本文主要是介绍人工智能在影像组学与放射组学中的最新进展|顶刊速递·24-06-22,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
小罗碎碎念
本期文献速递的主题——人工智能在影像组学中的最新进展。
小罗一直以来的观点,是把大问题分模块拆解——既然我们想做多模态,那么就先了解单模态的研究套路,再去研究不同模态提取的特征如何融合,搞科研的过程也是管理人才,管理自己的过程。
我是罗小罗同学,明天见!!

一、评估人工智能(AI)系统通过MRI检测前列腺癌方面的性能,并与传统的放射科医生使用前列腺成像-报告和数据系统进行比较

文献概述
这篇文章的目的是评估人工智能(AI)系统在通过MRI检测前列腺癌方面的性能,并与传统的放射科医生使用前列腺成像-报告和数据系统(PI-RADS 2.1)进行比较。
研究团队训练并外部验证了一个AI系统,用于检测Gleason评分2组或更高级别的癌症。
研究使用了10207例来自9129名患者的回顾性MRI检查队列。其中,9207例来自荷兰的三个中心(11个地点)的案例用于训练和调整,1000例来自荷兰和挪威的四个中心(12个地点)的案例用于测试。与此同时,研究还组织了一个多读者、多案例的观察者研究,涉及62名放射科医生(来自20个国家的45个中心),他们使用PI-RADS 2.1对测试队列中的400对MRI检查进行了评估。
研究的主要终点是AI系统的敏感性、特异性以及接收者操作特征曲线下面积(AUROC)与所有使用PI-RADS 2.1的读者以及多学科常规实践中的历史放射学读数(即标准护理)进行比较。使用组织病理学和至少3年(中位数5年)的随访来建立参考标准。统计分析计划是预先设定的,主要假设是AI系统的非劣效性(考虑0.05的边界),如果确认非劣效性,则进行AI系统的优越性测试。
研究发现,在400个测试案例的子集中,AI系统显示出统计上优越且非劣的AUROC为0.91(95% CI 0.87–0.94;p<0.0001),与62名放射科医生的AUROC 0.86(0.83–0.89)相比,AUROC差异的双侧95% Wald CI的下限为0.02。
在所有读者的平均PI-RADS 3或更高操作点,AI系统在相同的特异性下检测到6.8%更多的Gleason评分2组或更高级别的癌症案例,或者在相同的敏感性下减少了50.4%的假阳性结果和20.0%的Gleason评分1组癌症案例。在所有1000个测试案例中,AI系统与多学科实践中的放射学读数相比,未能确认非劣效性,因为AI系统在相同的敏感性(96.1%,94.0–98.2)下显示出较低的特异性(68.9% [95% CI 65.3–72.4] vs 69.0% [65.5–72.5])。
研究解释为AI系统在检测临床意义的前列腺癌方面平均优于使用PI-RADS 2.1的放射科医生,并且与标准护理相当。这样的系统显示出在初级诊断设置中作为支持工具的潜力,为患者和放射科医生带来多种相关好处。需要进行前瞻性验证来测试该系统在临床应用中的可行性。
重点关注
AI系统与放射科医生在诊断临床显著前列腺癌方面的表现对比。

