本文主要是介绍【Hadoop大数据技术】——期末复习(冲刺篇),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
📖 前言:快考试了,做篇期末总结,都是重点与必考点。
题型:简答题、编程题(Java与Shell操作)、看图分析题。题目大概率会从课后习题、实验里出。
课本:

目录
- 🕒 1. HDFS分布式文件系统☆☆☆
- 🕘 1.1 存储架构
- 🕘 1.2 文件读写原理
- 🕤 1.2.1 写文件流程
- 🕤 1.2.2 读文件流程
- 🕘 1.3 Shell操作
- 🕘 1.4 综合实验
- 🕒 2. MapReduce分布式计算框架☆☆☆
- 🕘 2.1 核心思想:分而治之
- 🕘 2.2 工作原理
- 🕘 2.3 MapTask
- 🕘 2.4 ReduceTask
- 🕘 2.5 Shuffle
- 🕒 3. ZooKeeper分布式协调服务
- 🕘 3.1 简介
- 🕘 3.2 Watcher机制
- 🕘 3.3 选举机制☆
- 🕤 3.3.1 全新集群选举
- 🕤 3.3.2 非全新集群选举
- 🕒 4. Hadoop高可用集群
- 🕘 4.1 YARN资源管理框架
- 🕤 4.1.1 体系结构
- 🕤 4.1.2 工作流程
- 🕘 4.2 HDFS的高可用架构☆
- 🕒 5. Hive数据仓库
- 🕘 5.1 简介
- 🕘 5.2 系统架构
- 🕘 5.3 数据模型
- 🕒 6. Flume日志采集系统
- 🕘 6.1 简介
- 🕘 6.2 运行机制☆
- 🕘 6.3 系统结构
- 🕘 6.4 可靠性保证
- 🕤 6.4.1 负载均衡
- 🕤 6.4.2 故障转移
- 🕒 7. Azkaban工作流管理器
- 🕒 8. Sqoop数据迁移
🕒 1. HDFS分布式文件系统☆☆☆
Hadoop的核心是HDFS(Hadoop Distributed File System,Hadoop分布式文件系统)和MapReduce。其中,HDFS是解决海量大数据文件存储的问题,是目前应用最广泛的分布式文件系统。
🕘 1.1 存储架构
HDFS是一个易于扩展的分布式文件系统,运行在成百上千台低成本的机器上。它与现有的分布式文件系统有许多相似之处,都是用来存储数据的系统工具,而区别于HDFS具有高度容错能力,旨在部署在低成本机器上。HDFS主要用于对海量文件信息进行存储和管理。
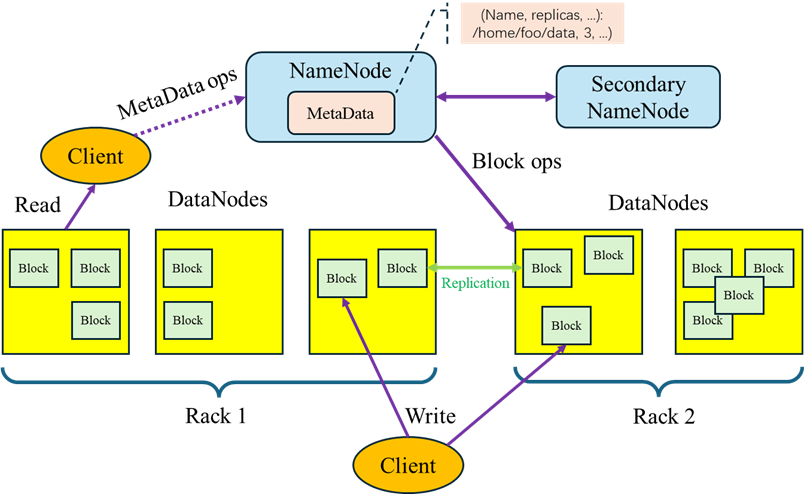
- HDFS采用主从架构(Master/Slave架构)。
- HDFS集群是由一个NameNode和多个 DataNode组成。
- HDFS提供 SecondaryNameNode 辅助 NameNode。
-
NameNode(名称节点)
NameNode是HDFS集群的主服务器,通常称为名称节点或者主节点。一旦NameNode关闭,就无法访问Hadoop集群。NameNode主要以元数据的形式进行管理和存储,用于维护文件系统名称并管理客户端对文件的访问;NameNode记录对文件系统名称空间或其属性的任何更改操作;HDFS负责整个数据集群的管理,并且在配置文件中可以设置备份数量,这些信息都由NameNode存储。 -
DataNode(数据节点)
DataNode是HDFS集群中的从服务器,通常称为数据节点。文件系统存储文件的方式是将文件切分成多个数据块,这些数据块实际上是存储在DataNode节点中的,因此DataNode机器需要配置大量磁盘空间。它与NameNode通过心跳监测机制保持不断的通信,DataNode在客户端或者NameNode的调度下,存储并检索数据块,对数据块进行创建、删除等操作,并且定期向NameNode发送所存储的数据块列表。 -
SecondaryNameNode(辅助节点)
SecondaryNameNode是HDFS集群中的辅助节点。定期从NameNode拷贝FsImage文件并合并Edits文件,将合并结果发送给NameNode。SecondaryNameNode和NameNode保存的FsImage和Edits文件相同,可以作为NameNode的冷备份,它的目的是帮助 NameNode合并编辑日志,减少NameNode启动时间。当NameNode宕机无法使用时,可以通过手动操作将SecondaryNameNode切换为NameNode。 -
Block(数据块)
每个磁盘都有默认的数据块大小,这是磁盘进行数据读/写的最小单位,HDFS同样也有块的概念,它是抽象的块,而非整个文件作为存储单元,在Hadoop3.x版本下,默认大小是128M,且备份3份,每个块尽可能地存储于不同的DataNode中。按块存储的好处主要是屏蔽了文件的大小,提供数据的容错性和可用性。 -
Rack(机架)
Rack是用来存放部署Hadoop集群服务器的机架,不同机架之间的节点通过交换机通信,HDFS通过机架感知策略,使NameNode能够确定每个DataNode所属的机架ID,使用副本存放策略,来改进数据的可靠性、可用性和网络带宽的利用率。 -
Metadata(元数据)
在 NameNode 内部是以元数据的形式,维护着两个文件,分别是FsImage镜像文件和EditLog日志文件。其中,FsImage镜像文件用于存储整个文件系统命名空间的信息,EditLog日志文件用于持久化记录文件系统元数据发生的变化。
当 NameNode启动的时候,FsImage 镜像文件就会被加载到内存中,然后对内存里的数据执行记录的操作,以确保内存所保留的数据处于最新的状态,这样就加快了元数据的读取和更新操作。
Q:简述NameNode管理分布式文件系统的命名空间。
A:回答如上Metadata部分。
🕘 1.2 文件读写原理
🕤 1.2.1 写文件流程
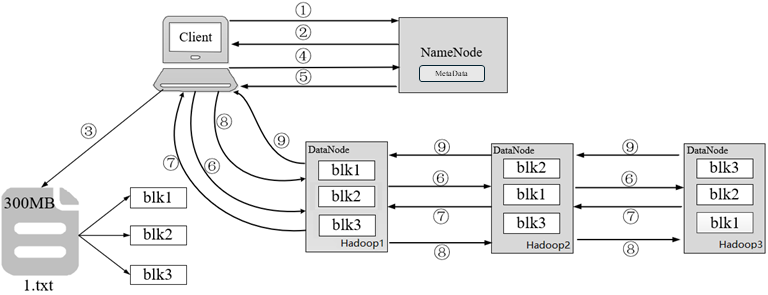
以300MB大小的1.txt文件为例,介绍HDFS写文件流程
-
客户端发起上传1.txt文件到指定目录的请求,通过RPC(远程过程调用)与NameNode建立通讯。
-
NameNode检查元数据文件的系统目录树,即检查客户端是否有上传文件的权限,以及文件是否存在等。若系统目录树的父目录不存在该文件相关信息,返回客户端可以上传文件。
-
客户端根据分块策略对文件1.txt进行切分,形成3个Block,分别是blk1、blk2和blk3。
-
客户端向NameNode请求上传第一个Block,即blk1,以及数据块副本的数量。
-
NameNode根据副本机制和机架感知向客户端返回可上传blk1的DataNode列表。
-
客户端从NameNode接收到blk1上传的DataNode列表,并与虚拟机建立管道(Pipeline)。
-
