本文主要是介绍Python期末复习:数据科学库,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
Numpy
python中的list可以当成数组使用,但是list元素可以是任何对象,保存的是对象的指针,所以用list做数值计算显然非常浪费时间,
python中还有一个array,虽然也可以当成数组,但是只能当成一维数组,不能用来计算多维数组
Numpy的诞生就解决了这个问题
Numpy提供了两个基本的对象:
一个是ndarray和ufunc
分别是:存储单一数据类型的多维数组 和 能对数组进行处理的函数
Numpy的实例的属性
import numpy as nps = np.array([1, 2, 3, 4])
print(s.ndim) # 得到数组的秩
print(s.shape) # 得到数组的形状
print(s.size) # 长*宽
print(s.dtype) # 得到数组的元素的类型
print(s.itemsize) # 得到每一个元素的大小,以字节为单位#注意这两个函数是不可变的
print(s.tolist())
print(type(s))
print(s.reshape((2,2)))
print(type(s))1
(4,)
4
int32
4
[1, 2, 3, 4]
<class 'numpy.ndarray'>
[[1 2][3 4]]
<class 'numpy.ndarray'>进程已结束,退出代码0
Numpy创建数组
arrange (start,end,step):注意是左闭右开,突然想起来random中的是全闭的
import numpy as nps = np.arange(6)
print(s)
d = np.arange(2, 6)
print(d)
k = np.arange(2, 6, 2)
print(k)[0 1 2 3 4 5]
[2 3 4 5]
[2 4] linespace (start,stop,num):也是全闭
import numpy as nps = np.linspace(1, 10, 9)
print(s)[ 1. 2.125 3.25 4.375 5.5 6.625 7.75 8.875 10. ]logspace(start,stop,num):也是全闭(start^10,end^10)
创建特定数组
zeros((x,y)):创建全部为零的矩阵
ones((x,y)):创建全部为一的矩阵
identity(num):创建对角矩阵,并且对角数值为1
diag([list]):创建对角矩阵,对角的值为list中的值
import numpy as nps = np.zeros((2, 3))
print(f"全零矩阵\n{s}")
d = np.ones((3, 3))
print(f"全一矩阵\n{d}")
k = np.identity(5)
print(f'创建对角矩阵\n{k}')
q = np.diag([1,2,3,4,5])
print(f"创建对角矩阵,对角值根据传入的list改变\n{q}")全零矩阵
[[0. 0. 0.][0. 0. 0.]]
全一矩阵
[[1. 1. 1.][1. 1. 1.][1. 1. 1.]]
创建对角矩阵
[[1. 0. 0. 0. 0.][0. 1. 0. 0. 0.][0. 0. 1. 0. 0.][0. 0. 0. 1. 0.][0. 0. 0. 0. 1.]]
创建对角矩阵,对角值根据传入的list改变
