本文主要是介绍网络爬虫设置代理服务器,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
1.获取代理 IP
2.设置代理 IP
3. 检测代理 IP 的有效性
4. 处理异常
如果希望在网络爬虫程序中使用代理服务器,就需要为网络爬虫程序设置代理服务器。
设置代理服务器一般分为获取代理 IP 、设置代理 IP 两步。接下来,分别对获取代理 IP 和设
置代理 IP 进行详细介绍。
1.获取代理 IP
代理 IP 主要有 3 种获取方式,它们分别是获取免费代理 IP 、获取付费代理 IP 和 ADSL
拨号,关于它们的介绍如下。
(1 )获取免费代理 IP 。免费代理 IP 基本没有成本,可以从免费代理网站(如快代理、全
网代理 IP 等)上找一些免费代理 IP ,测试可用后便可以收集起来备用,但使用这种方式获取
的可用代理 IP 相对较少。
(2 )获取付费代理 IP 。互联网上存在许多代理商,用户付费后便可以获得一些高质量的
代理 IP 。
(3 ) ADSL 拨号。 ADSL ( Asymmetric Digital Subscriber Line ,非对称数字用户线路)通
过拨号的方式上网,需要输入 ADSL 账号和密码。每次拨号都会更换一个新的 IP 地址,不过
ADSL 拨号操作起来比较麻烦。每切换一次 IP 地址,都要重新拨号。重拨期间还会处于短暂
断网的状态。
综上所述,免费代理 IP 是比较容易获取的,不过这类代理 IP 的质量不高,高度匿名代理
IP 比较少,有的代理 IP 很快会失效。如果大家对代理 IP 的质量要求比较高,或者需要大量
稳定的代理 IP ,那么建议选择一些正规的代理商进行购买。
2.设置代理 IP
在 Requests 中,设置代理 IP 的方式非常简单:只需要在调用请求函数时为 proxies 参数
传入一个字典。该字典包含了所需要的代理 IP ,其中字典的键为代理类型(如 http 或 https ),
字典的值为“代理类型 ://IP 地址 : 端口号”格式的字符串。例如,定义一个包含两个代理 IP 的
字典,代码如下。
proxies = { 'http': 'http://127.0.0.1:8070', 'https': 'https://10.10.1.10:1080',
} 接下来,通过一个例子演示如何从 IP 地址列表中随机选择一个 IP 地址,将该 IP 地址设
置为代理 IP ,之后基于该代理 IP 请求小兔鲜儿网首页,具体代码如下。
import requests
import random
# 代理 IP 地址的列表
proxy_list = [ {"http" : "http://101.200.127.149:3129"}, {"http" : "http://59.55.162.4:3256"}, {"http" : "http://180.122.147.76:3000"}, {"http" : "http://114.230.107.102:3256"}, {"http" : "http://121.230.211.163:3256"}
]
base_url = 'http://erabbit.itheima.net/#/'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/90.0.4430.212 Safari/537.36'}
# 发送 GET 请求,将 proxy_list 中任意一个 IP 地址设为代理
response = requests.get(base_url, headers=header, proxies= random.choice(proxy_list))
print(response.status_code)header请求头字段可以在网页按F12键,上方找到网络标识,然后点击下方有一个名称点进去,右边窗口下面就有User-Agent字段。
上述代码中,首先创建了包含 5 个 IP 地址的列表 proxy_list ,定义了代表小兔鲜儿网首页
URL 的变量 base_url ,定义了表示请求头的变量 header ;然后调用 get() 函数根据 base_url 请求
小兔鲜儿网首页,同时指定该请求的请求头为 header 且代理 IP 为 proxy_list 中的任意一个 IP
地址,以防止服务器识别出网络爬虫的身份而被禁止访问,并将服务器返回的响应赋值给变
量 response ;最后访问 response 的 status_code 属性获取响应状态码。
运行代码,输出如下结果。
200
从输出结果可以看出,程序成功访问了小兔鲜儿网首页。
需要说明的是,上述程序中使用的代理 IP 是免费的。由于使用时间不固定,这些代理 IP