Hadoop3向Hadoop2汇报管道建立成功,Hadoop2与Hadoop1汇报管道建立成功;Hadoop1与客户端汇报管道建立成功,客户端与所有DataNode列表中的所有DataNode都建立了管道。
-
客户端开始传输blk1,传输过程是以流式写入的方式实现。
1)将blk1写入到内存中进行缓存。
2)将blk1按照packet(默认为64K)为单位进行划分。
3)将第一个packet通过管道发送给Hadoop1。
4)Hadoop1接收完第一个packet之后,客户端会将第二个packet发送给Hadoop1,同时Hadoop1通过Pipeline将第一个packet发送给Hadoop2。
5)Hadoop2接收完第一个packet之后,Hadoop1会将第二个packet发送给Hadoop2,同时Hadoop2通过Pipeline将第一个packet发送给Hadoop3。
6)依次类推直至blk1上传完成。 -
Hadoop3向Hadoop2发送blk1写入完成的信息,Hadoop2向Hadoop1发送blk1写入完成的信息,最后,Hadoop1向客户端发送blk1写入完成的信息。
注意:客户端成功上传blk1后,重复第4~9步的流程,依次上传blk2和blk3,最终完成1.txt文件的上传。
🕤 1.2.2 读文件流程
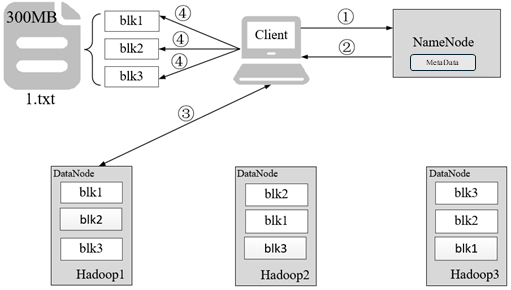
以300MB大小的1.txt文件为例,介绍HDFS读文件流程
-
客户端发起读取1.txt文件的请求,通过RPC与NameNode建立通讯。
-
NameNode检查元数据文件的系统目录树,即检查客户端是否有读取文件的权限,以及文件是否存在等。
-
客户端按照就近原则从NameNode返回的Block列表读取Block。
-
客户端将读取所有的Block按照顺序进行合并,最终形成1.txt文件,需要注意的是,如果文件过大导致NameNode无法一次性文件的所有Block列表返回客户端时,会分批次将Block列表返回客户端。
🕘 1.3 Shell操作
Hadoop提供了多种Client Commands类型的HDFS Shell子命令,包括dfs、envvars、classpath等,dfs主要用于操作HDFS的文件和目录,也是最常用的HDFS Shell子命令。
-ls:查看指定路径的目录结构-du:统计目录下所有文件大小-mv:移动文件-cp:复制文件-rm:删除文件/空白文件夹-cat:查看文件内容-text:源文件输出为文本格式-mkdir:创建空白文件夹-put:上传文件-help:删除文件/空白文件夹

🕘 1.4 综合实验
编程实现以下功能,并利用 Hadoop 提供的 Shell 命令完成相同任务:
(1) 向 HDFS 中上传任意文本文件,如果指定的文件在 HDFS 中已经存在,则由用户来指定是追加到原有文件末尾还是覆盖原有的文件;
cd /usr/local/hadoop
./bin/hdfs dfs -appendToFile local.txt text.txt #追加到原文件末尾
./bin/hdfs dfs -copyFromLocal -f local.txt text.txt #覆盖原来文件,第一种命令形式
/bin/hdfs dfs -cp -f file:///home/hadoop/local.txt text.txt #覆盖原来文件,第二种命令形式
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;public class HDFSApi {/*** 判断路径是否存在*/public static boolean test(Configuration conf, String path) throws IOException {FileSystem fs = FileSystem.get(conf);return fs.exists(new Path(path));}/*** 复制文件到指定路径* 若路径已存在,则进行覆盖*/public static void copyFromLocalFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path localPath = new Path(localFilePath);Path remotePath = new Path(remoteFilePath);/* fs.copyFromLocalFile 第一个参数表示是否删除源文件,第二个参数表示是否覆盖 */fs.copyFromLocalFile(false, true, localPath, remotePath);fs.close();}/*** 追加文件内容*/public static void appendToFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path remotePath = new Path(remoteFilePath);/* 创建一个文件读入流 */FileInputStream in = new FileInputStream(localFilePath);/* 创建一个文件输出流,输出的内容将追加到文件末尾 */FSDataOutputStream out = fs.append(remotePath);/* 读写文件内容 */byte[] data = new byte[1024];int read = -1;while ( (read = in.read(data)) > 0 ) {out.write(data, 0, read);}out.close();in.close();fs.close();}/*** 主函数*/public static void main(String[] args) {Configuration conf = new Configuration();conf.set("fs.default.name","hdfs://localhost:9000");String localFilePath = "/usr/local/hadoop/text.txt"; // 本地路径String remoteFilePath = "/user/hadoop/text.txt"; // HDFS路径String choice = "append"; // 若文件存在则追加到文件末尾
