本文主要是介绍AI大眼萌探索 AI 新世界:Ollama 使用指南【1】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在人工智能的浪潮中,Ollama 的出现无疑为 Windows 用户带来了一场革命。这款工具平台以其开创性的功能,简化了 AI 模型的开发与应用,让每一位爱好者都能轻松驾驭 AI 的强大力量。大家好,我是AI大眼萌,今天我们将带大家了解这款工具平台。
🤖 什么是 Ollama?
Ollama 不仅仅是一个 AI 和 ML (Machine Learning)工具平台,它是技术社区中的一股清流,以其直观高效的工具,让 AI 模型的开发变得触手可及。无论是资深专家还是新手,都能在 Ollama 上找到自己的舞台。
🌟Ollama优势
在 AI 工具的海洋中,Ollama 以其独特优势脱颖而出:
- 🔧 自动硬件加速:智能识别并利用最优硬件资源,简化配置,提升效率。
- 🚫 无需虚拟化:告别复杂环境配置,直接投身于 AI 项目的开发。
- 📚 接入丰富模型库:从 Lamma3到 qwen2,Ollama 的模型库应有尽有。
- 🔗 Ollama 的常驻 API:简化 AI 功能与项目对接,提升工作效率。
🛠️ Ollama Windows使用指南
下面是如何在 Windows 上使用 Ollama 的详细指南:
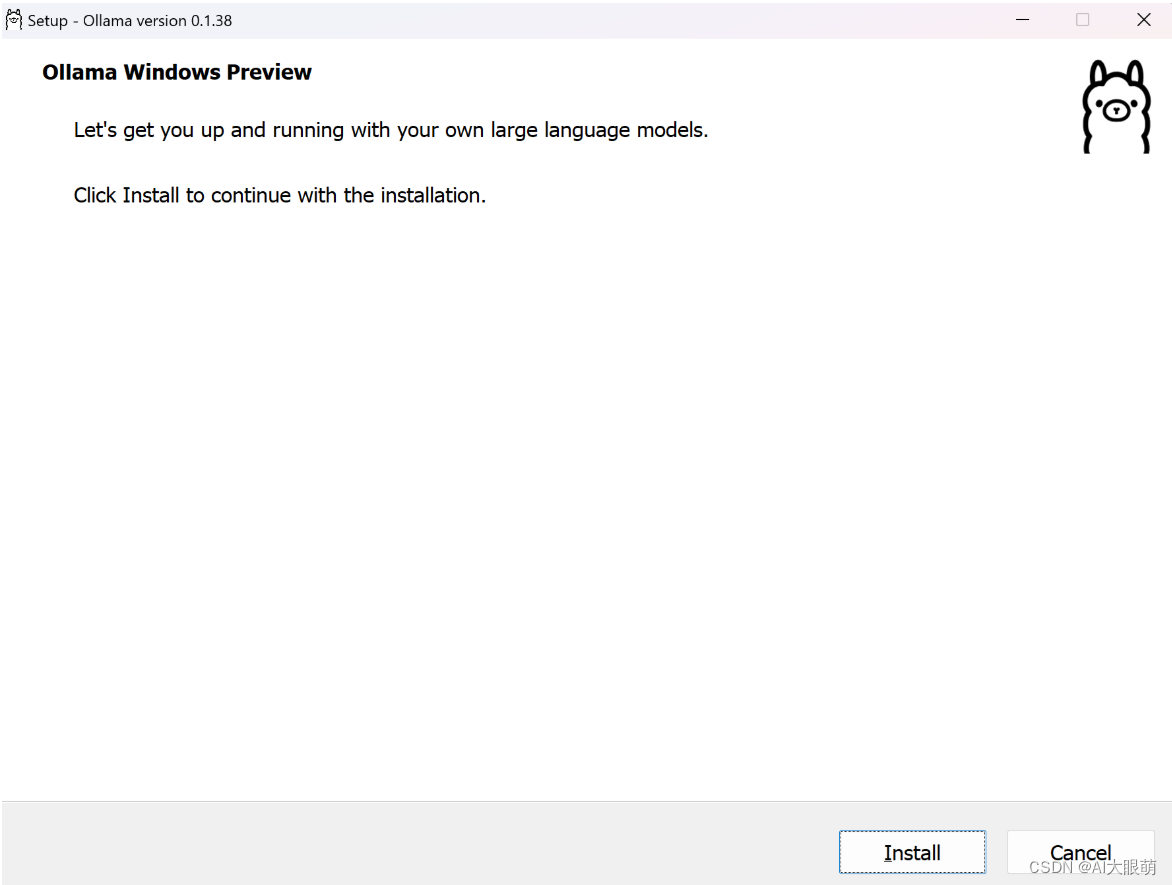