(A) 接收者操作特征曲线(Receiver Operating Characteristic Curve, ROC Curve)显示了AI系统和62位放射科医生在400个测试案例上的诊断性能。这些案例用于促进读者研究。每位放射科医生的PI-RADS操作点用浅灰色的圆圈、星号和三角形标记表示。对角虚线代表了随机分类器的ROC曲线,其AUROC(曲线下面积)为0.50,这是一个没有诊断能力的分类器的表现。
(B) 第二个ROC曲线展示了AI系统和在多学科常规实践中进行的放射学读数的PI-RADS操作点,考虑了所有1000个测试案例。同样,对角虚线代表了随机分类器的ROC曲线,AUROC为0.50。
© 展示了AI系统与62位放射科医生在AUROC度量上的差值,这是基于400个测试案例的子集,这些案例用于促进读者研究。这个度量表明了AI系统与放射科医生平均表现的差异。
(D) 当AI系统的阈值调整以匹配多学科常规实践中放射学读数的PI-RADS 3或更高操作点的相同敏感性(96.1%)时,展示了特异性的差异。这是基于所有1000个测试案例的考虑。如果AI系统的特异性与放射科医生的表现相当或更好,这将表明AI系统在减少假阳性诊断方面具有潜在的优势。
从这些图表中可以得出结论,AI系统在诊断临床显著的前列腺癌方面表现出了与经验丰富的放射科医生相当的或更优越的性能。特别是在AUROC的比较上,AI系统显示出较高的值,这表明它在敏感性和特异性之间取得了更好的平衡。
此外,调整阈值后的特异性比较也显示了AI系统在减少不必要的生物活检方面可能具有潜在的优势。然而,这些结果需要通过前瞻性验证来进一步测试其临床应用性。
二、一项关于鼻咽癌诱导化疗疗效预测的研究

文献概述
这篇文章是一项关于鼻咽癌(Nasopharyngeal Carcinoma, NPC)诱导化疗(Induction Chemotherapy, IC)疗效预测的研究。
研究目的是通过血浆代谢组学分析建立一个预测分类器,以预测IC对晚期NPC患者的疗效。
研究设计为一项双向临床试验,共纳入166名接受IC治疗的NPC患者。使用1H-NMR技术在IC治疗前后获取血浆脂蛋白谱,并通过人工智能辅助的放射组学方法有效评估疗效。通过基于机器学习的方法在发现队列中识别代谢生物标志物,并在模拟现实世界最不利情况的验证队列中进行验证。
研究发现,IC的疗效在不同患者间存在差异,并且与代谢物谱的变化相关。利用机器学习技术,特别是XGB模型,显示出显著的预测效果,其下曲线面积(Area Under the Curve, AUC)值达到0.792。在验证队列中,模型显示出强大的稳定性和泛化能力,AUC值为0.786。
研究结果表明,血浆脂蛋白的失调可能导致NPC患者对IC的耐药性,并且基于血浆代谢物谱构建的预测模型具有良好的预测能力和现实世界泛化潜力。这项发现对治疗策略的发展以及提高IC疗效的潜在靶点提供了见解。
研究还讨论了IC在治疗晚期NPC中的矛盾效果,强调了识别个体患者反应的重要性,以及如何利用AI辅助方法评估肿瘤负担,并识别与IC疗效相关的生物标志物。研究结果有助于开发更精确的预测模型,为临床治疗决策提供支持,并可能改善患者的生活质量。
重点关注
