本文主要是介绍深入分析并可视化城市轨道数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
介绍
中国城市化进程加速中,城市轨道交通的迅速扩张成为提升城市运行效率和居民生活品质的关键。这一网络从少数大城市延伸至众多大中型城市,映射了经济飞跃和城市管理现代化。深入分析并可视化城市轨道数据,对于揭示网络特性、评估效率、理解乘客行为及预测趋势至关重要,它不仅指导政府决策和城市规划,也通过简化复杂信息增进公众理解,助力形成共识。
数据概览
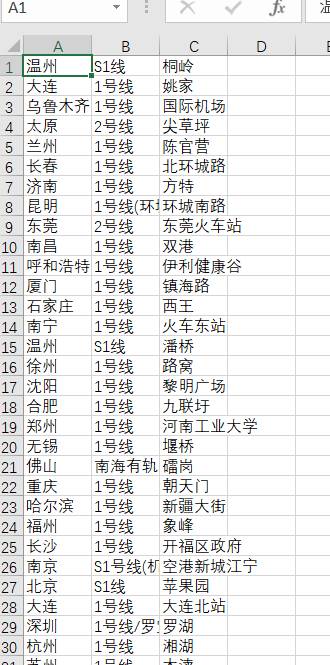
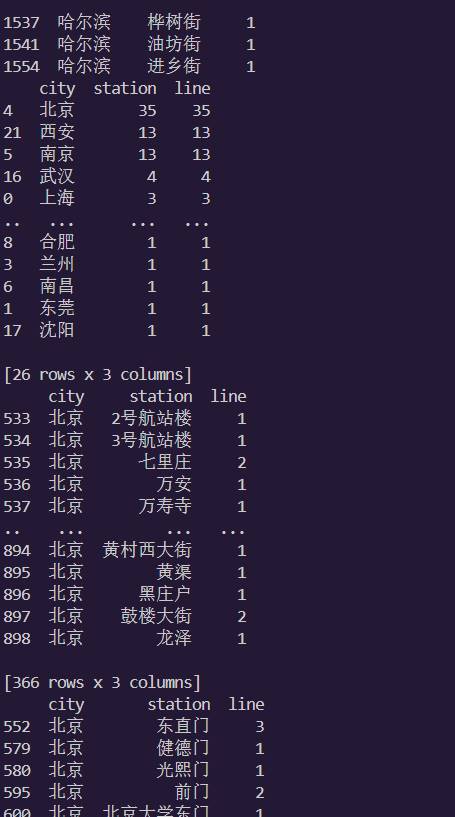
1.数据集表中各列含义说明如下:
最左边的是城市名,中间一列是号线,最右边的是站点名