[[1 0 0 0 0][0 2 0 0 0][0 0 3 0 0][0 0 0 4 0][0 0 0 0 5]]进程已结束,退出代码0np.fromiter(iterate,dtype=type) :从迭代器中生成
np.fromfunction(func,(x,y)) 从函数中生成
import numpy as npit = (i ** 2 for i in range(5))
s = np.fromiter(it, dtype=int)
print(s)def fun(x, y):return x - yd = np.fromfunction(fun, (4, 4))#这个就相当于对(4,4)这个数组进行遍历应该是吧QAQ
print(d)[ 0 1 4 9 16][[ 0. -1. -2. -3.][ 1. 0. -1. -2.][ 2. 1. 0. -1.][ 3. 2. 1. 0.]]进程已结束,退出代码0
Numpy.random(随机抽样)注意和random区别
import numpy as np
from numpy import random as nr# s = nr.random_integers(2,5,(2,5)) 这个好像已经被遗弃了,这个本来是[low,high]
s = nr.randint(2, 5, (2, 5), dtype=int) # 这个是[low,high)
print(s)
d = nr.rand(2, 3) # 生成指定形状的[0-1]的浮点数
print(d)
k = nr.randn(5, 5) # 按照正态分布的概率计算
print(k)q = nr.random_sample(5) # 返回随机的浮点数[0,1)
print(q)
p = nr.random(5) # 这个和上面的好像是一样的
print(p)
i = nr.ranf(5) # 这个似乎和上面也是一样的
print(i)
o = nr.sample(5) # 这个也是和上面一样
print(o)l = nr.choice(6, 5, replace=False, p=[0.1, 0.2, 0.3, 0.1, 0.2, 0.1]) # 从p中随机抽取,replace表示是否放回n = nr.bytes(5) # 生成随机的单位
print(n)[[4 2 4 2 4][3 4 4 2 3]]
[[0.55336786 0.66488795 0.95153315][0.17372736 0.80365202 0.77294536]]
[[-2.04772753 0.7001404 0.81329486 -1.33713303 -0.9596097 ][ 0.36737018 0.46765275 -0.41415292 -1.4931712 0.43632637][-0.77721146 0.04464664 -0.51497462 0.39877069 -0.26831653][ 0.46309697 -0.90536734 1.49091845 0.94789236 -0.18558578][-0.29923761 0.15979749 -0.59289668 -2.49348486 -0.52257789]]
[0.43074101 0.83482635 0.6611764 0.58381501 0.14710413]
[0.42986199 0.62969516 0.44950566 0.41486986 0.87479932]
[0.60047357 0.37202381 0.22236361 0.40351214 0.07840019]
