本文主要是介绍java中共享变量分析和volatile,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1 共享变量
- 1.1 简单理解
- 1.2 CountDownLatch示例以及说明
- 1.3 JAVA内存模型
- 2 volatile
- 2.1 volatile简介
- 2.2 缓存(工作内存)
- 2.3 使用
- 2.3.1 术语定义
- 2.3.2 基本操作
- 2.3.3 volatile保证可见性不保证原子性
- 2.3.4 禁止指令重排序优化
- 2.4 原理
- 2.4.1 Volatile实现原理
- 2.4.2 Volatile的使用优化
- 2.4.3 volatile中伪共享问题
- 2.4.3.1 定义
- 2.4.3.2 解决伪共享的办法
- 2.5 特性
- 2.5.1 volatile写-读建立的happens before关系
- 2.5.2 volatile写-读的内存语义
- 2.5.3 volatile内存语义(内存屏障)
- 2.5.4 JSR-133为什么要增强volatile的内存语义
1 共享变量
1.1 简单理解
Java并发一直都是开发中比较难也比较有挑战性的技术,对于很多新手来说是很容易掉进这个并发陷阱的,其中尤以共享变量最具代表性,其实关于讲这个知识点网上也不少,但是想讲讲自己对这个概念的理解。
共享变量比较典型的就是指类成员变量,在类中定义了很多方法对成员变量的使用,如果是单实例,当有多个线程同时来调用这些方法,方法又没加控制,那么这些方法对成员变量的操作就会使得该成员变量的值变得不准确了
1.2 CountDownLatch示例以及说明
详情点击此处了解CountDownLatch的示例以及示例说明
1.3 JAVA内存模型
Java内存模型由Java虚拟机规范定义,用来屏蔽各个平台的硬件差异。简单来说:
- 所有变量储存在主内存
- 每条线程拥有自己的工作内存,其中保存了主内存中线程使用到的变量的副本
- 线程不能直接读写主内存中的变量,所有操作均在工作内存中完成。
线程,主内存,工作内存的交互关系如图

内存间的交互操作有很多,和volatile有关的操作为行为有八种:
锁定,解锁,读取,加载,使用,赋值,存储,写入八种操作
点击了解更多Java内存模型和八种操作
2 volatile
出现上面的问题,可以使用关键字volatile来解决
2.1 volatile简介
volatile是什么
对于volatile, <The Java Language Specification Third Edition>是这样描述的:
A field may be declared volatile, in which case the Java memory model ensures that all threads see a consistent value for the variable.意思是,如果一个变量声明为volatile, Java内存模型保证所有的线程看到这个变量的值是一致的。
"… the volatile modifier guarantees that any thread that reads a field will see the most recently written value.” - Josh Bloch
Josh Bloch 说 "volatile描述符保证任意一个程序读取的是最新写的值“
有人会问,内存不是存放变量值的地方吗,线程T1写,然后线程T2读,怎么会出现不一致的情况呢(上面的那个demo就可以完美阐释)
在多线程并发编程中synchronized和Volatile都扮演着重要的角色,Volatile是轻量级的synchronized,它在多处理器开发中保证了共享变量的可见性。可见性的意思是当一个线程修改一个共享变量时,另外一个线程能读到这个修改的值。它在某些情况下比synchronized的开销更小
2.2 缓存(工作内存)
实际上内存不是唯一存储变量的地方。CPU往往会把变量的值存放到缓存中。假如一个CPU,即使在多线程环境下也不会出现值不一致的情况。但是,在多CPU,或者多核CPU的情况就不是这样了。如下图所示,在多个CPU情况下,每个CPU都有独立的缓存,CPU通过连接相互获取缓存内容。线程T1的可能运行在CPU 0上,它从内存中读取值放到缓存中做运算,比如执行方法foo;线程T2运行于CPU 1上,执行方法bar
void foo(void)
{a = 1;b = 1;}void bar(void)