// String choice = "overwrite"; // 若文件存在则覆盖try {/* 判断文件是否存在 */Boolean fileExists = false;if (HDFSApi.test(conf, remoteFilePath)) {fileExists = true;System.out.println(remoteFilePath + " 已存在.");} else {System.out.println(remoteFilePath + " 不存在.");}/* 进行处理 */if ( !fileExists) { // 文件不存在,则上传HDFSApi.copyFromLocalFile(conf, localFilePath, remoteFilePath);System.out.println(localFilePath + " 已上传至 " + remoteFilePath);} else if ( choice.equals("overwrite") ) { // 选择覆盖HDFSApi.copyFromLocalFile(conf, localFilePath, remoteFilePath);System.out.println(localFilePath + " 已覆盖 " + remoteFilePath);} else if ( choice.equals("append") ) { // 选择追加HDFSApi.appendToFile(conf, localFilePath, remoteFilePath);System.out.println(localFilePath + " 已追加至 " + remoteFilePath);}} catch (Exception e) {e.printStackTrace();}}
}
(2) 从 HDFS 中下载指定文件,如果本地文件与要下载的文件名称相同,则自动对下载的文件重命名;
if $(./bin/hdfs dfs -test -e file:///home/hadoop/text.txt);
then $(./bin/hdfs dfs -copyToLocal text.txt ./text2.txt);
else $(./bin/hdfs dfs -copyToLocal text.txt ./text.txt);
fi
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;public class HDFSApi {/*** 下载文件到本地* 判断本地路径是否已存在,若已存在,则自动进行重命名*/public static void copyToLocal(Configuration conf, String remoteFilePath, String localFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path remotePath = new Path(remoteFilePath);File f = new File(localFilePath);/* 如果文件名存在,自动重命名(在文件名后面加上 _0, _1 ...) */if (f.exists()) {System.out.println(localFilePath + " 已存在.");Integer i = 0;while (true) {f = new File(localFilePath + "_" + i.toString());if (!f.exists()) {localFilePath = localFilePath + "_" + i.toString();break;}}System.out.println("将重新命名为: " + localFilePath);}// 下载文件到本地Path localPath = new Path(localFilePath);fs.copyToLocalFile(remotePath, localPath);fs.close();}/*** 主函数*/public static void main(String[] args) {Configuration conf = new Configuration();conf.set("fs.default.name","hdfs://localhost:9000");String localFilePath = "/usr/local/hadoop/text.txt"; // 本地路径String remoteFilePath = "/user/hadoop/text.txt"; // HDFS路径try {HDFSApi.copyToLocal(conf, remoteFilePath, localFilePath);System.out.println("下载完成");} catch (Exception e) {e.printStackTrace();}}
}
(3) 将 HDFS 中指定文件的内容输出到终端中;
./bin/hdfs dfs -cat text.txt
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;public class HDFSApi {/*** 读取文件内容*/public static void cat(Configuration conf, String remoteFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path remotePath = new Path(remoteFilePath);FSDataInputStream in = fs.open(remotePath);BufferedReader d = new BufferedReader(new InputStreamReader(in));String line = null;while ( (line = d.readLine()) != null ) {System.out.println(line);}d.close();in.close();fs.close();}/*** 主函数*/public static void main(String[] args) {Configuration conf = new Configuration();conf.set("fs.default.name","hdfs://localhost:9000");String remoteFilePath = "/user/hadoop/text.txt"; // HDFS路径try {System.out.println("读取文件: " + remoteFilePath);HDFSApi.cat(conf, remoteFilePath);System.out.println("\n读取完成");} catch (Exception e) {e.printStackTrace();}}