[0.4048961 0.63081037 0.74358606 0.62701993 0.05613808]
b'S\x17t\x92,'进程已结束,退出代码0
Numpy的排列
import numpy as np
from numpy import random as nr
import random# 打乱一个数组
s = np.arange(10)
nr.shuffle(s) #打乱一个列表
print(s)# 和原生的比较
lis = [1, 2, 3, 4, 5]
random.shuffle(lis)
print(lis)# 这个可以直接代替上面的所有了
d = nr.permutation(5)
print(d)
k = nr.permutation([1, 2, 3, 4, 6])
print(k)
te = nr.permutation(lis)
print(te)[2 4 6 3 7 5 8 1 9 0]
[5, 3, 1, 4, 2]
[0 4 2 3 1]
[6 2 3 1 4]
[5 2 3 1 4]Numpy的概率分布
import numpy as np
from numpy import random as nr
import random# 高斯正态分布
mu = 0 # 决定顶峰左右的那个
sigma = 0.1 # 决定了顶峰的高度的那个
s = nr.normal(mu, sigma, (2, 2))
print(s)
labda = 5
s = nr.poisson(labda, (3, 3))
print(s)
k = nr.uniform(2, 5, (3, 3))
print(k)
n = 10 # 试验次数
p = 0.5 # 每次试验成功的概率# 生成10个随机样本
samples = np.random.binomial(n, p, 10)
print(samples)[[ 0.12284486 0.01837126][-0.17409858 -0.1348578 ]]
[[2 6 3][3 4 7][6 5 4]]
[[4.11560241 3.01363368 3.38453364][3.6228972 2.36235143 2.13154825][4.3493092 4.68555782 4.34941073]]
[4 8 5 5 5 4 5 7 3 9]进程已结束,退出代码0
Numpy的元素访问
下标切片:
使用下标或切片 与python列表序列有所不同,通过下标或切片获取的数组数据是原始数组的一个视图,与原始数组共享数据空间。简单来说就是通过切片得到的是共享数据空间的
import numpy as np# 创建一个NumPy数组
original_array = np.array([1, 2, 3, 4, 5])# 通过切片获取原始数组的一个部分
view_array = original_array[1:4]print("Original array:", original_array)
print("View array:", view_array)# 修改view_array中的一个元素
view_array[0] = 99print("After modifying the view array:")
print("Original array:", original_array)
print("View array:", view_array)
Original array: [1 2 3 4 5]
View array: [2 3 4]