评估诱导化疗(IC)疗效的工作流程。

以下是对该流程的分析:
-
图像数据收集:在IC治疗前后,收集患者的磁共振成像(MRI)和计算机断层扫描(CT)图像数据。如果图像数据缺失或质量较低,则将其排除在外。
-
图像处理:使用PV-iRT自动化目标勾画系统对收集到的成像数据进行处理。PV-iRT系统用于半自动地勾画出包含肿瘤和淋巴结的兴趣区域(ROI)。
-
3D模型构建:将勾画好的ROI转换为三维(3D)模型。这些模型能够更直观地展示肿瘤和淋巴结的空间结构。
-
体积计算:通过基于体素的分析方法计算肿瘤和淋巴结的体积。体素是构成3D模型的最小单元,通过计算体素数量可以得到肿瘤和淋巴结的体积。
-
肿瘤负担评估:通过上述步骤得到的3D模型和体积数据,评估每位患者当前条件下的肿瘤负担。
-
疗效评估:通过比较治疗前后肿瘤负担的变化来评估IC的疗效。具体来说,计算治疗前后肿瘤体积的变化率,这通常通过以下公式来表示:
TBRR (Tumor Burden Reduction Ratio) = ( Initial Tumor Burden Volume − Final Tumor Burden Volume Initial Tumor Burden Volume ) × 100 % \text{TBRR (Tumor Burden Reduction Ratio)} = \left( \frac{\text{Initial Tumor Burden Volume} - \text{Final Tumor Burden Volume}}{\text{Initial Tumor Burden Volume}} \right) \times 100\% TBRR (Tumor Burden Reduction Ratio)=(Initial Tumor Burden VolumeInitial Tumor Burden Volume−Final Tumor Burden Volume)×100%
其中,TBRR大于12.6%的患者被认为是对IC敏感的,TBRR小于0%的患者被认为是对IC有抵抗性的,而TBRR在0%至12.6%之间的患者被认为是对IC无反应的。
整个流程利用先进的影像技术和自动化工具,提高了评估IC疗效的准确性和效率。通过这种方法,研究人员能够更精确地量化治疗效果,并为患者提供个性化的治疗决策支持。
三、使用深度学习算法预测前列腺癌在主动监测期间的分级重分类

文献概述
这篇文章是关于使用深度学习(Deep Learning, DL)算法来预测前列腺癌(Prostate Cancer, PCa)在主动监测(Active Surveillance, AS)期间的分级重分类的研究。
研究使用了一种名为AIRAProstate的DL算法,对两个独立的PCa AS队列中的初始前列腺活检样本进行了重新分级。研究发现,与当代泌尿病理学家的评估相比,AIRAProstate算法在预测AS期间的分级重分类方面表现更好。
- 研究背景:前列腺癌的分级是管理PCa的关键,特别是在AS环境中。近年来,基于DL的算法已经被开发出来,用于识别整个幻灯片图像(Whole Slide Images, WSIs)上的Gleason模式,并与泌尿病理学家确定的分级进行比较进行验证。
