本文主要是介绍监控 Promethus的监控告警Alertmanager、Grafana,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Promethus的监控告警Alertmanager
Alertmanager 介绍
- Prometheus的一个组件,用于定义和发送告警通知,内置多种第三方告警通知方式,同时还提供了对Webhook通知的支持
- 基于警报规则对规则产生的警报进行分组、抑制和路由,并把告警发送给合适的接收端,例如邮件、钉钉或Webhook
- 在Prometheus中一条告警规则组成
- 告警名称:用户需要为告警规则命名
- 告警规则:主要由PromQL进行定义,表示当表达式(PromQL)查询结果持续多长时 间(During)后出发告警
- 关键特点
- 分组:将详细的告警信息合并成一个通知,某些情况下,如由于系统宕机导致大量的告警被同时触发
- 抑制:当某一告警发出后,可以停止重复发送由此告警引发的其它告警的机制,避免告警轰炸
- 静默:根据标签对告警进行静默处理,如果接收到的告警符合静默的配置, Alertmanager则不会发送告警通知
Alertmanager安装
注意:记住这里的地址,后面告警需要配置这个地址
#下载
wget https://github.com/prometheus/alertmanager/releases/download/v0.27.0/alertmanager-0.27.0.linux-arm64.tar.gz
#解压
tar -zxvf alertmanager-0.27.0.linux-arm64.tar.gz
#重名名
mv alertmanager-0.27.0.linux-amd64 alertmanager# 进入目录
cd alertmanager#启动
./alertmanager --config.file=alertmanager.yml#守护进程方式启动
nohup ./alertmanager --config.file=alertmanager.yml &
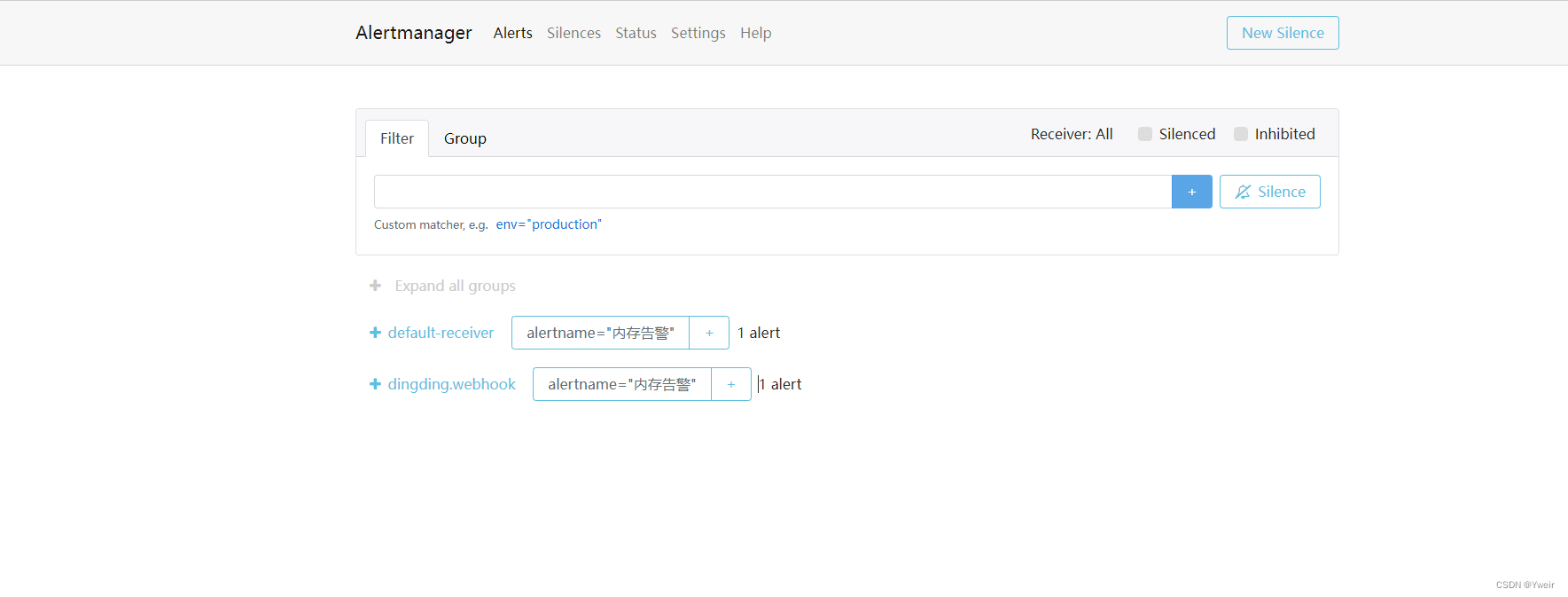
- 访问
http://ip:port, ,比如 http://47.115.61.73:9093/#/alerts
使用流程
-
步骤
- Prometheus的rules.yaml编写告警规则
- 配置Prometheus,定义在哪些情况下被告警
- 配置Alertmanager
- 添加Email、钉钉或者短信接收程序,为告警通知指定目标和通知媒介
- 建立告警路由
- 定义告警的路由方式,以便区分和分类告警级别,并为不同的告警目标设定不同的火灾通知方法。
- Prometheus的rules.yaml编写告警规则
-
关键配置解读
- Prometheus的
rule.yaml配置文件
- Prometheus的
groups: # 告警规则组
- name: server-alarmrules: #规则,可以配置多个alert告警- alert: # 告警名称expr: # 告警表达式,基于PromQL表达式告警触发条件,用于计算是否有时间序列满足该条件。for: # 评估等待时间,可选,用于表示只有当触发条件持续一段时间后才发送告警,在等待期间新产生告警 的状态为pending。labels: #自定义标签,允许用户指定要附加到告警上的一组附加标签。