2.部分数据展示,数据文件名:subway.csv
数据清洗
检查数据集中是否存在含有缺失值的行或重复的记录。如果发现这样的情况,采取措施移除这些行或记录。然而,根据提供的信息(尽管没有直接展示图像),所有数据似乎已经过初步审查,并未发现需要进行删除操作的缺失值或重复项。在此之后,原本计划对处理过程中涉及的数据量进行统计,并将处理完毕的数据集保存至一个新的文件夹中。但鉴于前期检查结果显示无需实际进行数据剔除,这一步可能转化为仅统计并确认数据的完整状态,并将当前完好无缺的数据集复制或存档至指定的备份位置。
将清洗后的数据命名为subway_clean.csv
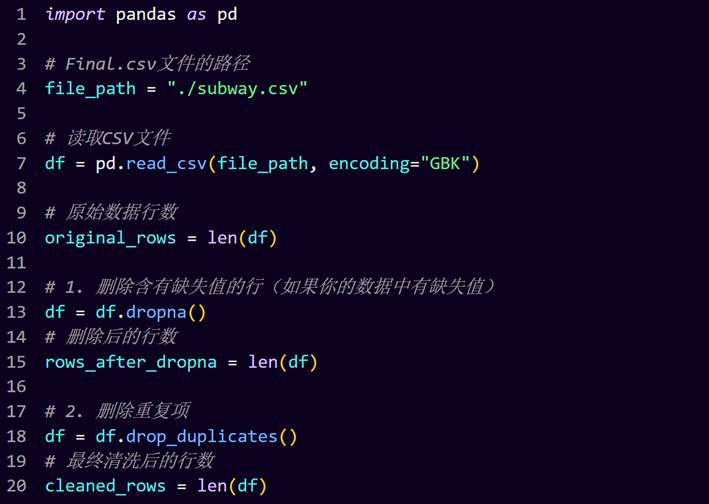
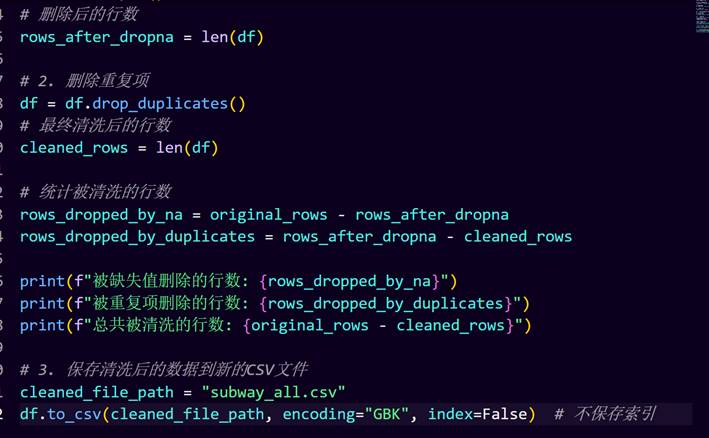
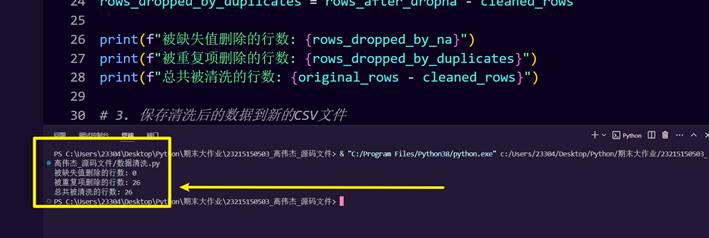
可以看到,清洗成功了,并且文件夹下多了一个名为subway_clean.csv
数据可视化
1.首先引入编写可视化函数需要的库:
这些库在Python中主要用于数据分析、可视化以及文本处理:
WordCloud: 这个库用于生成词云。你可以输入一段文本或者文本集合,它会根据词语出现的频率大小,以不同的尺寸展示这些词语,形成云状图案,常用于文本数据的视觉化分析。
ImageColorGenerator: 是wordcloud库中的一个功能,用于从图片中提取颜色方案来着色词云,使得生成的词云色彩更加丰富和美观,与背景图片色彩协调。
pyecharts: 一个用于生成图表的Python库,特别适合制作中国式风格的图表,支持多种图表类型,如折线图(Line)、柱状图(Bar)、地理图(Geo)等,适用于Web端的交互式数据可视化。
matplotlib.pyplot: Python中最常用的绘图库,支持创建静态、交互式和动画图表。plt是其子模块,提供了类似MATLAB的绘图接口,方便快速绘制图形,如直方图、折线图、散点图等。
pandas: 强大的数据处理和分析库,提供了DataFrame对象,可以高效地处理和分析表格型数据,包括数据清洗、转换、合并、分组、重塑等多种功能。
numpy: 基于Python的数值计算库,提供了高性能的多维数组对象和用于处理数组的工具,是进行科学计算的基础库,常与pandas一起使用,增强数据处理能力。
jieba: 中文分词库,用于中文文本的分词处理,能够将一段中文文本切割成一个个有意义的词语,是进行中文文本分析和处理的重要工具。
seaborn: 基于matplotlib的统计图形库,提供了更高级的接口来绘制统计图形,如热力图、联合分布图等,特别擅长于数据分布的可视化及复杂统计数据的展示,使数据可视化更加美观和专业。
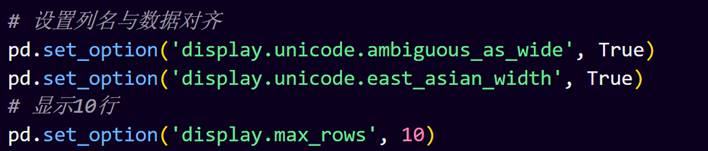
2.设置列名与数据对齐
3.进行数据的读取

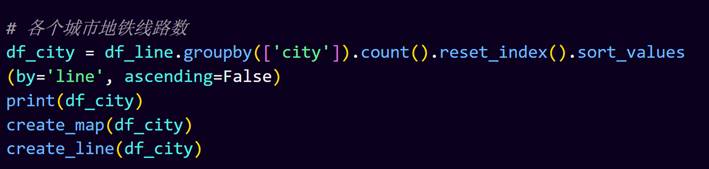
4.各个城市地铁线路情况,并打印在控制台

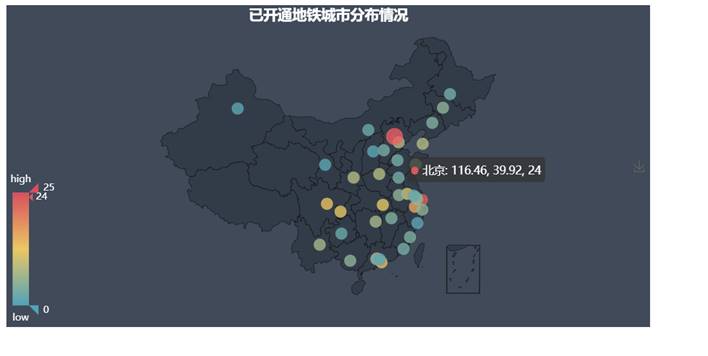
5.绘制已经开通了地铁的城市分布情况的地图
参数定义:函数接受一个名为df的DataFrame作为输入参数,这个DataFrame预期包含两列——'line'和'city'。其中,'line'列可能代表各城市的地铁线路数量或其他与地铁相关的数值指标,而'city'列则存储城市名称。
数据准备:
value = [i for i in df['line']]:从DataFrame的'line'列提取所有数值,用于地图上各个点的数值大小表示。
attr = [i for i in df['city']]:从'Df'的'city'列提取所有城市名称,这些将作为地图上各个点的标签。
Geo对象创建:
Geo(...)初始化了一个地图图表对象,具体配置包括:
标题为"已开通地铁城市分布情况",居中且顶部对齐,距离顶部0。
图表宽度800像素,高度400像素。
标题颜色为白色("#fff"),背景颜色为深灰色("#404a59")。
数据添加到地图:
geo.add(...)向地图中添加数据,参数包括:
空字符串作为系列名称(表明只有一个数据序列)。
'city'列数据作为属性(attr),对应地图上的地理位置标记。
'line'列数据作为值(value),决定标记的视觉效果(如大小)。
is_visualmap=True开启视觉映射,用于根据数值大小自动调整标记的视觉表现。
visual_range=[0, 25]设定视觉映射的范围,这里假设地铁线路数量在0到25之间。
visual_text_color="#fff"保持视觉映射文本颜色为白色,确保在深色背景下清晰可见。
symbol_size=15设置地图标记的基本大小。
渲染与保存:
geo.render("已开通地铁城市分布情况.html")将创建的地图保存为HTML文件,文件名为"已开通地铁城市分布情况.html",便于在浏览器中查看。

