本文主要是介绍技术干货|如何快速提升SNMP监控性能,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!

作者:Arturs Lontons
Zabbix从6.4开始就对SNMP监控进行了重大改进,特别是在从单个设备采集大量指标时。这是通过利用主从监控项逻辑并将其与低级别自动发现和新引入的预处理规则相结合来完成的。这篇文章将介绍传统SNMP监控方法的缺点、新方法的优点以及部署批量SNMP指标采集所需的步骤。
以下是本文的主要内容
1、传统SNMP监控方法及其潜在隐患
2、使用主从监控项进行批量数据采集
3、通过批量指标采集提升SNMP监控性能
4、使用批量SNMP数据采集监控接口流量
4.1创建主监控项
4.2创建低级别自动发现规则
4.3创建监控项原型
5、最后的注意事项
本文翻译整理自Zabbix原厂官网博客栏目
戳这里👇回顾Zabbix原厂及产品动态:
升级提醒 | Zabbix Server 审计日志存在基于时间的SQL注入漏洞
01 传统SNMP监控方法—潜在隐患
让我们来看看大家都习惯的SNMP监控逻辑。对于此处的示例,我们将了解网络交换机上的网络接口发现。
首先,创建一个低级别自动发现规则。在发现规则中,指定从哪些 OID 采集哪些 LLD宏。这样,就可以创建多个 LLD宏和 OID 对。然后,Zabbix遍历指定 OID末尾的索引列表,并将采集的值与 LLD宏进行匹配。Zabbix还会采集指定 OID的已发现索引列表,并自动将它们与{#SNMPINDEX} LLD宏进行匹配。
常规 SNMP 自动发现监控项键值的示例:

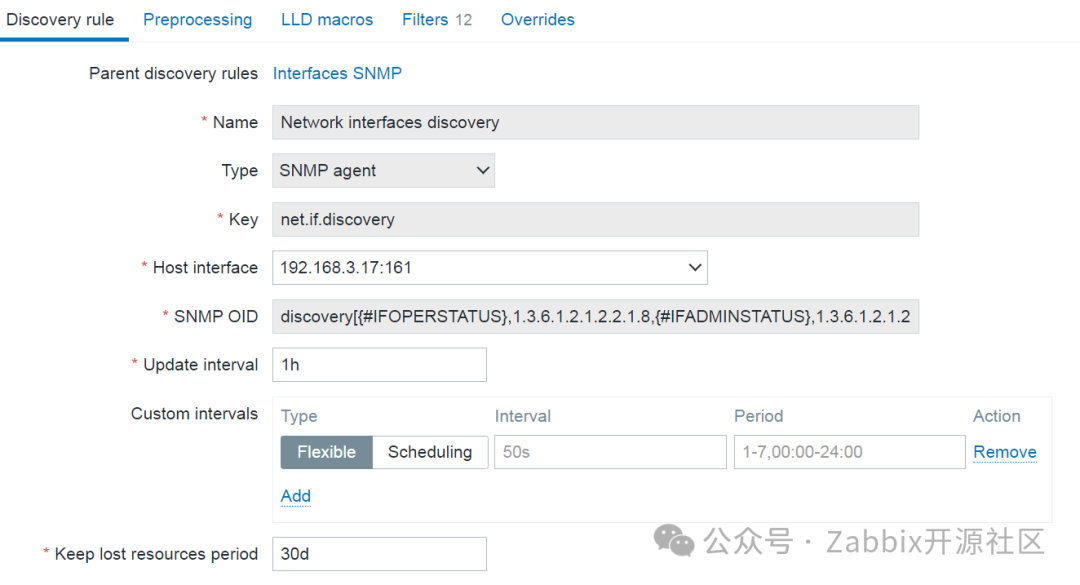
常规 SNMP 低级别自动发现规则的示例
采集的低级别自动发现数据如下所示:

创建低级别自动发现规则后,将继续创建监控项原型。
基于此监控项原型创建的监控项将从 SNMP OID 字段中指定的 OID 中采集指标,并将为低级别自动发现规则采集的每个索引({#SNMPINDEX} 宏)创建一个监控项。请注意,监控项类型是 SNMP agent - 每个发现和创建的监控项都将是一个常规的 SNMP 监控项,轮询设备并根据监控项 OID 采集指标。
现在,假设有数百个接口,我们正在快速轮询每个接口的各种指标。如果设备硬件较旧或较慢,可能会导致设备根本无法处理那么多请求的问题。要解决此问题,需要一种更好的方法来采集SNMP指标。
02 使用主从监控项进行批量数据采集
继续改进的SNMP指标采集方法之前,需要首先看一下在Zabbix中是如何实现主从监控项批量指标采集和低级别自动发现逻辑的。
●首先,创建一个主监控项,它一次性采集指标和低级别自动发现信息。
●接下来,创建一个依赖监控项类型的低级别自动发现规则,并指向在上一步中创建的主监控项。此时,需要确保主监控项采集的数据格式为 JSON,或者使用预处理将数据转换为 JSON。
●一旦确保数据是 JSON 格式的,就可以使用 LLD 宏选项卡通过 JSONPath 分配LLD宏值。注意:此处,使用批量指标采集的SNMP低级别自动发现使用不同的方式,专为SNMP检查而设计。