{while (b == 0) continue;assert(a == 1);
}

在多CPU情况下,由于CPU各自缓存的原因,线程可能观察到不一致的变量值。
而volitate标志通过CPU基本的指令,比如(mfence x86 Xeon 或 membar SPARC)添加内存界限,让缓存和内存之间的值进行同步
2.3 使用
2.3.1 术语定义
| 术语 | 英文单词 | 描述 |
|---|---|---|
| 共享变量 | Shared Variable | 在多个线程之间能够被共享的变量被称为共享变量。共享变量包括所有的实例变量,静态变量和数组元素。他们都被存放在堆内存中,Volatile只作用于共享变量。 |
| 内存屏障 | Memory Barriers | 是一组处理器指令,用于实现对内存操作的顺序限制。 |
| 缓冲行 | Cache line | 缓存中可以分配的最小存储单位。处理器填写缓存线时会加载整个缓存线,需要使用多个主内存读周期。 |
| 原子操作 | Atomic operations | 不可中断的一个或一系列操作 |
| 缓存行填充 | cache line fill | 当处理器识别到从内存中读取操作数是可缓存的,处理器读取整个缓存行到适当的缓存(L1,L2,L3的或所有) |
| 缓存命中 | cache hit | 如果进行高速缓存行填充操作的内存位置仍然是下次处理器访问的地址时,处理器从缓存中读取操作数,而不是从内存。 |
| 写命中 | write hit | 当处理器将操作数写回到一个内存缓存的区域时,它首先会检查这个缓存的内存地址是否在缓存行中,如果存在一个有效的缓存行,则处理器将这个操作数写回到缓存,而不是写回到内存,这个操作被称为写命中。 |
| 写缺失 | write misses the cache | 一个有效的缓存行被写入到不存在的内存区域。 |
2.3.2 基本操作
volatile的一个作用
由于volatile保证一些线程写的值,另外一些线程能够立即看得到。我们可以通过这一特性,实现信号或事件机制。比如下面程序里主线程可以发送信号(把stopSignal设为true), 把线程workerThread立即终止。
public class WorkerOwnerThread{// field is accessed by multiple threads.private static volatile boolean stopSignal;private static void doWork(){while (!stopSignal){Thread t = Thread.currentThread(); System.out.println(t.getName()+ ": I will work until i get STOP signal from my Owner...");}System.out.println("I got Stop signal . I stop my work");}private static void stopWork(){stopSignal = true;//Thread t = Thread.currentThread(); //System.out.println("Stop signal from " + t.getName() );}
public static void main(String[] args) throws InterruptedException {Thread workerThread = new Thread(new Runnable() {public void run() {doWork(); }});workerThread.setName("Worker");workerThread.start();//Main threadThread.sleep(100);stopWork();System.out.println("Stop from main...");}
}
2.3.3 volatile保证可见性不保证原子性
volatile变量对所有线程是立即可见的,在各个线程中不存在一致性问题。但是,volatile变量在并发运算下是线程不安全的,即不保证原子性
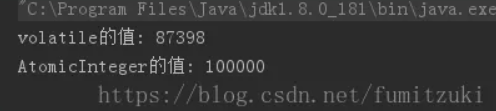