severity: # 告警严重程度annotations: #用于指定一组附加信息,比如用于描述告警详细信息的文字等summary: # 告警摘要description: # 告警详细描述- alert: "内存告警"expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes))) * 100 > 80for: 1mlabels:severity: warningannotations:summary: "{{$labels.instance}}: 检测到 高内存 使用率!"description: "{{$labels.instance}}: 内存使用率在 80% 以上 (当前使用值为:{{ $value }})"- alert: "CPU告警"expr: (1 - avg(irate(node_cpu_seconds_total{mode="idle"}[2m])) by(instance)) * 100 > 80for: 1mlabels:severity: warningannotations:summary: "{{$labels.instance}}: 检测到 高CPU 使用率!"description: "{{$labels.instance}}: CPU使用率在 80% 以上 (当前使用值为:{{ $value }})"
-
severity有以下几种常用值
- critical(严重),用于描述影响系统主要功能甚至导致系统崩溃的情况。
- warning(警告),用于描述存在异常但不会导致系统崩溃或停止服务的情况。
- info(信息),用于描述与业务正常运行相对应的正常状态信息。
- debug(调试),用于描述可以用于排除故障的调试信息。
-
Alertmanager的alertmanager.yml配置文件- 主要包含两个部分:路由(
route) + 接收器(receivers)- 告警信息会从配置中的顶级路由(route)进入路由树,根据路由规则将告警信息发送给相应的接收器
- 主要包含两个部分:路由(
global:smtp_smarthost: 'smtp.126.com:25' # SMTP服务器地址和端口smtp_from: 'xxxxx@126.com' # 显示在邮件“发件人”字段中的地址smtp_auth_username: 'xxxx@126.com' # STMP认证时使用的用户名smtp_auth_password: 'xxxxxx' # SMTP认证时使用的密码,不是密码smtp_require_tls: false # SMTP服务器是否需要TLS加密route:receiver: 'email' # 发送告警通知的收件人,和下面的接受者名称匹配group_wait: 10s # 在发送前等待各个警报的时间group_interval: 30s # 相同警报名称的警报发送间隔repeat_interval: 10m # 重复发送警报的时间间隔group_by: ['alertname'] # 根据警报名分组告警接收者# 告警接收者
receivers:
- name: 'email' # 接收者名称email_configs:- to: 'xxxxxx@qq.com' # 接收告警邮件的收件人
Alertmanager监控告警和邮件通知
需求
- 应用程序监控,如果应用程序挂了,触发邮件发送开发人员
Prometheus板块配置
- 配置Prometheus的rule告警规则
#创建配置文件 prometheus程序目录下
touch rules.yml
#配置规则
groups:
- name: server-alarmrules:- alert: "InstanceDown"expr: up == 0for: 1mlabels:severity: warningannotations:summary: "{{ $labels.instance }}"description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 1 minutes."
