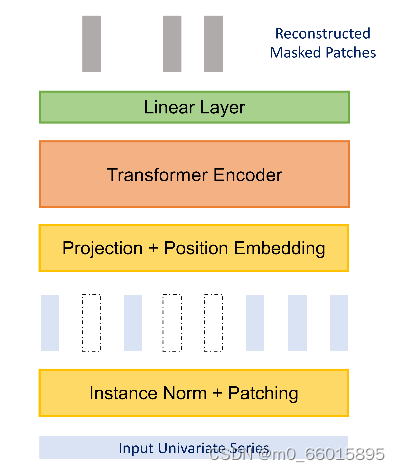
使用表征学习不仅增强了模型对时间序列内在结构的理解,还能提升在特定任务上的微调性能。实验结果表明,在大规模数据集上,预训练的PatchTST模型在微调后能超越仅使用监督学习训练的模型,且其预训练表示的迁移能力在其他数据集上也达到了SOTA水平。
3、模型优点
- 时间和空间复杂度的降低:原始的Transformer在时间和空间上的复杂度都是O(N2),其中N是输入令牌的数量。如果不进行前处理,N将与输入序列长度L具有相同的值,这在实际应用中成为计算时间和内存的主要瓶颈。通过应用patch,我们可以将N减少一个步长的因子:N≈L/S,从而将复杂度平方降低。
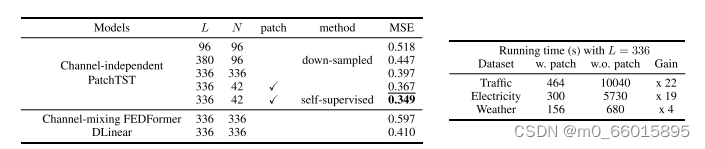
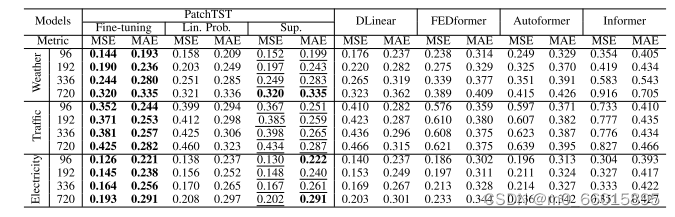
- 较长回溯窗口的学习能力:下表显示,将回溯窗口L从96增加到336,均方误差可以从0.518降低到0.397。然而,简单地扩展L是以更大的内存和计算使用为代价的,由于时间序列往往携带严重的时间冗余信息。通过研究发现在相同数量的输入令牌的情况下,更长的回顾窗口也传达了更重要的信息。patch可以对可能包含相似值的本地时间步长进行分组,同时使模型能够减少输入标记的长度,从而提高计算效率。
- 表征学习能力:随着强大的自我监督学习技术的出现,需要具有多个非线性抽象层的复杂模型来捕获数据的抽象表征。通过提出的PatchTST模型,不仅证实了Transformer对于时间序列预测的有效性,而且还展示了可以进一步提高预测性能的表示能力。
五、研究实验
1、数据集
本研究使用8个常用数据集上,包括天气、交通、电力、ILI和4个ETT数据集(ETTh1、ETTh2、ETTm1、ETTm2)。ETTh1数据集特别适合于评估模型在能源消耗时间序列预测中的表现,而Traffic数据集则用于交通流预测,这些数据集具有不同的复杂性和规模,能够全面测试模型的泛化能力和鲁棒性。

2、评估指标
主要采用均方误差(MSE)作为评估模型预测性能的主要指标。MSE是一种常用的回归问题评价标准,衡量模型预测值与真实值之间的差异,MSE值越低说明预测精度越高。
3、基线模型
选择基于Sota Transformer的模型,包括FEDformer、Autoformer、Informer、Pyraformer、LogTrans以及最近的非基于Transformer的模型DLine作为基线模型,所有模型都遵循与原始论文相同的实验设置。
4、实验过程
首先,对PatchTST模型进行监督学习训练,比较不同预测长度下的性能,验证其在长时序预测中的有效性。随后,进行自我监督预训练,将模型在大量无标签数据上进行预训练,学习通用的时间序列表示。此阶段包括掩码预测任务,以增强模型捕捉序列间复杂依赖的能力。最后,通过线性探针或微调模型在特定任务上的最后一层,评估预训练表示的质量。
5、实验结果
时间序列表示学习
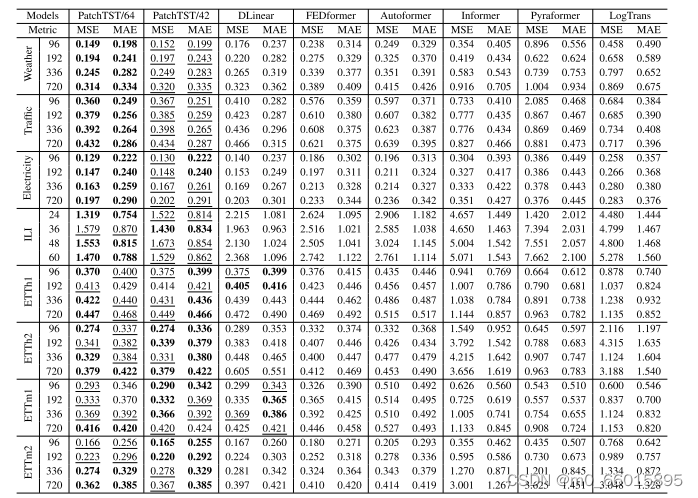
PatchTST在自我监督学习任务上展现出卓越性能,PatchTST/64实现了MSE和MAE的总体减少21.0%和16.7%,而PatchTST/42实现了MSE和MAE的整体减少20.2%和16.4%。当仅对模型的最后一层进行微调时,它在ETTh1数据集上的MSE降至0.349,远优于其他对比模型。这证明了模型在学习高质量时间序列表示方面的强大能力。
表征学习
通过对比实验,PatchTST预训练后的表示在转移到其他数据集时,仍然保持了SOTA的预测精度,表明所学表示具有良好的泛化能力。
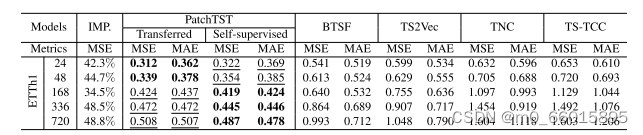
与BTSF、TS2Vec、TNC和TS-TCC等其他自监督对比学习方法相比,PatchTST在ETTh1数据集上无论是自我监督还是跨数据集转移学习均表现出最佳性能。
消融实验
对模型中的两个关键组件:分段(patching)和通道独立性(channel-independence)进行了分析。实验结果显示,分段不仅保留了局部语义信息,还显著减少了计算资源的需求。而通道独立性不仅加快了模型收敛速度,减少了过拟合风险,还为学习跨序列空间相关性和多任务学习提供了便利。模型在不混合通道的情况下,对于噪声的抵抗能力更强,从而提升了预测的稳健性。

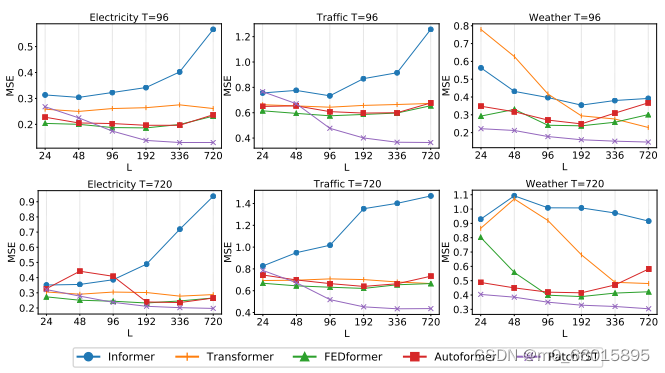
原则上,较长的回顾窗口增加了receptive field,这将潜在地改善预测性能。然而,这种现象在大多数基于Transformer的模型中都没有观察到。图中演示了在大多数情况下,这些基于Transformer的基线没有受益于较长的回顾窗口L,这表明它们在捕获时间信息方面无效。相比之下,PatchTST随着接受野的增加而持续降低MSE分数,这证实了我们的模型从更长的回顾窗口中学习的能力。
六、代码实现
数据处理模块
def __read_data__(self):# 数据标准化实例self.scaler = StandardScaler()# 读取数据df_raw = pd.read_csv(os.path.join(self.root_path,self.data_path))# 计算数据起始点border1s = [0, 12 * 30 * 24 - self.seq_len, 12 * 30 * 24 + 4 * 30 * 24 - self.seq_len]border2s = [12 * 30 * 24, 12 * 30 * 24 + 4 * 30 * 24, 12 * 30 * 24 + 8 * 30 * 24]border1 = border1s[self.set_type]border2 = border2s[self.set_type]# 如果预测对象为多变量预测或多元预测单变量if self.features == 'M' or self.features == 'MS':# 取除日期列的其他所有列cols_data = df_raw.columns[1:]df_data = df_raw[cols_data]# 若预测类型为S(单特征预测单特征)elif self.features == 'S':# 取特征列df_data = df_raw[[self.target]]# 将数据进行归一化if self.scale:train_data = df_data[border1s[0]:border2s[0]]self.scaler.fit(train_data.values)data = self.scaler.transform(df_data.values)else:data = df_data.values# 取日期列df_stamp = df_raw[['date']][border1:border2]# 利用pandas将数据转换为日期格式df_stamp['date'] = pd.to_datetime(df_stamp.date)# 构建时间特征if self.timeenc == 0:df_stamp['month'] = df_stamp.date.apply(lambda row: row.month, 1)df_stamp['day'] = df_stamp.date.apply(lambda row: row.day, 1)df_stamp['weekday'] = df_stamp.date.apply(lambda row: row.weekday(), 1)df_stamp['hour'] = df_stamp.date.apply(lambda row: row.hour, 1)data_stamp = df_stamp.drop(['date'], 1).valueselif self.timeenc == 1:# 时间特征构造函数data_stamp = time_features(pd.to_datetime(df_stamp['date'].values), freq=self.freq)# 转置data_stamp = data_stamp.transpose(1, 0)# 取数据特征列self.data_x = data[border1:border2]self.data_y = data[border1:border2]self.data_stamp = data_stampdef __getitem__(self, index):# 随机取得标签s_begin = index# 训练区间s_end = s_begin + self.seq_len# 有标签区间+无标签区间(预测时间步长)r_begin = s_end - self.label_lenr_end = r_begin + self.label_len + self.pred_len# 取训练数据seq_x = self.data_x[s_begin:s_end]seq_y = self.data_y[r_begin:r_end]# 取训练数据对应时间特征seq_x_mark = self.data_stamp[s_begin:s_end]# 取有标签区间+无标签区间(预测时间步长)对应时间特征seq_y_mark = self.data_stamp[r_begin:r_end]return seq_x, seq_y, seq_x_mark, seq_y_markPatchTST_backbone
class PatchTST_backbone(nn.Module):def __init__(self, c_in:int, context_window:int, target_window:int, patch_len:int, stride:int, max_seq_len:Optional[int]=1024, n_layers:int=3, d_model=128, n_heads=16, d_k:Optional[int]=None, d_v:Optional[int]=None,d_ff:int=256, norm:str='BatchNorm', attn_dropout:float=0., dropout:float=0., act:str="gelu", key_padding_mask:bool='auto',padding_var:Optional[int]=None, attn_mask:Optional[Tensor]=None, res_attention:bool=True, pre_norm:bool=False, store_attn:bool=False,pe:str='zeros', learn_pe:bool=True, fc_dropout:float=0., head_dropout = 0, padding_patch = None,pretrain_head:bool=False, head_type = 'flatten', individual = False, revin = True, affine = True, subtract_last = False,verbose:bool=False, **kwargs):super().__init__()# RevInself.revin = revinif self.revin: self.revin_layer = RevIN(c_in, affine=affine, subtract_last=subtract_last)# Patchingself.patch_len = patch_lenself.stride = strideself.padding_patch = padding_patchpatch_num = int((context_window - patch_len)/stride + 1)if padding_patch == 'end': # can be modified to general caseself.padding_patch_layer = nn.ReplicationPad1d((0, stride)) patch_num += 1# Backbone self.backbone = TSTiEncoder(c_in, patch_num=patch_num, patch_len=patch_len, max_seq_len=max_seq_len,n_layers=n_layers, d_model=d_model, n_heads=n_heads, d_k=d_k, d_v=d_v, d_ff=d_ff,attn_dropout=attn_dropout, dropout=dropout, act=act, key_padding_mask=key_padding_mask, padding_var=padding_var,attn_mask=attn_mask, res_attention=res_attention, pre_norm=pre_norm, store_attn=store_attn,pe=pe, learn_pe=learn_pe, verbose=verbose, **kwargs)# Headself.head_nf = d_model * patch_numself.n_vars = c_inself.pretrain_head = pretrain_headself.head_type = head_typeself.individual = individualif self.pretrain_head: self.head = self.create_pretrain_head(self.head_nf, c_in, fc_dropout) # custom head passed as a partial func with all its kwargselif head_type == 'flatten': self.head = Flatten_Head(self.individual, self.n_vars, self.head_nf, target_window, head_dropout=head_dropout)def forward(self, z):# z:[batch,feature,seq_len]# normif self.revin: z = z.permute(0,2,1)z = self.revin_layer(z, 'norm')z = z.permute(0,2,1)# do patchingif self.padding_patch == 'end':# padding操作z = self.padding_patch_layer(z)# 从一个分批输入的张量中提取滑动的局部块# z:[batch,feature,patch_num,patch_len]z = z.unfold(dimension=-1, size=self.patch_len, step=self.stride)# 维度交换z:[batch,feature,patch_len,patch_num]z = z.permute(0,1,3,2)# 进入骨干网络,输出维度[batch, feature, d_model, patch_num]z = self.backbone(z)z = self.head(z) # z: [bs x nvars x target_window] # 反归一化if self.revin: z = z.permute(0,2,1)z = self.revin_layer(z, 'denorm')z = z.permute(0,2,1)return z
positional_encoding层
def positional_encoding(pe, learn_pe, q_len, d_model):# Positional encodingif pe == None:W_pos = torch.empty((q_len, d_model)) # pe = None and learn_pe = False can be used to measure impact of penn.init.uniform_(W_pos, -0.02, 0.02)learn_pe = Falseelif pe == 'zero':W_pos = torch.empty((q_len, 1))nn.init.uniform_(W_pos, -0.02, 0.02)elif pe == 'zeros':W_pos = torch.empty((q_len, d_model))nn.init.uniform_(W_pos, -0.02, 0.02)elif pe == 'normal' or pe == 'gauss':W_pos = torch.zeros((q_len, 1))torch.nn.init.normal_(W_pos, mean=0.0, std=0.1)elif pe == 'uniform':W_pos = torch.zeros((q_len, 1))nn.init.uniform_(W_pos, a=0.0, b=0.1)elif pe == 'lin1d': W_pos = Coord1dPosEncoding(q_len, exponential=False, normalize=True)elif pe == 'exp1d': W_pos = Coord1dPosEncoding(q_len, exponential=True, normalize=True)elif pe == 'lin2d': W_pos = Coord2dPosEncoding(q_len, d_model, exponential=False, normalize=True)elif pe == 'exp2d': W_pos = Coord2dPosEncoding(q_len, d_model, exponential=True, normalize=True)elif pe == 'sincos': W_pos = PositionalEncoding(q_len, d_model, normalize=True)else: raise ValueError(f"{pe} is not a valid pe (positional encoder. Available types: 'gauss'=='normal', \'zeros', 'zero', uniform', 'lin1d', 'exp1d', 'lin2d', 'exp2d', 'sincos', None.)")# 设定为可训练参数return nn.Parameter(W_pos, requires_grad=learn_pe)
TSTiEncoder层
class TSTiEncoder(nn.Module): #i means channel-independentdef __init__(self, c_in, patch_num, patch_len, max_seq_len=1024,n_layers=3, d_model=128, n_heads=16, d_k=None, d_v=None,d_ff=256, norm='BatchNorm', attn_dropout=0., dropout=0., act="gelu", store_attn=False,key_padding_mask='auto', padding_var=None, attn_mask=None, res_attention=True, pre_norm=False,pe='zeros', learn_pe=True, verbose=False, **kwargs):super().__init__()self.patch_num = patch_numself.patch_len = patch_len# Input encodingq_len = patch_numself.W_P = nn.Linear(patch_len, d_model) # Eq 1: projection of feature vectors onto a d-dim vector spaceself.seq_len = q_len# Positional encodingself.W_pos = positional_encoding(pe, learn_pe, q_len, d_model)# Residual dropoutself.dropout = nn.Dropout(dropout)# Encoderself.encoder = TSTEncoder(q_len, d_model, n_heads, d_k=d_k, d_v=d_v, d_ff=d_ff, norm=norm, attn_dropout=attn_dropout, dropout=dropout,pre_norm=pre_norm, activation=act, res_attention=res_attention, n_layers=n_layers, store_attn=store_attn)def forward(self, x) -> Tensor:# 输入x维度:[batch,feature,patch_len,patch_num]# 取feature数量n_vars = x.shape[1]# 调换维度,变为:[batch, feature, patch_num, patch_len]x = x.permute(0,1,3,2)# 进入全连接层,输出为[batch, feature, patch_num, d_model]x = self.W_P(x)# 重置维度为[batch * feature, patch_nums, d_model]u = torch.reshape(x, (x.shape[0]*x.shape[1],x.shape[2],x.shape[3]))# 进入位置编码后共同进入dropout层[batch * feature,patch_nums,d_model]u = self.dropout(u + self.W_pos)# 进入encoder层后z的维度[batch * feature, patch_num, d_model]z = self.encoder(u)# 重置维度为[batch, feature, patch_num, d_model]z = torch.reshape(z, (-1,n_vars,z.shape[-2],z.shape[-1]))# 再度交换维度为[batch, feature, d_model, patch_num]z = z.permute(0,1,3,2)return z
TSTEncoderLayer层
class TSTEncoderLayer(nn.Module):def __init__(self, q_len, d_model, n_heads, d_k=None, d_v=None, d_ff=256, store_attn=False,norm='BatchNorm', attn_dropout=0, dropout=0., bias=True, activation="gelu", res_attention=False, pre_norm=False):super().__init__()assert not d_model%n_heads, f"d_model ({d_model}) must be divisible by n_heads ({n_heads})"d_k = d_model // n_heads if d_k is None else d_kd_v = d_model // n_heads if d_v is None else d_v# Multi-Head attentionself.res_attention = res_attentionself.self_attn = _MultiheadAttention(d_model, n_heads, d_k, d_v, attn_dropout=attn_dropout, proj_dropout=dropout, res_attention=res_attention)# Add & Normself.dropout_attn = nn.Dropout(dropout)if "batch" in norm.lower():self.norm_attn = nn.Sequential(Transpose(1,2), nn.BatchNorm1d(d_model), Transpose(1,2))else:self.norm_attn = nn.LayerNorm(d_model)# Position-wise Feed-Forwardself.ff = nn.Sequential(nn.Linear(d_model, d_ff, bias=bias),get_activation_fn(activation),nn.Dropout(dropout),nn.Linear(d_ff, d_model, bias=bias))# Add & Normself.dropout_ffn = nn.Dropout(dropout)if "batch" in norm.lower():self.norm_ffn = nn.Sequential(Transpose(1,2), nn.BatchNorm1d(d_model), Transpose(1,2))else:self.norm_ffn = nn.LayerNorm(d_model)self.pre_norm = pre_normself.store_attn = store_attndef forward(self, src:Tensor, prev:Optional[Tensor]=None, key_padding_mask:Optional[Tensor]=None, attn_mask:Optional[Tensor]=None) -> Tensor:# Multi-Head attention sublayerif self.pre_norm:src = self.norm_attn(src)## Multi-Head attentionif self.res_attention:src2, attn, scores = self.self_attn(src, src, src, prev, key_padding_mask=key_padding_mask, attn_mask=attn_mask)else:src2, attn = self.self_attn(src, src, src, key_padding_mask=key_padding_mask, attn_mask=attn_mask)if self.store_attn:self.attn = attn## Add & Normsrc = src + self.dropout_attn(src2) # Add: residual connection with residual dropoutif not self.pre_norm:src = self.norm_attn(src)# Feed-forward sublayerif self.pre_norm:src = self.norm_ffn(src)## Position-wise Feed-Forwardsrc2 = self.ff(src)## Add & Normsrc = src + self.dropout_ffn(src2) # Add: residual connection with residual dropoutif not self.pre_norm:src = self.norm_ffn(src)if self.res_attention:return src, scoreselse:return src