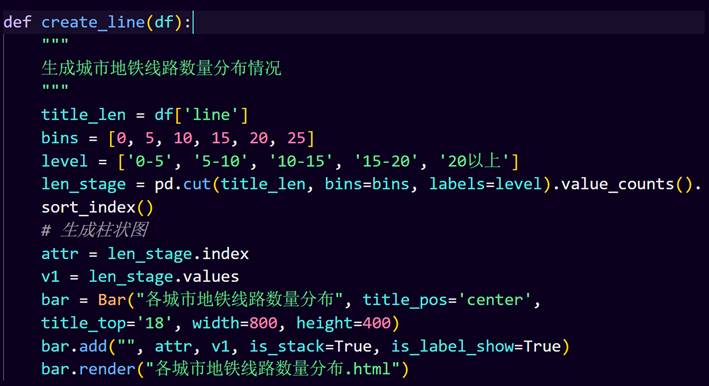
6.创建各城市地铁线路数量分布柱状图
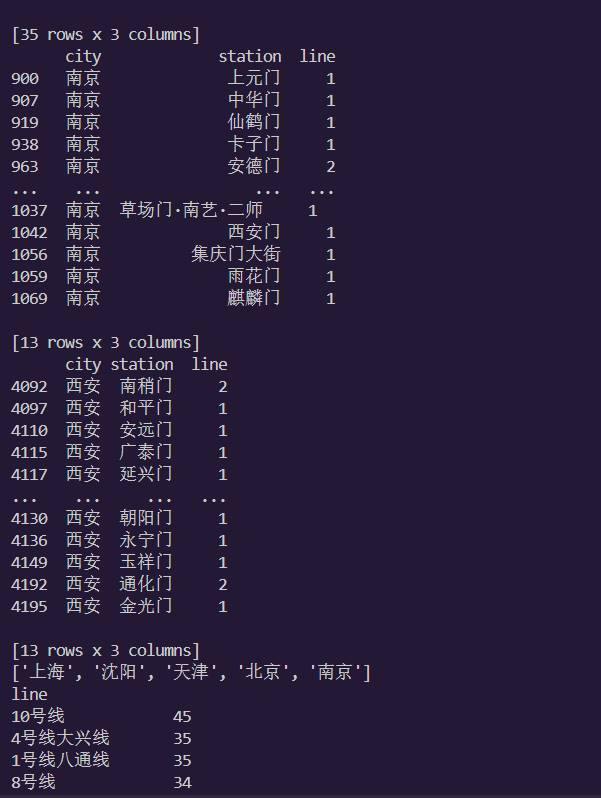
7.查看哪个城市哪条线路地铁站最多,并打印在控制台

8.进行去除重复换乘站的地铁数据的操作, 并将结果打印在控制台

9.统计每个城市包含地铁站数(已去除重复换乘站)