- 配置Prometheus关联Alertmanager地址和rules规则启用
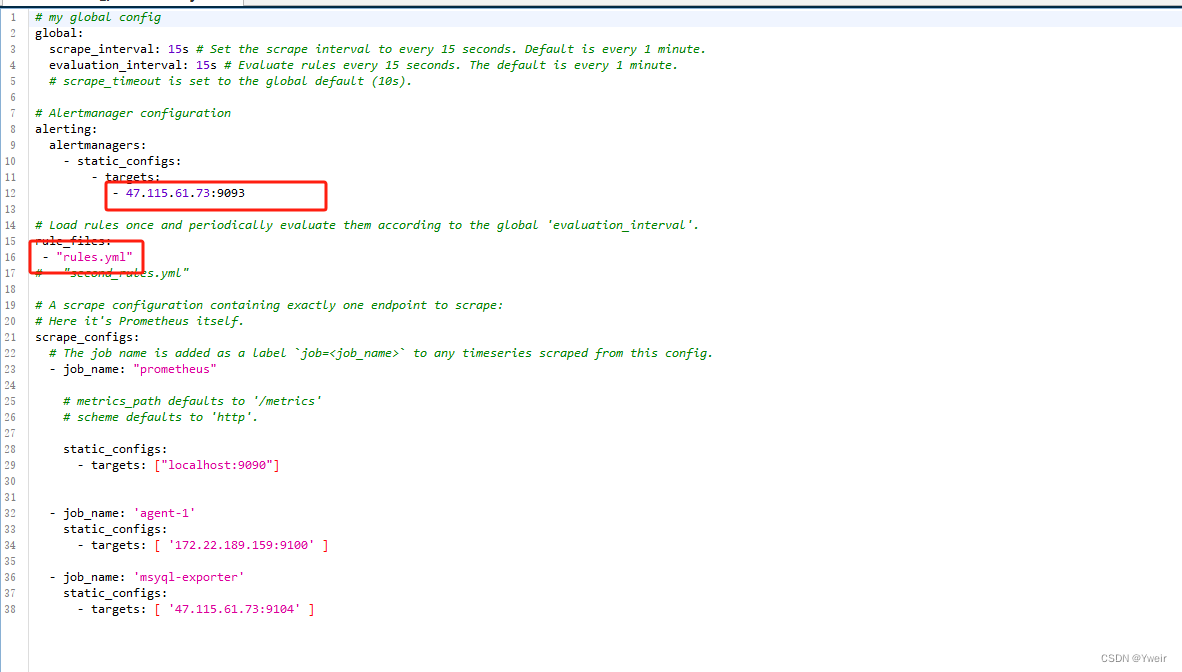
- 动态更新Prometheus配置
注意:Prometheus 需要开启支持热更新
curl -X POST http://localhost:9090/-/reload
Alertmanager板块配置
- alertmanager.yml 配置文件(如果测试服务是在阿里云,需要将25端口(被禁用)改成其它的)
# 第一个版本
global:smtp_smarthost: 'smtp.126.com:465'smtp_from: 'xxxxx@126.com'smtp_auth_username: 'xxxxx@126.com'smtp_auth_password: 'xxxx'smtp_require_tls: falseroute:receiver: 'dingding.webhook'group_wait: 10sgroup_interval: 30srepeat_interval: 10mgroup_by: ['alertname', 'cluster', 'service']routes:- receiver: 'dingding.webhook'continue: true- receiver: 'default-receiver'receivers:- name: 'default-receiver'email_configs:- to: 'xxxxx@qq.com'send_resolved: true- name: 'dingding.webhook'webhook_configs:- url: 'https://oapi.dingtalk.com/robot/send?access_token=xxxx'send_resolved: true
# 第二个版本
global:smtp_smarthost: 'smtp.126.com:25' # SMTP服务器地址和端口smtp_from: 'xxxxx@126.com' # 显示在邮件“发件人”字段中的地址smtp_auth_username: 'xxxx@126.com' # STMP认证时使用的用户名smtp_auth_password: 'xxxxxx' # SMTP认证时使用的密码,不是密码smtp_require_tls: false # SMTP服务器是否需要TLS加密route:receiver: 'email' # 