一旦超出使用时间范围就会失效,此时再运行上述程序则会出现 ProxyError 异常,所以我们
在这里建议大家换用自己查找的代理 IP 。
3. 检测代理 IP 的有效性
互联网上有很多免费的代理 IP ,但这些 IP 地址并不都是有效的。因此需要对获取的免费
IP 地址进行检测,确定 IP 地址是否有效。检测代理 IP 有效性的过程比较简单,需要先遍历
收集的所有代理 IP ,将获取的每个代理 IP 依次设为代理,再通过该 IP 地址向网站发送请求。
如果请求成功,则说明该 IP 地址是有效的;如果请求失败,则说明该 IP 地址是无效的,需要
被剔除。
下面以 3.4.2 节的代理 IP 为例,为大家演示如何检测代理 IP 的有效性,具体代码如下
import requests
proxy_list = [ {"http" : "http://101.200.127.149:3129"}, {"http" : "http://59.55.162.4:3256"}, {"http" : "http://180.122.147.76:3000"}, {"http" : "http://114.230.107.102:3256"}, {"http" : "http://121.230.211.163:3256"}
]
base_url = 'http://erabbit.itheima.net/#/'
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64' 'AppleWebKit/537.36 (KHTML, like Gecko)' 'Chrome/90.0.4430.212 Safari/537.36'}
# 遍历代理 IP
for per_ip in proxy_list.copy(): try: # 发送 GET 请求,将获取的每个 IP 地址设置为代理response = requests.get(base_url, headers=header, proxies=per_ip, timeout=3) except: # 失败则输出 IP 地址无效,并将该 IP 地址从 proxy_list 列表中移除print(f'IP 地址:{per_ip.get("http")}无效') proxy_list.remove(per_ip) else: # 成功则输出 IP 地址有效print(f'IP 地址:{per_ip.get("http")}有效') 上述加粗部分的代码中,首先从 proxy_list 列表的副本遍历了每个 IP 地址 per_ip ;然后在 try
子句中调用 get() 函数发送了一个 GET 请求,并在发送该请求时将 per_ip 依次设置为代理,由代
理服务器代替程序向服务器转发请求;接着在 except 子句中处理了请求失败的情况,输出“ IP
地址: ××× 无效”,并将该 IP 地址从 proxy_list 列表中移除,确保 proxy_list 列表中只保留有效
的 IP 地址;最后在 else 子句中处理了请求成功的情况,输出“ IP 地址: ××× 有效”。
运行代码,输出如下结果。
IP 地址:http://101.200.127.149:3129 有效
IP 地址:http://59.55.162.4:3256 无效
IP 地址:http://180.122.147.76:3000 无效
IP 地址:http://114.230.107.102:3256 无效
IP 地址:http://121.230.211.163:3256 有效 从输出结果可以看出,这 5 个代理 IP 中有两个是有效的,其余 3 个都是无效的。
4. 处理异常
每个程序在运行过程中可能会遇到各种各样的问题,网络爬虫自然也不例外。
访问网站离不开网络的支撑。由于网络环境十分复杂,具有一定的不可控性,所以网络爬虫
每次访问网站后不一定能够成功地获得从服务器返回的数据。网络爬虫一旦在访问过程中遇
到一些网络问题(如 DNS 故障、拒绝连接等),就会导致程序引发异常并停止运行。
requests.exceptions 模块中定义了很多异常类型,常见的异常类型如表 3-2 所示。
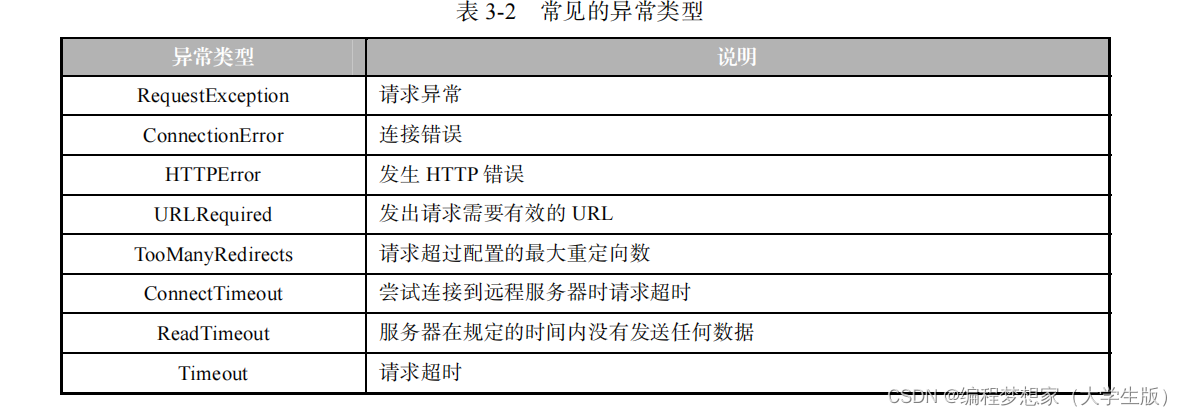 表 3-2 中罗列了一些常见的异常类型。其中,Timeout 继承自 RequestException,Connect Timeout 和 ReadTimeout 继承自 Timeout。 为保证程序能够正常终止,我们可以使用 try-except 语句捕获相应的异常,并对异常进行 相应的处理。 由于谷歌网站服务器的原因,访问该网站必定会出现连接超时的问题。下面以访问谷歌 网站为例,为大家演示如何使用 try-except 语句捕获 RequestException 异常,具体代码如下。