public class VolatileTest extends Thread{static volatile int increase = 0;static AtomicInteger aInteger=new AtomicInteger();//对照组static void increaseFun() {increase++;aInteger.incrementAndGet();}public void run(){int i=0;while (i < 10000) {increaseFun();i++;}}public static void main(String[] args) {VolatileTest vt = new VolatileTest();int THREAD_NUM = 10;Thread[] threads = new Thread[THREAD_NUM];for (int i = 0; i < THREAD_NUM; i++) {threads[i] = new Thread(vt, "线程" + i);threads[i].start();}//idea中会返回主线程和守护线程,如果用Eclipse的话改为1while (Thread.activeCount() > 2) {Thread.yield();}System.out.println("volatile的值: "+increase);System.out.println("AtomicInteger的值: "+aInteger);}
}
这个程序我们跑了10个线程同时对volatile修饰的变量进行10000的自增操作(AtomicInteger实现了原子性,作为对照组),如果volatile变量是并发安全的话,运行结果应该为100000,可是多次运行后,每次的结果均小于预期值。
volatile关键字只保证可见性,所以在以下情况中,需要使用锁来保证原子性:
- 运算结果依赖变量的当前值,并且有不止一个线程在修改变量的值。
- 变量需要与其他状态变量共同参与不变约束
2.3.4 禁止指令重排序优化
volatile变量的第二个语义是禁止指令重排序。指令重排序是什么?简单点说就是
jvm会把代码中没有依赖赋值的地方打乱执行顺序,由于一些规则限定,我们在单线程内观察不到打乱的现象(线程内表现为串行的语义),但是在并发程序中,从别的线程看另一个线程,操作是无序的
一个非常经典的指令重排序例子
public class SingletonTest {private volatile static SingletonTest instance = null;private SingletonTest() { }public static SingletonTest getInstance() {if(instance == null) {synchronized (SingletonTest.class){if(instance == null) {instance = new SingletonTest(); //非原子操作}}}return instance;}
}
这是单例模式中的双重检查加锁模式,我们看到instance用了volatile修饰,由于 instance = new SingletonTest();可分解为
- memory =allocate(); //分配对象的内存空间
- ctorInstance(memory); //初始化对象
- instance =memory; //设置instance指向刚分配的内存地址
操作2依赖1,但是操作3不依赖2,所以有可能出现1,3,2的顺序,当出现这种顺序的时候,虽然instance不为空,但是对象也有可能没有正确初始化,会出错
2.4 原理
2.4.1 Volatile实现原理
那么Volatile是如何来保证可见性的呢?在x86处理器下通过工具获取JIT编译器生成的汇编指令来看看对Volatile进行写操作CPU会做什么事情。
- Java代码:instance = new Singleton();//instance是volatile变量
- 汇编代码:0x01a3de1d: movb $0x0,0x1104800(%esi);0x01a3de24: lock addl $0x0,(%esp);
有volatile变量修饰的共享变量进行写操作的时候会多第二行汇编代码,通过查IA-32架构软件开发者手册可知,lock前缀的指令在多核处理器下会引发了两件事情:
- 将当前处理器缓存行的数据会写回到系统内存。
- 这个写回内存的操作会引起在其他
CPU里缓存了该内存地址的数据无效