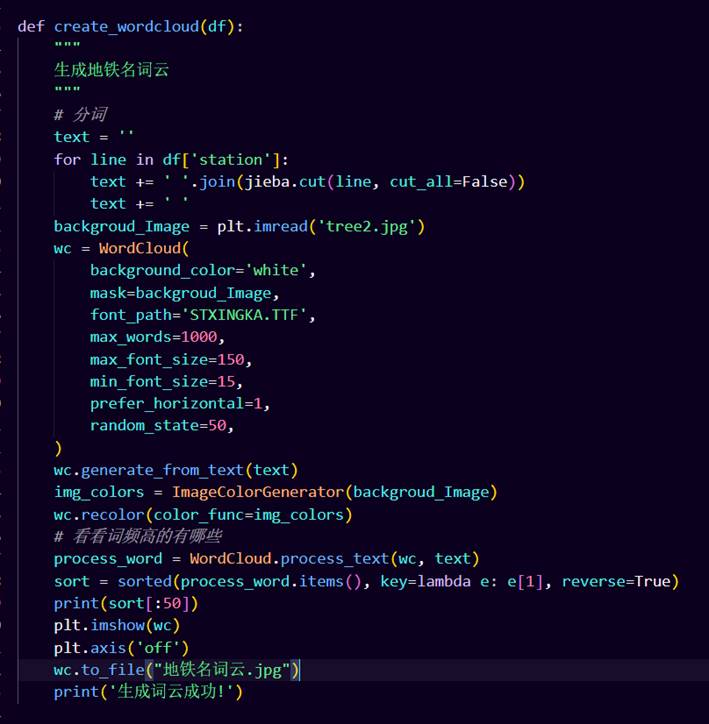
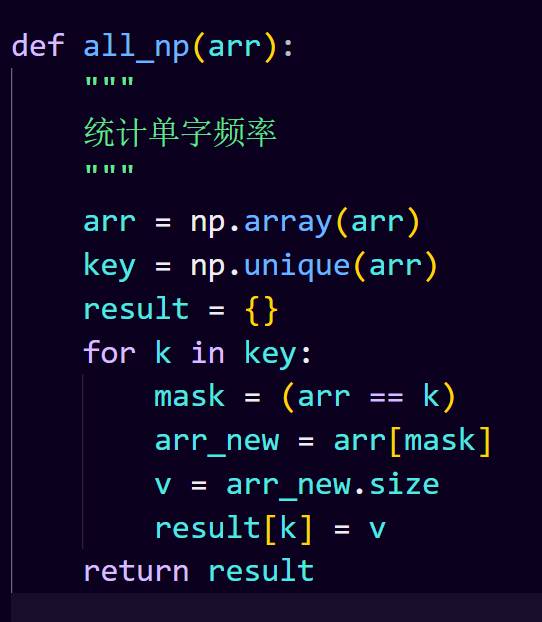
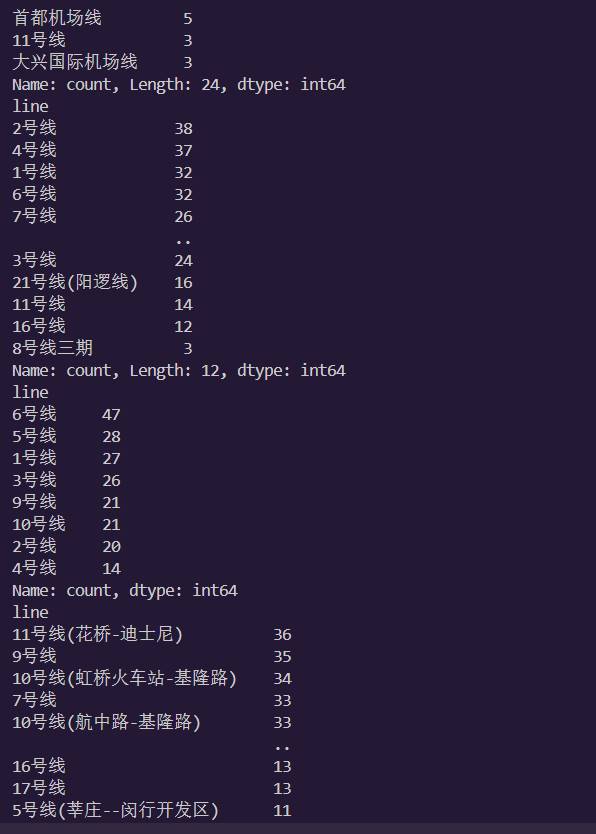
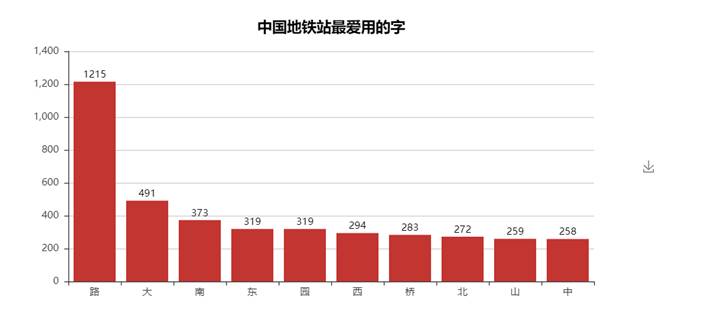
10.统计中国城轨的单字频率
11.生成统计了中国地铁站最爱用的名字的柱状图