}
(4)显示 HDFS 中指定的文件的读写权限、大小、创建时间、路径等信息;
./bin/hdfs dfs -ls -h text.txt
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
import java.text.SimpleDateFormat;public class HDFSApi {/*** 显示指定文件的信息*/public static void ls(Configuration conf, String remoteFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path remotePath = new Path(remoteFilePath);FileStatus[] fileStatuses = fs.listStatus(remotePath);for (FileStatus s : fileStatuses) {System.out.println("路径: " + s.getPath().toString());System.out.println("权限: " + s.getPermission().toString());System.out.println("大小: " + s.getLen());/* 返回的是时间戳,转化为时间日期格式 */Long timeStamp = s.getModificationTime();SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String date = format.format(timeStamp); System.out.println("时间: " + date);}fs.close();}/*** 主函数*/public static void main(String[] args) {Configuration conf = new Configuration();conf.set("fs.default.name","hdfs://localhost:9000");String remoteFilePath = "/user/hadoop/text.txt"; // HDFS路径try {System.out.println("读取文件信息: " + remoteFilePath);HDFSApi.ls(conf, remoteFilePath);System.out.println("\n读取完成");} catch (Exception e) {e.printStackTrace();}}
}
(5)给定 HDFS 中某一个目录,输出该目录下的所有文件的读写权限、大小、创建时间、路径等信息,如果该文件是目录,则递归输出该目录下所有文件相关信息;
./bin/hdfs dfs -ls -R -h /user/Hadoop
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;
import java.text.SimpleDateFormat;public class HDFSApi {/*** 显示指定文件夹下所有文件的信息(递归)*/public static void lsDir(Configuration conf, String remoteDir) throws IOException {FileSystem fs = FileSystem.get(conf);Path dirPath = new Path(remoteDir);/* 递归获取目录下的所有文件 */RemoteIterator<LocatedFileStatus> remoteIterator = fs.listFiles(dirPath, true);/* 输出每个文件的信息 */while (remoteIterator.hasNext()) {FileStatus s = remoteIterator.next();System.out.println("路径: " + s.getPath().toString());System.out.println("权限: " + s.getPermission().toString());System.out.println("大小: " + s.getLen());/* 返回的是时间戳,转化为时间日期格式 */Long timeStamp = s.getModificationTime();SimpleDateFormat format = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");String date = format.format(timeStamp); System.out.println("时间: " + date);System.out.println();}fs.close();} /*** 主函数*/public static void main(String[] args) {Configuration conf = new Configuration();conf.set("fs.default.name","hdfs://localhost:9000");String remoteDir = "/user/hadoop"; // HDFS路径try {System.out.println("(递归)读取目录下所有文件的信息: " + remoteDir);HDFSApi.lsDir(conf, remoteDir);System.out.println("读取完成");} catch (Exception e) {e.printStackTrace();}}
}
(6)提供一个 HDFS 内的文件的路径,对该文件进行创建和删除操作。如果文件所在目录不存在,则自动创建目录;
if $(./bin/hdfs dfs -test -d dir1/dir2);
then $(./bin/hdfs dfs -touchz dir1/dir2/filename);
else $(./bin/hdfs dfs -mkdir -p dir1/dir2 && ./bin/hdfs dfs -touchz dir1/dir2/filename);
fi
./bin/hdfs dfs -rm dir1/dir2/filename #删除文件
