本文主要是介绍【教学类-36-09】20240622钓鱼(通义万相)-A4各种大小的鱼,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

背景需求:
用通义万相获得大量的简笔画鱼的图片,制作成不同大小,幼儿用吸铁石钓鱼的纸片(回形针),涂色、排序等
补一张通义万相的鱼图
素材准备
(一)优质的鱼图片

(二)剔除的鱼(两个眼睛、很多鱼鳍、不是鱼的造型)

(三)模板

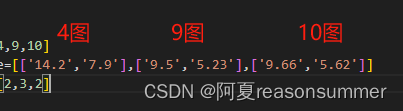
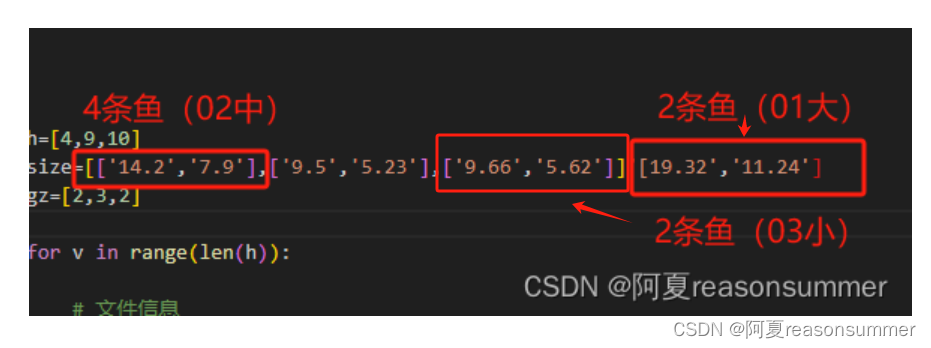
模板4条(14.2*7.9)
模板9条(9.5*5.23)
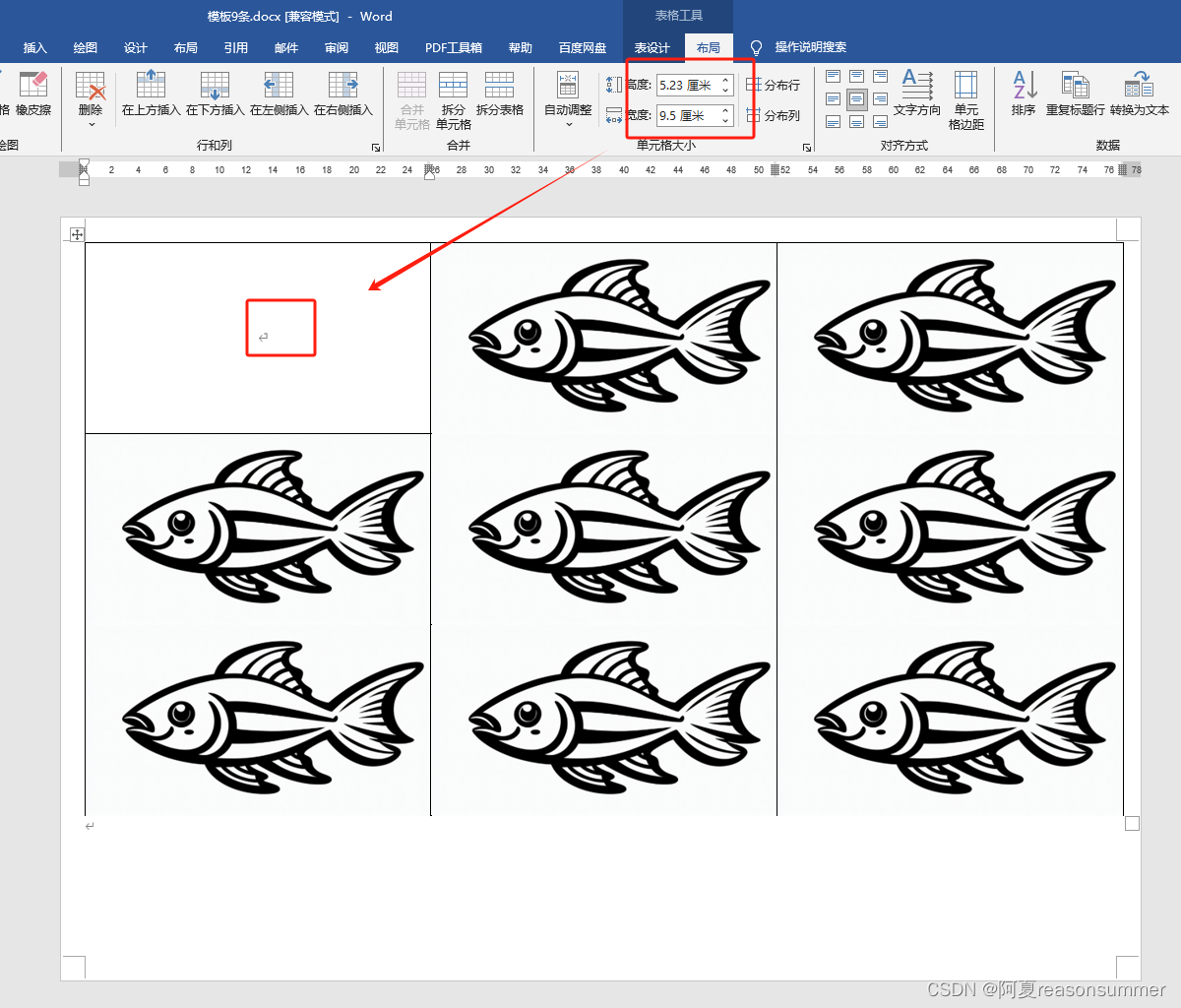