12.编写不同城市的城轨数据
13.绘制折线图分布

14.绘制天津的折线图
15.绘制上海各线路站点数量的折线图

16.绘制哈尔滨各线路站点数量的折线图

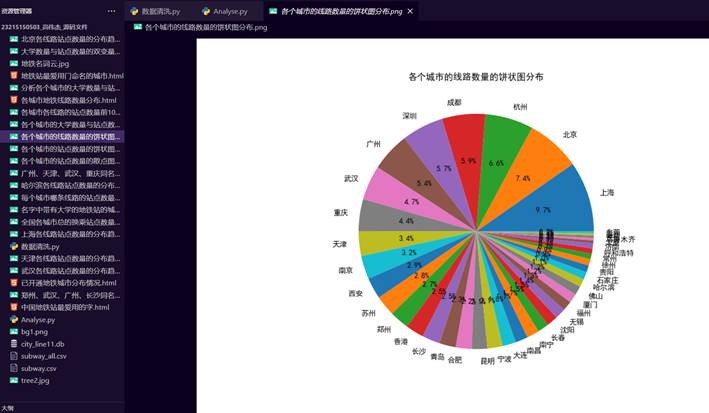
17.绘制各个城市的线路数量的饼状图分布

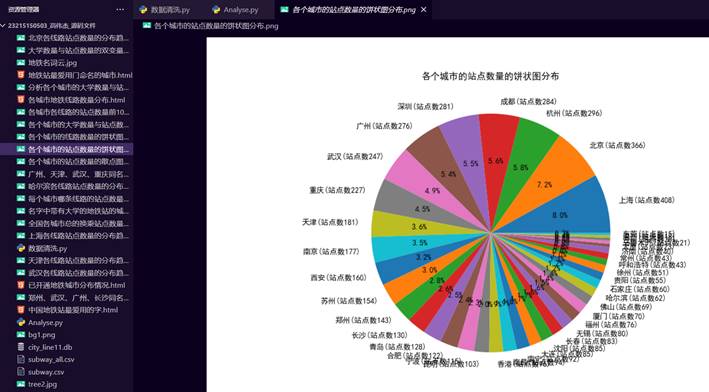
18.绘制各个城市的站点数量的饼状图分布
并通过去除每个城市的重复换乘站点数,得到实际数量的站点 数量