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;public class HDFSApi {/*** 判断路径是否存在*/public static boolean test(Configuration conf, String path) throws IOException {FileSystem fs = FileSystem.get(conf);return fs.exists(new Path(path));}/*** 创建目录*/public static boolean mkdir(Configuration conf, String remoteDir) throws IOException {FileSystem fs = FileSystem.get(conf);Path dirPath = new Path(remoteDir);boolean result = fs.mkdirs(dirPath);fs.close();return result;}/*** 创建文件*/public static void touchz(Configuration conf, String remoteFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path remotePath = new Path(remoteFilePath);FSDataOutputStream outputStream = fs.create(remotePath);outputStream.close();fs.close();}/*** 删除文件*/public static boolean rm(Configuration conf, String remoteFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path remotePath = new Path(remoteFilePath);boolean result = fs.delete(remotePath, false);fs.close();return result;}/*** 主函数*/public static void main(String[] args) {Configuration conf = new Configuration();conf.set("fs.default.name","hdfs://localhost:9000");String remoteFilePath = "/user/hadoop/input/text.txt"; // HDFS路径String remoteDir = "/user/hadoop/input"; // HDFS路径对应的目录try {/* 判断路径是否存在,存在则删除,否则进行创建 */if ( HDFSApi.test(conf, remoteFilePath) ) {HDFSApi.rm(conf, remoteFilePath); // 删除System.out.println("删除路径: " + remoteFilePath);} else {if ( !HDFSApi.test(conf, remoteDir) ) { // 若目录不存在,则进行创建HDFSApi.mkdir(conf, remoteDir);System.out.println("创建文件夹: " + remoteDir);}HDFSApi.touchz(conf, remoteFilePath);System.out.println("创建路径: " + remoteFilePath);}} catch (Exception e) {e.printStackTrace();}}
}
(7)提供一个 HDFS 的目录的路径,对该目录进行创建和删除操作。创建目录时,如果目录文件所在目录不存在,则自动创建相应目录;删除目录时,由用户指定当该目录不为空时是否还删除该目录;
./bin/hdfs dfs -mkdir -p dir1/dir2
./bin/hdfs dfs -rmdir dir1/dir2
./bin/hdfs dfs -rm -R dir1/dir2
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;public class HDFSApi {/*** 判断路径是否存在*/public static boolean test(Configuration conf, String path) throws IOException {FileSystem fs = FileSystem.get(conf);return fs.exists(new Path(path));}/*** 判断目录是否为空* true: 空,false: 非空*/public static boolean isDirEmpty(Configuration conf, String remoteDir) throws IOException {FileSystem fs = FileSystem.get(conf);Path dirPath = new Path(remoteDir);RemoteIterator<LocatedFileStatus> remoteIterator = fs.listFiles(dirPath, true);return !remoteIterator.hasNext();}/*** 创建目录*/public static boolean mkdir(Configuration conf, String remoteDir) throws IOException {FileSystem fs = FileSystem.get(conf);Path dirPath = new Path(remoteDir);boolean result = fs.mkdirs(dirPath);fs.close();return result;}/*** 删除目录*/public static boolean rmDir(Configuration conf, String remoteDir) throws IOException {FileSystem fs = FileSystem.get(conf);Path dirPath = new Path(remoteDir);/* 第二个参数表示是否递归删除所有文件 */boolean result = fs.delete(dirPath, true);fs.close();return result;}/*** 主函数*/public static void main(String[] args) {Configuration conf = new