- 研究目的:评估DL分级算法在AS患者风险分层中的性能,通过分析算法确定的初始前列腺活检的分级与随后AS的临床结果之间的关联。
- 研究方法:研究分析了在约翰霍普金斯大学使用AS管理的两个独立队列的患者。比较了当代泌尿病理学家为这些患者初始前列腺活检分配的分级与DL算法确定的分级,并评估了两组分级与随后AS期间分级重分类的关联。
- 研究结果:
- 在最初使用系统活检诊断为GG1 PCa的队列中(n=138),AIRAProstate将初始活检升级为≥GG2与AS期间快速或极端分级重分类相关联(比值比3.3,p=0.04),而当代泌尿病理学家的评估则没有显示出这种关联。
- 在进行前列腺磁共振成像(MRI)的当代验证队列中(n=169),AIRAProstate将初始活检(所有由泌尿病理学家分级为GG1)升级为≥GG2与AS期间的分级重分类相关联(风险比1.7,p=0.03)。
- 结论:DL算法在预测AS期间的PCa分级重分类方面具有实用性,可能有助于标准化PCa分级并改善AS的风险分层。
- 研究限制:研究的局限性包括其回顾性性质和单一机构设计。研究的优势包括使用了两个特征鲜明的独立AS队列,一个来自MRI时代之前,一个来自MRI时代,每个队列评估了不同的临床结果。
重点关注
表1提供了在病例对照AS队列(N=138)中,单变量和多变量逻辑回归分析的结果,用以评估快速或极端的前列腺癌分级重分类的影响因素。

以下是对表中数据的分析:
-
Uropathologist Consensus GG for Initial Biopsy(初始活检的泌尿病理学家共识分级):
- 在单变量回归中,GG1被用作参照组(排除)。
- GG2或更高分级在单变量回归中与快速或极端分级重分类的比值比(OR)为1.69,但不具有统计学意义(P=.39)。
-
AIRAProstate GG for Initial Biopsy(初始活检的AIRAProstate分级):
- 同样,GG1作为参照组。
- GG2或更高分级在单变量回归中的OR为5.53,具有统计学意义(P=.001),表明使用AIRAProstate算法对初始活检样本进行分级与快速或极端分级重分类显著相关。
- 在多变量回归模型中,调整了其他已知的AS预后因素后,OR降至3.33,但仍然具有统计学意义(P=.04)。
-
Year of Biopsy(活检年份):
- 活检年份每增加一年,快速或极端分级重分类的风险比在单变量和多变量模型中均显著增加,表明近年来活检的患者重分类风险更高。
-
Age at Biopsy(活检时年龄):
- 活检时年龄每增加一岁,与重分类风险呈负相关,但这种关系在多变量模型中不显著。
-
Race(种族):
- 黑人患者的重分类风险在单变量模型中显著高于其他种族,但在多变量模型中不再显著。
-
PSA Density(PSA密度):
- PSA密度每增加0.1 ng/mL^2,与重分类风险的关系在所有模型中均不显著。
-
Number of Positive Biopsy Cores(阳性活检核心数):