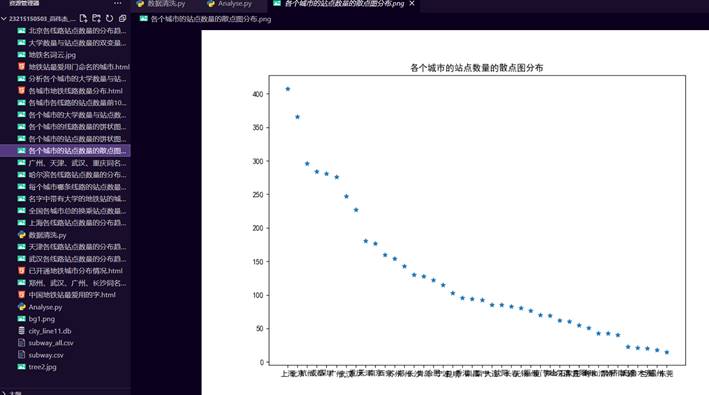
19.进行散点图的绘制和展示
20.绘制站点数量前十的数量变化

21.运行.py文件并查看控制台输出:
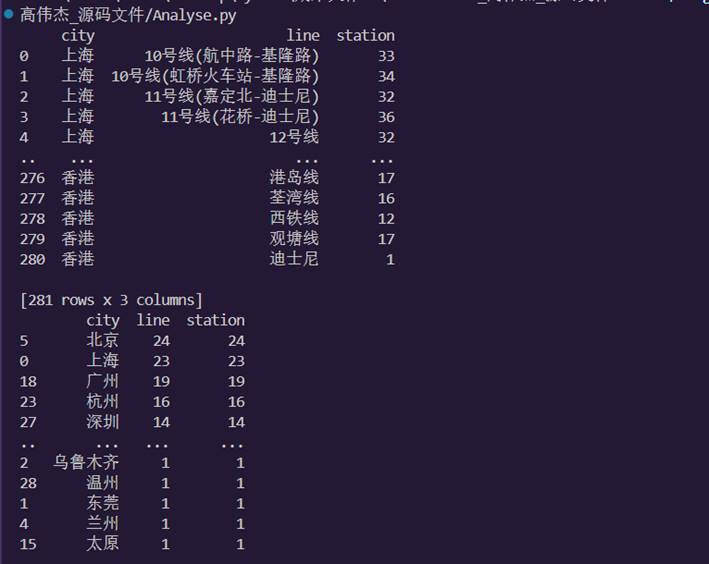
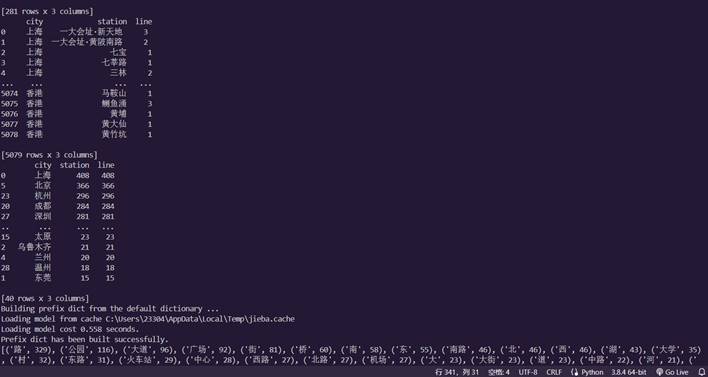
22.可以发现,右边的项目目录下生成了许多的散点图和折线图和 柱状图等图片和管理这些图片的HTML文件
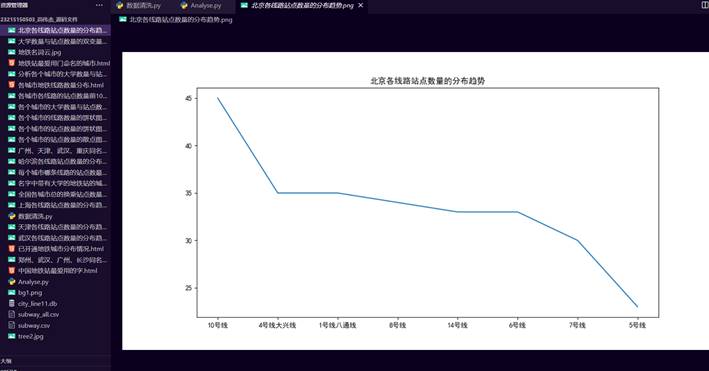
23.这是北京各线路站点数量的分布趋势图
24.这是大学数量与站点数量的双变量图
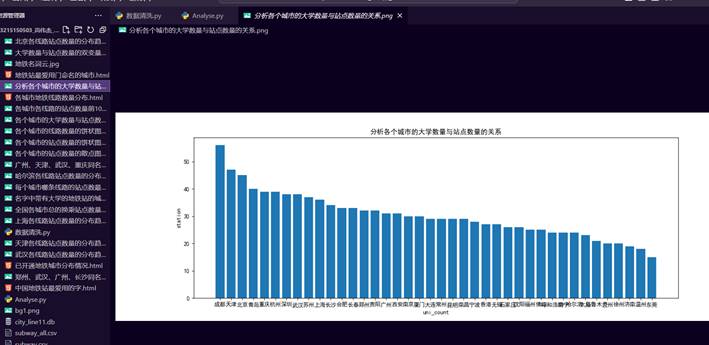
25.分析全国各个城市的大学数量与站点数量的关系图
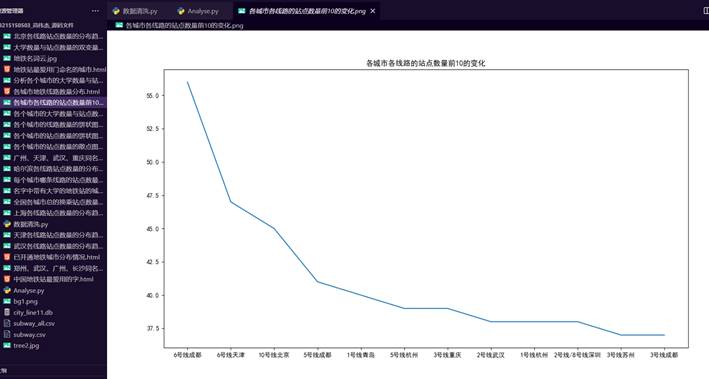
26.全国各城市线路的站点数量的前十变化图
27.各个城市的大学数量与站点数量的关系图
28.各个城市的线路数量的饼状图分布
29.各个城市的站点数量的饼状图分布
30.各个城市的站点数量的散点图分布
31.各个城市的站点数量分布图
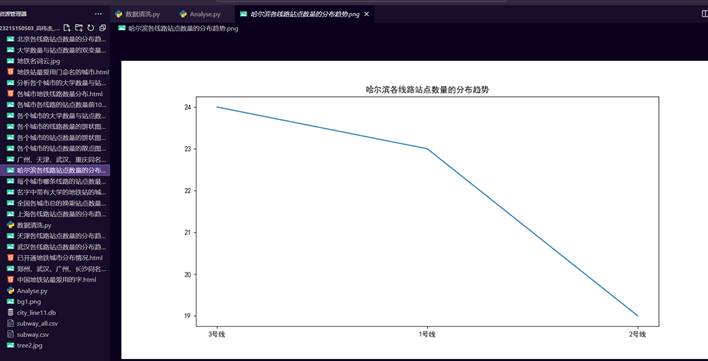
32.哈尔滨各线路站点数量的分布趋势图
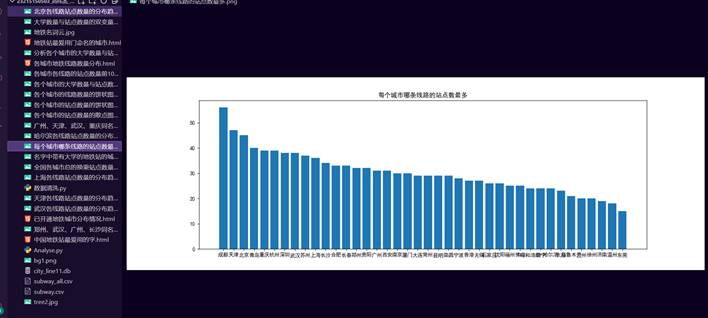
33.统计全国哪些城市线路的站点数量最多的数据统计图
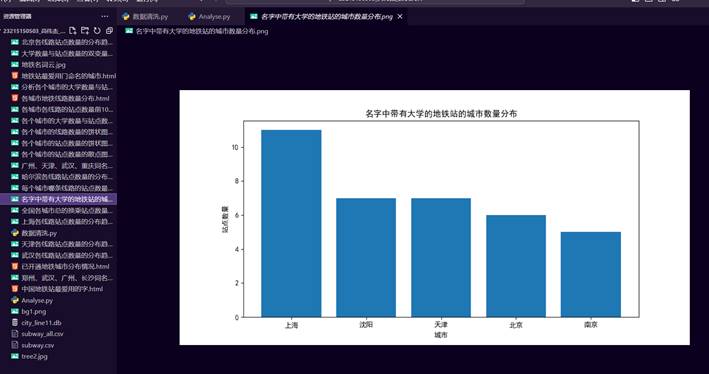
34.带有大学这个词的地铁站在全国不同城市的数量分布图
35.全国各城市总的换乘站点数量图

