本文主要是介绍python判断目标网页编码,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
第一种是使用requests模块下载网页后会得到一个response对象,通过response对象的apparent_encoding方法可以获得目标网页的编码:
import requests
url = 'http://news.ifeng.com/a/20180311/56636409_0.shtml'
resp = requests.get(url)
resp.apparent_encoding输出:
'utf-8'
第二种是使用chardet模块的detect方法:
import requests
import chardet
url = 'http://news.ifeng.com/a/20180311/56636409_0.shtml'
resp = requests.get(url)
chardet.detect(resp.text.encode('utf8')).get('encoding')输出:
'utf-8'
以上编程环境为Python2
第三种
使用requests.utils.get_encoding_from_headers,或者requests.utils.get_encodings_from_content
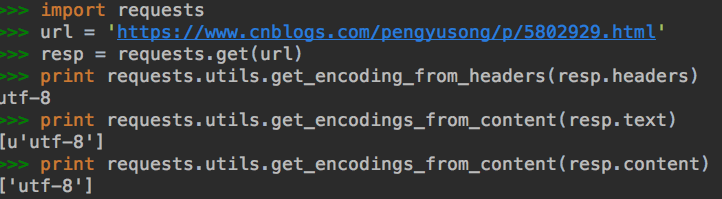
相比于前两种方法,如果加入logging模块并设置log的级别为debug的时候,第三种方法不会打印过多的log信息
这篇关于python判断目标网页编码的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!