模板10条(9.66*5.62)

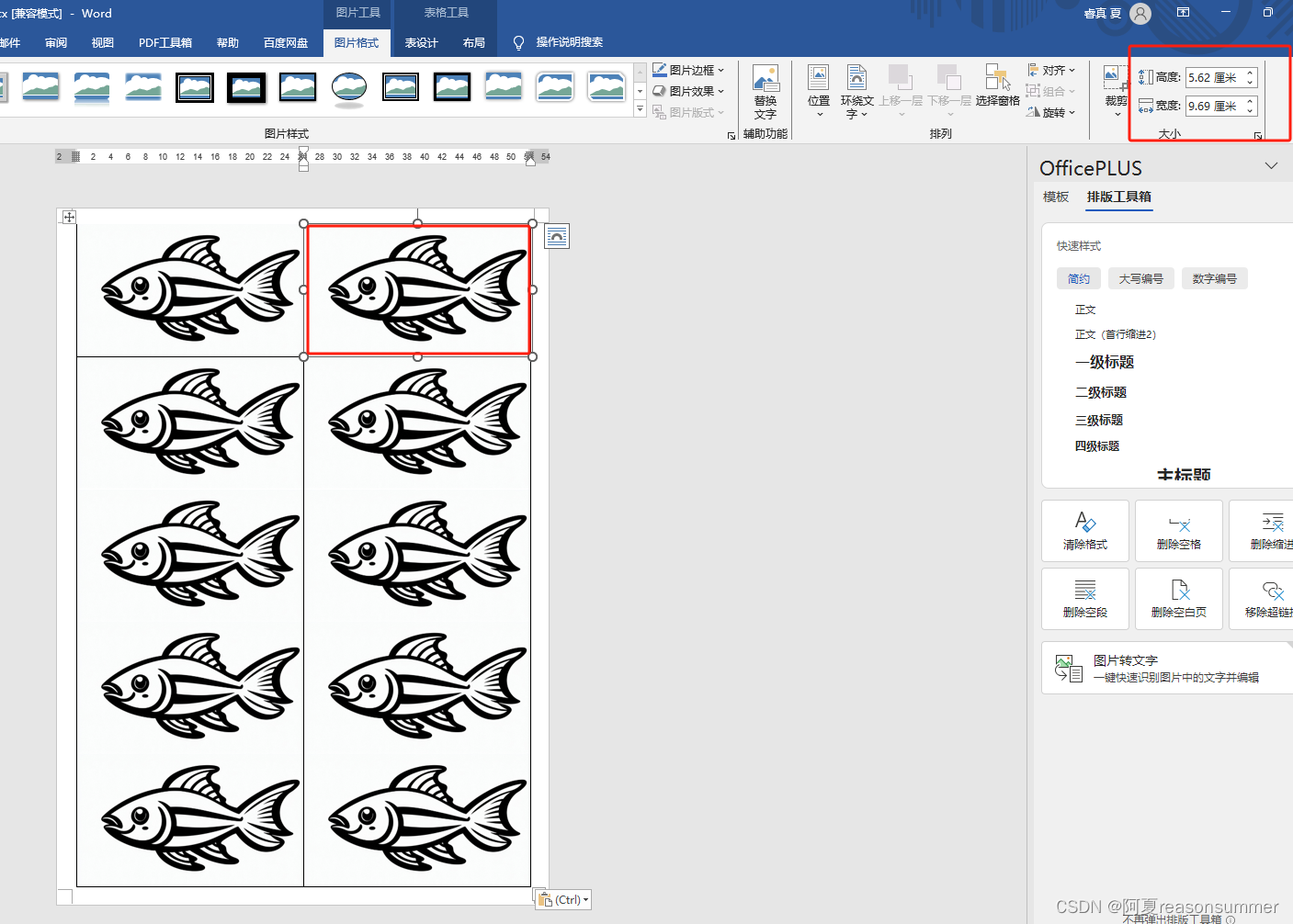
把模板里面的图片清空,
代码展示:
'''
02钓鱼(通义鱼类图片)3款模板,4张、9张、10张)
作者:AI对话大师,阿夏
2024年6月9日'''
import os
import time
from docx import Document
from reportlab.lib.pagesizes import letter
from reportlab.pdfgen import canvas
from PyPDF2 import PdfMerger
from docx.shared import Cm
import random, itertoolsh=[4,9,10]
size=[['14.2','7.9'],['9.5','5.23'],['9.66','5.62']]
gz=[2,3,2]for v in range(len(h)):# 文件信息path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20240618鱼'image_folder = path + r'\02鱼'new_folder = path + r'\零时文件夹'os.makedirs(new_folder, exist_ok=True)# 读取图片image_file = [os.path.join(image_folder, file) for file in os.listdir(image_folder) if file.endswith('.png')]image_files = random.sample(image_file, len(image_file))# 图片数量g=int(h[v])# 图片按照4张一组分割grouped_files = [image_files[i:i + g] for i in range(0, len(image_files), g)]print(len(grouped_files))# 处理每一组图片for group_index, group in enumerate(grouped_files):# 创建新的Word文档doc = Document(path+fr'\模板{g}条.docx')# print(group)# 遍历每个单元格,并插入图片for cell_index, image_file in enumerate(group):# 计算图片长宽(单位:厘米) # 插入图片到单元格table = doc.tables[0]cell = table.cell(int(cell_index / int(gz[v])), cell_index % int(gz[v]))# 如果第一行有4个格子,两个数字都写4cell_paragraph = cell.paragraphs[0]cell_paragraph.clear()run = cell_paragraph.add_run()run.add_picture(image_file, width=Cm(float(size[v][0])), height=Cm(float(size[v][1])))# 保存Word文档doc.save(os.path.join(new_folder, f'{group_index + 1:03d}.docx'))# 将N个docx转为PDFimport osfrom docx2pdf import convertfrom PyPDF2 import PdfFileMergerimport time pdf_output_path = path+fr'\\钓鱼{g}图.pdf'# 将所有DOCX文件转换为PDFfor docx_file in os.listdir(new_folder):if docx_file.endswith('.docx'):docx_path = os.path.join(new_folder, docx_file)convert(docx_path, docx_path.replace('.docx', '.pdf'))time.sleep(20) # 图片比较大,多保存几秒# 合并“零时文件”里所有PDF文件merger = PdfFileMerger()for pdf_file in os.listdir(new_folder):if pdf_file.endswith('.pdf'):pdf_path = os.path.join(new_folder, pdf_file)merger.append(pdf_path)# 保存合并后的PDF文件merger.write(pdf_output_path)time.sleep(10) # 图片比较大,多保存几秒merger.close()# 删除输出文件夹 import shutil shutil.rmtree(new_folder)结果
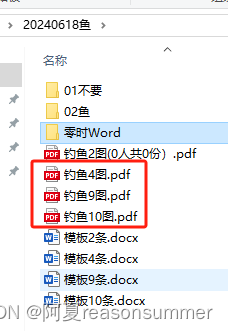
钓鱼4图:28张*4=112,实际110,所以空了2格
 钓鱼9图:13张*9=117,实际110,所以空了7格
钓鱼9图:13张*9=117,实际110,所以空了7格