After modifying the view array:
Original array: [ 1 99 3 4 5]
View array: [99 3 4]
整数序列访问小标
使用整数序列中的每个元素作为下标,而整数序列可以是列表或者数组。获得的数组不与原始数组共享空间。
import numpy as np# 创建一个NumPy数组
original_array = np.array([10, 20, 30, 40, 50])# 使用整数序列作为下标
index_array = [1, 3, 4]
new_array = original_array[index_array]print("Original array:", original_array)
print("New array:", new_array)# 修改new_array中的一个元素
new_array[0] = 99print("After modifying the new array:")
print("Original array:", original_array)
print("New array:", new_array)
Original array: [10 20 30 40 50]
New array: [20 40 50]
After modifying the new array:
Original array: [10 20 30 40 50]
New array: [99 40 50]
使用布尔数组
.使用布尔数组 当使用布尔数组b作为下标存取数组x中的元素时,将收集数组x中所有在数组b中对应下标为True的元素。 使用布尔数组作为下标获得的数组不和原始数组共享数据空间,注意这种方式只对应于布尔数组,不能使用布尔列表。
说人话就是用np创建的数组bool序列可以这样使用,并且是True的话就取了
但是用原生的list就会报错
import numpy as np# 创建一个NumPy数组
original_array = np.array([10, 20, 30, 40, 50])# 使用布尔数组进行索引
bool_array = np.array([True, False, True, False, True])
new_array = original_array[bool_array]print("Using Boolean array:")
print("Original array:", original_array)
print("New array:", new_array)
# 创建一个布尔列表
bool_list = [True, False, True, False, True]# 尝试使用布尔列表进行索引(会引发错误)
try:new_array = original_array[bool_list]print("Using Boolean list:")print("Original array:", original_array)print("New array:", new_array)
except IndexError as e:print("Error:", e)
Using Boolean array:
Original array: [10 20 30 40 50]
New array: [10 30 50]
Error: only integer scalar arrays can be converted to a scalar index
Bool索引:
import numpy as np
from numpy import random as nrs = np.array([1, 2, 3, 4, 5, 6])
print(np.any(s < 2))
print(np.all(s < 10))k = s[s < 3]
k[0] = 2
print(k)
print(s)
k[k==2] = 3
print(k)True
True
[2 2]
[1 2 3 4 5 6]
[3 3]
import numpy as np
from numpy import random as nrs = np.array([1, 2, 3, 4, 5, 6])
index = np.nonzero(s > 5)
index_where = np.where(s > 3)
print(s[index])
print(s[index_where])
t = np.clip(s, 2, 5)
print(t)
[6]
[4 6]
[2 2 3 4 2 5]
Numpy的二维数组
对高纬数组的索引
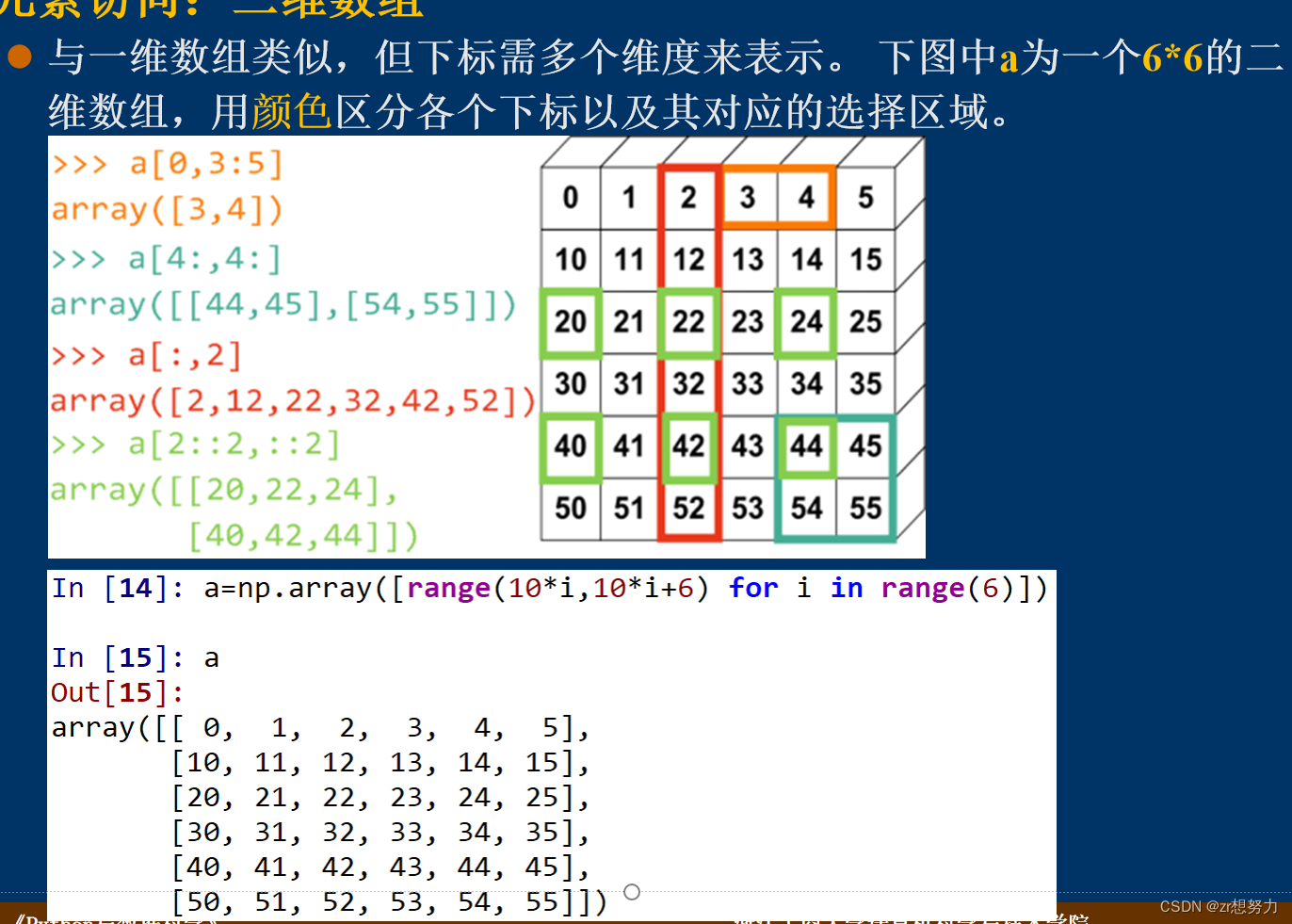
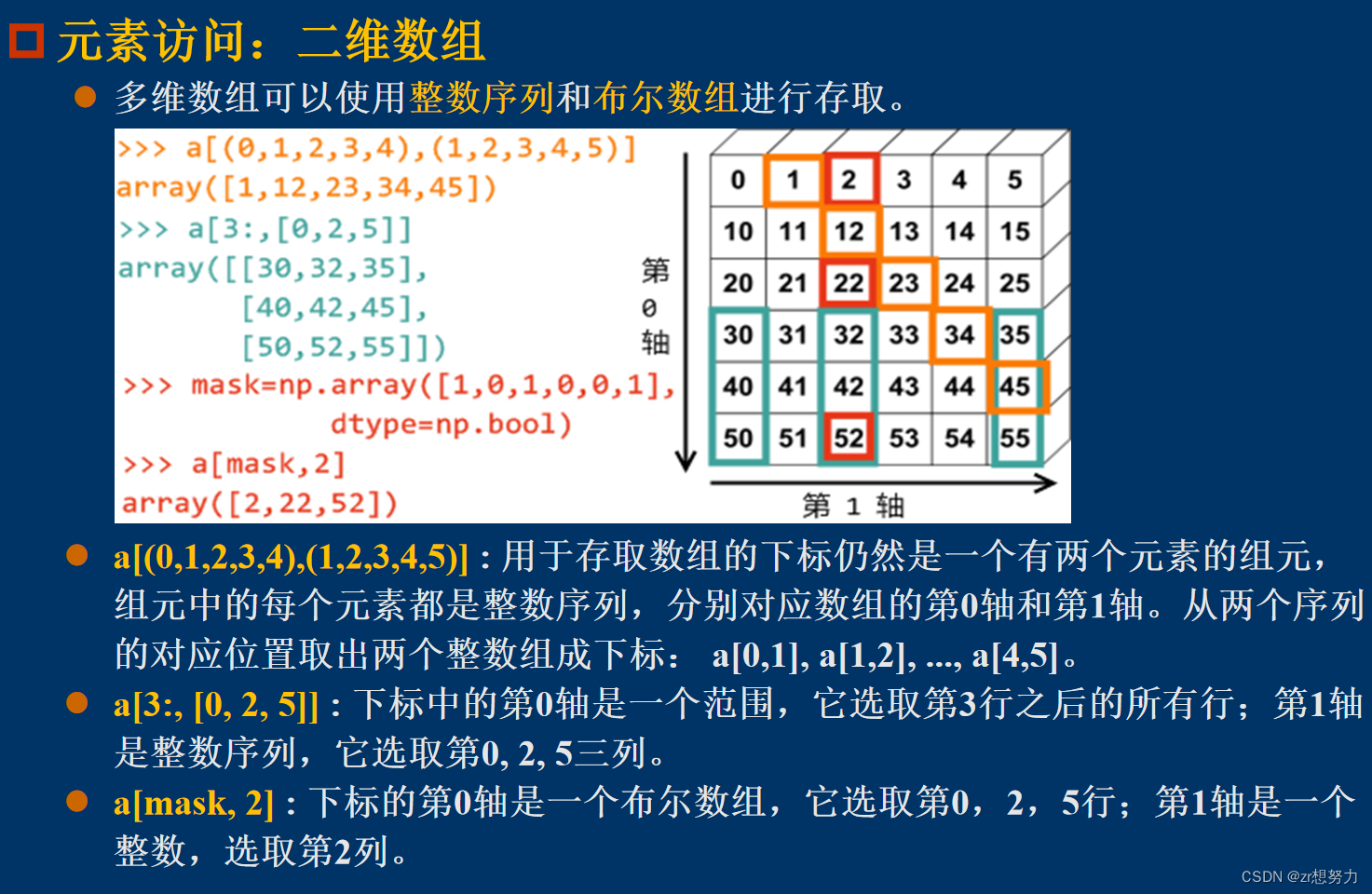
对高于二维数组的坐标判断
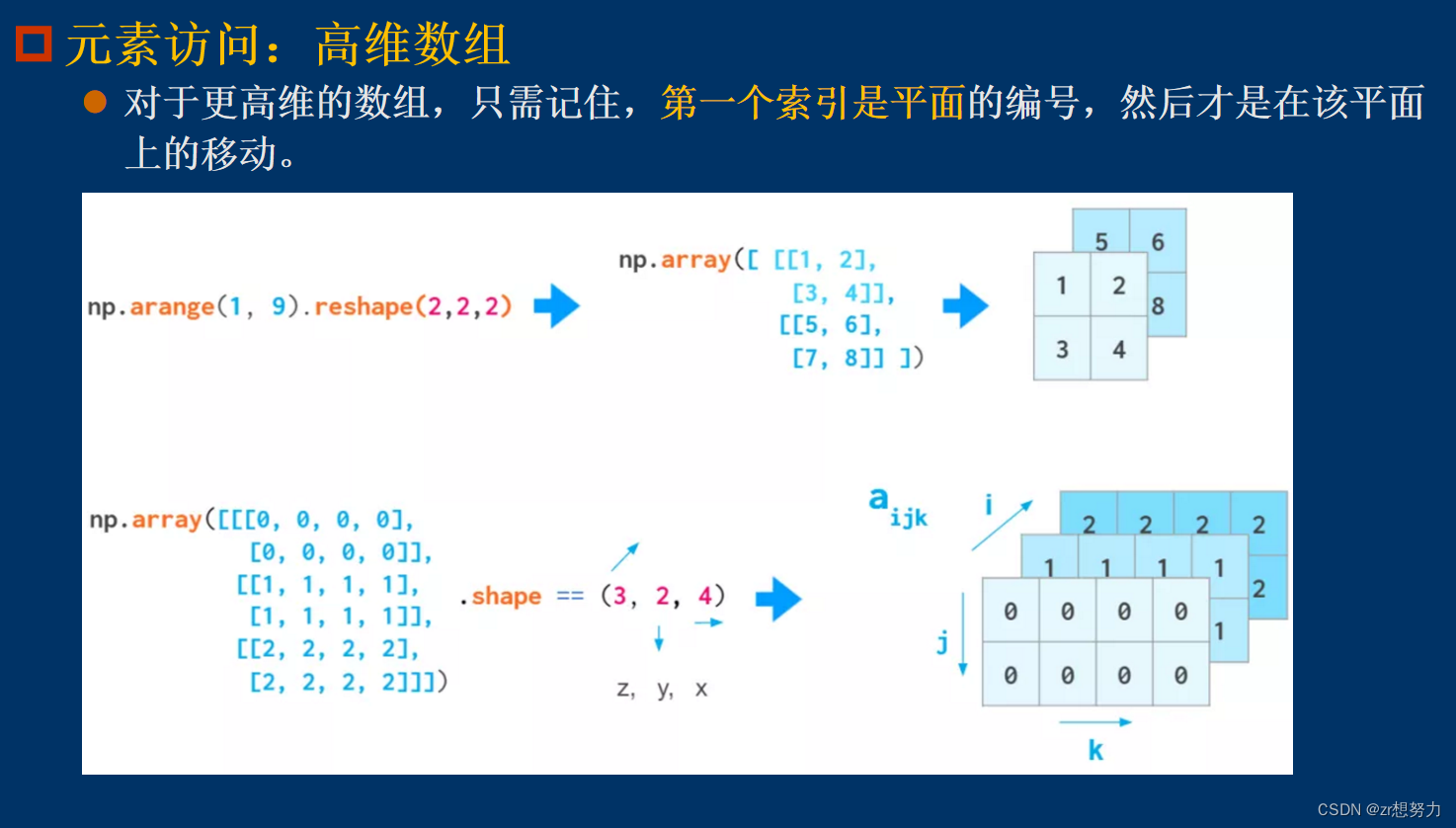
数学计算中的计算标准
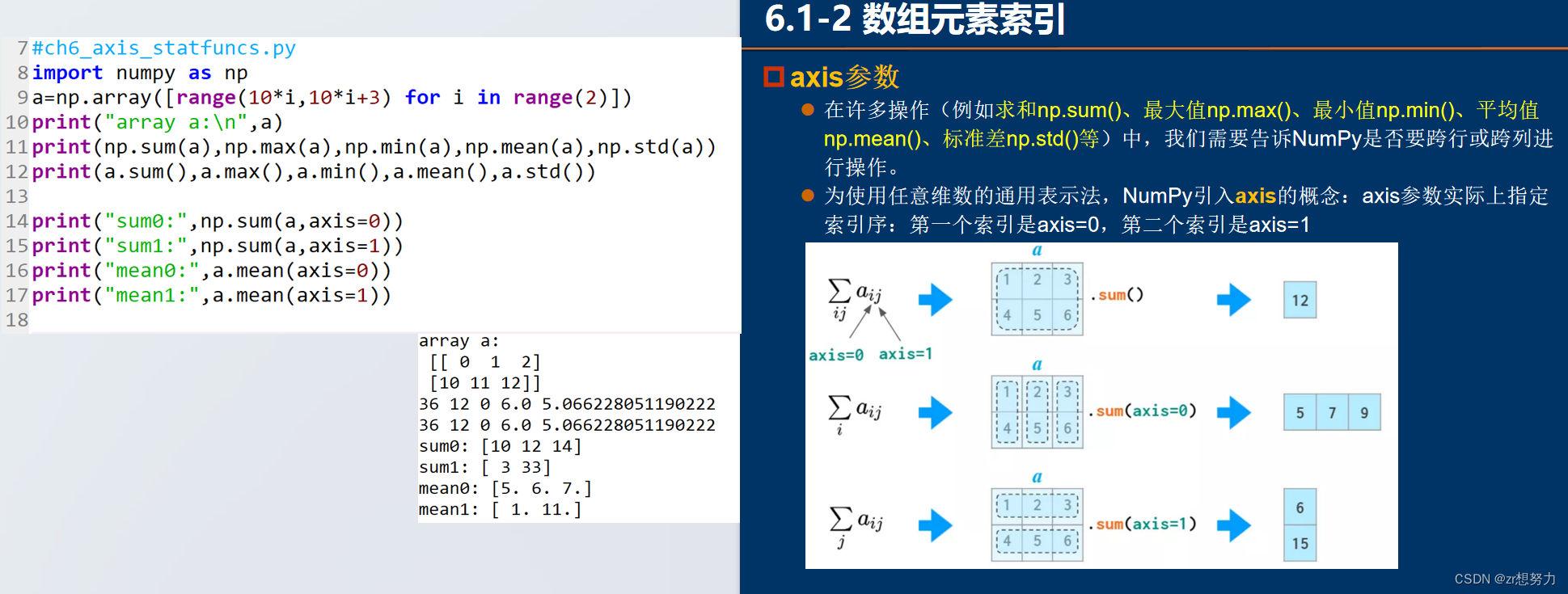
Numpy中的ufunc(里面的许多函数都是由C语言实现的所以速度快)
import mathimport numpy as np
from numpy import random as nrs = np.linspace(0, math.pi * 2, 10)
t = np.sin(s)
print(t)[ 0.00000000e+00 6.42787610e-01 9.84807753e-01 8.66025404e-013.42020143e-01 -3.42020143e-01 -8.66025404e-01 -9.84807753e-01-6.42787610e-01 -2.44929360e-16]一些常见的函数
Numpy的自定义ufunc函数

Numpy向量的矩阵运算
np.dot:计算点积
import numpy as npx = np.array([1, 2, 3, 4, 5, 6])
y = np.ones_like(x)
print(np.dot(x, y))21np.cross:计算叉积(注意np里面的向量叉积只支持三个元素的计算)
import numpy as npx = np.array([1, 2, 3])
y = np.ones_like(x)
print(np.cross(x, y))[-1 2 -1]
二维矩阵的运算 :(同时支持乘法除法加法减法,矩阵的乘积等等)
import numpy as npx = np.array([[1, 2], [3, 4]])
y = np.array([[1, 2], [3, 4]])print(x*y)
print(x//y)
print(x@y)[[ 1 4][ 9 16]]
[[1 1][1 1]]
[[ 7 10][15 22]]进程已结束,退出代码0
矩阵的转置(转至是原地转置的)
import numpy as npx = np.array([[1, 2], [3, 4]])
print(x)
print(x.T)[[1 2][3 4]]
[[1 3][2 4]]