处理器为了提高处理速度,不直接和内存进行通讯,而是先将系统内存的数据读到内部缓存(L1,L2,L3)后再进行操作,但操作完之后不知道何时会写到内存,如果对声明了Volatile变量进行写操作,JVM就会向处理器发送一条Lock #前缀的指令,将这个变量所在缓存行的数据写回到系统内存。但是就算写回到内存,如果其他处理器缓存的值还是旧的,再执行计算操作就会有问题,所以在多处理器下,为了保证各个处理器的缓存是一致的,就会实现缓存一致性协议,每个处理器通过嗅探在总线上传播的数据来检查自己缓存的值是不是过期了,当处理器发现自己缓存行对应的内存地址被修改,就会将当前处理器的缓存行设置成无效状态,当处理器要对这个数据进行修改操作的时候,会强制重新从系统内存里把数据读到处理器缓存里。
总线嗅探:当 A 号CPU核心修改了 L1 Cache 中 i 变量的值,通过总线把这个事件⼴播通知给其他所有的核心,然后每个 CPU 核心都会监听总线上的⼴播事件,并检查是否有相同的数据在自己的 L1 Cache里面,如果 B 号 CPU 核心的 L1 Cache 中有该数据,那么也需要把该数据更新到自己的 L1 Cache。
在 BUS 总线上 , 存在一个 总线嗅探机制, 一旦某个线程共享变量被声明为 volatile 变量之后 , 一旦在某个线程中 , 修改了该共享变量值 , 就会向 BUS 总线发送一个 共享变量改变的消息 ;CPU不停地嗅探 BUS 总线上的共享变量改变的消息, 一旦接收到该消息事件 , 就会将正在该CPU核心上执行的其它线程的工作内存 的变量副本置为失效 ( Invalid ) 状态 ; 之后该 CPU 核心 会立刻向 BUS 总线 发送一条消息 , 表示 该线程中的副本变量已经失效
Lock前缀指令会引起处理器缓存回写到内存。Lock前缀指令导致在执行指令期间,声言处理器的 LOCK 信号。在多处理器环境中,LOCK 信号确保在声言该信号期间,处理器可以独占使用任何共享内存。(因为它会锁住总线,导致其他CPU不能访问总线,不能访问总线就意味着不能访问系统内存),但是在最近的处理器里,LOCK信号一般不锁总线,而是锁缓存,毕竟锁总线开销比较大,对于早期处理器,在锁操作时,总是在总线上声言LOCK信号。但在现在大部分处理器中,如果访问的内存区域已经缓存在处理器内部,则不会声言LOCK信号,相反地,它会锁定这块内存区域的缓存并回写到内存,并使用缓存一致性机制来确保修改的原子性,此操作被称为缓存锁定,缓存一致性机制会阻止同时修改被两个以上处理器缓存的内存区域数据
缓存一致性协议中,最出名的就是Intel 的MESI协议,MESI协议保证了每个缓存中使用的共享变量的副本是一致的。它核心的思想是:当CPU写数据时,如果发现操作的变量是共享变量,即在其他CPU中也存在该变量的副本,会发出信号通知其他CPU将该变量的缓存行置为无效状态,因此当其他CPU需要读取这个变量时,发现自己缓存中缓存该变量的缓存行是无效的,那么它就会从内存重新读取
| MESI状态 | 描述 |
|---|---|
| M(Modified) 修改 | 这行数据有效,数据被修改了,和内存中的数据不一致,数据只存在于本Cache中 |
| E(Exclusive)独占 | 数据只存储在⼀个 CPU核心的 Cache里,而其他 CPU 核心的 Cache 没有该数据。若向独占的 Cache 写数据,就可以直接自由地写入,而不需要通知其他 CPU 核心,因为只有这有这个数据,就不存在缓存⼀致性的问题了,于是就可以随便操作该数据。在独占状态下的数据,如果有其他核心从内存读取了相同的数据到各自的 Cache ,那么这个时候,独占状态下的数据就会变成共享状态 |
| S(Shared)共享 | 代表着相同的数据在多个 CPU 核心的 Cache里都有,所以当我们要更新 Cache里面的数据的时候,不能直接修改,而是要先向所有的其他 CPU 核心广播⼀个请求,要求先把其他核心的 Cache 中对应的 Cache Line 标记为无效状态,然后再更新当前Cache里面的数据 |
| I(Invalid)失效 | 这行数据无效 |
一个处理器的缓存回写到内存会导致其他处理器的缓存无效。IA-32处理器和Intel 64处理器使用MESI(修改,独占,共享,无效)控制协议去维护内部缓存和其他处理器缓存的一致性。在多核处理器系统中进行操作的时候,IA-32 和Intel 64处理器能嗅探其他处理器访问系统内存和它们的内部缓存。它们使用嗅探技术保证它的内部缓存,系统内存和其他处理器的缓存的数据在总线上保持一致。例如在Pentium和P6 family处理器中,如果通过嗅探一个处理器来检测其他处理器打算写内存地址,而这个地址当前处理共享状态,那么正在嗅探的处理器将无效它的缓存行,在下次访问相同内存地址时,强制执行缓存行填充。