钓鱼10图:11张*10=110,实际110,所以空了0格

我发现:9图和10图的尺寸大小差不多,所以只要大一套10图就可以了。
那么最好再做一套图片更大的模版。
于是我做了模版2条

效果是一页上两条不一样的大鱼,最下面10条格子里放两条不一样的小鱼。

代码展示
'''
02钓鱼(通义鱼类图片,模板2图(2个大图2个小图)
作者:AI对话大师,阿夏
2024年6月22日'''import osprint('----------第1步:提取所有的幼儿照片的路径------------')
# 文件信息
folder_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\20240618鱼'
ppp =folder_path + r'\02鱼'
qqq = folder_path+r'\零时Word'
os.makedirs(qqq , exist_ok=True)paths=[]
# 过滤:只保留png结尾的图片 31张(多几张备用)
imgs=os.listdir(ppp)
for img in imgs:if img.endswith(".png"):paths.append(ppp+'\\'+img)
# 所有图片的路径
print(paths)
# 提取动物名字倒数第4个字之前的动物名字
print(imgs)print('----------第3步:随机抽取12张图片 ------------')import docx
from docx import Document
from docx.shared import Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
from docx.oxml.ns import qn
import randomimport os,time
import docx
from docx import Document
from docx.shared import Inches,Cm,Pt
from docx.shared import RGBColor
from docx.enum.text import WD_PARAGRAPH_ALIGNMENT
# # from docx.enum.text import WD_VERTICAL_ALIGNMENT
# from docx.enum.table import WD_CELL_VERTICAL_ALIGNMENT #用来设置单元格垂直对齐方式
from docx.oxml.ns import qnfrom docxtpl import DocxTemplate
import pandas as pd
from docx2pdf import convert
from docx.shared import RGBColorpic=['00','10','20','21']
long=['19.32','19.32','9.66','9.66']
wide=['11.24','11.24','5.62','5.62']
# 每4个图片一组进行处理path=[]
grouped_files = [paths[i:i+2] for i in range(0, len(paths), 2)]
for g in grouped_files:p=g*2path.append(p)print(path)
print(len(path))
# 55for nn in range(0,int(len(path))): # 读取图片的全路径 的数量 31张doc = Document(folder_path+r'\模板2条.docx')table = doc.tables[0] # 4567(8)行for l in range(len(long)):# 单元格坐标a=int(pic[l][0])b=int(pic[l][1])figures=path[nn][l] # 图片的全路径的第一张
## 写入1张大图run=doc.tables[0].cell(a,b).paragraphs[0].add_run() # # 图片位置 第一个表格的0 3 插入照片run.add_picture(r'{}'.format(figures),width=Cm(float(long[l])),height=Cm(float(wide[l])))table.cell(a,b).paragraphs[0].alignment = WD_PARAGRAPH_ALIGNMENT.CENTER #居中 doc.save(qqq+r'\{}.docx'.format('%02d'%nn)) from docx2pdf import convert# docx 文件另存为PDF文件inputFile = qqq+fr'\{nn:02d}.docx' # 要转换的文件:已存在outputFile = qqq+fr'\{nn:02d}.pdf' # 要生成的文件:不存在# 先创建 不存在的 文件f1 = open(outputFile, 'w')f1.close()# 再转换往PDF中写入内容convert(inputFile, outputFile)print('----------第4步:把都有PDF合并为一个打印用PDF------------')# 多个PDF合并(CSDN博主「红色小小螃蟹」,https://blog.csdn.net/yangcunbiao/article/details/125248205)
import os
from PyPDF2 import PdfFileMerger
target_path = qqq
pdf_lst = [f for f in os.listdir(target_path) if f.endswith('.pdf')]
pdf_lst = [os.path.join(target_path, filename) for filename in pdf_lst]
pdf_lst.sort()
file_merger = PdfFileMerger()
for pdf in pdf_lst:print(pdf)file_merger.append(pdf)
file_merger.write(folder_path+fr"\钓鱼2图({len(path)}人共{len(path)}份).pdf")
file_merger.close()
# doc.Close()# print('----------第5步:删除临时文件夹------------')
import shutil
shutil.rmtree(qqq) #递归删除文件夹,即:删除非空文件夹

所以我准备打印三款大小的鱼
实际就打印两份:

1、考虑到幼儿的兴趣是钓鱼,所以鱼图片数量要多,(吸铁石瞬间就能吸走很多回形针)
2、图片数量多,为了节省纸张,就需要鱼小一点
(1)但图片太小,回形针不一定能卡上
(2)图片多,卡回形针需要很长时间(图片大点,让孩子们自己插回形针)
(3)而且图片小,容易满地碎纸。收拾不便利。
3、所以第一次实验,还是投放三种大小——19、14、9CM。
第一款19的(4图)26张,准备打印15张=60条
第二款14+9(2图*2)55张,准备打印20张=80条
合计140张。29平均每人5条
4、最好一次能钓完拿光,否则小碎片太多,我也没地方存放。
这篇关于【教学类-36-09】20240622钓鱼(通义万相)-A4各种大小的鱼的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