Flatten_Head层
class Flatten_Head(nn.Module):def __init__(self, individual, n_vars, nf, target_window, head_dropout=0):super().__init__()self.individual = individualself.n_vars = n_varsif self.individual:# 对每个特征进行展平,然后进入线性层和dropout层self.linears = nn.ModuleList()self.dropouts = nn.ModuleList()self.flattens = nn.ModuleList()for i in range(self.n_vars):self.flattens.append(nn.Flatten(start_dim=-2))self.linears.append(nn.Linear(nf, target_window))self.dropouts.append(nn.Dropout(head_dropout))else:self.flatten = nn.Flatten(start_dim=-2)self.linear = nn.Linear(nf, target_window)self.dropout = nn.Dropout(head_dropout)def forward(self, x): # x: [bs x nvars x d_model x patch_num]if self.individual:x_out = []for i in range(self.n_vars):z = self.flattens[i](x[:,i,:,:]) # z: [bs x d_model * patch_num]z = self.linears[i](z) # z: [bs x target_window]z = self.dropouts[i](z)x_out.append(z)x = torch.stack(x_out, dim=1) # x: [bs x nvars x target_window]else:# 输出x为[batch,target_window]x = self.flatten(x)x = self.linear(x)x = self.dropout(x)return x
MultiheadAttention模块
class _MultiheadAttention(nn.Module):def __init__(self, d_model, n_heads, d_k=None, d_v=None, res_attention=False, attn_dropout=0., proj_dropout=0., qkv_bias=True, lsa=False):"""Multi Head Attention LayerInput shape:Q: [batch_size (bs) x max_q_len x d_model]K, V: [batch_size (bs) x q_len x d_model]mask: [q_len x q_len]"""super().__init__()d_k = d_model // n_heads if d_k is None else d_kd_v = d_model // n_heads if d_v is None else d_vself.n_heads, self.d_k, self.d_v = n_heads, d_k, d_vself.W_Q = nn.Linear(d_model, d_k * n_heads, bias=qkv_bias)self.W_K = nn.Linear(d_model, d_k * n_heads, bias=qkv_bias)self.W_V = nn.Linear(d_model, d_v * n_heads, bias=qkv_bias)# Scaled Dot-Product Attention (multiple heads)self.res_attention = res_attentionself.sdp_attn = _ScaledDotProductAttention(d_model, n_heads, attn_dropout=attn_dropout, res_attention=self.res_attention, lsa=lsa)# Poject outputself.to_out = nn.Sequential(nn.Linear(n_heads * d_v, d_model), nn.Dropout(proj_dropout))def forward(self, Q:Tensor, K:Optional[Tensor]=None, V:Optional[Tensor]=None, prev:Optional[Tensor]=None,key_padding_mask:Optional[Tensor]=None, attn_mask:Optional[Tensor]=None):bs = Q.size(0)if K is None: K = Qif V is None: V = Q# Linear (+ split in multiple heads)q_s = self.W_Q(Q).view(bs, -1, self.n_heads, self.d_k).transpose(1,2) # q_s : [bs x n_heads x max_q_len x d_k]k_s = self.W_K(K).view(bs, -1, self.n_heads, self.d_k).permute(0,2,3,1) # k_s : [bs x n_heads x d_k x q_len] - transpose(1,2) + transpose(2,3)v_s = self.W_V(V).view(bs, -1, self.n_heads, self.d_v).transpose(1,2) # v_s : [bs x n_heads x q_len x d_v]# Apply Scaled Dot-Product Attention (multiple heads)if self.res_attention:output, attn_weights, attn_scores = self.sdp_attn(q_s, k_s, v_s, prev=prev, key_padding_mask=key_padding_mask, attn_mask=attn_mask)else:output, attn_weights = self.sdp_attn(q_s, k_s, v_s, key_padding_mask=key_padding_mask, attn_mask=attn_mask)# output: [bs x n_heads x q_len x d_v], attn: [bs x n_heads x q_len x q_len], scores: [bs x n_heads x max_q_len x q_len]# back to the original inputs dimensionsoutput = output.transpose(1, 2).contiguous().view(bs, -1, self.n_heads * self.d_v) # output: [bs x q_len x n_heads * d_v]output = self.to_out(output)if self.res_attention: return output, attn_weights, attn_scoreselse: return output, attn_weightsScaledDotProductAttention模块
class _ScaledDotProductAttention(nn.Module):r"""Scaled Dot-Product Attention module (Attention is all you need by Vaswani et al., 2017) with optional residual attention from previous layer(Realformer: Transformer likes residual attention by He et al, 2020) and locality self sttention (Vision Transformer for Small-Size Datasetsby Lee et al, 2021)"""def __init__(self, d_model, n_heads, attn_dropout=0., res_attention=False, lsa=False):super().__init__()self.attn_dropout = nn.Dropout(attn_dropout)self.res_attention = res_attentionhead_dim = d_model // n_headsself.scale = nn.Parameter(torch.tensor(head_dim ** -0.5), requires_grad=lsa)self.lsa = lsadef forward(self, q:Tensor, k:Tensor, v:Tensor, prev:Optional[Tensor]=None, key_padding_mask:Optional[Tensor]=None, attn_mask:Optional[Tensor]=None):'''Input shape:q : [bs x n_heads x max_q_len x d_k]k : [bs x n_heads x d_k x seq_len]v : [bs x n_heads x seq_len x d_v]prev : [bs x n_heads x q_len x seq_len]key_padding_mask: [bs x seq_len]attn_mask : [1 x seq_len x seq_len]Output shape:output: [bs x n_heads x q_len x d_v]attn : [bs x n_heads x q_len x seq_len]scores : [bs x n_heads x q_len x seq_len]'''# Scaled MatMul (q, k) - similarity scores for all pairs of positions in an input sequenceattn_scores = torch.matmul(q, k) * self.scale # attn_scores : [bs x n_heads x max_q_len x q_len]# Add pre-softmax attention scores from the previous layer (optional)if prev is not None: attn_scores = attn_scores + prev# Attention mask (optional)if attn_mask is not None: # attn_mask with shape [q_len x seq_len] - only used when q_len == seq_lenif attn_mask.dtype == torch.bool:attn_scores.masked_fill_(attn_mask, -np.inf)else:attn_scores += attn_mask# Key padding mask (optional)if key_padding_mask is not None: # mask with shape [bs x q_len] (only when max_w_len == q_len)attn_scores.masked_fill_(key_padding_mask.unsqueeze(1).unsqueeze(2), -np.inf)# normalize the attention weightsattn_weights = F.softmax(attn_scores, dim=-1) # attn_weights : [bs x n_heads x max_q_len x q_len]attn_weights = self.attn_dropout(attn_weights)# compute the new values given the attention weightsoutput = torch.matmul(attn_weights, v) # output: [bs x n_heads x max_q_len x d_v]if self.res_attention: return output, attn_weights, attn_scoreselse: return output, attn_weights实验结果 (exp_main.py)