2.4.2 Volatile的使用优化
在JDK7的并发包里新增一个队列集合类LinkedTransferQueue,在使用Volatile变量时,用一种追加字节的方式来优化队列出队和入队的性能。
追加字节能优化性能?这种方式看起来很神奇,但如果深入理解处理器架构就能理解其中的奥秘。让我们先来看看LinkedTransferQueue这个类,它使用一个内部类类型来定义队列的头队列(Head)和尾节点(tail),而这个内部类PaddedAtomicReference相对于父类AtomicReference只做了一件事情,就将共享变量追加到64字节。我们可以来计算下,一个对象的引用占4个字节,它追加了15个变量共占60个字节,再加上父类的Value变量,一共64个字节。
/** head of the queue */
private transient final PaddedAtomicReference<QNode> head;/** tail of the queue */
private transient final PaddedAtomicReference<QNode> tail;static final class PaddedAtomicReference <T> extends AtomicReference <T> {// enough padding for 64bytes with 4byte refsObject p0, p1, p2, p3, p4, p5, p6, p7, p8, p9, pa, pb, pc, pd, pe;PaddedAtomicReference(T r) {super(r);}}public class AtomicReference <V> implements java.io.Serializable {private volatile V value;//省略其他代码}
为什么追加64字节能够提高并发编程的效率呢? 因为对于英特尔酷睿i7,酷睿, Atom和NetBurst, Core Solo和Pentium M处理器的L1,L2或L3缓存的高速缓存行是64个字节宽,不支持部分填充缓存行,这意味着如果队列的头节点和尾节点都不足64字节的话,处理器会将它们都读到同一个高速缓存行中,在多处理器下每个处理器都会缓存同样的头尾节点,当一个处理器试图修改头接点时会将整个缓存行锁定,那么在缓存一致性机制的作用下,会导致其他处理器不能访问自己高速缓存中的尾节点,而队列的入队和出队操作是需要不停修改头接点和尾节点,所以在多处理器的情况下将会严重影响到队列的入队和出队效率。使用追加到64字节的方式来填满高速缓冲区的缓存行,避免头接点和尾节点加载到同一个缓存行,使得头尾节点在修改时不会互相锁定。
那么是不是在使用Volatile变量时都应该追加到64字节呢?
不是的。在两种场景下不应该使用这种方式:
- 缓存行非64字节宽的处理器,如P6系列和奔腾处理器,它们的L1和L2高速缓存行是32个字节宽。
- 共享变量不会被频繁的写。因为使用追加字节的方式需要处理器读取更多的字节到高速缓冲区,这本身就会带来一定的性能消耗,共享变量如果不被频繁写的话,锁的几率也非常小,就没必要通过追加字节的方式来避免相互锁定
2.4.3 volatile中伪共享问题
2.4.3.1 定义
伪共享问题指两个线程A和B,他们俩写入同一个cache block的不同变量时,会导致另一个cpu核心的缓存失效的问题。
我们来详细看一下伪共享问题到底是怎么产生的:
假设A线程要访问变量A,B线程要访问变量B,并且变量A和B会被分配到同一个 缓存行(cache line:缓存的最小操作单位)中:
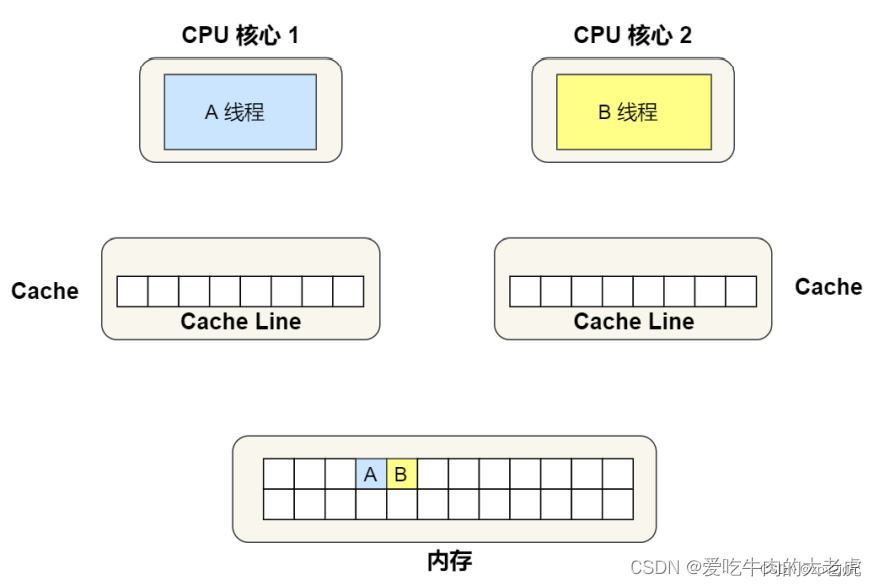
接下来,A线程要读取变量A。此时A、B所在的cache line被加载到核心1的cache中,并且状态被标记为 独占:
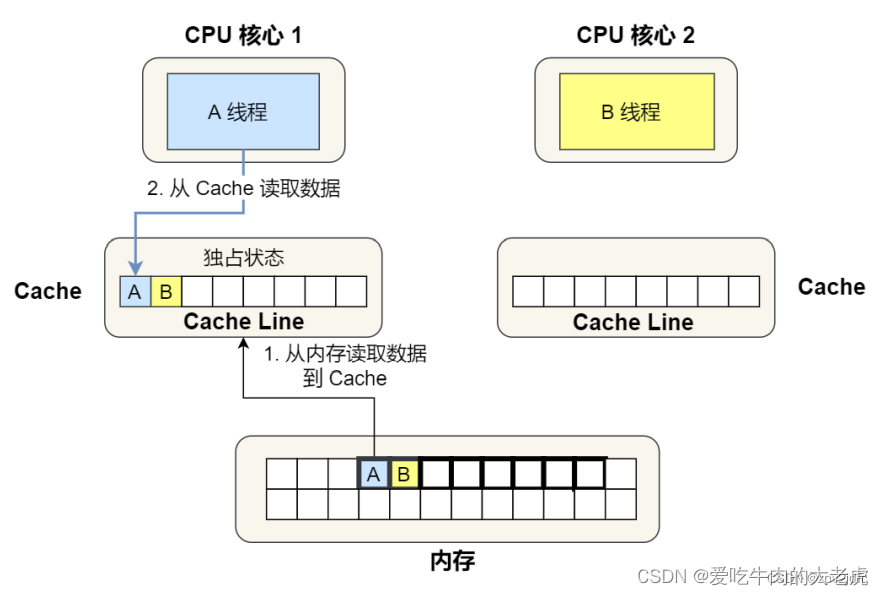
此时,B线程要访问变量B,那么这个 cache line 被加载到核心2的cache中。并且两个核心的cache line 都标记为 共享:
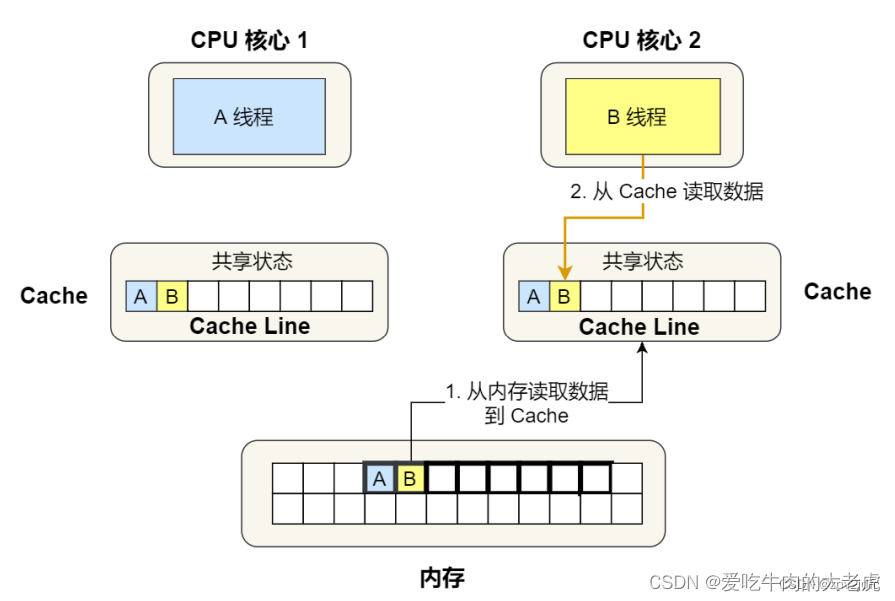
接下来,问题来了。假设A线程修改了变量A,为了保证数据一致性,就需要把核心2的 cache line 标记为失效:
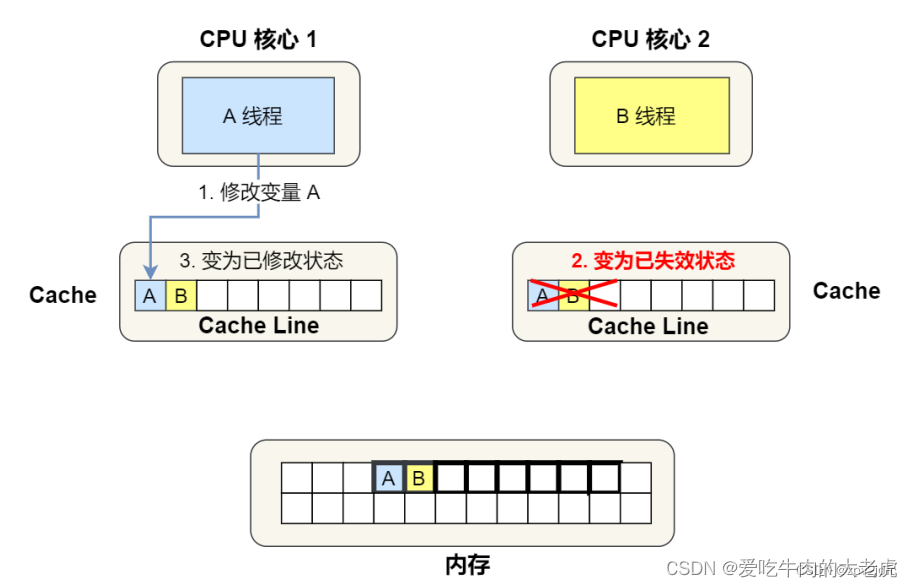
