本文主要是介绍【开源项目】智慧北京案例~超经典实景三维数字孪生智慧城市CIM/BIM数字孪生可视化项目——开源工程及源码!,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
飞渡科技数字孪生北京管理平台, 依托实景数字孪生底座,以城市感知网络为硬件基础,以城市大数据为核心资源,以数字孪生、云计算、人工智能为关键技术,实现城市产业规划、资产安全管理、城市能耗监控等一体化空间融合。

利用自主研发DTS平台,根据数据源、使用环境和场景精细度,从宏观到微观对首都进行全要素场景构建,涵盖城市的道路、主要建筑、以及行政区划地名散点标牌,并对北京CBD中心区进行高精度还原。

在数字化地图上用不同的颜色展示城市行政区域的分布情况。
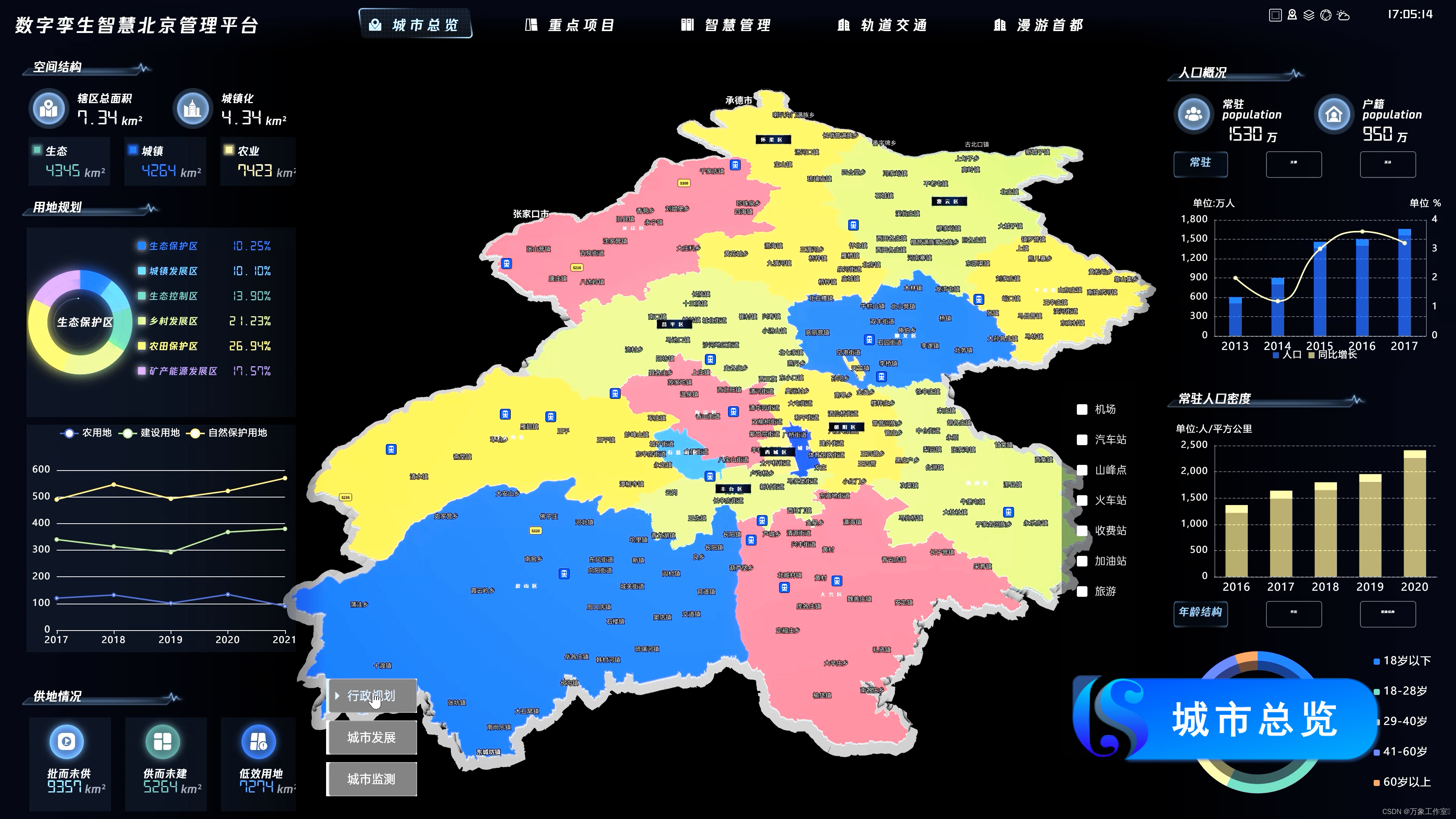
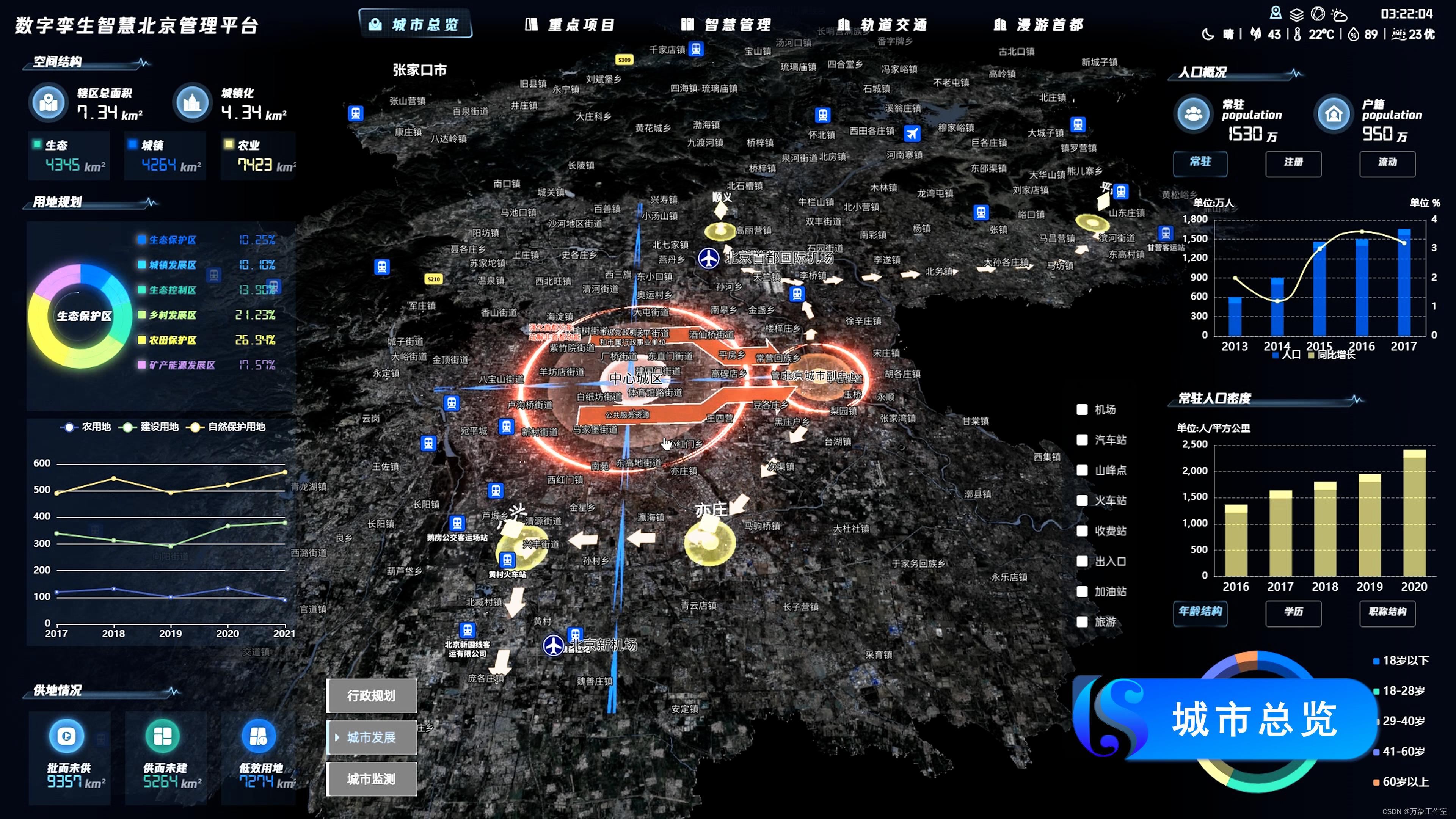
实现中心城区、副中心城区的物理空间与数字空间全时、全域、全要素映射,推动北京非首都功能疏解工作。
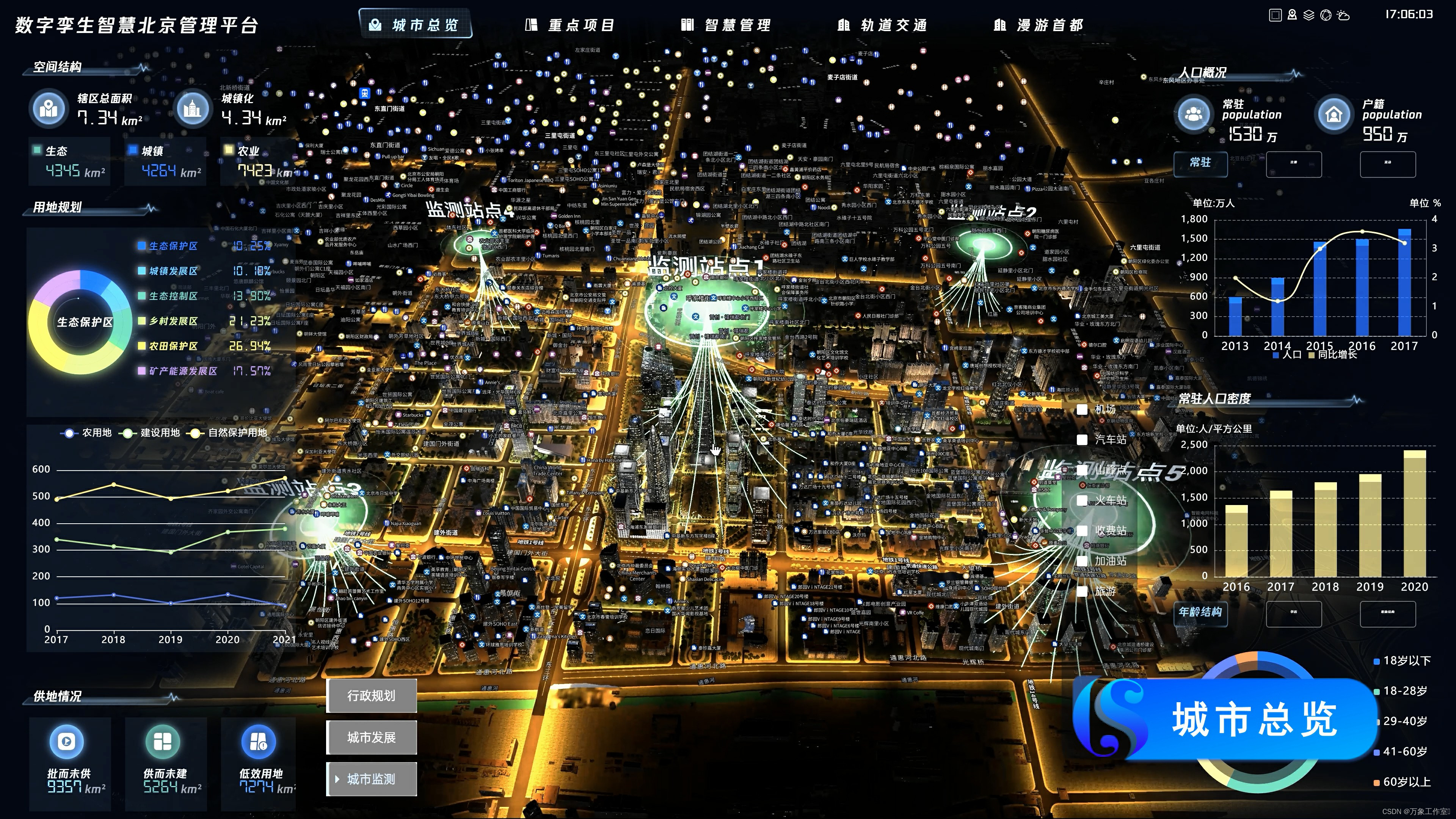
集成城市监测站点获取的多源时空大数据,提供多视角、多维度的城市动态感知。
