本文主要是介绍OpenTSDB安装,配置,数据存储介绍,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.什么是OpenTSDB2.OpenTSDB是用什么语言编写和构建的?
3.如何安装OpenTSDB?
1. OpenTSDB介绍
OpenTSDB用HBase存储所有的时序(无须采样)来构建一个分布式、可伸缩的时间序列数据库。它支持秒级数据采集所有metrics,支持永久存储,可以做容量规划,并很容易的接入到现有的报警系统里。OpenTSDB可以从大规模的集群(包括集群中的网络设备、操作系统、应用程序)中获取相应的metrics并进行存储、索引以及服务,从而使得这些数据更容易让人理解,如web化、图形化等。
对于运维工程师而言,OpenTSDB可以获取基础设施和服务的实时状态信息,展示集群的各种软硬件错误,性能变化以及性能瓶颈。对于管理者而言,OpenTSDB可以衡量系统的SLA,理解复杂系统间的相互作用,展示资源消耗情况。集群的整体作业情况,可以用以辅助预算和集群资源协调。对于开发者而言,OpenTSDB可以展示集群的主要性能瓶颈,经常出现的错误,从而可以着力重点解决重要问题。
OpenTSDB使用LGPLv2.1+开源协议,目前版本为2.X。
- 官网地址:http://opentsdb.net/
- 源代码:https://github.com/OpenTSDB/opentsdb/
OpenTSDB依赖jdk和Gnuplot,Gnuplot需要提前安装,版本要求为最小4.2,最大4.4,执行以下命令安装即可:
OpenTSDB是用java编写的,但是项目构建不是用的java的方式而是使用的C、C++程序员构建项目的方式。运行时依赖:
- JDK 1.6
- asynchbase 1.3.0 (BSD)
- Guava 12.0 (ASLv2)
- logback 1.0 (LGPLv2.1 / EPL)
- Netty 3.4 (ASLv2)
- SLF4J 1.6 (MIT) with Log4J and JCL adapters
- suasync 1.2 (BSD)
- ZooKeeper 3.3 (ASLv2)
可选的编译时依赖:
- GWT 2.4 (ASLv2)
可选的单元测试依赖:
- Javassist 3.15 (MPL / LGPL)
- JUnit 4.10 (CPL)
- Mockito 1.9 (MIT)
- PowerMock 1.4 (ASLv2)
首先安装必要依赖:
下载源代码,可以指定最新版本或者手动checkout
2.3 安装
- 1. 首先安装一个单节点或者多节点集群的hbase环境,hbase版本要求为0.94
- 2. 设置环境变量并创建opentsdb使用的表,需要设置的环境变量为COMPRESSION和HBASE_HOME,前者设置是否启用压缩,或者设置hbase home目录。如果使用压缩,则还需要安装lzo
- 3. 执行建表语句src/create_table.sh
- 4. 启动TSD
如果你使用的是hbase集群,则你还需要设置--zkquorum,--cachedir对应的目录会产生一些临时文件,你可以设置cron定时任务进行删除。添加--auto-metric,则当新的数据被搜集时自动创建指标。
你可以将这些参数编写到配置文件中,然后通过--config指定该文件所在路径。
- 5. 启动成功之后,你可以通过127.0.0.1:4242进行访问。
从源代码安装gnuplot、autoconf、opentsdb以及tcollector,可以参考: OpenTSDB & tcollector 安装部署(Installation and Deployment)
3. 使用向导
3.1 配置
OpenTSDB的配置参数可以在命令行指定,也可以在配置文件中指定。配置文件使用的是java的properties文件,文件中key为小写,支持逗号连接字符串但是不能有空格。所有的OpenTSDB属性都以tsdb开头,例如:
配置参数优先级:
命令行参数 > 配置文件 > 默认值
你可以在命令行中通过--config指定配置文件所在路径,如果没有指定,OpenTSDB会从以下路径寻找配置文件:
- ./opentsdb.conf
- /etc/opentsdb.conf
- /etc/opentsdb/opentsdb.conf
- /opt/opentsdb/opentsdb.conf