二维矩阵的连接:
vstack和hstack(顾名思义就是首字母的方向,Vertical和Horizontal代表了两个水平和垂直的连接方向)
np.hstack
np.vstack
Numpy的排序算法
np.sort
sort(a):
原始的用法是对每一个行进行排序
sort(a,axis)
axis = 0 对每一行进行排序
axis = 1 对每一列进行排序
axis = None 将多维数组直接展开后做一维的从小到大的排序
sort(a,order = ):按照某个进行排序
import numpy as npdtype = [('name', 'S10'), ('height', float), ('age', int)]
values = [('autore', 1.7, 32), ('what', 15.2, 31)]
b = np.array(values,dtype=dtype)
a4 = np.sort(b,order='height')
print(a4)[(b'autore', 1.7, 32) (b'what', 15.2, 31)][(b'autore', 1.7, 32) (b'what', 15.2, 31)]
np.argsort(x,axis)返回排序后的数组对应原来的数组的位置
Numpy的CSV文件存取
import numpy as np# 下面的两种方法只适用于一维或者二维数组
x = np.array([[1, 2, 3, 4, 5, 6], [4, 5, 6, 7, 8, 9]])
np.savetxt('b.csv', x, fmt='%d', delimiter=',')
y = np.loadtxt('b.csv', delimiter=',')
print(y)# 下面是存储任意维度的方法
c = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])
c.tofile('nums.dat', sep=',', format='%d')
# 这个是读取一维数组的,所以要动手恢复数组
e = np.fromfile('nums.dat', dtype=np.int32, sep=',')
e = e.reshape(c.shape)
print(e)[[1. 2. 3. 4. 5. 6.][4. 5. 6. 7. 8. 9.]]
[[1 2 3][4 5 6][7 8 9]]Numpy的快速存取文件
np.save(只能保存单个文件)
np.savez(可以存储多个文件)
np.load(将文件加载出来)
import numpy as npa = np.arange(30).reshape(2, 3, 5)
print(a)
np.save('sd.npy', a)
b = np.load('sd.npy')
print(b)# 注意这里用多维的时候是用的npz后缀的文件压缩的
np.savez('zips.npz', a)
d = np.load('zips.npz')
print(d['arr_0']) # 这里读取要用下标表示读取的是哪个数组s = np.array([1, 2, 3])
k = np.array([4, 5, 6])
i = np.array([7, 8, 9])
np.savez('what.npz', s, k, i)
p = np.load('what.npz')
print("first", p['arr_0'])