步骤 1:下载与安装
-
访问 Ollama Windows Preview页面,下载安装程序。
-
双击运行,一键安装。
步骤 2:启动与模型获取
-
启动 Ollama
Usage:ollama [flags]ollama [command] Available Commands:serve Start ollamacreate Create a model from a Modelfileshow Show information for a modelrun Run a modelpull Pull a model from a registrypush Push a model to a registrylist List modelsps List running modelscp Copy a modelrm Remove a modelhelp Help about any command启动ollama服务: ollama serve -
使用命令行加载模型,开始你的 AI 之旅。
ollama run [modelname] ollama run gemma:2b
执行以上命令后,Ollama 将开始初始化,并自动从 Ollama 模型库中拉取并加载所选模型。一旦准备就绪,就可以向它发送指令,它会利用所选模型来进行理解和回应。

- 记得将
modelname名称换成要运行的模型名称,常用的有:
| Model | Parameters | Size | Download |
|---|---|---|---|
| Qwen2 7B | 7B | 4.5G | ollama run qwen:7b |
| Qwen2 72B | 72B | 41G | ollama run qwen:72b |
| Llama 3 | 8B | 4.7GB | ollama run llama3 |
| Llama 3 | 70B | 40GB | ollama run llama3:70b |
| Phi 3 Mini | 3.8B | 2.3GB | ollama run phi3 |
| Phi 3 Medium | 14B | 7.9GB | ollama run phi3:medium |
| Gemma | 2B | 1.4GB | ollama run gemma:2b |
| Gemma | 7B | 4.8GB | ollama run gemma:7b |
| Mistral | 7B | 4.1GB | ollama run mistral |
| Moondream 2 | 1.4B | 829MB | ollama run moondream |
| Neural Chat | 7B | 4.1GB | ollama run neural-chat |
| Starling | 7B | 4.1GB | ollama run starling-lm |