Configuration();conf.set("fs.default.name","hdfs://localhost:9000");String remoteDir = "/user/hadoop/input"; // HDFS目录Boolean forceDelete = false; // 是否强制删除try {/* 判断目录是否存在,不存在则创建,存在则删除 */if ( !HDFSApi.test(conf, remoteDir) ) {HDFSApi.mkdir(conf, remoteDir); // 创建目录System.out.println("创建目录: " + remoteDir);} else {if ( HDFSApi.isDirEmpty(conf, remoteDir) || forceDelete ) { // 目录为空或强制删除HDFSApi.rmDir(conf, remoteDir);System.out.println("删除目录: " + remoteDir);} else { // 目录不为空System.out.println("目录不为空,不删除: " + remoteDir);}}} catch (Exception e) {e.printStackTrace();}}
}
(8)向 HDFS 中指定的文件追加内容,由用户指定内容追加到原有文件的开头或结尾;
./bin/hdfs dfs -appendToFile local.txt text.txt
./bin/hdfs dfs -get text.txt
cat text.txt >> local.txt
./bin/hdfs dfs -copyFromLocal -f text.txt text.txt
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;public class HDFSApi {/*** 判断路径是否存在*/public static boolean test(Configuration conf, String path) throws IOException {FileSystem fs = FileSystem.get(conf);return fs.exists(new Path(path));}/*** 追加文本内容*/public static void appendContentToFile(Configuration conf, String content, String remoteFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path remotePath = new Path(remoteFilePath);/* 创建一个文件输出流,输出的内容将追加到文件末尾 */FSDataOutputStream out = fs.append(remotePath);out.write(content.getBytes());out.close();fs.close();
}/*** 追加文件内容*/public static void appendToFile(Configuration conf, String localFilePath, String remoteFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path remotePath = new Path(remoteFilePath);/* 创建一个文件读入流 */FileInputStream in = new FileInputStream(localFilePath);/* 创建一个文件输出流,输出的内容将追加到文件末尾 */FSDataOutputStream out = fs.append(remotePath);/* 读写文件内容 */byte[] data = new byte[1024];int read = -1;while ( (read = in.read(data)) > 0 ) {out.write(data, 0, read);}out.close();in.close();fs.close();}/*** 移动文件到本地* 移动后,删除源文件*/public static void moveToLocalFile(Configuration conf, String remoteFilePath, String localFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path remotePath = new Path(remoteFilePath);Path localPath = new Path(localFilePath);fs.moveToLocalFile(remotePath, localPath);}/*** 创建文件*/public static void touchz(Configuration conf, String remoteFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path remotePath = new Path(remoteFilePath);FSDataOutputStream outputStream = fs.create(remotePath);outputStream.close();fs.close();}/*** 主函数*/public static void main(String[] args) {Configuration conf = new Configuration();conf.set("fs.default.name","hdfs://localhost:9000");String remoteFilePath = "/user/hadoop/text.txt"; // HDFS文件String content = "新追加的内容\n";String choice = "after"; //追加到文件末尾
// String choice = "before"; // 追加到文件开头try {/* 判断文件是否存在 */if ( !HDFSApi.test(conf, remoteFilePath) ) {System.out.println("文件不存在: " + remoteFilePath);} else {if ( choice.equals("after") ) { // 追加在文件末尾HDFSApi.appendContentToFile(conf, content, remoteFilePath);System.out.println("已追加内容到文件末尾" + remoteFilePath);} else if ( choice.equals("before") ) { // 追加到文件开头/* 没有相应的api可以直接操作,因此先把文件移动到本地*/