●最后,创建依赖监控项原型,并再次将它们指向在第一步中创建的主监控项(请记住 - 主监控项不仅包含低级别自动发现信息,还包含所有必需的指标)。在这里,使用 JSONPath 预处理和LLD宏来指定应采集哪些值。请记住,对于从监控项原型创建的每个监控项,LLD宏将解析为其值。
03通过批量指标采集提升SNMP监控性能
SNMP 批量指标采集和发现逻辑与上一节中讨论的逻辑非常相似,但它更适合 SNMP 细微差别。
在这里,为了避免过度的轮询,引入了一个新的 walk[] 监控项。该监控项利用具有 SNMPv2 和 v3 接口的 GetBulk 请求以及用于 SNMPv1 接口的 GetNext 来采集 SNMP 数据。根据设计,GetBulk 请求的性能要好得多。GetBulk 请求一次性检索 OID 树末尾所有实例的值,而不是为每个实例发出单独的 Get 请求。
为了在Zabbix中利用这一点,首先必须创建一个walk[]主监控项,指定要从中采集值的OID列表。检索到的值将用于低级别自动发现(例如:接口名称)和从低级别自动发现监控项原型创建的监控项(例如:进口和出口流量)。
引入了两个新的预处理步骤,以便于采集SNMP批量数据:
●SNMP 遍历到 JSON (SNMP walk to JSON)用于指定 OID,LLD宏将从中分配其值
●SNMP 遍历值(SNMP walk value)在监控项原型中用于指定将从中采监控项值的 OID
SNMP批量数据收集的工作流可以通过以下步骤进行描述:
●创建一个包含所需 OID 的 master walk[] 项
●创建一个依赖于 walk[] 主项的类型依赖项的低级发现规则
●使用 SNMP 遍历到 JSON 预处理步骤定义低级别发现宏