| Code Llama | 7B | 3.8GB | ollama run codellama |
| Llama 2 Uncensored | 7B | 3.8GB | ollama run llama2-uncensored |
| LLaVA | 7B | 4.5GB | ollama run llava |
| Solar | 10.7B | 6.1GB | ollama run solar |
模型存储在哪里?如需更换地点,可以参考环境配置章节
- macOS: ~/.ollama/models
- Linux: /usr/share/ollama/.ollama/models
- Windows: C:\Users\%username%\.ollama\models
步骤 3:模型应用
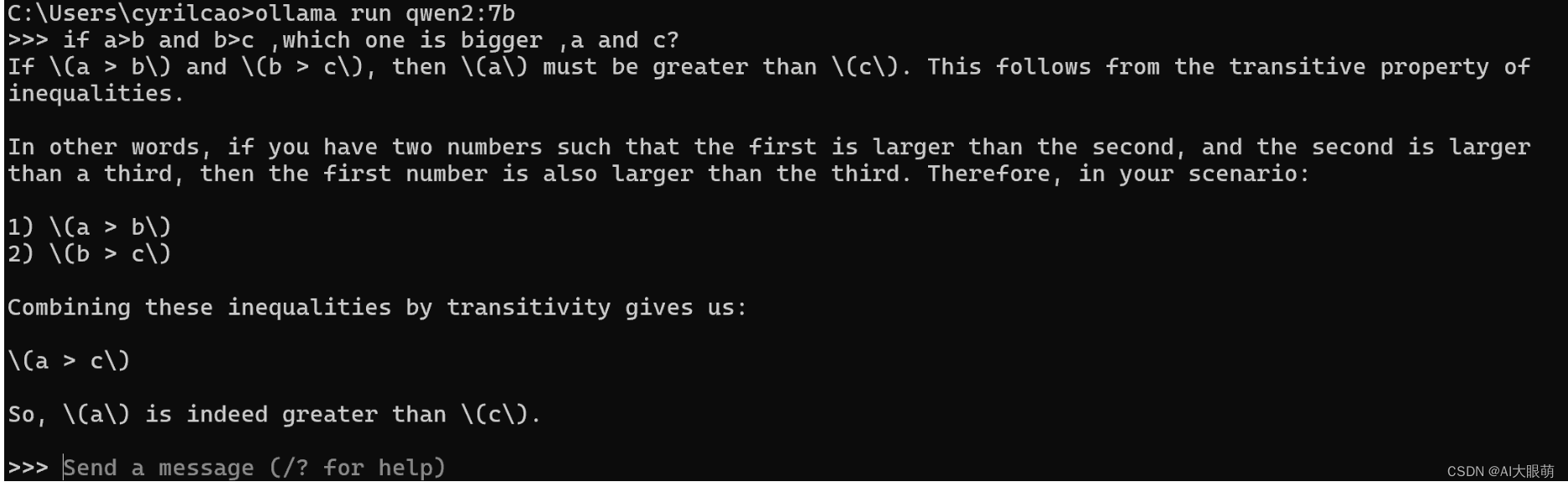
步骤 4:API 连接
将 AI 功能整合到你的应用中,Ollama API 是关键。
默认端口为11434

Ollama Linux 使用指南
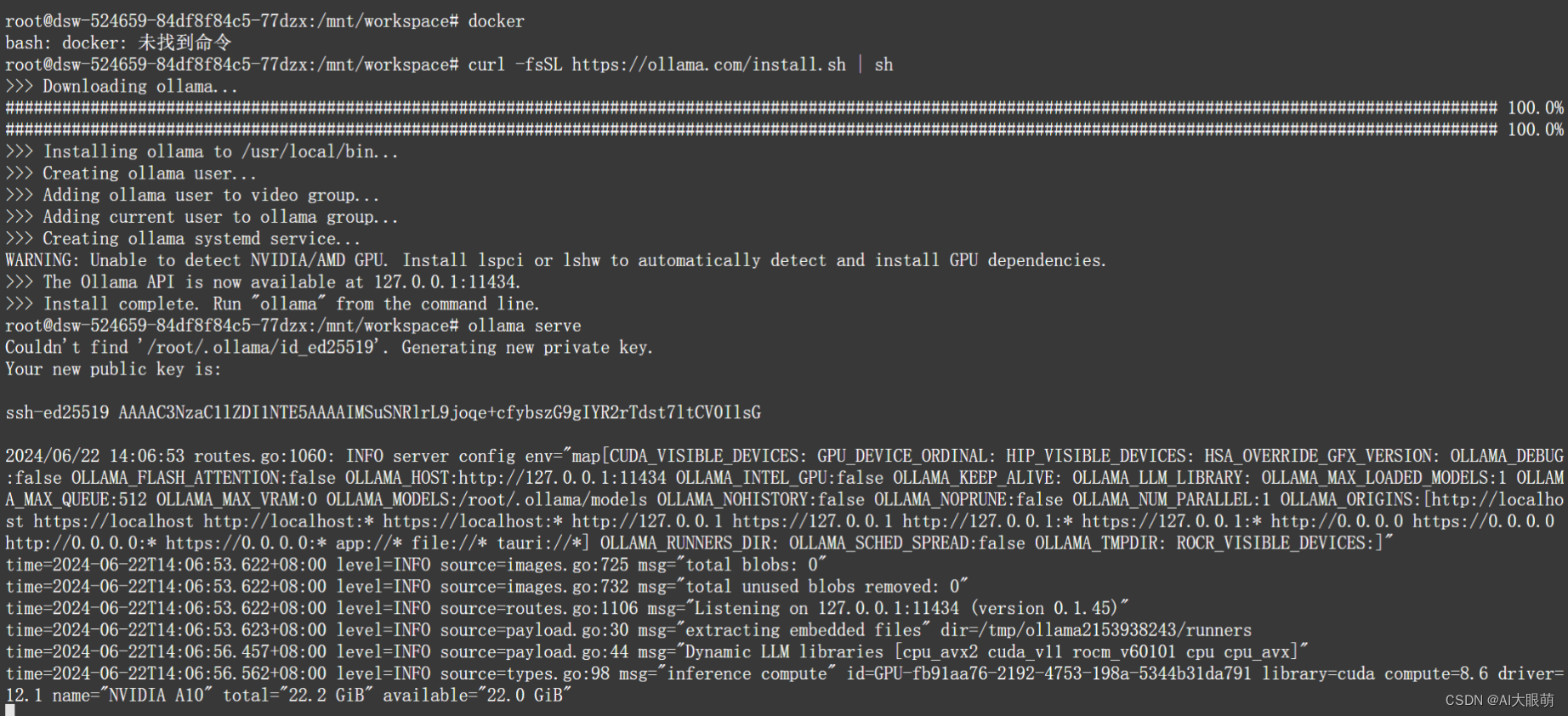
步骤 1:下载与安装
curl -fsSL https://ollama.com/install.sh | sh
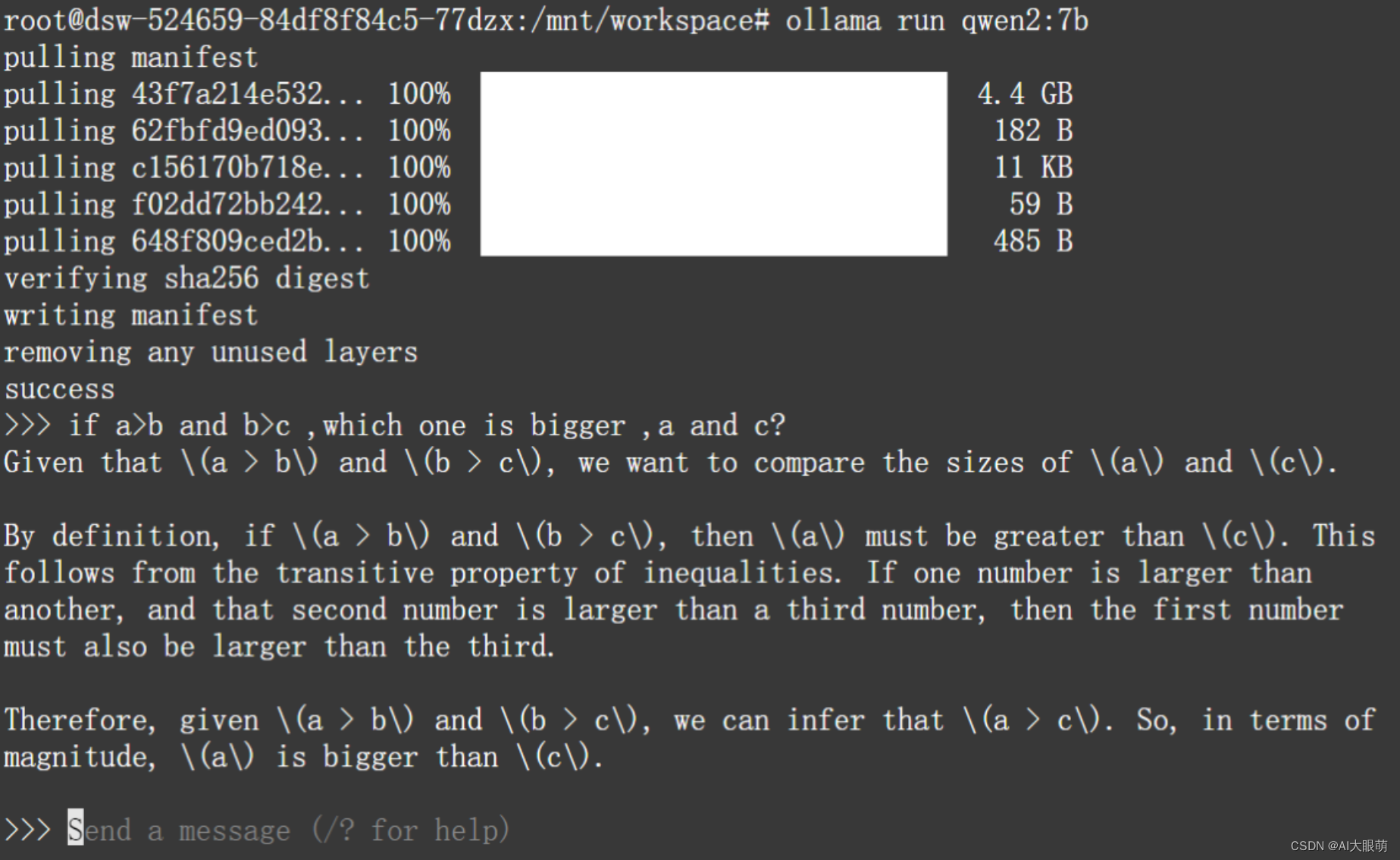
步骤 2:启动与模型获取
ollama serve
ollama run [modelname]
步骤 3与4: 与之前一致。
Ollama 环境变量设置
在Linux上设置环境变量
如果Ollama作为systemd服务运行,通过systemctl设置环境变量:
-
使用systemctl edit ollama.service命令编辑systemd服务,将打开一个编辑器。
-
对每个环境变量,在[Service]部分添加一行Environment:
-
[Service]
Environment="OLLAMA_HOST=:8000"#要更改侦听地址和端口,可以环境变量: -
保存并退出。
-
重新加载systemd并重启Ollama:
systemctl daemon-reload
systemctl restart ollama
在Windows上设置环境变量
在Windows上,Ollama会继承您的用户和系统环境变量。
1. 首先通过任务栏图标退出Ollama,
2. 从控制面板编辑系统环境变量,
3. 为OLLAMA_HOST、OLLAMA_MODELS等编辑或新建变量。a、要更改侦听地址和端口,可以添加以下环境变量:变量名:OLLAMA_HOST变量值(端口)::8000b、要更为debug模式,可以添加以下环境变量:变量名:OLLAMA_DEBUG变量值(端口):1 c、模型存储位置要更为指定路径变量名:OLLAMA_MODELS变量值(端口):指定的路径
4. 点击OK/Apply保存,
使用代理服务器访问Ollama?