- 阳性活检核心数每增加一个,与重分类风险的关系在单变量模型中不显著,但在多变量模型中没有提供数据。
-
Maximum Percent Core Involvement(最大核心受累百分比):
- 核心受累百分比每增加10%,在单变量和多变量模型中均与重分类风险显著相关。
-
Underwent mpMRI before Biopsy(活检前是否进行mpMRI):
- 在活检前进行多参数磁共振成像(mpMRI)与重分类风险的关系在所有模型中均不显著。
表中的“P values <.05 are marked in bold”说明P值小于0.05的结果被认为是统计学上显著的,并以粗体显示。多变量模型的Harrell’s concordance statistic值接近1表示模型预测的准确性较高,0.81和0.82表明模型具有较好的预测能力。
总的来说,表1显示AIRAProstate算法在预测前列腺癌分级重分类方面可能比泌尿病理学家的共识分级更为有效,且活检年份和核心受累的百分比是影响重分类风险的重要因素。
四、使用基于影像组学的方法预测脑转移瘤患者在接受术后立体定向放疗后的局部控制情况

文献概述
这篇文章是一项关于使用基于影像组学的方法预测脑转移瘤患者在接受术后立体定向放疗后的局部控制情况的研究。
研究的目的是开发并验证一个预治疗的影像组学工具,以识别具有高局部失败(LF)风险的患者。
研究包括来自多中心分析的**253名患者(两个中心的训练队列)和99名患者(五个中心的外部测试队列)**的数据。从对比增强的脑转移瘤(T1-CE MRI序列)及其周围水肿(FLAIR序列)中提取影像组学特征,并比较了不同的影像组学和临床特征组合。最终模型在训练队列中通过内部5折交叉验证确定的最佳参数进行训练,并在外部测试集上进行测试。
研究结果显示,结合影像组学和临床特征的弹性网回归模型在外部测试中表现最佳,一致性指数(CI)为0.77,超过了任何仅使用临床特征的模型(最佳CI为0.70)。该模型有效地通过Kaplan-Meier分析(p < 0.001)对患者按LF风险进行了分层,并展示了增量的净临床效益。在24个月时,低风险和高风险组的LF发生率分别为9%和74%。
研究的结论是,结合临床和影像组学特征的预测模型比单独使用任何临床特征集更好。高风险LF患者可能从更严格的随访程序或强化治疗中受益。研究强调了多模态数据分析在这一挑战性任务中的潜力,并可能通过根据个体的局部失败风险定制随访和治疗来改善脑转移瘤患者的管理。
研究还指出,尽管结果有前景,但存在一些限制,包括模型仅使用有限数量的特征,以及需要一致质量的分割。此外,研究还提到了使用自动生成的分割作为完全自动化工作流程的可行性。最后,研究提供了一个易于使用的网络应用程序,用户可以上传所需的MRI序列和分割或输入之前提取的影像组学特征。
重点关注
研究中用于开发预测模型的关键步骤
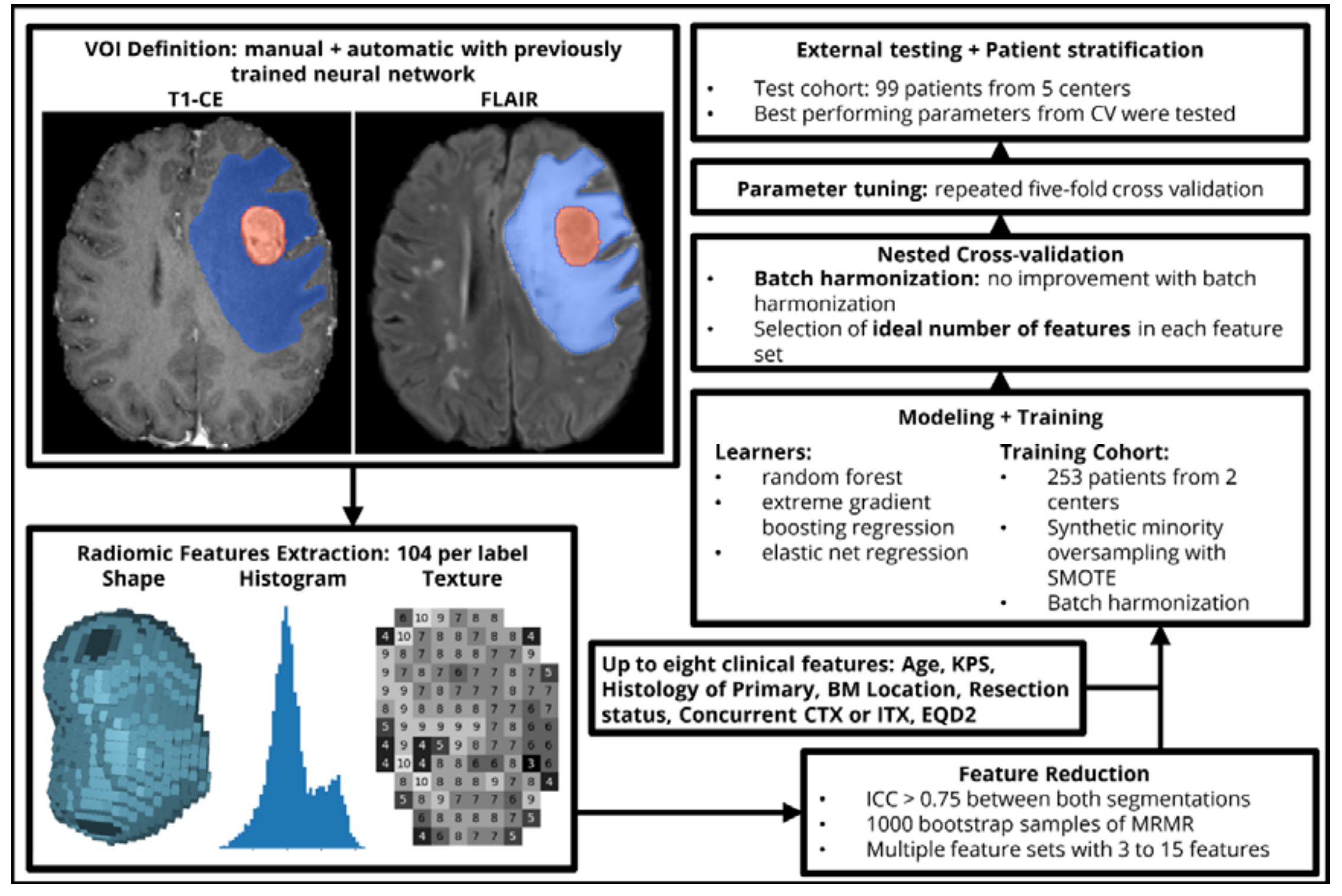
具体包括以下几个环节:
-
定义兴趣体积(VOI):无论是手动还是自动,首先定义了需要分析的脑部转移瘤和水肿的体积区域。
-