/*创建一个新的HDFS,再按顺序追加内容 */String localTmpPath = "/user/hadoop/tmp.txt";// 移动到本地
HDFSApi.moveToLocalFile(conf, remoteFilePath, localTmpPath);// 创建一个新文件HDFSApi.touchz(conf, remoteFilePath); // 先写入新内容HDFSApi.appendContentToFile(conf, content, remoteFilePath);// 再写入原来内容HDFSApi.appendToFile(conf, localTmpPath, remoteFilePath); System.out.println("已追加内容到文件开头: " + remoteFilePath);}}} catch (Exception e) {e.printStackTrace();}}
}
(9)删除 HDFS 中指定的文件;
./bin/hdfs dfs -rm text.txt
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;public class HDFSApi {/*** 删除文件*/public static boolean rm(Configuration conf, String remoteFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path remotePath = new Path(remoteFilePath);boolean result = fs.delete(remotePath, false);fs.close();return result;}/*** 主函数*/public static void main(String[] args) {Configuration conf = new Configuration();conf.set("fs.default.name","hdfs://localhost:9000");String remoteFilePath = "/user/hadoop/text.txt"; // HDFS文件try {if ( HDFSApi.rm(conf, remoteFilePath) ) {System.out.println("文件删除: " + remoteFilePath);} else {System.out.println("操作失败(文件不存在或删除失败)");}} catch (Exception e) {e.printStackTrace();}}
}
(10)在 HDFS 中,将文件从源路径移动到目的路径。
./bin/hdfs dfs -mv text.txt text2.txt
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import java.io.*;public class HDFSApi {/*** 移动文件*/public static boolean mv(Configuration conf, String remoteFilePath, String remoteToFilePath) throws IOException {FileSystem fs = FileSystem.get(conf);Path srcPath = new Path(remoteFilePath);Path dstPath = new Path(remoteToFilePath);boolean result = fs.rename(srcPath, dstPath);fs.close();return result;}/*** 主函数*/public static void main(String[] args) {Configuration conf = new Configuration();conf.set("fs.default.name","hdfs://localhost:9000");String remoteFilePath = "hdfs:///user/hadoop/text.txt"; // 源文件HDFS路径String remoteToFilePath = "hdfs:///user/hadoop/new.txt"; // 目的HDFS路径try {if ( HDFSApi.mv(conf, remoteFilePath, remoteToFilePath) ) {System.out.println("将文件 " + remoteFilePath + " 移动到 " + remoteToFilePath);} else {System.out.println("操作失败(源文件不存在或移动失败)");}} catch (Exception e) {e.printStackTrace();}}
}
🕒 2. MapReduce分布式计算框架☆☆☆
🕘 2.1 核心思想:分而治之
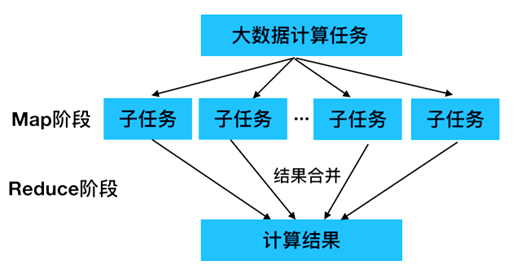
使用MapReduce操作海量数据时,每个MapReduce程序被初始化为一个工作任务,每个工作任务可以分为Map和Reduce两个阶段。
- Map阶段:负责将工作任务分解为若干个子任务来并行处理,这些子任务相互独立,可以单独被执行。
- Reduce阶段:负责将Map过程处理完的子任务结果合并,从而得到工作任务的最终结果。
🕘 2.2 工作原理
流程:分片、格式化数据源 → 执行MapTask → 执行Shuffle过程 → 执行ReduceTask → 写入文件
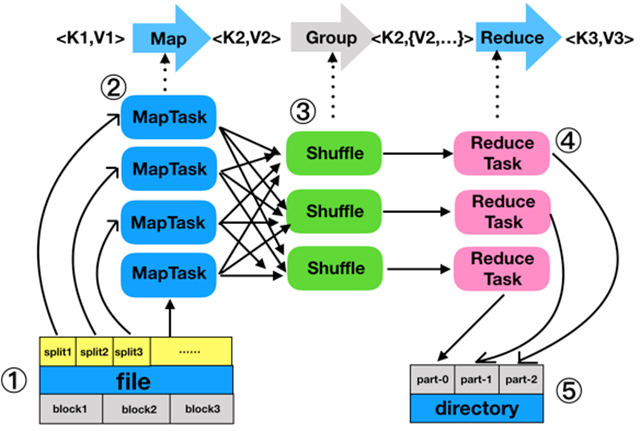
🕘 2.3 MapTask
MapTask作为MapReduce工作流程前半部分,它主要经历5个阶段,分别是Read阶段、Map阶段、Collect阶段、Spill阶段和Combiner阶段。
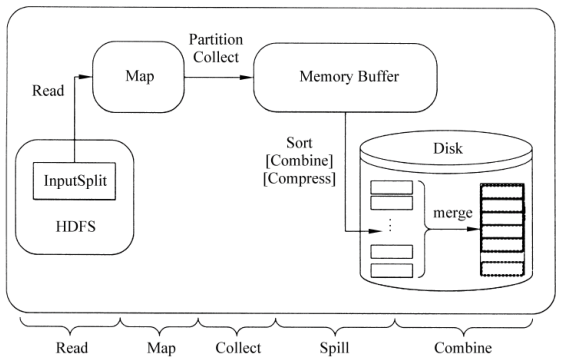
- Read阶段:通过MapReduce内置的InputSplit组件将读取的文件进行分片处理,将数据块中的数据映射为键值对形式。
- Map阶段:将Read阶段映射的键值对进行转换,并生成新的键值对。
- Collect阶段:将Map阶段输出的键值对写入内存缓冲区。