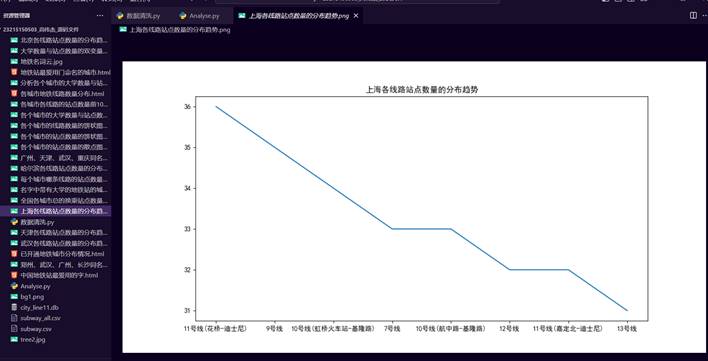
36.上海各线路站点数量的分布趋势
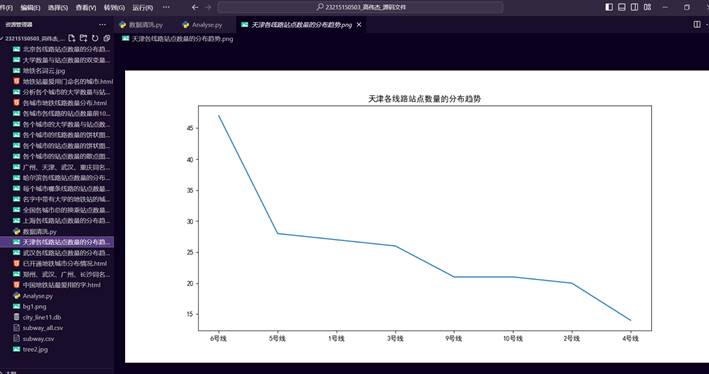
37.天津各线路站点数量的分布趋势
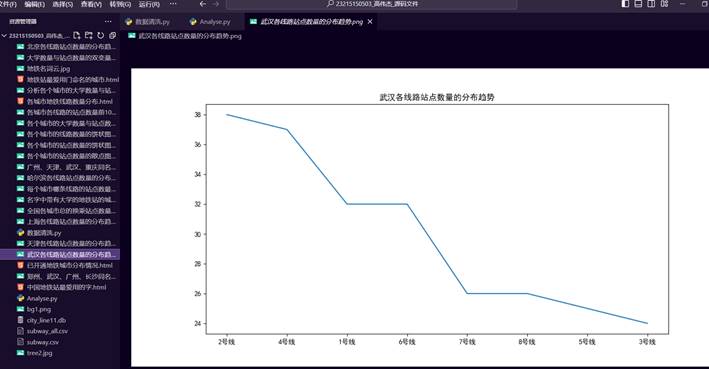
38.武汉各线路站点数量的分布趋势图
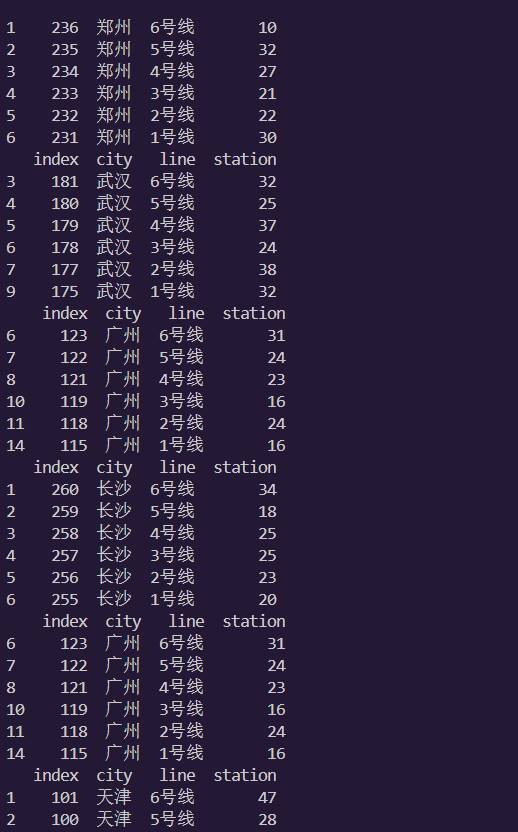
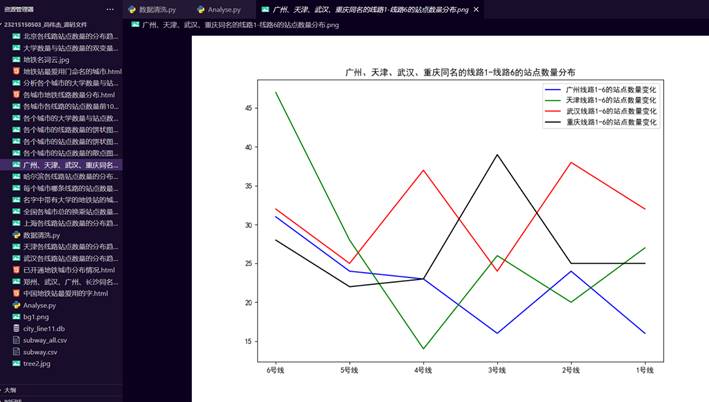
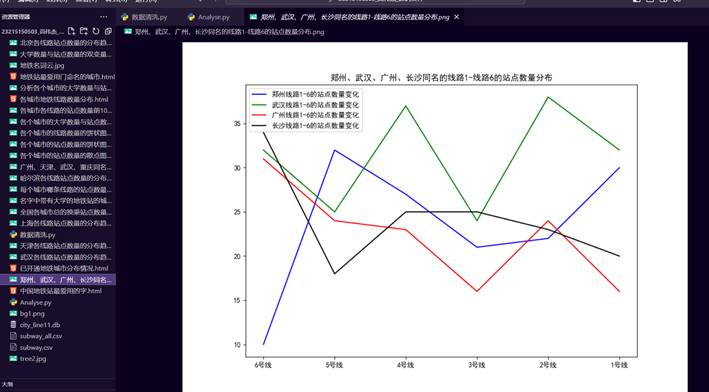
39.郑州、武汉、广州、长沙同名的线路站点数量分布图
40.地铁站最爱用”门”命名的城市