特征提取:从每个转移瘤和水肿的分割图像中提取了104个原始影像组学特征。这些特征可能包括图像的纹理、形状和信号强度分布等定量属性。
-
特征数量减少:使用最小冗余-最大相关性(MRMR)方法来减少每组特征的数量。MRMR是一种特征选择技术,旨在选择出既相关又不会彼此重复的特征,以提高模型的性能并减少复杂性。
-
临床特征的整合:在影像组学特征的基础上,研究者还添加了多达8个临床特征。这些临床特征可能包括患者的年龄、性别、病史等信息。
-
特征集的组合:将影像组学特征与临床特征结合,形成了多个不同的特征集,以探索它们对预测结果的贡献。
-
特征数量的优化:使用嵌套交叉验证来确定每个特征集中最优的特征数量。嵌套交叉验证是一种模型选择方法,可以更稳健地评估不同特征数量组合的性能。
-
学习器参数的选择:基于5折交叉验证来选择最优的学习器参数。交叉验证是一种统计方法,用于评估并提高模型的预测性能,通过将数据集分成几个子集进行训练和验证。
-
外部测试队列的验证:使用外部测试队列来测试每个学习器-特征组合的最佳参数。这是为了验证模型在新的、独立的数据集上的泛化能力。
这个过程展示了一个系统的方法来开发和验证一个预测模型,其中包括了特征的提取、优化和临床验证,确保了模型的准确性和可靠性。
五、一种新型的人工智能(AI)框架,用于从腹部计算机断层扫描(CT)图像中进行器官分割和肿瘤检测

文献概述
这篇文章是关于一种新型的人工智能(AI)框架,用于从腹部计算机断层扫描(CT)图像中进行器官分割和肿瘤检测。
主要贡献和特点:
- 通用性和可扩展性:该框架能够处理多个公共数据集,并能够适应新类别(例如器官/肿瘤)。
- 语言驱动的参数生成器:利用大型语言模型的语言嵌入来丰富语义编码,与传统的一位有效编码相比,能够更好地捕捉器官和肿瘤之间的语义关系。
- 类特定的输出层:用轻量级、类特定的头(class-specific heads)替代传统的输出层,允许模型同时分割25个器官和六种肿瘤类型,并简化新增类别的流程。
- 训练和测试:在3410个CT体积上训练,并在来自四个外部数据集的6173个CT体积上进行测试。
- 性能:在医学分割十项全能(Medical Segmentation Decathlon, MSD)公共排行榜上的六项CT任务中取得第一名,并在Beyond The Cranial Vault (BTCV)数据集上展现出领先的性能。
- 计算效率:比特定数据集模型快6倍,且在不同医院的数据上展现出强大的泛化能力,能够很好地转移到多个下游任务,并且在学习新类别的同时减轻了对之前学习类别的灾难性遗忘。
相关工作:文章还讨论了器官分割和肿瘤检测的相关研究,包括深度学习技术、基于 Transformer 的模型,以及增量学习等。
方法论:
- 问题定义:学习一个统一的多器官分割模型来处理部分标记的数据集。
- CLIP驱动的通用模型:包含语言分支和视觉分支,利用大型语言模型的嵌入作为语义编码的新方法。
- 优化:使用二元交叉熵和二元Dice损失函数进行监督。
实验:
- 在MSD和BTCV数据集上进行了广泛的实验,证明了所提出框架的有效性。
- 对比其他部分标记学习方法,使用MOTS数据集作为基准。