这样一来,如果B要读取变量B的值,就需要A先将 cache line 写回内存,然后B再从内存中读取。也就是说,明明B变量自始至终都没有改变过,但是在访问时却需要重新从内存读取。如果A、B两个线程轮流修改变量A、B的话,伪共享问题会严重影响性能。
2.4.3.2 解决伪共享的办法
字节填充
对上面这种情况,如果A、B不被分配在同一个cache line中自然就不存在伪共享问题了。
如何让A、B分配在不同cache line中呢?我们可以通过这个命令查看cache line的大小
more /sys/devices/system/cpu/cpu1/cache/index0/coherency_line_size
可以看到 cache line 大小为64字节。接下来,我们来对比一下使用字节填充后程序性能会提高多少。
由于 CPU 缓存行一般大小为 64 字节或128字节,所以可以通过占满缓存行的方法来避免伪共享问题。例如,在多线程环境下访问两个变量 a 和 b,它们位于同一个缓存行中,就可以在它们之间插入一个 long 类型的变量 c,从而让 a 和 b 分别被存储到不同的缓存行中,避免了缓存行的竞争。
public class Data {long a1,a2,a3,a4,a5,a6,a7; // 前置填充volatile int value;long b1,b2,b3,b4,b5,b6,b7; // 后置填充
}
在 JDK8 中,@sun.misc.Contended 注解可以用来避免伪共享问题。这个注解只能用于类和属性,并且需要手动启用 JVM 的 -XX:-RestrictContended 参数才能生效。该注解表示某个字段会被频繁地修改并且多个线程同时访问,可以让编译器自动进行填充,使其与其它不同位置的字段占据不同的缓存行,从而避免伪共享问题。
需要注意的是,使用 @sun.misc.Contended 注解可能会带来一些风险,因为它可能会改变内存布局,带来一些不可预期的行为。所以,在使用该注解时需要特别小心,并进行充分的测试和评估。
实际上,从 JDK 9 开始,@Contended 注解已经被废弃,并且在 JDK 12 中被完全删除。这是因为在现代的硬件架构中,缓存行对齐已经得到了很好的优化,所以使用@Contended 注解对性能的提升效果有限。
2.5 特性
2.5.1 volatile写-读建立的happens before关系
点击了解happens-before规则
上面讲的是volatile变量自身的特性,对程序员来说,volatile对线程的内存可见性的影响比volatile自身的特性更为重要,也更需要我们去关注。
volatile变量的写-读可以实现线程之间的通信。
从内存语义的角度来说,volatile与监视器锁有相同的效果:volatile写和监视器的释放有相同的内存语义;volatile读与监视器的获取有相同的内存语义。
请看下面使用volatile变量的示例代码:
class VolatileExample {int a = 0;volatile boolean flag = false;public void writer() {a = 1; //1flag = true; //2}public void reader() {if (flag) { //3int i = a; //4……}}
}
假设线程A执行writer()方法之后,线程B执行reader()方法。根据happens before规则,这个过程建立的happens before 关系可以分为两类:
- 根据程序次序规则,1 happens before 2; 3 happens before 4。
- 根据volatile规则,2 happens before 3。
- 根据happens before 的传递性规则,1 happens before 4。
上述happens before 关系的图形化表现形式如下:
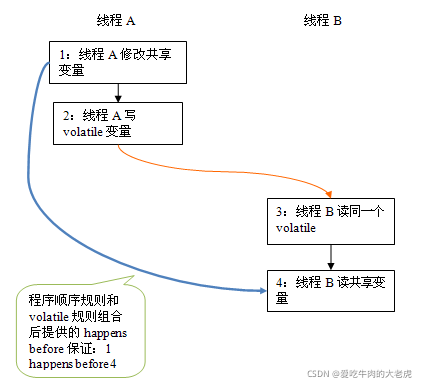
在上图中,每一个箭头链接的两个节点,代表了一个happens before 关系。黑色箭头表示程序顺序规则;橙色箭头表示volatile规则;蓝色箭头表示组合这些规则后提供的happens before保证。
这里A线程写一个volatile变量后,B线程读同一个volatile变量。A线程在写volatile变量之前所有可见的共享变量,在B线程读同一个volatile变量后,将立即变得对B线程可见。
2.5.2 volatile写-读的内存语义
volatile写的内存语义如下:
当写一个volatile变量时,JMM会把该线程对应的本地内存中的共享变量刷新到主内存。