如果一个合法的配置文件没有找到并且一些必须参数没有设置,TSD进程将不会启动。
配置文件中可配置的属性请参考: Properties
3.2 基本概念
在深入理解OpenTSDB之前,需要了解一些基本概念。
- Cardinality。基数,在数学中定义为一个集合中的一些元素,在数据库中定义为一个索引的一些唯一元素,在OpenTSDB定义为:
- 一个给定指标的一些唯一时间序列
- 和一个标签名称相关联的一些唯一标签值
在OpenTSDB中拥有高基数的指标在查询过程中返回的值要多于低基数的指标,这样花费的时间也就越多。
Compaction。在OpenTSDB中,会将多列合并到一列之中以减少磁盘占用空间,这和hbase中的Compaction不一样。这个过程会在TSD写数据或者查询过程中不定期的发生。
Data Point。每一个指标可以被记录为某一个时间点的一个数值。Data Point包括以下部分:
- 一个指标:metric
- 一个数值
- 这个数值被记录的时间戳
- 多个标签
Metric。一个可测量的单位的标称。metric不包括一个数值或一个时间,其仅仅是一个标签,包含数值和时间的叫datapoints,metric是用逗号连接的不允许有空格,例如:
- hours.worked
- webserver.downloads
- accumulation.snow
Tags。一个metric应该描述什么东西被测量,在OpenTSDB中,其不应该定义的太简单。通常,更好的做法是用Tags来描述具有相同维度的metric。Tags由tagk和tagv组成,前者表示一个分组,后者表示一个特定的项。
Time Series。一个metric的带有多个tag的data point集合。
Timestamp。一个绝对时间,用来描述一个数值或者一个给定的metric是在什么时候定义的。
Value。一个Value表示一个metric的实际数值。
UID。在OpenTSDB中,每一个metric、tagk或者tagv在创建的时候被分配一个唯一标识叫做UID,他们组合在一起可以创建一个序列的UID或者TSUID。在OpenTSDB的存储中,对于每一个metric、tagk或者tagv都存在从0开始的计数器,每来一个新的metric、tagk或者tagv,对应的计数器就会加1。当data point写到TSD时,UID是自动分配的。你也可以手动分配UID,前提是auto metric被设置为true。默认地,UID被编码为3Bytes,每一种UID类型最多可以有16,777,215个UID。你也可以修改源代码改为4Bytes。UID的展示有几种方式,最常见的方式是通过http api访问时,3 bytes的UID被编码为16进制的字符串。例如,UID为1的写为二进制的形式为000000000000000000000001,最为一个无符号的byte数组,其可以表示为[0,0,1],编码为16进制字符串为000001,其中每一位左边都被补上0,如果其不足两位。故,UID为255的会显示为[0,0,255]和0000FF。
关于为什么使用UID而不使用hashes,可以参考: why-uids
TSUID。当一个data point被写到OpenTSDB时,其row key格式为:<metric_UID><timestamp><tagk1_UID><tagv1_UID>[...<tagkN_UID><tagvN_UID>],不考虑时间戳的话,将其余部分都转换为UID,然后拼在一起,就可以组成为TSUID。
Metadata。主要用于记录data point的一些附加的信息,方便搜索和跟踪,分为UIDMeta和TSMeta。
每一个UID都有一个metadata记录保存在tsdb-uid表中,每一个UID包括一些不可变的字段,如uid、type、name和created字段表示什么时候被创建,还可以有一些额外字段,如description、notes、displayName和一些custom key/value对,详细信息,可以查看 /api/uid/uidmeta
同样,每一个TSUID可以对应一个TSMeta,记录在tsdb-uid中,其包括的字段有tsuid、metric、tags、lastReceived和created,可选的字段有description, notes,详细信息,可以查看 /api/uid/tsmeta
开启Metadata有以下几个参数:
- tsd.core.meta.enable_realtime_uid