发送告警通知的收件人,和下面的接受者名称匹配group_wait: 10s # 在发送前等待各个警报的时间group_interval: 30s # 相同警报名称的警报发送间隔repeat_interval: 10m # 重复发送警报的时间间隔group_by: ['alertname'] # 根据警报名分组告警接收者# 告警接收者
receivers:
- name: 'email' # 接收者名称email_configs:- to: 'xxxxxx@qq.com' # 接收告警邮件的收件人
应用和验证步骤
- 应用
#启动
./alertmanager --config.file=alertmanager.yml#守护进程方式启动
nohup ./alertmanager --config.file=alertmanager.yml &
- 验证步骤
- 停止spring boot程序(停止其他服务都可以)
- 查看prometheus
- 查看alertmanager
- 查看邮件
Grafana+钉钉群告警机器人
前言
- Alertmanager告警和Grafana告警功能,两个组件各有优缺点
- Grafana更适合于小规模或简单的监控系统,而Alertmanager更适合于大规模或更复杂的告警处理场景
- 如果需要高级告警规则和复杂的告警逻辑,请使用Alertmanager
- 如果仅需要基本的告警功能并且已经使用Grafana进行数据可视化,则可以使用Grafana作为告警处理工具
Alertmanager、Grafana对比
- Grafana
- 优点
- 简单易用,Grafana的告警规则配置界面直观易懂,可以方便地设置告警的触发条件、持续时间和通知方式等
- 定制性强,Grafana的告警规则支持自定义查询和指标,使得监控系统的告警范围更加广泛
- 能够对告警事件进行统计和可视化处理,在Grafana中可以方便地对告警事件进行统计,同时还可以进行实况监控和定期报告等操作
- 缺点
- 不支持高级告警逻辑。Grafana只能识别基于简单算术或表达式的逻辑,无法支持更复杂的逻辑
- 设计初衷不是作为告警处理工具,Grafana更多地是作为数据可视化工具
- 核心功能是数据分析和展示,并不是专门的告警处理工具,因此不太适合大规模或复杂的告警处理场景
- 可扩展性不够,无法满足比较复杂、高级的告警规则设计
- 优点
- Alertmanager
- 优点
- 提供高级告警逻辑功能,支持许多常用的高级告警逻辑,如静默、抑制和聚合等