以数据为基础搭建城市规划一张图的场景应用,监测城市重点楼宇,实时查看核心产业的分布情况。
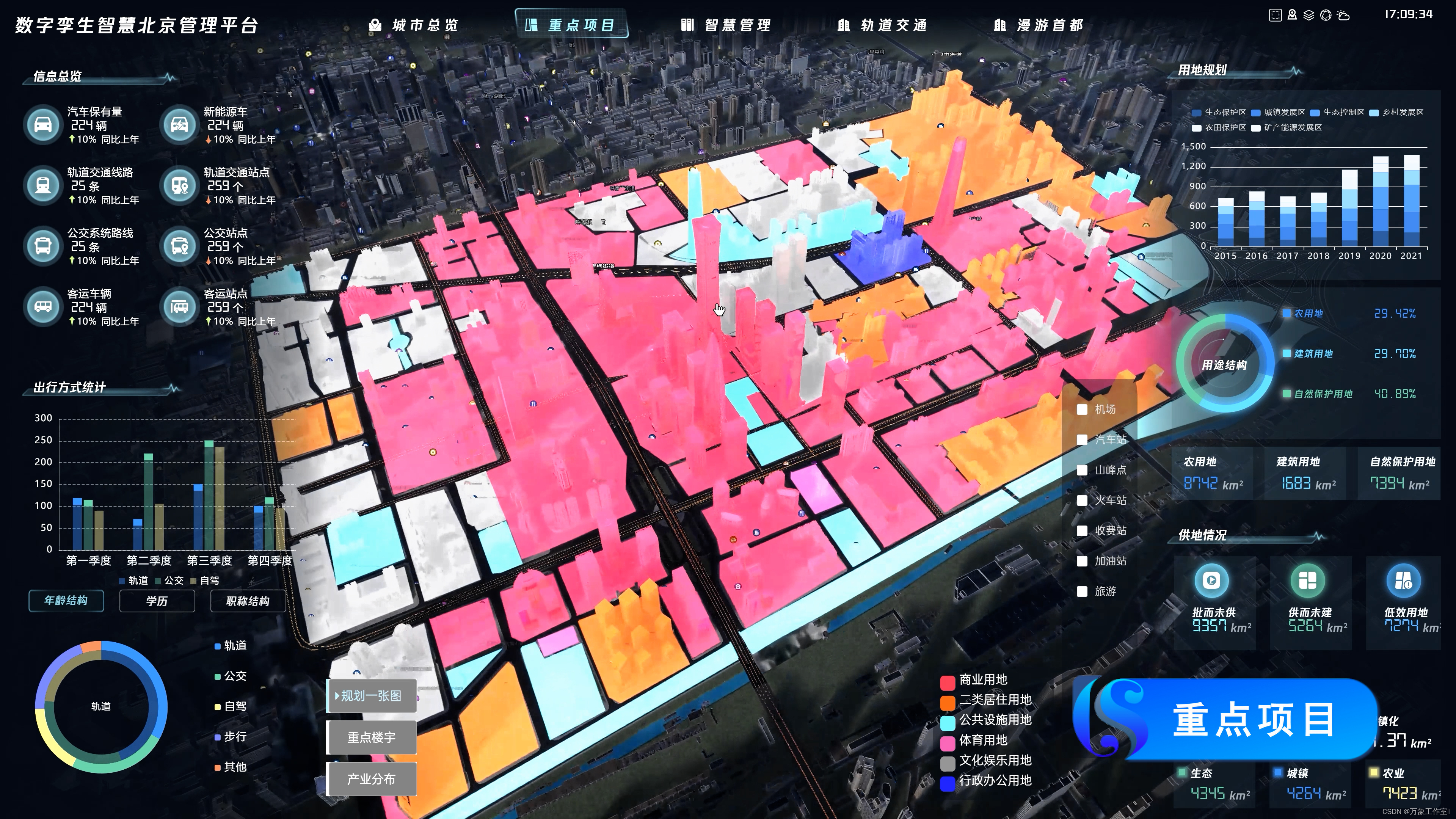
规范标准地址、可实时查看人口、房屋、单位的详细情况。

确定各地块建筑高度、建筑密度等控制指标,为施政提供信息支撑。