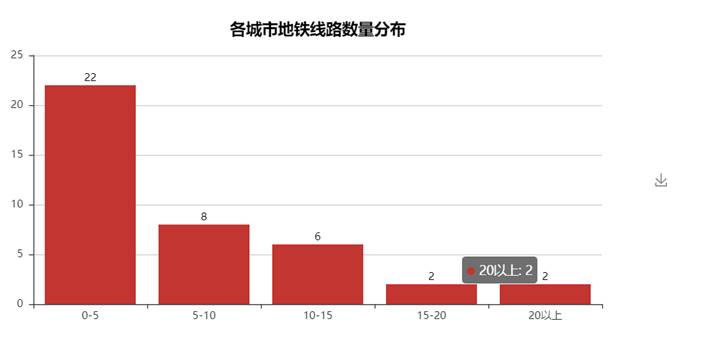
41.各城市地铁线路数量分布图
42.查看已经开通了地铁的城市分布情况
43.查看我国地铁站最爱用的字都有哪些排布图
结论与建议
结论
数据处理能力提升:通过本次实践,熟练掌握了使用Pandas进行数据清洗与分析的能力,特别是在处理实际城市轨道交通数据时,能够有效识别并处理数据集中的潜在问题,如缺失值和重复记录,确保后续分析的准确性。
可视化技能强化:利用matplotlib、pyecharts等工具,实现了对中国城市轨道交通数据的多样化可视化展示,包括但不限于地铁线路分布地图、线路数量的柱状图、站点数量的折线图以及站点命名的词云分析。这些可视化不仅丰富了数据表达形式,而且增强了数据分析的直观性和说服力。
深入洞察城轨交通:实践过程中,通过数据挖掘和分析,发现了城市轨道交通系统发展的若干特点,比如特定城市地铁线路与站点数量的显著增长、线路命名规律以及与城市其他因素(如大学数量)的关联性,这些发现为理解城市交通布局和规划提供了新的视角。
技术栈拓展:实践还涉及到了Numpy的高维数据计算、Sklearn的机器学习基础应用,以及中文分词工具jieba的使用,这不仅加深了对Python数据科学生态的理解,也为解决复杂数据问题提供了更多工具和思路。
建议
数据质量持续监控:虽然本次实践中数据清洗工作相对顺利,但在未来项目中应考虑建立更完善的数据质量监控机制,确保数据实时更新与维护,及时发现并修正错误,提高分析的时效性和准确性。
深化分析维度:进一步结合城市人口密度、经济发展水平、交通拥堵指数等多元数据,进行综合分析,以便更全面地评估城市轨道交通的运行效率和对城市发展的贡献度,为政策制定者提供更为精准的决策依据。
增强交互体验:探索开发基于Web的动态交互式可视化平台,用户可以通过筛选条件、时间序列等自定义参数,动态查看不同维度下的城轨交通数据,提升用户体验和数据的可用性。
产学研合作:鼓励与城市规划部门、交通研究机构及高校的产学研合作,共享数据资源,共同研究城轨交通发展的前沿问题,推动理论与实践的深度融合,为我国城市可持续发展贡献力量。
技术创新与应用:继续探索人工智能、大数据等新技术在城市轨道交通数据分析与预测中的应用,比如利用机器学习模型预测未来城轨需求,优化线路规划,提高城市交通系统的智能化水平。
这篇关于深入分析并可视化城市轨道数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