from data_provider.data_factory import data_provider
from exp.exp_basic import Exp_Basic
from models import Informer, Autoformer, Transformer, DLinear, Linear, NLinear, PatchTST
from utils.tools import EarlyStopping, adjust_learning_rate, visual, test_params_flop
from utils.metrics import metricimport numpy as np
import torch
import torch.nn as nn
from torch import optim
from torch.optim import lr_scheduler import os
import timeimport warnings
import matplotlib.pyplot as plt
import numpy as npwarnings.filterwarnings('ignore')class Exp_Main(Exp_Basic):def __init__(self, args):super(Exp_Main, self).__init__(args)#构建模型def _build_model(self):model_dict = {'Autoformer': Autoformer,'Transformer': Transformer,'Informer': Informer,'DLinear': DLinear,'NLinear': NLinear,'Linear': Linear,'PatchTST': PatchTST,}model = model_dict[self.args.model].Model(self.args).float()if self.args.use_multi_gpu and self.args.use_gpu:model = nn.DataParallel(model, device_ids=self.args.device_ids)return model#获取数据def _get_data(self, flag):data_set, data_loader = data_provider(self.args, flag)return data_set, data_loader
#选择优化器def _select_optimizer(self):model_optim = optim.Adam(self.model.parameters(), lr=self.args.learning_rate)return model_optim
#选择评估指标def _select_criterion(self):criterion = nn.MSELoss()return criteriondef vali(self, vali_data, vali_loader, criterion):total_loss = []self.model.eval()with torch.no_grad():for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(vali_loader):batch_x = batch_x.float().to(self.device)batch_y = batch_y.float()batch_x_mark = batch_x_mark.float().to(self.device)batch_y_mark = batch_y_mark.float().to(self.device)#解码器输入dec_inp = torch.zeros_like(batch_y[:, -self.args.pred_len:, :]).float()dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)# encoder - decoderif self.args.use_amp:with torch.cuda.amp.autocast():if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)else:if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)f_dim = -1 if self.args.features == 'MS' else 0outputs = outputs[:, -self.args.pred_len:, f_dim:]batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)pred = outputs.detach().cpu()true = batch_y.detach().cpu()loss = criterion(pred, true)total_loss.append(loss)total_loss = np.average(total_loss)self.model.train()return total_loss
#模型训练def train(self, setting):train_data, train_loader = self._get_data(flag='train')vali_data, vali_loader = self._get_data(flag='val')test_data, test_loader = self._get_data(flag='test')path = os.path.join(self.args.checkpoints, setting)if not os.path.exists(path):os.makedirs(path)time_now = time.time()train_steps = len(train_loader)early_stopping = EarlyStopping(patience=self.args.patience, verbose=True)model_optim = self._select_optimizer()criterion = self._select_criterion()if self.args.use_amp:scaler = torch.cuda.amp.GradScaler()scheduler = lr_scheduler.OneCycleLR(optimizer = model_optim,steps_per_epoch = train_steps,pct_start = self.args.pct_start,epochs = self.args.train_epochs,max_lr = self.args.learning_rate)for epoch in range(self.args.train_epochs):iter_count = 0train_loss = []self.model.train()epoch_time = time.time()for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(train_loader):iter_count += 1model_optim.zero_grad()batch_x = batch_x.float().to(self.device)batch_y = batch_y.float().to(self.device)batch_x_mark = batch_x_mark.float().to(self.device)batch_y_mark = batch_y_mark.float().to(self.device)#解码器输出dec_inp = torch.zeros_like(batch_y[:, -self.args.pred_len:, :]).float()dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)# 编码器-解码器if self.args.use_amp:with torch.cuda.amp.autocast():if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)f_dim = -1 if self.args.features == 'MS' else 0outputs = outputs[:, -self.args.pred_len:, f_dim:]batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)loss = criterion(outputs, batch_y)train_loss.append(loss.item())else:if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark, batch_y)# print(outputs.shape,batch_y.shape)f_dim = -1 if self.args.features == 'MS' else 0outputs = outputs[:, -self.args.pred_len:, f_dim:]batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)loss = criterion(outputs, batch_y)train_loss.append(loss.item())if (i + 1) % 100 == 0:print("\titers: {0}, epoch: {1} | loss: {2:.7f}".format(i + 1, epoch + 1, loss.item()))speed = (time.time() - time_now) / iter_countleft_time = speed * ((self.args.train_epochs - epoch) * train_steps - i)print('\tspeed: {:.4f}s/iter; left time: {:.4f}s'.format(speed, left_time))iter_count = 0time_now = time.time()if self.args.use_amp:scaler.scale(loss).backward()scaler.step(model_optim)scaler.update()else:loss.backward()model_optim.step()if self.args.lradj == 'TST':adjust_learning_rate(model_optim, scheduler, epoch + 1, self.args, printout=False)scheduler.step()print("Epoch: {} cost time: {}".format(epoch + 1, time.time() - epoch_time))train_loss = np.average(train_loss)vali_loss = self.vali(vali_data, vali_loader, criterion)test_loss = self.vali(test_data, test_loader, criterion)print("Epoch: {0}, Steps: {1} | Train Loss: {2:.7f} Vali Loss: {3:.7f} Test Loss: {4:.7f}".format(epoch + 1, train_steps, train_loss, vali_loss, test_loss))early_stopping(vali_loss, self.model, path)if early_stopping.early_stop:print("Early stopping")breakif self.args.lradj != 'TST':adjust_learning_rate(model_optim, scheduler, epoch + 1, self.args)else:print('Updating learning rate to {}'.format(scheduler.get_last_lr()[0]))best_model_path = path + '/' + 'checkpoint.pth'self.model.load_state_dict(torch.load(best_model_path))return self.modeldef test(self, setting, test=0):test_data, test_loader = self._get_data(flag='test')if test:print('loading model')self.model.load_state_dict(torch.load(os.path.join('./checkpoints/' + setting, 'checkpoint.pth')))preds = []trues = []inputx = []folder_path = './test_results/' + setting + '/'if not os.path.exists(folder_path):os.makedirs(folder_path)self.model.eval()with torch.no_grad():for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(test_loader):batch_x = batch_x.float().to(self.device)batch_y = batch_y.float().to(self.device)batch_x_mark = batch_x_mark.float().to(self.device)batch_y_mark = batch_y_mark.float().to(self.device)# decoder inputdec_inp = torch.zeros_like(batch_y[:, -self.args.pred_len:, :]).float()dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)# encoder - decoderif self.args.use_amp:with torch.cuda.amp.autocast():if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)else:if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)f_dim = -1 if self.args.features == 'MS' else 0# print(outputs.shape,batch_y.shape)outputs = outputs[:, -self.args.pred_len:, f_dim:]batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)outputs = outputs.detach().cpu().numpy()batch_y = batch_y.detach().cpu().numpy()pred = outputs # outputs.detach().cpu().numpy() # .squeeze()true = batch_y # batch_y.detach().cpu().numpy() # .squeeze()preds.append(pred)trues.append(true)inputx.append(batch_x.detach().cpu().numpy())if i % 20 == 0:input = batch_x.detach().cpu().numpy()gt = np.concatenate((input[0, :, -1], true[0, :, -1]), axis=0)pd = np.concatenate((input[0, :, -1], pred[0, :, -1]), axis=0)visual(gt, pd, os.path.join(folder_path, str(i) + '.pdf'))if self.args.test_flop:test_params_flop((batch_x.shape[1],batch_x.shape[2]))exit()preds = np.array(preds)trues = np.array(trues)inputx = np.array(inputx)preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])trues = trues.reshape(-1, trues.shape[-2], trues.shape[-1])inputx = inputx.reshape(-1, inputx.shape[-2], inputx.shape[-1])# result savefolder_path = './results/' + setting + '/'if not os.path.exists(folder_path):os.makedirs(folder_path)mae, mse, rmse, mape, mspe, rse, corr = metric(preds, trues)print('mse:{}, mae:{}, rse:{}'.format(mse, mae, rse))f = open("result.txt", 'a')f.write(setting + " \n")f.write('mse:{}, mae:{}, rse:{}'.format(mse, mae, rse))f.write('\n')f.write('\n')f.close()# np.save(folder_path + 'metrics.npy', np.array([mae, mse, rmse, mape, mspe,rse, corr]))np.save(folder_path + 'pred.npy', preds)# np.save(folder_path + 'true.npy', trues)# np.save(folder_path + 'x.npy', inputx)return#模型预测def predict(self, setting, load=False):pred_data, pred_loader = self._get_data(flag='pred')if load:path = os.path.join(self.args.checkpoints, setting)best_model_path = path + '/' + 'checkpoint.pth'self.model.load_state_dict(torch.load(best_model_path))preds = []self.model.eval()with torch.no_grad():for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(pred_loader):batch_x = batch_x.float().to(self.device)batch_y = batch_y.float()batch_x_mark = batch_x_mark.float().to(self.device)batch_y_mark = batch_y_mark.float().to(self.device)# 解码器输入dec_inp = torch.zeros([batch_y.shape[0], self.args.pred_len, batch_y.shape[2]]).float().to(batch_y.device)dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)# encoder - decoderif self.args.use_amp:with torch.cuda.amp.autocast():if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)else:if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)pred = outputs.detach().cpu().numpy() # .squeeze()preds.append(pred)preds = np.array(preds)preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])#保存结果folder_path = './results/' + setting + '/'if not os.path.exists(folder_path):os.makedirs(folder_path)np.save(folder_path + 'real_prediction.npy', preds)return
参数设定模块(run_longExp.py)
import argparse
import os
import torch
from exp.exp_main import Exp_Main
import random
import numpy as npif __name__ == '__main__':parser = argparse.ArgumentParser(description='Autoformer & Transformer family for Time Series Forecasting')# 随机数种子
parser.add_argument('--random_seed', type=int, default=2021, help='random seed')# basic config
parser.add_argument('--is_training', type=int, default=1, help='status')
parser.add_argument('--model_id', type=str, default='test', help='model id')
parser.add_argument('--model', type=str, default='PatchTST',help='model name, options: [Autoformer, Informer, Transformer]')# 数据名称
parser.add_argument('--data', type=str, default='ETTh1', help='dataset type')
# 数据所在文件夹
parser.add_argument('--root_path', type=str, default='./data/', help='root path of the data file')
# 数据文件全称
parser.add_argument('--data_path', type=str, default='ETTh1.csv', help='data file')
# 时间特征处理方式
parser.add_argument('--features', type=str, default='M',help='forecasting task, options:[M, S, MS]; M:multivariate predict multivariate, S:univariate predict univariate, MS:multivariate predict univariate')
# 目标列列名
parser.add_argument('--target', type=str, default='OT', help='target feature in S or MS task')
# 时间采集粒度
parser.add_argument('--freq', type=str, default='h',help='freq for time features encoding, options:[s:secondly, t:minutely, h:hourly, d:daily, b:business days, w:weekly, m:monthly], you can also use more detailed freq like 15min or 3h')