print('second', p['arr_2'])[[[ 0 1 2 3 4][ 5 6 7 8 9][10 11 12 13 14]][[15 16 17 18 19][20 21 22 23 24][25 26 27 28 29]]]
[[[ 0 1 2 3 4][ 5 6 7 8 9][10 11 12 13 14]][[15 16 17 18 19][20 21 22 23 24][25 26 27 28 29]]]
[[[ 0 1 2 3 4][ 5 6 7 8 9][10 11 12 13 14]][[15 16 17 18 19][20 21 22 23 24][25 26 27 28 29]]]
first [1 2 3]
second [7 8 9]进程已结束,退出代码0
Numpy的pandas中的series
Series是一种类似于一维数组的对象,它由一组数据(各种numpy数据类型)以及一组与之相关的数据标签(即索引)组成。 Series可以看做一个定长的有序字典
Series对象包含了两个主要的属性,一个是index另一个是values,分别对应了第一列和后面一列
第一种形式:
import pandas as pd
import numpy as np# 创建一个 Series 对象
s = pd.Series([1, 3, 5, "what", 6, 8])
# 输出 Series 对象print(s.values)0 1
1 3
2 5
3 what
4 6
5 8
dtype: object进程已结束,退出代码0
第二种形式:
import pandas as pd
import numpy as nps = pd.Series(index=['a', 'b', 'v'], data=['yes', 'no', 'idon'])
print(s)a yes
b no
v idon
dtype: object这里需要注意的是在Series中的index和values是相互独立的,所以在性能方面是完全没问题的
Numpy的DataFram(切片都是右端包含的)
DataFrame是一个表格型的数据结构,由一组有序的列构成,每列可以是不同的值类 型,不像 ndarray 只能有一个 dtype。
DataFrame既有行索引也有列索引,基本上可以把 DataFrame 看成是共享同一个 index 的 Series 的集合。
下面是实例
import pandas as pd
import numpy as npdaat = {'state': ['sleep', 'walk', 'jump', 'forward'],'name': ['joy', 'laugh', 'kind', 'strong'],'age': [12, 12, 15, 12]}
dataframe = pd.DataFrame(daat)
print(dataframe[dataframe['age']==12])state name age
0 sleep joy 12
1 walk laugh 12
3 forward strong 12
下面是完整的创建形式
import pandas as pd
import numpy as npdaat = {'state': ['sleep', 'walk', 'jump', 'forward'],'name': ['joy', 'laugh', 'kind', 'strong'],'age': [12, 12, 15, 12]}dataframe = pd.DataFrame(daat, index=['第一行', '第二行', '第三行','第四行'], columns=['states', 'name', 'age']) # 这个colums不是随便的,是按照原先给的数据内容确定的