表 3-2 中罗列了一些常见的异常类型。其中,Timeout 继承自 RequestException,Connect Timeout 和 ReadTimeout 继承自 Timeout。 为保证程序能够正常终止,我们可以使用 try-except 语句捕获相应的异常,并对异常进行 相应的处理。 由于谷歌网站服务器的原因,访问该网站必定会出现连接超时的问题。下面以访问谷歌 网站为例,为大家演示如何使用 try-except 语句捕获 RequestException 异常,具体代码如下。
1 import time
2 import requests
3 # 记录请求的发起时间
4 print(time.strftime('开始时间:%Y-%m-%d %H:%M:%S'))
5 # 捕获 RequestException 异常
6 try:
7 html_str = requests.get('http://www.google.com').text
8 print('访问成功')
9 except requests.exceptions.RequestException as error:
10 print(error)
11 # 记录请求的终止时间
12 print(time.strftime('结束时间:%Y-%m-%d %H:%M:%S')) 上述代码中,第 4 行代码记录了发送请求之后的时间。第 6 ~ 10 行代码使用 try-except 语
句尝试捕获与处理 RequestException 异常。其中,第 6 ~ 8 行代码在 try 子句中调用 get() 函数
访问谷歌网站,并在访问成功后输出“访问成功”。第 9 ~ 10 行代码在 except 子句中指定了捕
获的异常类型为 RequestException 。程序监测到 try 子句中的代码抛出 RequestException 异常
时,会捕获 RequestException 和所有继承自 RequestException 的异常,并在捕获异常后输出详
细的异常信息。第 12 行代码记录了终止请求之后的时间。
运行代码,输出如下结果。
开始时间:2021-06-16 13:50:53
HTTPConnectionPool(host='www.google.com', port=80): Max retries exceeded with url:
/ (Caused by NewConnectionError('<urllib3.connection.HTTPConnection object at
0x00000000034D6790>: Failed to establish a new connection: [WinError 10060] 由于连接方
在一段时间后没有正确答复或连接的主机没有反应,连接尝试失败。'))
结束时间:2021-06-16 13:51:14 通过对比结束时间与开始时间可知,我们等待了约 20 秒,这个时间相对来说有些长,这
种长时间的等待是没有任何意义的。
为了减少无意义的等待,我们在发送 HTTP 请求时可以设置超时时长,即调用 get() 函数
时传入 timeout 参数,并给该参数指定代表超时时长的值。如果超过该时长,服务器仍然没有
返回任何响应内容,就让程序立即引发一个超时异常。在以上示例中,为请求设置超时时长
为 5 秒,具体代码如下。
# 发送 GET 请求,设置超时时长
html_str = requests.get('http://www.google.com', timeout=5).text再次运行代码,输出如下结果。
开始时间:2021-06-16 14:30:01
HTTPConnectionPool(host='www.google.com', port=80): Max retries exceeded with url:
/ (Caused by ConnectTimeoutError(<urllib3.connection.HTTPConnection object at
0x00000000033E23D0>, 'Connection to www.google.com timed out. (connect timeout=5)'))
结束时间:2021-06-16 14:30:06 通过对比结果中的结束时间和开始时间可知,程序执行了 5 秒后便直接结束,并抛出
ConnectTimeoutError 异常及提示信息“ Connection to www.google.com timed out ”。这说明连接
谷歌网站时超过了预设的等待时长而导致访问失败。
这篇关于网络爬虫设置代理服务器的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