# 模型保存文件夹
parser.add_argument('--checkpoints', type=str, default='./checkpoints/', help='location of model checkpoints')# 回视窗口
parser.add_argument('--seq_len', type=int, default=96, help='input sequence length')
# 先验序列长度
parser.add_argument('--label_len', type=int, default=48, help='start token length')
# 预测窗口长度
parser.add_argument('--pred_len', type=int, default=96, help='prediction sequence length')# DLinear
#parser.add_argument('--individual', action='store_true', default=False, help='DLinear: a linear layer for each variate(channel) individually')# PatchTST
# 全连接层的dropout率
parser.add_argument('--fc_dropout', type=float, default=0.05, help='fully connected dropout')
# 多头注意力机制的dropout率
parser.add_argument('--head_dropout', type=float, default=0.0, help='head dropout')
# patch的长度
parser.add_argument('--patch_len', type=int, default=16, help='patch length')
# 核的步长
parser.add_argument('--stride', type=int, default=8, help='stride')
# padding方式
parser.add_argument('--padding_patch', default='end', help='None: None; end: padding on the end')
# 是否要进行实例归一化(instancenorm1d)
parser.add_argument('--revin', type=int, default=1, help='RevIN; True 1 False 0')
# 是否要学习仿生参数
parser.add_argument('--affine', type=int, default=0, help='RevIN-affine; True 1 False 0')
parser.add_argument('--subtract_last', type=int, default=0, help='0: subtract mean; 1: subtract last')
# 是否做趋势分解
parser.add_argument('--decomposition', type=int, default=0, help='decomposition; True 1 False 0')
# 趋势分解所用kerner_size
parser.add_argument('--kernel_size', type=int, default=25, help='decomposition-kernel')
parser.add_argument('--individual', type=int, default=0, help='individual head; True 1 False 0')# embedding方式
parser.add_argument('--embed_type', type=int, default=0, help='0: default 1: value embedding + temporal embedding + positional embedding 2: value embedding + temporal embedding 3: value embedding + positional embedding 4: value embedding')
# encoder输入特征数
parser.add_argument('--enc_in', type=int, default=5, help='encoder input size') # DLinear with --individual, use this hyperparameter as the number of channels
# decoder输入特征数
parser.add_argument('--dec_in', type=int, default=5, help='decoder input size')
# 输出通道数
parser.add_argument('--c_out', type=int, default=5, help='output size')
# 线性层隐含神经元个数
parser.add_argument('--d_model', type=int, default=512, help='dimension of model')
# 多头注意力机制
parser.add_argument('--n_heads', type=int, default=8, help='num of heads')
# encoder层数
parser.add_argument('--e_layers', type=int, default=2, help='num of encoder layers')
# decoder层数
parser.add_argument('--d_layers', type=int, default=1, help='num of decoder layers')
# FFN层隐含神经元个数
parser.add_argument('--d_ff', type=int, default=2048, help='dimension of fcn')
# 滑动窗口长度
parser.add_argument('--moving_avg', type=int, default=25, help='window size of moving average')
# 对Q进行采样,对Q采样的因子数
parser.add_argument('--factor', type=int, default=1, help='attn factor')
# 是否下采样操作pooling
parser.add_argument('--distil', action='store_false',help='whether to use distilling in encoder, using this argument means not using distilling',default=True)
# dropout率
parser.add_argument('--dropout', type=float, default=0.05, help='dropout')
# 时间特征嵌入方式
parser.add_argument('--embed', type=str, default='timeF',help='time features encoding, options:[timeF, fixed, learned]')
# 激活函数类型
parser.add_argument('--activation', type=str, default='gelu', help='activation')
# 是否输出attention矩阵
parser.add_argument('--output_attention', action='store_true', help='whether to output attention in ecoder')
# 是否进行预测
parser.add_argument('--do_predict', action='store_true', help='whether to predict unseen future data')# 并行核心数
parser.add_argument('--num_workers', type=int, default=0, help='data loader num workers')
# 实验轮数
parser.add_argument('--itr', type=int, default=1, help='experiments times')
# 训练迭代次数
parser.add_argument('--train_epochs', type=int, default=100, help='train epochs')
# batch size大小
parser.add_argument('--batch_size', type=int, default=128, help='batch size of train input data')
# early stopping机制容忍次数
parser.add_argument('--patience', type=int, default=100, help='early stopping patience')
# 学习率
parser.add_argument('--learning_rate', type=float, default=0.0001, help='optimizer learning rate')
parser.add_argument('--des', type=str, default='test', help='exp description')
# 损失函数
parser.add_argument('--loss', type=str, default='mse', help='loss function')
# 学习率下降策略
parser.add_argument('--lradj', type=str, default='type3', help='adjust learning rate')
parser.add_argument('--pct_start', type=float, default=0.3, help='pct_start')
# 使用混合精度训练
parser.add_argument('--use_amp', action='store_true', help='use automatic mixed precision training', default=False)# GPU
parser.add_argument('--use_gpu', type=bool, default=False, help='use gpu')
parser.add_argument('--gpu', type=int, default=0, help='gpu')
parser.add_argument('--use_multi_gpu', action='store_true', help='use multiple gpus', default=False)
parser.add_argument('--devices', type=str, default='0,1,2,3', help='device ids of multile gpus')