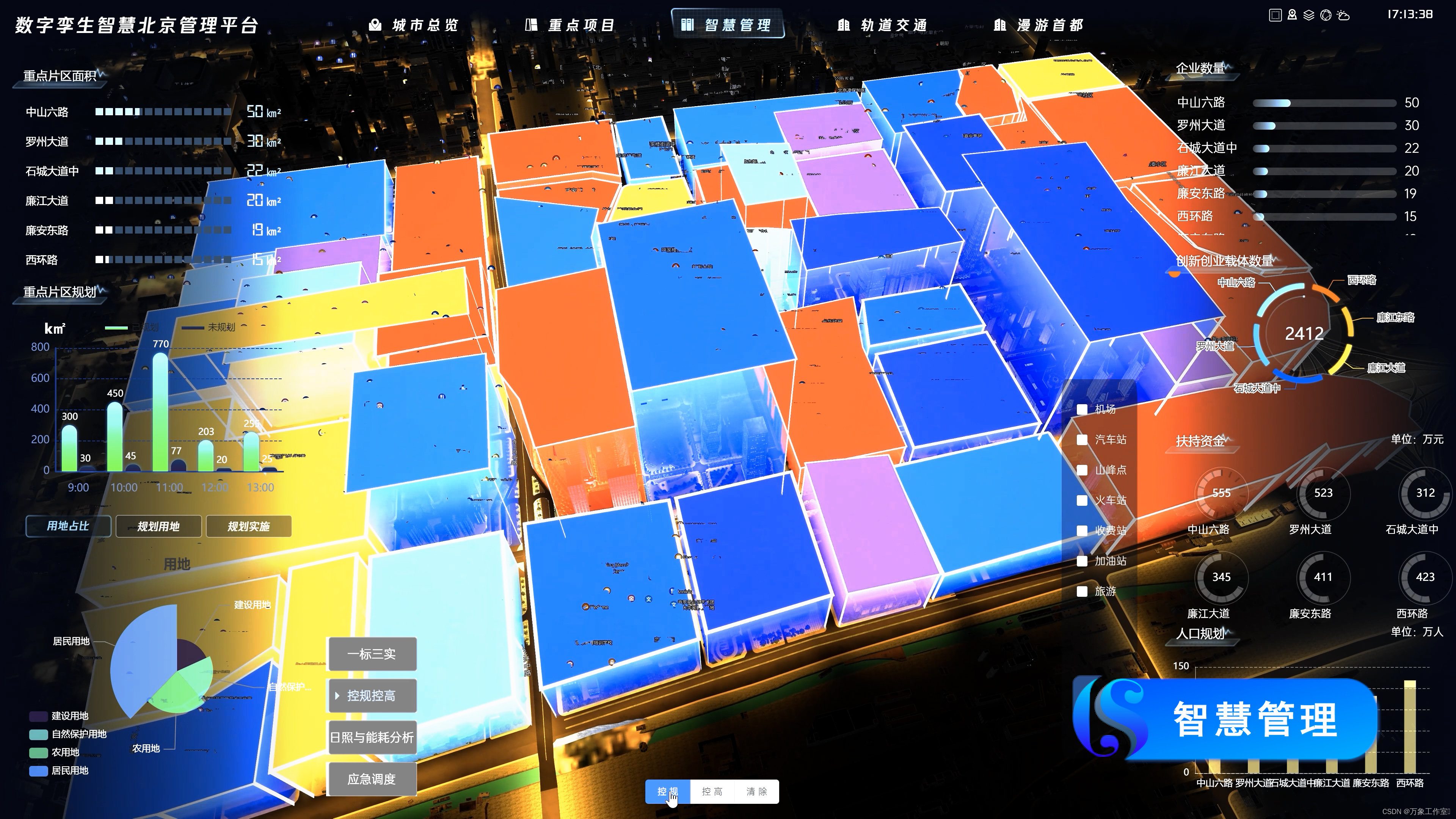
对接数字城市能源系统,通过绘制区域云图,可查看区域内能源消耗详情,实现城市能源系统全要素的数字化、虚拟化,和可视化。

对接数字城市公共安全系统,可查看突发事件应急救援指挥中心,形成完整、统一、高效的应急管理与协调指挥体系。
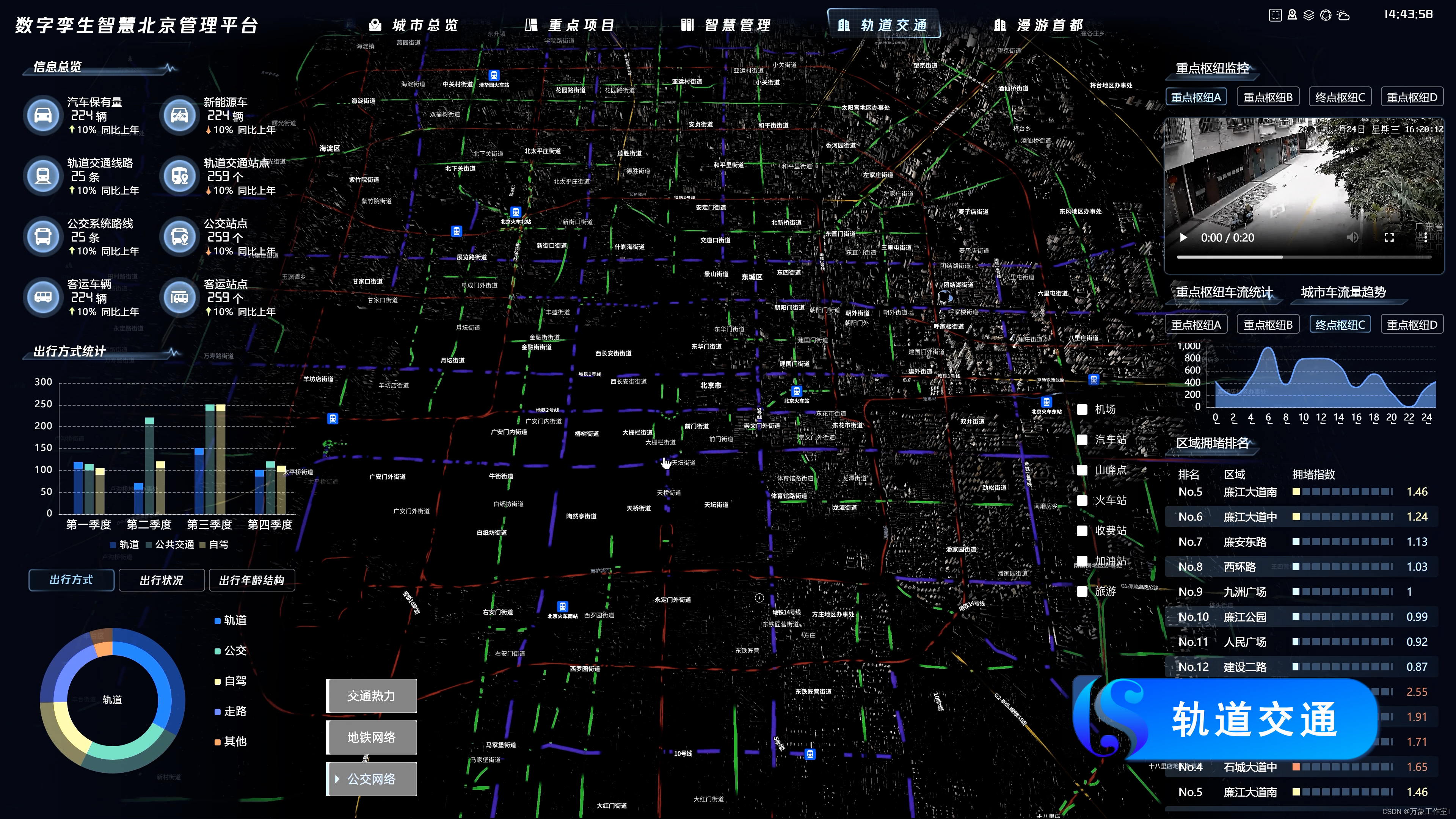
通过融合多源异构数据,搭建包含基础交通设施、动态车流、地理位置等信息的交通数字孪生底座,提供实时交通数据下的交通信息服务。
这篇关于【开源项目】智慧北京案例~超经典实景三维数字孪生智慧城市CIM/BIM数字孪生可视化项目——开源工程及源码!的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