以上面示例程序VolatileExample为例,假设线程A首先执行writer()方法,随后线程B执行reader()方法,初始时两个线程的本地内存中的flag和a都是初始状态。下图是线程A执行volatile写后,共享变量的状态示意图:
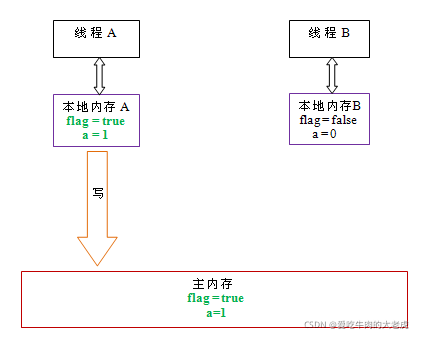
如上图所示,线程A在写flag变量后,本地内存A中被线程A更新过的两个共享变量的值被刷新到主内存中。此时,本地内存A和主内存中的共享变量的值是一致的。
volatile读的内存语义如下:
当读一个volatile变量时,JMM会把该线程对应的本地内存置为无效。线程接下来将从主内存中读取共享变量。
下面是线程B读同一个volatile变量后,共享变量的状态示意图:

如上图所示,在读flag变量后,本地内存B已经被置为无效。此时,线程B必须从主内存中读取共享变量。线程B的读取操作将导致本地内存B与主内存中的共享变量的值也变成一致的了。
如果我们把volatile写和volatile读这两个步骤综合起来看的话,在读线程B读一个volatile变量后,写线程A在写这个volatile变量之前所有可见的共享变量的值都将立即变得对读线程B可见。
下面对volatile写和volatile读的内存语义做个总结:
- 线程A写一个
volatile变量,实质上是线程A向接下来将要读这个volatile变量的某个线程发出了(其对共享变量所在修改的)消息。 - 线程B读一个
volatile变量,实质上是线程B接收了之前某个线程发出的(在写这个volatile变量之前对共享变量所做修改的)消息。 - 线程A写一个
volatile变量,随后线程B读这个volatile变量,这个过程实质上是线程A通过主内存向线程B发送消息。
2.5.3 volatile内存语义(内存屏障)
下面,让我们来看看JMM如何实现volatile写/读的内存语义。
由于重排序分为编译器重排序和处理器重排序。为了实现volatile内存语义,JMM会分别限制这两种类型的重排序类型。下面是JMM针对编译器制定的volatile重排序规则表:

举例来说,第三行最后一个单元格的意思是:在程序顺序中,当第一个操作为普通变量的读或写时,如果第二个操作为volatile写,则编译器不能重排序这两个操作。
从上表我们可以看出:
- 当第二个操作是
volatile写时,不管第一个操作是什么,都不能重排序。这个规则确保volatile写之前的操作不会被编译器重排序到volatile写之后。 - 当第一个操作是
volatile读时,不管第二个操作是什么,都不能重排序。这个规则确保volatile读之后的操作不会被编译器重排序到volatile读之前。 - 当第一个操作是
volatile写,第二个操作是volatile读时,不能重排序。
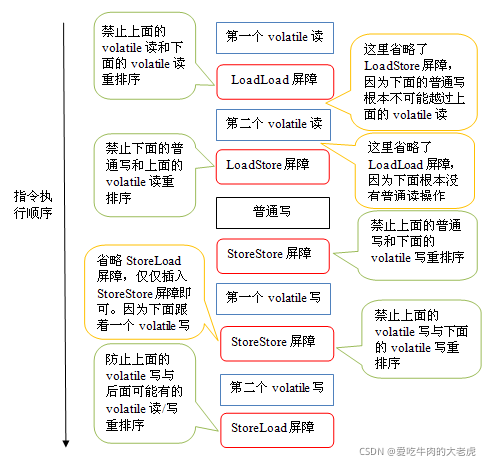
为了实现volatile的内存语义,编译器在生成字节码时,会在指令序列中插入内存屏障来禁止特定类型的处理器重排序。对于编译器来说,发现一个最优布置来最小化插入屏障的总数几乎不可能,为此,JMM采取保守策略。下面是基于保守策略的JMM内存屏障插入策略:
- 在每个
volatile写操作的前面插入一个StoreStore屏障。 - 在每个
volatile写操作的后面插入一个StoreLoad屏障。 - 在每个
volatile读操作的后面插入一个LoadLoad屏障。 - 在每个
volatile读操作的后面插入一个LoadStore屏障。
上述内存屏障插入策略非常保守,但它可以保证在任意处理器平台,任意的程序中都能得到正确的volatile内存语义。
下面是保守策略下,volatile写插入内存屏障后生成的指令序列示意图:

上图中的StoreStore屏障可以保证在volatile写之前,其前面的所有普通写操作已经对任意处理器可见了。这是因为StoreStore屏障将保障上面所有的普通写在volatile写之前刷新到主内存。
这里比较有意思的是volatile写后面的StoreLoad屏障。这个屏障的作用是避免volatile写与后面可能有的volatile读/写操作重排序。因为编译器常常无法准确判断在一个volatile写的后面,是否需要插入一个StoreLoad屏障(比如,一个volatile写之后方法立即return)。为了保证能正确实现volatile的内存语义,JMM在这里采取了保守策略:在每个volatile写的后面或在每个volatile读的前面插入一个StoreLoad屏障。从整体执行效率的角度考虑,JMM选择了在每个volatile写的后面插入一个StoreLoad屏障。因为volatile写-读内存语义的常见使用模式是:一个写线程写volatile变量,多个读线程读同一个volatile变量。当读线程的数量大大超过写线程时,选择在volatile写之后插入StoreLoad屏障将带来可观的执行效率的提升。从这里我们可以看到JMM在实现上的一个特点:首先确保正确性,然后再去追求执行效率。