- 支持多通道分发告警,支持将告警通知分发到多个通道,如电子邮件,短信等,能够满足不同场景下的需求
- 可靠性高,提供多种保护机制,如去重、失败重试和自动恢复,确保告警能够可靠地传送给相应的接收方
- 支持高度可扩展性,可以与各种 monitoring system 集成使告警触发进一步个性
- 缺点
- 复杂和难以部署,Alertmanager的配置比Grafana更复杂,需要深入了解监控系统和告警系统
- 学习成本高,Alertmanager需要学习更多的知识和技能才能掌握
- 不善于定义静态监控告警,对于 Dashboard 监控告警,它可能不太适合
- 优点
需求
- 使用Grafana的alert告警模块,内存告警
- 配置自动告警机器人,如果内存超过一定范围,推送到钉钉群
实现步骤
-
创建钉钉告警机器人,获取webhook地址
- webhook地址:
https://oapi.dingtalk.com/robot/send?access_token=xxxx - Postman 验证消息推送是否准确
- 钉钉机器人相关地址:https://open.dingtalk.com/document/robots/custom-robot-access
- webhook地址:
-
Grafana新建推送通道
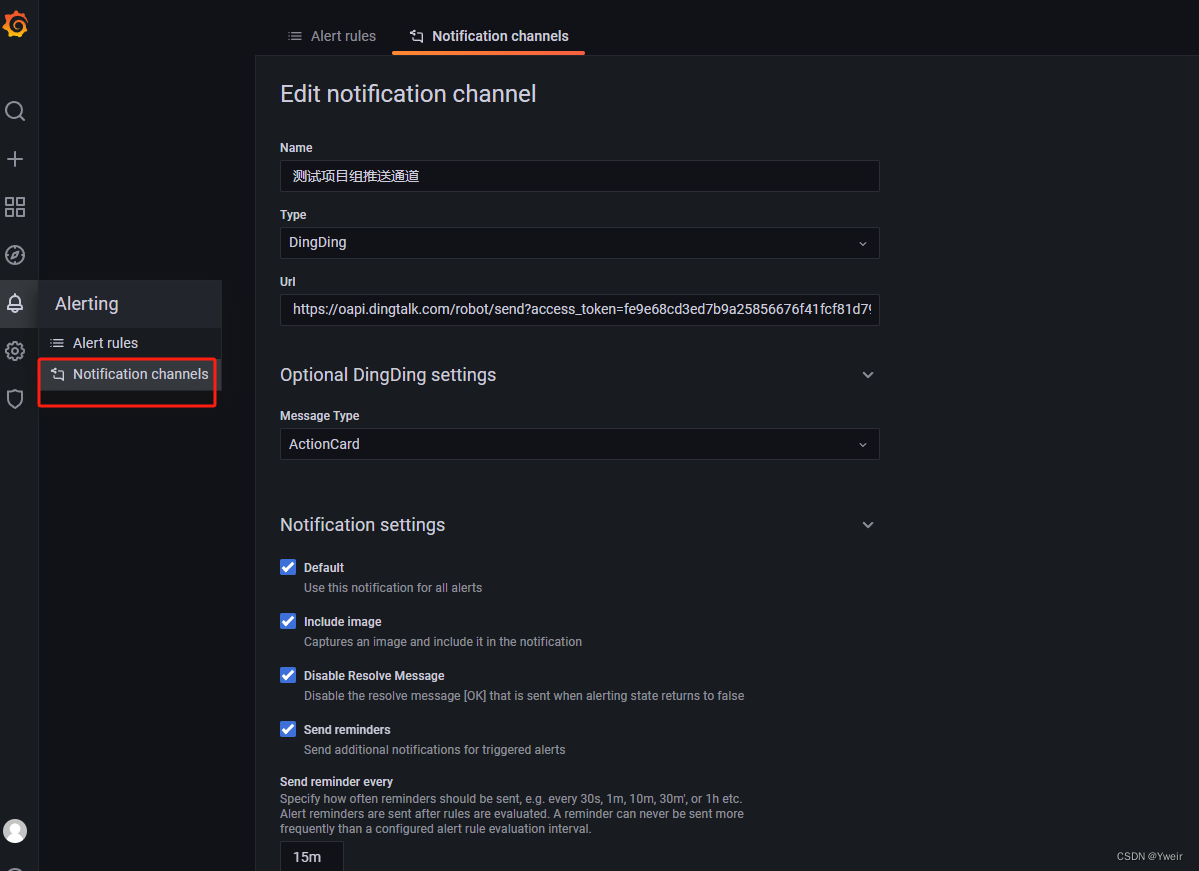
-
面板Panel配置告警规则

告警流程验证
- 停止应用服务器
- 查看prometheus相关监控(可以停止Alert Manager)
- 查看Grafana相关告警
- 查看钉钉群机器人是否推送(记得配置ip白名单)
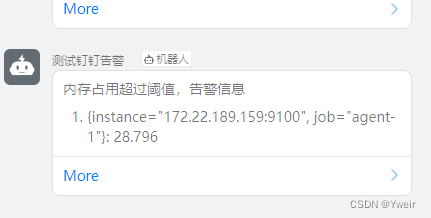
问题修复
- 点击群告警信息没法直接进到告警页面
- 解决方案
- 配置默认跳转路径,使用root用户进入容器修改配置文件
docker exec -u 0 -it #{容器id/容器名称} /bin/bash
#使用该-u选项时,可以使用root用户(ID = 0)而不是提供的默认用户登录Docker容器.root(id = 0)是容器中的默认用户
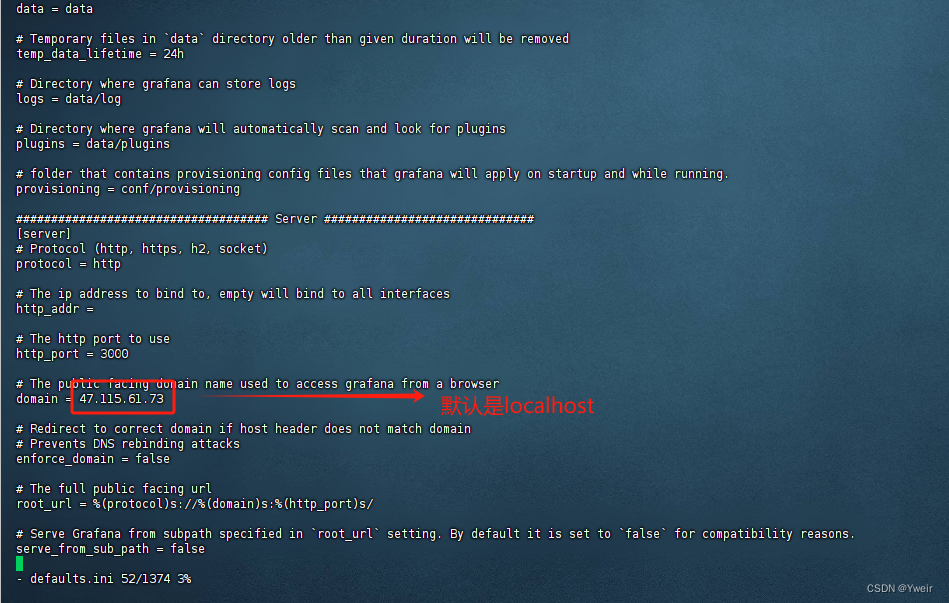
- 编辑配置文件,修改为Grafana的部署地址,然后重启

这篇关于监控 Promethus的监控告警Alertmanager、Grafana的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!