●创建依赖于 walk[] 主项的类型依赖项的项原型,并使用 SNMP 遍历值预处理步骤指定应使用哪个 OID 进行值收集
04通过批量SNMP数据收集来监控接口流量
让我们看一个简单的示例,您可以将其用作为设备实现批量 SNMP 指标采集的起点。在以下示例中,将创建一个 walk[] 主监控项、用于发现网络接口的依赖的低级别自动发现规则,以及用于进口和出口流量的依赖监控项原型。
1、创建主监控项
我们将从创建 walk[] SNMP agent类型主监控项开始。可以任意指定监控项的名称和键值。这里重要的是 OID 字段,其中指定逗号分隔的 OID 列表,从中采集其实例值。

walk[] 监控项将从以下 OID 收集值:
●1.3.6.1.2.1.31.1.1.1.6 – 进口流量
●1.3.6.1.2.1.31.1.1.1.10 – 出口流量
●1.3.6.1.2.1.31.1.1.1.1 – 接口名称
●1.3.6.1.2.1.2.2.1.2 – 接口说明
●1.3.6.1.2.1.2.2.1.3 – 接口类型
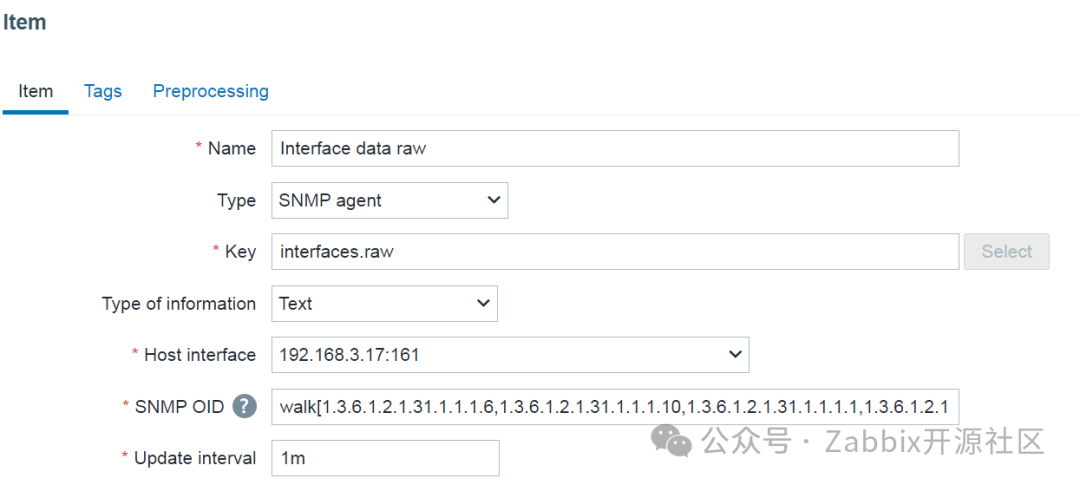
SNMP 批量指标采集 walk[] 主监控项
在这里,可以看到这个监控项采集的结果值:
注意:为了便于阅读,输出已被截断,并且某些接口已被省略。
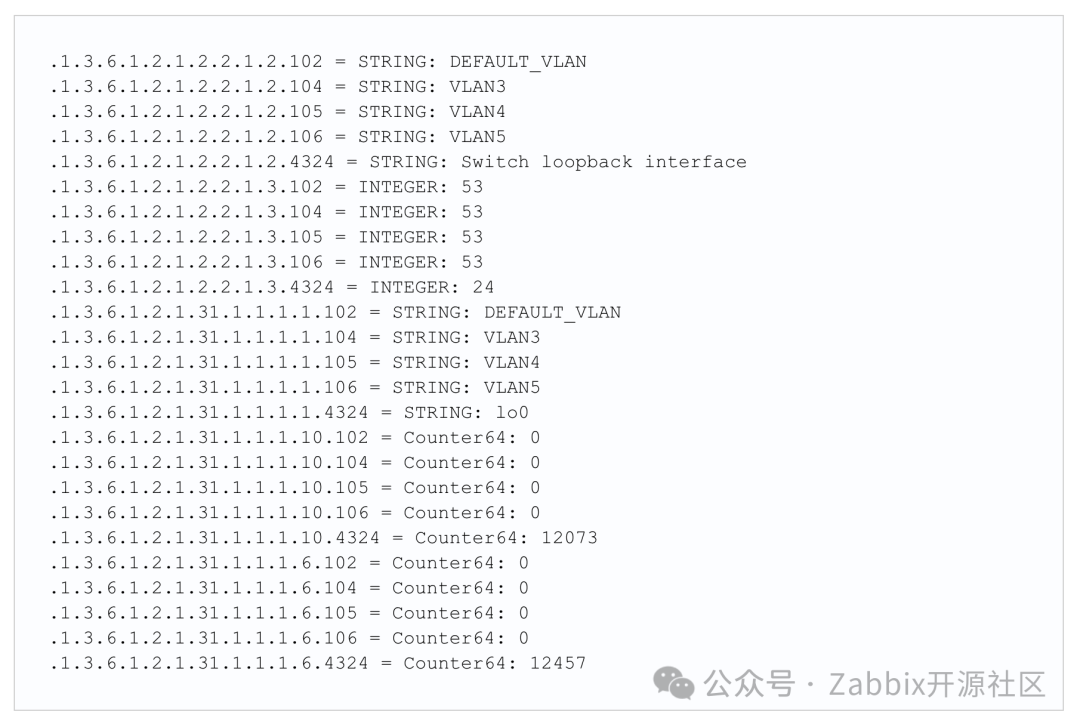
通过查看这些值,可以确认监控项采集了低级别自动发现规则(接口名称、类型和描述)和从监控项原型创建的监控项(进口/出口流量)所需的值。
下一步,创建一个依赖的低级别自动发现规则,该规则将根据 walk[] 主监控项中的数据发现接口。