Ollama运行一个HTTP服务器,可以通过代理服务器,比如Nginx,进行公开。具体操作方法是配置代理转发请求,并可选设置所需的头部(如果不在网络上公开Ollama)。例如,使用Nginx配置如下:
server {listen 80;server_name 192.168.70.1; location / {proxy_pass http://localhost:11434;proxy_set_header Host localhost:11434;}}
使用python调用ollama
1、安装依赖库
pip install ollama langchain_community langchain 2、测试代码
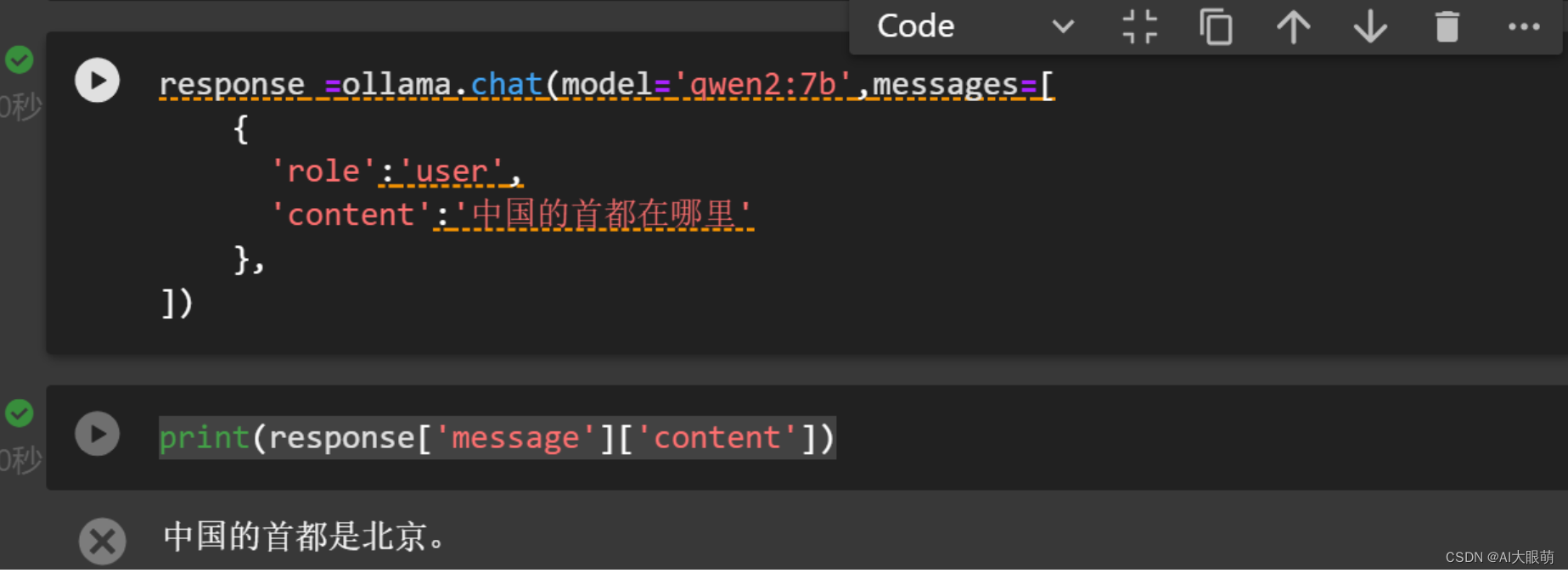
import ollama
response =ollama.chat(model='qwen2:7b',messages=[{'role':'user','content':'中国的首都在哪里'},
])
print(response['message']['content'])
3、简单的人机交互界面
import ollama
def get_completion(prompt):response =ollama.chat(model='qwen2:7b',messages=[{'role':'user','content':prompt},])return response['message']['content'].strip()while True:user_input = input("你: ")if user_input.lower() == '退出':print("聊天结束。")breakprint("\n机器人: 正在处理你的请求...")response = get_completion(user_input)print("机器人:", response)
结语
通过本教程,我们学习了 Ollama的简单安装与使用,让我们一起探索、实践、创新!
如果您发现这篇文章对您有所启发或帮助, 请不吝赐赞,为我【点赞】、【转发】、【关注】,带你一起玩转AI !
全网ID|AI大眼萌
这篇关于AI大眼萌探索 AI 新世界:Ollama 使用指南【1】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






