本文主要是介绍从零开始的Ollama指南:部署私域大模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
大模型相关目录
大模型,包括部署微调prompt/Agent应用开发、知识库增强、数据库增强、知识图谱增强、自然语言处理、多模态等大模型应用开发内容
从0起步,扬帆起航。
- 大模型应用向开发路径:AI代理工作流
- 大模型应用开发实用开源项目汇总
- 大模型问答项目问答性能评估方法
- 大模型数据侧总结
- 大模型token等基本概念及参数和内存的关系
- 大模型应用开发-华为大模型生态规划
- 从零开始的LLaMA-Factory的指令增量微调
- 基于实体抽取-SMC-语义向量的大模型能力评估通用算法(附代码)
- 基于Langchain-chatchat的向量库构建及检索(附代码)
- 一文教你成为合格的Prompt工程师
- 最简明的大模型agent教程
- 批量使用API调用langchain-chatchat知识库能力
- langchin-chatchat部分开发笔记(持续更新)
- 文心一言、讯飞星火、GPT、通义千问等线上API调用示例
- 大模型RAG性能提升路径
- langchain的基本使用
- 结合基础模型的大模型多源信息应用开发
- COT:大模型的强化利器
- 多角色大模型问答性能提升策略(附代码)
- 大模型接入外部在线信息提升应用性能
- 从零开始的Dify大模型应用开发指南
- 基于dify开发的多模态大模型应用(附代码)
- 基于零一万物多模态大模型通过外接数据方案优化图像文字抽取系统
- 快速接入stable diffusion的文生图能力
- 多模态大模型通过外接数据方案实现电力智能巡检(设计方案)
- 大模型prompt实例:知识库信息质量校验模块
- 基于Dify的LLM-RAG多轮对话需求解决方案(附代码)
- Dify大模型开发技巧:约束大模型回答范围
- 以API形式调用Dify项目应用(附代码)
- 基于Dify的QA数据集构建(附代码)
- Qwen-2-7B和GLM-4-9B:大模型届的比亚迪秦L
- 文擎毕昇和Dify:大模型开发平台模式对比
- Qwen-VL图文多模态大模型微调指南
- 从零开始的Ollama指南:部署私域大模型
文章目录
- 大模型相关目录
- Olama简介
- 下载更新
- 模型下载(https://ollama.com/library)
- 修改环境变量
- 模型对话
- 运行模型
- 更多应用示例参考:
Olama简介
Olama是一个旨在简化大型语言模型本地部署和运行过程的工具。它提供了一个轻量级、易于扩展的框架,让开发者能够在本地机器上轻松构建和管理LLMS。通过Olama,开发者可以访问和运行一系列预构建的模型,并与其他开源项目、应用程序进行耦合实现大模型应用开发。
Ollama支持多场家、多尺寸、多模态的各类大模型。此外,还提供Chinese-中文模型、Embedding-嵌入、Multimodal-多模态、Code-编码模型、RAG-检索增强生成、SLM-小语言模型、Medical-医学模型、Cybersecurity-网络安全等模型。
下载更新
curl -fsSL https://ollama.com/install.sh | sh
模型下载(https://ollama.com/library)
ollama pull llama2
ollama pull wizardlm2:8x22b

上述指令也可由上图内容代替,选定厂家、参数规模、量化格式后即可使用对应的指令运行,若本地服务器没有模型,则默认下载。
修改环境变量
使用root权限打开文件:
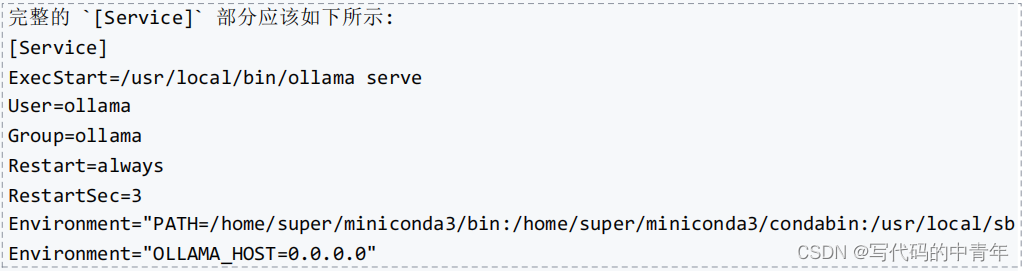
sudonano/etc/systemd/system/ollama.service
找到[Service]部分,在最后一行添加:
Environment="OLLAMA_HOST=0.0.0.0"
sudo nano ollama.service
指定显卡
Environment="CUDA_VISIBLE_DEVICES=0,1"
设定并发
Environment="OLLAMA_NUM_PARALLEL=16"
设定模型存活时间
Environment="OLLAMA_KEEP_ALIVE=24h"
设定可同时加载模型数量
Environment="OLLAMA_MAX_LOADED_MODELS=4"
指定存储位置
Environment="OLLAMA_MODELS=/data/ollama/models"
按下Ctrl+X保存并退出。系统会提示您是否要保存修改,输入y回车即可。
重新加载systemd配置并重启Ollama服务:
sudosystemctldaemon-reload
sudosystemctlrestartollama
模型对话
运行模型
ollama pull llama2
pip install -r requirements.txt
import jsonimport requests# NOTE: ollama must be running for this to work, start the ollama app or run `ollama serve`model = "llama2" # TODO: update this for whatever model you wish to usedef chat(messages):r = requests.post("http://0.0.0.0:11434/api/chat",json={"model": model, "messages": messages, "stream": True},)r.raise_for_status()output = ""for line in r.iter_lines():body = json.loads(line)if "error" in body:raise Exception(body["error"])if body.get("done") is False:message = body.get("message", "")content = message.get("content", "")output += content# the response streams one token at a time, print that as we receive itprint(content, end="", flush=True)if body.get("done", False):message["content"] = outputreturn messagedef main():messages = []while True:user_input = input("Enter a prompt: ")if not user_input:exit()print()messages.append({"role": "user", "content": user_input})message = chat(messages)messages.append(message)print("\n\n")if __name__ == "__main__":main()
若返回模型回复则成功
更多应用示例参考:
https://ollama.fan/getting-started/examples/001-python-simplechat/#running-the-example
这篇关于从零开始的Ollama指南:部署私域大模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