下面是在保守策略下,volatile读插入内存屏障后生成的指令序列示意图:

上图中的LoadLoad屏障用来禁止处理器把上面的volatile读与下面的普通读重排序。LoadStore屏障用来禁止处理器把上面的volatile读与下面的普通写重排序。
上述volatile写和volatile读的内存屏障插入策略非常保守。在实际执行时,只要不改变volatile写-读的内存语义,编译器可以根据具体情况省略不必要的屏障。下面我们通过具体的示例代码来说明:
class VolatileBarrierExample {int a;volatile int v1 = 1;volatile int v2 = 2;void readAndWrite() {int i = v1; //第一个volatile读int j = v2; // 第二个volatile读a = i + j; //普通写v1 = i + 1; // 第一个volatile写v2 = j * 2; //第二个 volatile写}… //其他方法
}
针对readAndWrite()方法,编译器在生成字节码时可以做如下的优化:
注意,最后的StoreLoad屏障不能省略。因为第二个volatile写之后,方法立即return。此时编译器可能无法准确断定后面是否会有volatile读或写,为了安全起见,编译器常常会在这里插入一个StoreLoad屏障。
上面的优化是针对任意处理器平台,由于不同的处理器有不同松紧度的处理器内存模型,内存屏障的插入还可以根据具体的处理器内存模型继续优化。以x86处理器为例,上图中除最后的StoreLoad屏障外,其它的屏障都会被省略。
前面保守策略下的volatile读和写,在 x86处理器平台可以优化成:

前文提到过,x86处理器仅会对写-读操作做重排序。X86不会对读-读,读-写和写-写操作做重排序,因此在x86处理器中会省略掉这三种操作类型对应的内存屏障。在x86中,JMM仅需在volatile写后面插入一个StoreLoad屏障即可正确实现volatile写-读的内存语义。这意味着在x86处理器中,volatile写的开销比volatile读的开销会大很多(因为执行StoreLoad屏障开销会比较大)
2.5.4 JSR-133为什么要增强volatile的内存语义
在JSR-133(从JDK5开始,java使用新的JSR -133内存模型。JSR-133提出了happens-before的概念)之前的旧Java内存模型中,虽然不允许volatile变量之间重排序,但旧的Java内存模型允许volatile变量与普通变量之间重排序。在旧的内存模型中,VolatileExample示例程序可能被重排序成下列时序来执行:

在旧的内存模型中,当1和2之间没有数据依赖关系时,1和2之间就可能被重排序(3和4类似)。其结果就是:读线程B执行4时,不一定能看到写线程A在执行1时对共享变量的修改。
因此在旧的内存模型中 ,volatile的写-读没有监视器的释放-获所具有的内存语义。为了提供一种比监视器锁更轻量级的线程之间通信的机制,JSR-133专家组决定增强volatile的内存语义:严格限制编译器和处理器对volatile变量与普通变量的重排序,确保volatile的写-读和监视器的释放-获取一样,具有相同的内存语义。从编译器重排序规则和处理器内存屏障插入策略来看,只要volatile变量与普通变量之间的重排序可能会破坏volatile的内存语意,这种重排序就会被编译器重排序规则和处理器内存屏障插入策略禁止。
由于volatile仅仅保证对单个volatile变量的读/写具有原子性,而监视器锁的互斥执行的特性可以确保对整个临界区代码的执行具有原子性。在功能上,监视器锁比volatile更强大;在可伸缩性和执行性能上,volatile更有优势
参考资料:
Memory Barrier
为什么需要Memory Barrier
Java 内存模型和Memory Barrier
这篇关于java中共享变量分析和volatile的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