- 对于肿瘤检测,评估了在五个数据集上的性能,使用敏感性和特异性进行评估。
结论:文章提出了一个新颖的多器官分割和肿瘤检测框架,通过将语言嵌入与分割模型相结合,实现了一个灵活强大的分割器。实验结果验证了CLIP驱动的通用模型在效率、泛化能力、迁移能力和可扩展性方面的重要临床优势。
此外,作者还讨论了当前工作的局限性,并提出了未来的研究方向,如多模态集成、语言嵌入的优化,以及未标记区域的利用等。
重点关注
Fig. 1 提供了对持续CLIP驱动的通用模型(continual CLIP-Driven Universal Model)的概述,该模型是基于14个公共数据集的3410个CT体积开发的。
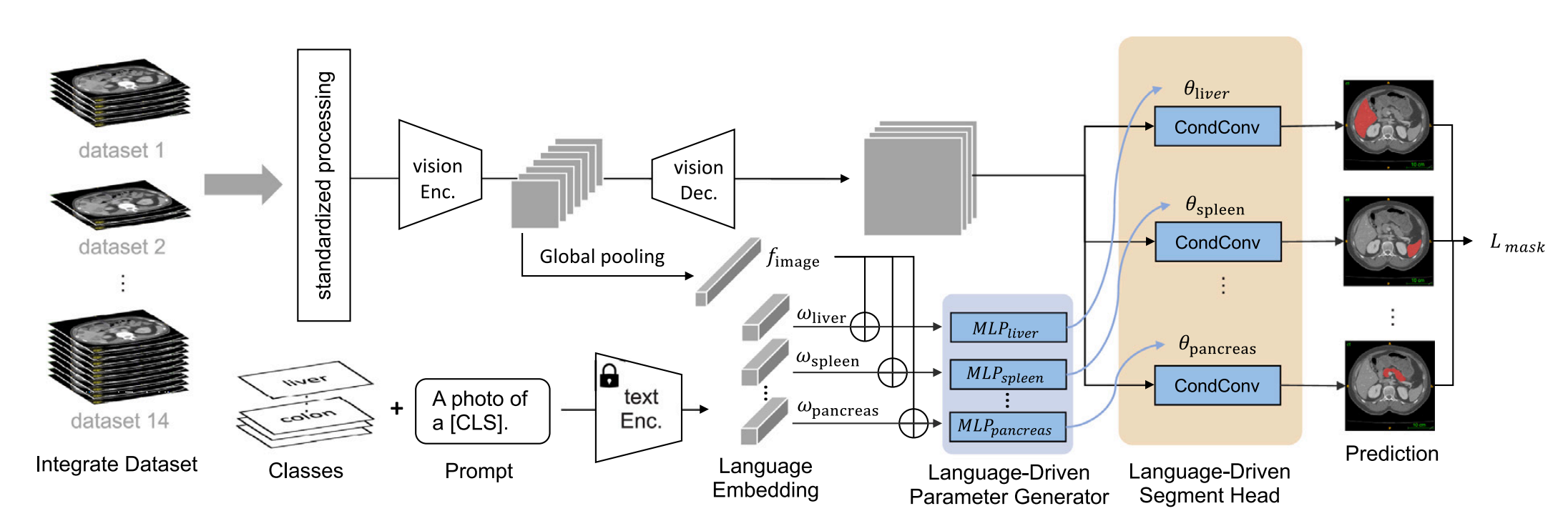
这些数据集中总共包含了25个器官和6种类型的肿瘤的部分标签。为了处理这些部分标签,通用模型由语言分支(language branch)和视觉分支(vision branch)组成,如图中Section 3.2所述。
-
语言分支(Language Branch):利用大型语言模型(如CLIP的文本编码器)的嵌入来生成每个器官/肿瘤类别的语言嵌入,以捕捉类别之间的语义关系。
-
视觉分支(Vision Branch):专注于从CT体积中提取特征嵌入,然后使用类特定分割头(Class-Specific Segmentation Head, CSH)结合语言嵌入来预测每个器官/肿瘤的二进制掩模。
-
性能基准测试(Benchmarking Performance):使用MSD(Medical Segmentation Decathlon)和BTCV(Beyond The Cranial Vault)的官方测试集来评估器官分割(Section 4.2)和肿瘤检测(Section 4.3)的性能。
-
外部验证(External Validation):使用3D-IRCADb、TotalSegmentator和一个包含5038个CT体积的大型私有数据集,这些数据集共有21个带注释的器官,用于独立评估模型的泛化能力(Section 4.5)和迁移能力(Section 4.6)。
-
持续学习(Continual Learning):LPG(Language-driven Parameter Generator)模块为每个器官使用独立的多层感知器(MLP),以解决ICCV版本(Liu et al., 2023a)中存在的纠缠问题,该版本依赖于单一的MLP。
这个框架的设计允许模型在不断学习新类别的同时,最小化对旧类别的干扰,即所谓的灾难性遗忘(catastrophic forgetting)。通过这种方式,通用模型能够适应新数据,同时保留对旧数据的知识,这对于医学图像分割和肿瘤检测领域是一个重要的进步。
这篇关于人工智能在影像组学与放射组学中的最新进展|顶刊速递·24-06-22的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






![[Day 73] 區塊鏈與人工智能的聯動應用:理論、技術與實踐](/front/images/it_default.jpg)