print(dataframe[dataframe['age'] == 12])states name age
第一行 NaN joy 12
第二行 NaN laugh 12
第四行 NaN strong 12
DataFram中的索引和切片
就像 Numpy,pandas 也支持通过 obj[::] 的方式进行索引和切片,以及通过布尔型数组进行过滤。 不过须要注意,因为 pandas 对象的 index 不限于整数,所以当使用非整数作为切片索引时,它是末端包含的
这段话是在说明 Pandas 中对索引的切片操作的规则。通常情况下,Python 中的切片操作是左闭右开的,即不包括右侧边界。但是在 Pandas 中,对于使用非整数作为索引的情况,切片操作是末端包含的,也就是说切片会包括右侧边界。举个例子来说明,在 Pandas 中如果有如下 Series:python
import pandas as pddata = {'a': 1, 'b': 2, 'c': 3, 'd': 4}
s = pd.Series(data, index=['one', 'two', 'three', 'four'])
如果我们进行切片操作 s['two':'four'],在普通的 Python 切片中,这个操作会得到 {'two', 'three'},不包括 'four'。但是在 Pandas 中,这个切片操作会包括 'four',即结果为 {'two', 'three', 'four'}。这种规则对于处理时间序列数据、非整数索引的数据非常方便,因为它符合了许多实际数据处理的需求。因此,在使用 Pandas 进行数据处理时,需要注意索引的切片操作是末端包含的这一特点。DataFrame 对象的索引方式较特别,因为有两个轴向(双重索引) DataFrame 对象的标准切片语法为:.ix[::,::]
ix 对象可以接受两套切片,分别为行(axis=0)和列(axis=1)的方向。 而不使用 ix ,直接切的情况 就特殊了: 索引时,选取的是列 切片时,选取的是行
Pandas中的统计方法
pandas对象拥有一组常用的数学和统计方法。它们大部分都属于约简和汇总统计,用于从Series中提取的个值(如sum或mean)或从DataFrame的行或列中提取一个Series。
描述和汇总统计 方法 说明
count 非NA值的数量
describe 针对Series或各DataFrame列计算汇总统计
min,max 计算最小值和最大值
argmin,argmax 计算能够获取到最小值和最大值的索引位置
idxmin,idxmax 计算能够获取到最小值和最大值的索引值
quantile 计算样本的分位数(0到 1)
sum 值的总和
描述和汇总统计(续)
mean 值的平均数
median 值的算术中位数(50%分位数)
mad 根据平均值计算平均绝对离差
var 样本值的方差
std 样本值的标准差
skew 样本值的偏度(三阶矩)
kurt 样本值的峰度(四阶矩)
cumsum 样本值的累计和
cummin,cummax 样本值的累计最大值和累计最小
cumprod 样本值的累计积
diff 计算一阶差分(对时间序列很有用)
pct_change 计算百分数变化
这篇关于Python期末复习:数据科学库的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