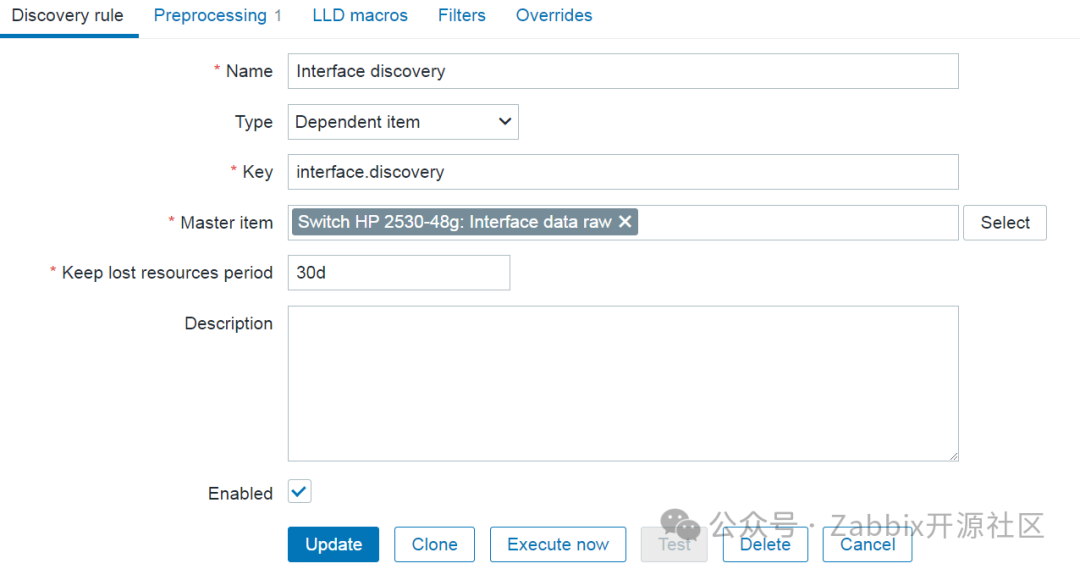
发现接口的依赖的低级别自动发现规则
配置低级别自动发现规则的最重要部分在于定义 SNMP 遍历到 JSON 预处理步骤。在这里,可以将LLD宏分配给 OID。在示例中,将 {#IFNAME} 宏分配给包含接口名称值的 OID:

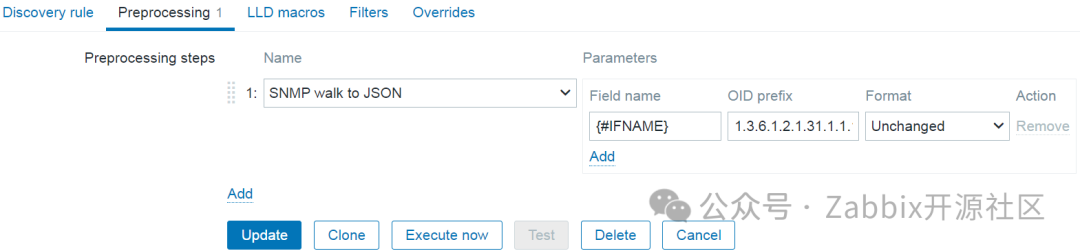
依赖的低级别发现规则预处理步骤
依赖监控项的名称和键可以任意指定。
3、创建监控项原型
最后,创建两个依赖监控项原型,以从主监控项采集流量数据。
在这里,我们将提供一个包含LLD宏的任意名称和键值。对于从监控项原型创建的监控项,宏将解析为 OID 值,从而为每个监控项提供唯一的名称和键值。
注意:{#SNMPINDEX}宏由低级别自动发现规则自动采集,并包含SNMP漫游到JSON预处理步骤中指定的OID中的索引。
创建监控项原型的最后一步是使用 SNMP 遍历值预处理步骤来定义监控项将采集的值。将在 OID 的末尾附加 {#SNMPINDEX}宏。这样,从原型创建的每个监控项都将从与正确对象实例对应的唯一 OID 中采集数据。
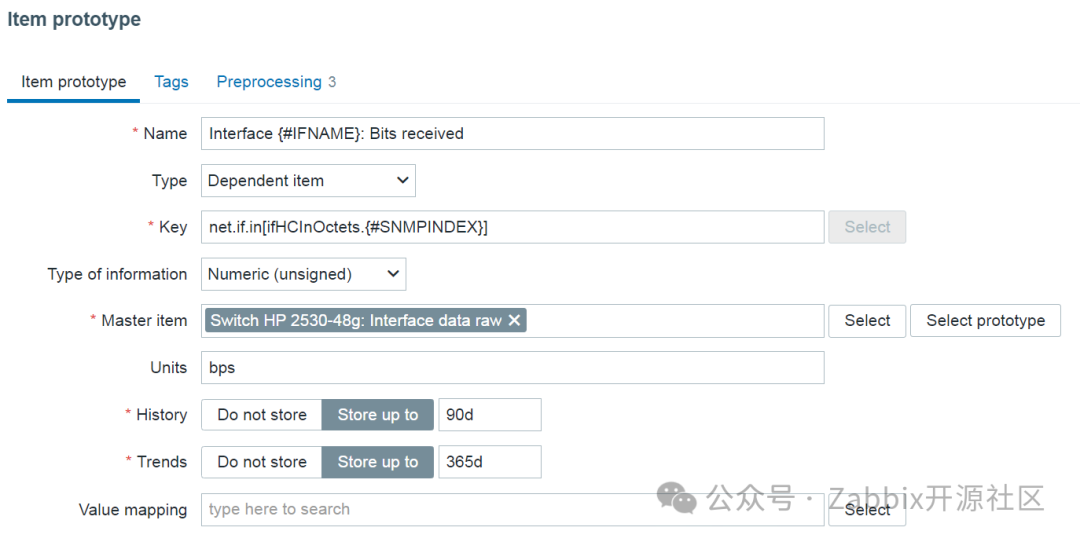
进口流量监控项原型
进口流量监控项原型预处理步骤:

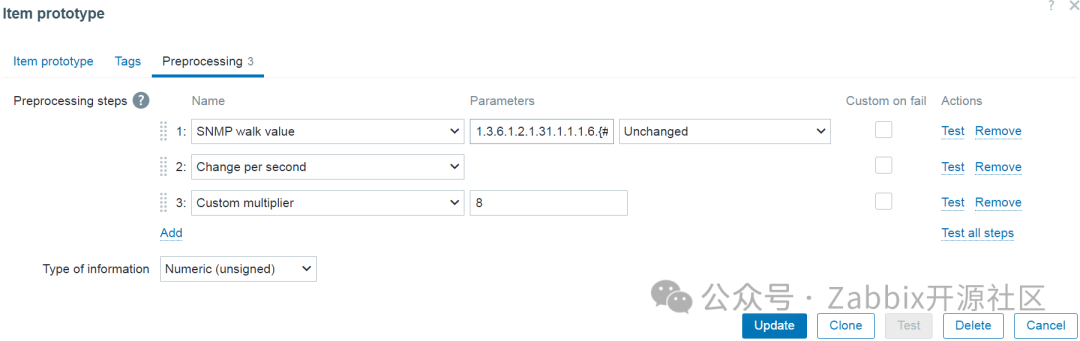
进口流量监控项预处理步骤
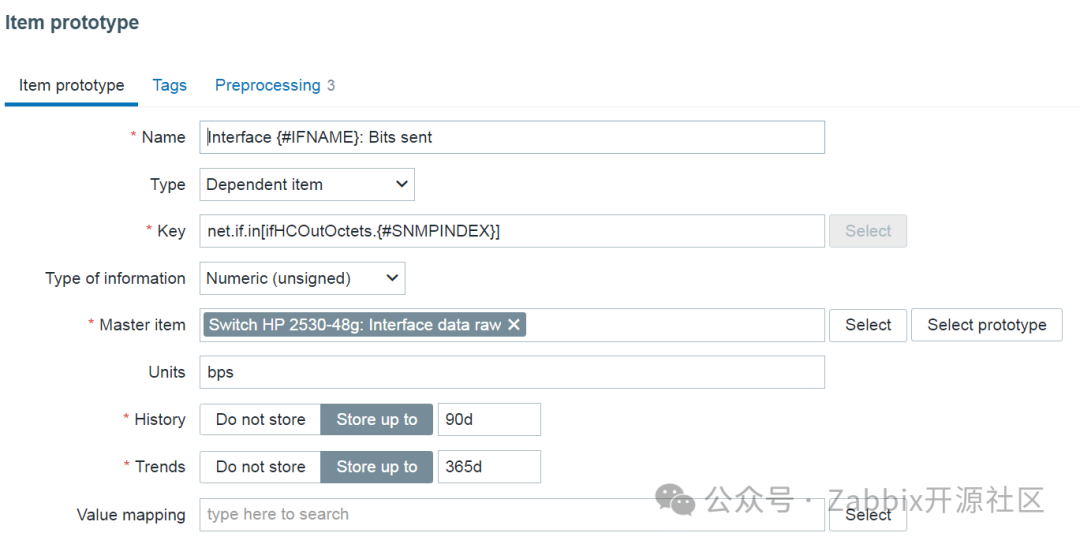
出口流量监控项原型
出口流量监控项原型预处理步骤:

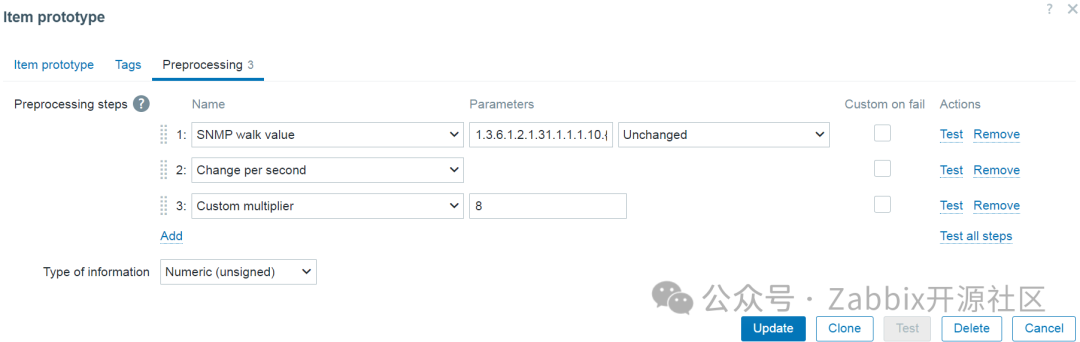
出口流量监控项预处理步骤
注意:由于采集的流量值是计数器值(总是在增加),因此需要“每秒更改”预处理步骤来采集每秒流量值。
注意:由于这些值是以字节为单位采集的,因此使用自定义乘数预处理步骤将字节转换为位。
05最后的注意事项
大功告成!现在我们所要做的就是等到主监控项更新间隔开始,监控项自动发现。
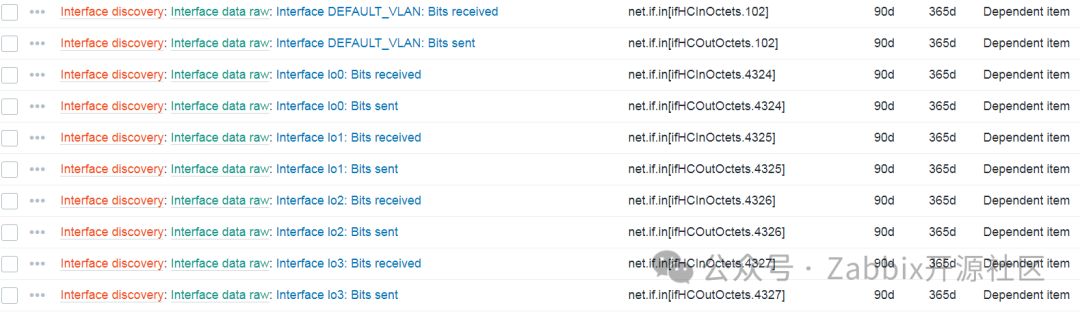
从监控项原型创建的监控项
确认接口正在被发现并且监控项正在从主监控项采集指标之后,还应该在低级别自动发现规则添加 Discard unchanged with heartbeat 预处理步骤。这样一来,低级别自动发现规则就不会一遍又一遍地从主监控项获取同一组接口的情况下尝试发现新实体。这反过来又提升了内部低级别自动发现过程的整体性能。

在低级别自动发现规则
添加 Discard unchanged heartbeat 预处理
请注意,我们发现了除了接口名称之外的其他接口参数 - 接口描述和类型也采集在主监控项中。要使用此数据,须在低级别自动发现规则 SNMP 遍历到 JSON 预处理步骤中添加其他字段,并将LLD宏分配给包含此信息的相应 OID。完成此操作后,我们可以使用监控项原型中的新宏在监控项名称或键值中提供其他信息,或者根据此信息过滤发现的接口(例如:仅发现特定类型的接口)。
这篇关于技术干货|如何快速提升SNMP监控性能的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