- tsd.core.meta.enable_tsuid_tracking
- tsd.core.meta.enable_tsuid_incrementing
- tsd.core.meta.enable_realtime_ts
metadata的另外一个形式是Annotations,详细说明,请参考 annotations
Tree
3.3 数据存储方式
OpenTSDB使用HBase作为后端存储,在安装OpenTSDB之前,需要先启动一个hbase节点或者集群,然后再执行建表语句src/create_table.sh创建hbase表。建表语句如下:
从上面可以看出一共创建了4张表,并且可以设置是否压缩、是否启用布隆过滤、保存版本号等等,如果追求hbase读写性能,还可以预建分区。
3.3.1 Data Table Schema
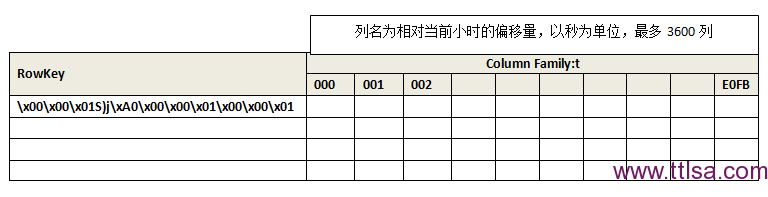
在OpenTSDB中,所有数据存储在一张叫做tsdb的表中,这是为了充分利用hbase有序和region分布式的特点。所有的值都保存在列族t中。
rowkey为<metric_uid><timestamp><tagk1><tagv1>[...<tagkN><tagvN>],UID默认编码为3 Bytes,而时间戳会编码为4 Bytes
OpenTSDB的tsdb启动之后,会监控指定的socket端口(默认为4242),接收到监控数据,包括指标、时间戳、数据、tag标签,tag标签包括tag名称ID和tag值ID。例如:
对于指标myservice.latency.avg的ID为:[0, 0, -69],reqtype标签名称的ID为:[0, 0, 1], foo标签值的ID为:[0, 1, 11], 标签名称的ID为:[0, 0, 2] web42标签值的ID为:[0, -7, 42],他们组成rowkey:
row表示格式为: 每个数字对应1 byte
- [0, 0, -69] metric ID
- [77, 4, -99, 32] base timestamp = 1292148000. timestamps in the row key are rounded down to a 60 minute boundary。也就是说对于同一个小时的metric + tags相同的数据都会存放在一个row下面
- [0, 0, 1] “reqtype” index
- [0, 1, 11] “foo” index
- [0, 0, 2] “host” index
- [0, -7, 42] “web42″ index
NOTE:可以看到,对于metric + tags相同的数据都会连续存放,且metic相同的数据也会连续存放,这样对于scan以及做aggregation都非常有帮助
column qualifier 占用2 bytes或者4 bytes,占用2 bytes时表示以秒为单位的偏移,格式为:
- 12 bits:相对row表示的小时的delta, 最多2^ 12 = 4096 > 3600因此没有问题
- 4 bits:format flags
- 1 bit: an integer or floating point
- 3 bits: 标明数据的长度,其长度必须是1、2、4、8。000表示1个byte,010表示2byte,011表示4byte,100表示8byte
占用4 bytes时表示以毫秒为单位的偏移,格式为:
- 4 bits:十六进制的1或者F
- 22 bits:毫秒偏移
- 2 bit:保留
- 4 bits: format flags
- 1 bit: an integer or floating point,0表示整数,1表示浮点数
- 3 bits: 标明数据的长度,其长度必须是1、2、4、8。000表示1个byte,010表示2byte,011表示4byte,100表示8byte
举例:
对于时间戳为1292148123的数据点来说,其转换为以小时为单位的基准时间(去掉小时后的秒)为129214800,偏移为123,转换为二进制为1111011,因为该值为整数且长度为8位(对应为2byte,故最后3bit为100),故其对应的列族名为:0000011110110100,将其转换为十六进制为07B4
value 使用8bytes存储,既可以存储long,也可以存储double。
总结一下,tsdb表结构如下:
3.3.2 UID Table Schema