parser.add_argument('--test_flop', action='store_true', default=False, help='See utils/tools for usage')args = parser.parse_args()# random seedfix_seed = args.random_seedrandom.seed(fix_seed)torch.manual_seed(fix_seed)np.random.seed(fix_seed)args.use_gpu = True if torch.cuda.is_available() and args.use_gpu else Falseif args.use_gpu and args.use_multi_gpu:args.dvices = args.devices.replace(' ', '')device_ids = args.devices.split(',')args.device_ids = [int(id_) for id_ in device_ids]args.gpu = args.device_ids[0]print('Args in experiment:')print(args)Exp = Exp_Mainif args.is_training:for ii in range(args.itr):# setting record of experimentssetting = '{}_{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_fc{}_eb{}_dt{}_{}_{}'.format(args.model_id,args.model,args.data,args.features,args.seq_len,args.label_len,args.pred_len,args.d_model,args.n_heads,args.e_layers,args.d_layers,args.d_ff,args.factor,args.embed,args.distil,args.des,ii)exp = Exp(args) # set experimentsprint('>>>>>>>start training : {}>>>>>>>>>>>>>>>>>>>>>>>>>>'.format(setting))exp.train(setting)print('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))exp.test(setting)if args.do_predict:print('>>>>>>>predicting : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))exp.predict(setting, True)torch.cuda.empty_cache()else:ii = 0setting = '{}_{}_{}_ft{}_sl{}_ll{}_pl{}_dm{}_nh{}_el{}_dl{}_df{}_fc{}_eb{}_dt{}_{}_{}'.format(args.model_id,args.model,args.data,args.features,args.seq_len,args.label_len,args.pred_len,args.d_model,args.n_heads,args.e_layers,args.d_layers,args.d_ff,args.factor,args.embed,args.distil,args.des, ii)exp = Exp(args) # set experimentsprint('>>>>>>>testing : {}<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<'.format(setting))exp.test(setting, test=1)torch.cuda.empty_cache()实验主模块(Exp_Main.py)
from data_provider.data_factory import data_provider
from exp.exp_basic import Exp_Basic
from models import Informer, Autoformer, Transformer, DLinear, Linear, NLinear, PatchTST
from utils.tools import EarlyStopping, adjust_learning_rate, visual, test_params_flop
from utils.metrics import metricimport numpy as np
import torch
import torch.nn as nn
from torch import optim
from torch.optim import lr_schedulerimport os
import timeimport warnings
import matplotlib.pyplot as plt
import numpy as npwarnings.filterwarnings('ignore')class Exp_Main(Exp_Basic):def __init__(self, args):super(Exp_Main, self).__init__(args)def _build_model(self):model_dict = {'Autoformer': Autoformer,'Transformer': Transformer,'Informer': Informer,'DLinear': DLinear,'NLinear': NLinear,'Linear': Linear,'PatchTST': PatchTST,}model = model_dict[self.args.model].Model(self.args).float()if self.args.use_multi_gpu and self.args.use_gpu:model = nn.DataParallel(model, device_ids=self.args.device_ids)return modeldef _get_data(self, flag):data_set, data_loader = data_provider(self.args, flag)return data_set, data_loaderdef _select_optimizer(self):model_optim = optim.Adam(self.model.parameters(), lr=self.args.learning_rate)return model_optimdef _select_criterion(self):criterion = nn.MSELoss()return criteriondef vali(self, vali_data, vali_loader, criterion):total_loss = []self.model.eval()with torch.no_grad():for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(vali_loader):batch_x = batch_x.float().to(self.device)batch_y = batch_y.float()batch_x_mark = batch_x_mark.float().to(self.device)batch_y_mark = batch_y_mark.float().to(self.device)# decoder inputdec_inp = torch.zeros_like(batch_y[:, -self.args.pred_len:, :]).float()dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)# encoder - decoderif self.args.use_amp:with torch.cuda.amp.autocast():if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)else:if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)f_dim = -1 if self.args.features == 'MS' else 0outputs = outputs[:, -self.args.pred_len:, f_dim:]batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)pred = outputs.detach().cpu()true = batch_y.detach().cpu()loss = criterion(pred, true)total_loss.append(loss)total_loss = np.average(total_loss)self.model.train()return total_lossdef train(self, setting):train_data, train_loader = self._get_data(flag='train')vali_data, vali_loader = self._get_data(flag='val')test_data, test_loader = self._get_data(flag='test')path = os.path.join(self.args.checkpoints, setting)if not os.path.exists(path):os.makedirs(path)time_now = time.time()train_steps = len(train_loader)early_stopping = EarlyStopping(patience=self.args.patience, verbose=True)model_optim = self._select_optimizer()criterion = self._select_criterion()if self.args.use_amp:scaler = torch.cuda.amp.GradScaler()scheduler = lr_scheduler.OneCycleLR(optimizer = model_optim,steps_per_epoch = train_steps,pct_start = self.args.pct_start,epochs = self.args.train_epochs,max_lr = self.args.learning_rate)for epoch in range(self.args.train_epochs):iter_count = 0train_loss = []self.model.train()epoch_time = time.time()for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(train_loader):iter_count += 1model_optim.zero_grad()batch_x = batch_x.float().to(self.device)batch_y = batch_y.float().to(self.device)batch_x_mark = batch_x_mark.float().to(self.device)batch_y_mark = batch_y_mark.float().to(self.device)# decoder inputdec_inp = torch.zeros_like(batch_y[:, -self.args.pred_len:, :]).float()dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)# encoder - decoderif self.args.use_amp:with torch.cuda.amp.autocast():if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)f_dim = -1 if self.args.features == 'MS' else 0outputs = outputs[:, -self.args.pred_len:, f_dim:]batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)loss = criterion(outputs, batch_y)train_loss.append(loss.item())else:if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark, batch_y)#print(outputs.shape,batch_y.shape)f_dim = -1 if self.args.features == 'MS' else 0outputs = outputs[:, -self.args.pred_len:, f_dim:]batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)loss = criterion(outputs, batch_y)train_loss.append(loss.item())if (i + 1) % 100 == 0:print("\titers: {0}, epoch: {1} | loss: {2:.7f}".format(i + 1, epoch + 1, loss.item()))speed = (time.time() - time_now) / iter_countleft_time = speed * ((self.args.train_epochs - epoch) * train_steps - i)print('\tspeed: {:.4f}s/iter; left time: {:.4f}s'.format(speed, left_time))iter_count = 0time_now = time.time()if self.args.use_amp:scaler.scale(loss).backward()scaler.step(model_optim)scaler.update()else:loss.backward()model_optim.step()if self.args.lradj == 'TST':adjust_learning_rate(model_optim, scheduler, epoch + 1, self.args, printout=False)scheduler.step()print("Epoch: {} cost time: {}".format(epoch + 1, time.time() - epoch_time))train_loss = np.average(train_loss)vali_loss = self.vali(vali_data, vali_loader, criterion)test_loss = self.vali(test_data, test_loader, criterion)print("Epoch: {0}, Steps: {1} | Train Loss: {2:.7f} Vali Loss: {3:.7f} Test Loss: {4:.7f}".format(epoch + 1, train_steps, train_loss, vali_loss, test_loss))early_stopping(vali_loss, self.model, path)if early_stopping.early_stop:print("Early stopping")breakif self.args.lradj != 'TST':adjust_learning_rate(model_optim, scheduler, epoch + 1, self.args)else:print('Updating learning rate to {}'.format(scheduler.get_last_lr()[0]))best_model_path = path + '/' + 'checkpoint.pth'self.model.load_state_dict(torch.load(best_model_path))return self.modeldef test(self, setting, test=0):test_data, test_loader = self._get_data(flag='test')if test:print('loading model')self.model.load_state_dict(torch.load(os.path.join('./checkpoints/' + setting, 'checkpoint.pth')))preds = []trues = []inputx = []folder_path = './test_results/' + setting + '/'if not os.path.exists(folder_path):os.makedirs(folder_path)self.model.eval()with torch.no_grad():for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(test_loader):batch_x = batch_x.float().to(self.device)batch_y = batch_y.float().to(self.device)batch_x_mark = batch_x_mark.float().to(self.device)batch_y_mark = batch_y_mark.float().to(self.device)# decoder inputdec_inp = torch.zeros_like(batch_y[:, -self.args.pred_len:, :]).float()dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)# encoder - decoderif self.args.use_amp:with torch.cuda.amp.autocast():if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)else:if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)f_dim = -1 if self.args.features == 'MS' else 0# print(outputs.shape,batch_y.shape)outputs = outputs[:, -self.args.pred_len:, f_dim:]batch_y = batch_y[:, -self.args.pred_len:, f_dim:].to(self.device)outputs = outputs.detach().cpu().numpy()batch_y = batch_y.detach().cpu().numpy()pred = outputs # outputs.detach().cpu().numpy() # .squeeze()true = batch_y # batch_y.detach().cpu().numpy() # .squeeze()preds.append(pred)trues.append(true)inputx.append(batch_x.detach().cpu().numpy())if i % 20 == 0:input = batch_x.detach().cpu().numpy()gt = np.concatenate((input[0, :, -1], true[0, :, -1]), axis=0)pd = np.concatenate((input[0, :, -1], pred[0, :, -1]), axis=0)visual(gt, pd, os.path.join(folder_path, str(i) + '.pdf'))if self.args.test_flop:test_params_flop((batch_x.shape[1],batch_x.shape[2]))exit()preds = np.array(preds)trues = np.array(trues)inputx = np.array(inputx)preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])trues = trues.reshape(-1, trues.shape[-2], trues.shape[-1])inputx = inputx.reshape(-1, inputx.shape[-2], inputx.shape[-1])# result savefolder_path = './results/' + setting + '/'if not os.path.exists(folder_path):os.makedirs(folder_path)mae, mse, rmse, mape, mspe, rse, corr = metric(preds, trues)print('mse:{}, mae:{}, rse:{}'.format(mse, mae, rse))f = open("result.txt", 'a')f.write(setting + " \n")f.write('mse:{}, mae:{}, rse:{}'.format(mse, mae, rse))f.write('\n')f.write('\n')f.close()# np.save(folder_path + 'metrics.npy', np.array([mae, mse, rmse, mape, mspe,rse, corr]))np.save(folder_path + 'pred.npy', preds)# np.save(folder_path + 'true.npy', trues)# np.save(folder_path + 'x.npy', inputx)returndef predict(self, setting, load=False):pred_data, pred_loader = self._get_data(flag='pred')if load:path = os.path.join(self.args.checkpoints, setting)best_model_path = path + '/' + 'checkpoint.pth'self.model.load_state_dict(torch.load(best_model_path))preds = []self.model.eval()with torch.no_grad():for i, (batch_x, batch_y, batch_x_mark, batch_y_mark) in enumerate(pred_loader):batch_x = batch_x.float().to(self.device)batch_y = batch_y.float()batch_x_mark = batch_x_mark.float().to(self.device)batch_y_mark = batch_y_mark.float().to(self.device)# decoder inputdec_inp = torch.zeros([batch_y.shape[0], self.args.pred_len, batch_y.shape[2]]).float().to(batch_y.device)dec_inp = torch.cat([batch_y[:, :self.args.label_len, :], dec_inp], dim=1).float().to(self.device)# encoder - decoderif self.args.use_amp:with torch.cuda.amp.autocast():if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)else:if 'Linear' in self.args.model or 'TST' in self.args.model:outputs = self.model(batch_x)else:if self.args.output_attention:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)[0]else:outputs = self.model(batch_x, batch_x_mark, dec_inp, batch_y_mark)pred = outputs.detach().cpu().numpy() # .squeeze()preds.append(pred)preds = np.array(preds)preds = preds.reshape(-1, preds.shape[-2], preds.shape[-1])# result savefolder_path = './results/' + setting + '/'if not os.path.exists(folder_path):os.makedirs(folder_path)np.save(folder_path + 'real_prediction.npy', preds)return
运行结果 (使用ETTh1数据集,跑的epoch=10的结果)

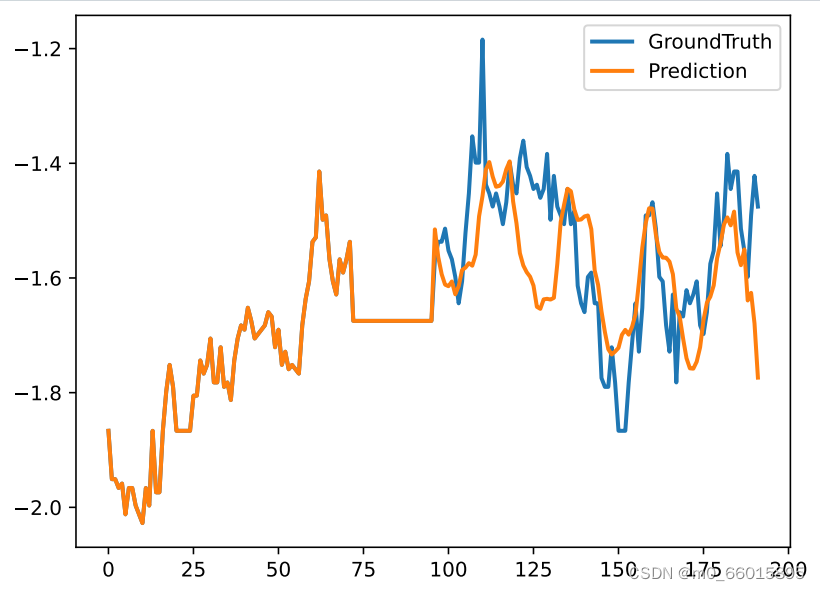
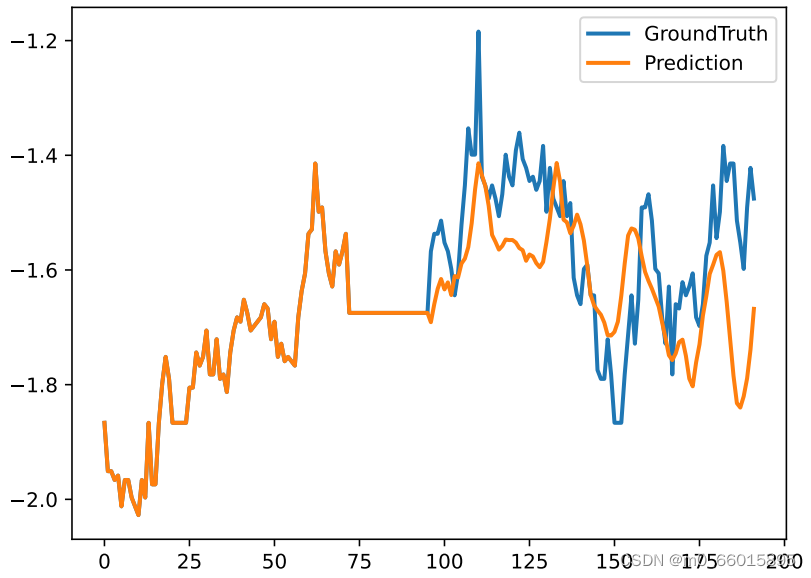
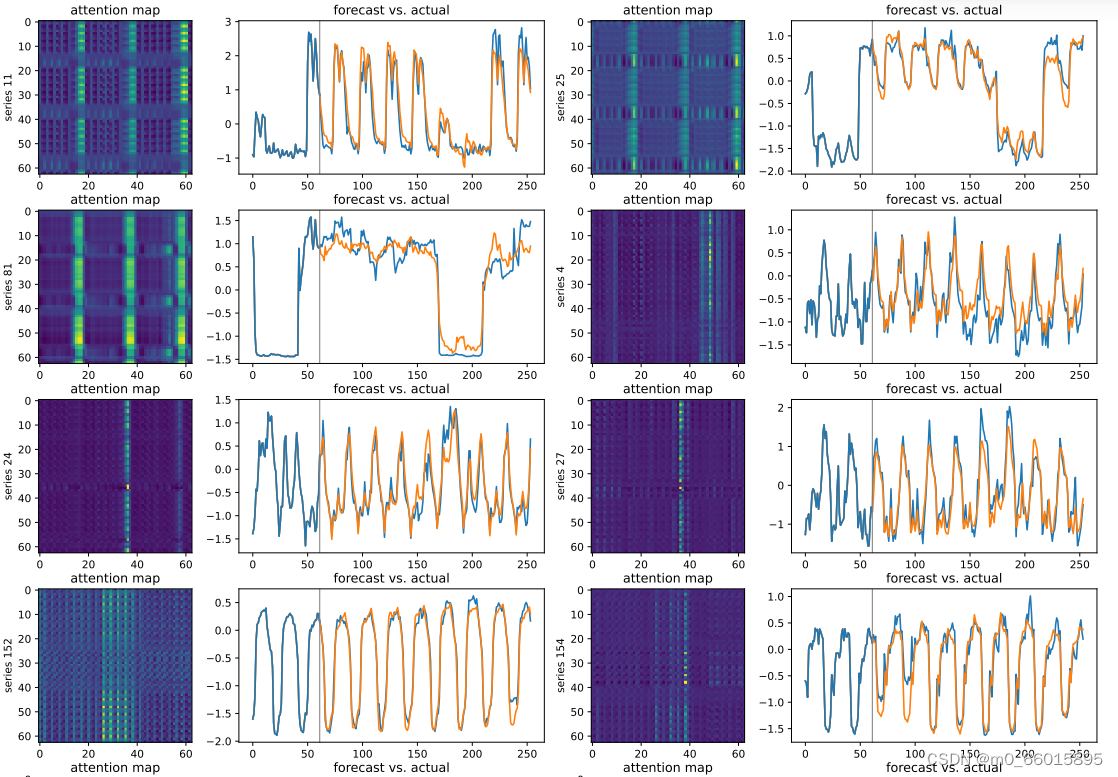
epoch设置10跑出来的MSE值相对较小,预测曲线拟合效果不是很好 ,epoch设置得太小。当使用电力数据集,epoch设置为128时跑出的结果很好。下图为注意力图和预测折现图
七、总结
PatchTST是一个基于Transformer的模型,通过引入时间序列分段和通道独立性两大创新策略,使用Patch来提取时间序列数据中的局部语义,这使得该模型的训练速度更快,并且有更长的输入窗口。显著提升了长期时间序列预测的准确性和效率。自我监督预训练进一步增强了模型的泛化能力,使得模型在多个数据集和任务上都达到了当前最优水平。而消融研究揭示了模型各部分设计的必要性和优势。
这篇关于五十八周:文献阅读的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!