一个单独的较小的表叫做tsdb-uid用来存储UID映射,包括正向的和反向的。存在两列族,一列族叫做name用来将一个UID映射到一个字符串,另一个列族叫做id,用来将字符串映射到UID。列族的每一行都至少有以下三列中的一个:
- metrics 将metric的名称映射到UID
- tagk 将tag名称映射到UID
- tagv 将tag的值映射到UID
如果配置了metadata,则name列族还可以包括额外的metatata列。
- id 列族
Row Key – 将会是一个分配到UID的字符串,例如,对于一个指标可能有一个值为sys.cpu.user或者对于一个标签其值可能为42
Column Qualifiers – 上面三种列类型中一种。
Column Value – 一个无符号的整数,默认被编码为3个byte,其值为UID。
例如以下几行数据是从tsdb-uid表中查询出来的数据,第一个列为row key,第二列为”列族:列名”,第三列为值,对应为UID
- name 列族
Row Key – 为UID
Column Qualifiers – 上面三种列类型中一种或者为metrics_meta、tagk_meta、tagv_meta
Column Value – 与UID对应的字符串,对于一个*_meta列,其值将会是一个UTF-8编码的JSON格式字符串。不要在OpenTSDB外部去修改该值,其中的字段顺序会影响CAS调用。
例如,以下几行数据是从tsdb-uid表中查询出来的数据,第一个列为row key,第二列为”列族:列名”,第三列为值,对应为UID
总结一下,tsdb-uid表结构如下:

上图对应的一个datapoint如下:
从上图可以看出tsdb-uid的表结构以及数据存储方式,对于一个data point来说,其被保存到opentsdb之前,会对metrics、tagk、tagv、metric_meta、tagk_meta、tagv_meta生成一个UID(如上图中的000001),然后将其插入hbase表中,rowkey为UID,同时会存储多行记录,分别保存metrics、tagk、tagv、metric_meta、tagk_meta、tagv_meta到UID的映射。
3.3.3 Meta Table Schema
这个表是OpenTSDB中不同时间序列的一个索引,可以用来存储一些额外的信息。这个表名称叫做tsdb-meta,该表只有一个列族name,两个列,分别为ts_meta、ts_ctr,该表中数据如下:
Row Key 和tsdb表一样,其中不包含时间戳,<metric_uid><tagk1><tagv1>[...<tagkN><tagvN>]
TSMeta Column 和UIDMeta相似,其为UTF-8编码的JSON格式字符串
ts_ctr Column 计数器,用来记录一个时间序列中存储的数据个数,其列名为ts_ctr,为8位有符号的整数。
索引表,用于展示树状结构的,类似于文件系统,以方便其他系统使用,例如:Graphite
3.4 如何写数据
3.5 如何查询数据
3.6 CLI Tools
tsdb支持以下参数:
通过以下命令创建指标:
执行上述命令的结果如下:
4. HTTP API 5. 谁在用OpenTSDB
- StumbleUpon StumbleUpon is the easiest way to find cool new websites, videos, photos and images from across the Web
- box Box simplifies online file storage, replaces FTP and connects teams in online workspaces.
- tumblr 一个轻量级博客,用户可以跟进其他的会员并在自己的页面上看到跟进会员发表的文章,还可以转发他人在Tumblr上的文章
KairosDB是一个快速可靠的分布式时间序列数据库,主要用于Cassandra当然也可以适用与HBase。KairosDB是在OpenTSDB基础上重写的,他不仅可以在HBase上存储数据还支持Cassandra。
KairosDB主页: https://code.google.com/p/kairosdb/
这篇关于OpenTSDB安装,配置,数据存储介绍的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