- Spill阶段:判断内存缓冲区中的数据是否达到指定阈值。
- Combine阶段:将写入本地磁盘的所有临时文件合并成一个新的文件,对新文件进行归并排序。
🕘 2.4 ReduceTask
ReduceTask的工作过程主要经历了5个阶段,分别是Copy阶段、Merge阶段、Sort阶段、Reduce阶段和Write阶段。
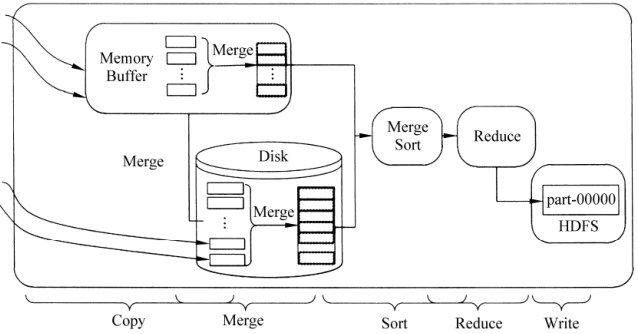
- Copy阶段:从不同的MapTask复制需要处理的数据,将数据写入内存缓冲区。
- Merge阶段:对内存和磁盘上的文件进行合并,防止内存使用过多或者磁盘文件过多。
- Sort阶段:由于各个 MapTask已经实现对自己的处理结果进行了局部排序,因此,ReduceTask只需对所有数据进行一次归并排序即可。
- Reduce阶段:根据实际应用场景自定义reduce()方法,对Sort阶段输出的键值对进行处理。
- Write阶段:将Reduce阶段生成的新键值对写入HDFS中。
🕘 2.5 Shuffle
Shuffle是MapReduce的核心,它用来确保每个ReduceTask的输入数据都是按键排序的。它的性能高低直接决定了整个MapReduce程序的性能高低,map和reduce阶段都涉及到了shuffle机制。
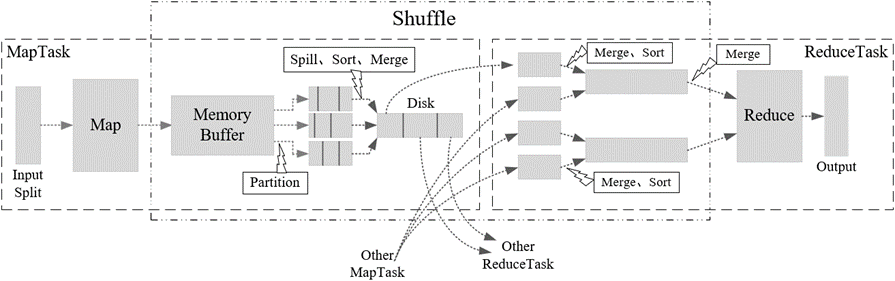
Partition可以让Map对Key进行分区,从而可以根据不同的key分发到不同的Reduce中去处理,其目的就是将 key 均匀分布在 ReduceTask 上。
Q:简述Shuffle工作流程。
A:Map 阶段:Map 任务读取输入 split,并为每个输入记录生成一个键值对。这些键值对被写入内存缓冲区。
Spill 到磁盘:当内存缓冲区满时,键值对被排序并写入磁盘文件,这个过程称为 spill。在写入磁盘之前,可以应用 combiner 函数(如果有的话)进行局部聚合,以减少磁盘 I/O 和网络传输。
Reduce 阶段:Reduce 任务开始时,会从每个 Map 任务的输出文件中拉取对应的分区数据,这个过程称为 shuffle。拉取的数据被合并排序,然后传递给 Reduce 函数进行处理。处理结果被写入输出文件。
🔎 MapReduce经典案例实战(倒排索引、数据去重、TopN)
🕒 3. ZooKeeper分布式协调服务
🕘 3.1 简介
Zookeeper主要用来解决分布式集群中应用系统的一致性问题和单点故障问题,例如如何避免同时操作同一数据造成脏读的一致性问题等。
Zookeeper具有全局数据一致性、可靠性、顺序性、原子性以及实时性,可以说Zookeeper的其他特性都是为满足Zookeeper全局数据一致性这一特性。
Zookeeper集群是一个主从集群,它一般是由一个Leader(领导者)和多个Follower(跟随者)组成。此外,针对访问量比较大的Zookeeper集群,还可新增Observer(观察者)。Zookeeper集群中的三种角色各司其职,共同完成分布式协调服务。
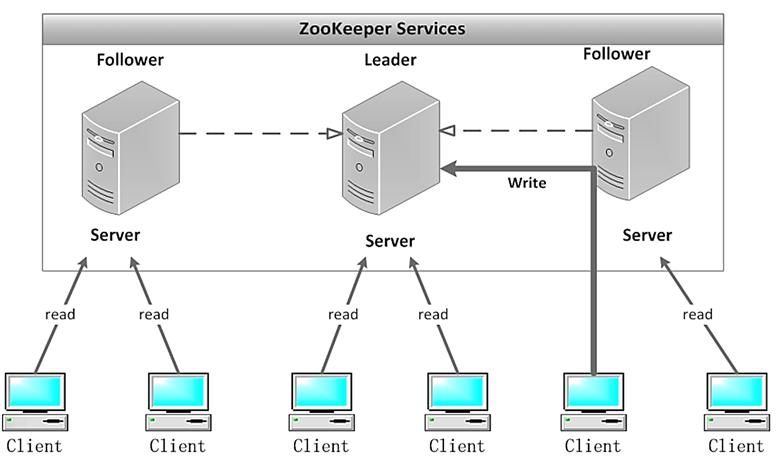
- Leader是Zookeeper集群工作的核心,也是事务性请求(写操作)的唯一调度和处理者,保证集群事务处理的顺序性,同时负责进行投票的发起和决议,以及更新系统状态。
- Follower负责处理客户端的非事务(读操作)请求,如果接收到客户端发来的事务性请求,则会转发给Leader,让Leader进行处理,同时还负责在Leader选举过程中参与投票。
- Observer负责观察Zookeeper集群的最新状态的变化,并且将这些状态进行同步。对于非事务性请求可进行独立处理;对于事务性请求,则会转发给Leader服务器进行处理。它不参与任何形式的投票,只提供非事务性的服务。
🕘 3.2 Watcher机制
在ZooKeeper中,引入了Watch机制来实现这种分布式的通知功能。ZooKeeper允许客户端向服务端注册一个Watch监听,当服务端的一些事件触发了这个Watch,那么就会向指定客户端发送一个事件通知,来实现分布式的通知功能。
Watch机制的特点:一次性触发、事件封装、异步发送、先注册再触发
🕘 3.3 选举机制☆
Zookeeper为了保证各节点的协同工作,在工作时需要一个Leader角色,而Zookeeper默认采用FastLeaderElection算法,且投票数大于半数则胜出的机制。
- 选举ID:选举过程中,Zookeeper服务器有四种状态,分别为竞选状态、随从状态、观察状态、领导者状态。
- 数据ID:是服务器中存放的最新数据版本号,该值越大则说明数据越新,在选举过程中数据越新权重越大。
- 服务器ID:设置集群myid参数时,参数分别为服务器1、服务器2、服务器3,编号越大FastLeaderElection算法中权重越大。
- 逻辑时钟;逻辑时钟被称为投票次数,同一轮投票过程中逻辑时钟值相同,逻辑时钟起始值为0,每投一次票,数据增加。与接收到其它服务器返回的投票信息中数值比较,根据不同值做出不同判断。
Zookeeper选举机制有两种类型,分别为全新集群选举和非全新集群选举。全新集群选举是新搭建起来的,没有数据ID和逻辑时钟的数据影响集群的选举;非全新集群选举时是优中选优,保证Leader是Zookeeper集群中数据最完整、最可靠的一台服务器。
🕤 3.3.1 全新集群选举
假设有5台编号分别是1~5的服务器,全新集群选举过程如下:
- 服务器1启动,先给自己投票;其次,发投票信息,由于其它机器还没有启动所以它无法接收到投票的反馈信息,因此服务器1的状态一直属于竞选状态。
- 服务器2启动,先给自己投票;其次,在集群中启动Zookeeper服务的机器发起投票对比,它会与服务器1交换结果,由于服务器2编号大,服务器2胜出,服务器1会将票投给服务器2,此时服务器2的投票数并没有大于集群半数,两个服务器状态依旧是竞选状态。
- 服务器3启动,先给自己投票;其次,与之前启动的服务器1、2交换信息,服务器3的编号最大,服务器3胜出,服务器1、2会将票投给服务器3,此时投票数正好大于半数,所以服务器3成为领导者状态,服务器1、2成为追随者状态。
- 服务器4启动,先给自己投票;其次,与之前启动的服务器1、2、3交换信息,尽管服务器4的编号大,但是服务器3已经胜,所以服务器4只能成为追随者状态。
- 服务器5启动,同服务器4一样,均成为追随者状态。
🕤 3.3.2 非全新集群选举
- 统计逻辑时钟是否相同,逻辑时钟小,则说明途中可能存在宕机问题,因此数据不完整,那么该选举结果被忽略,重新投票选举。
- 统一逻辑时钟后,对比数据ID值,数据ID反应数据的新旧程度,因此数据ID大的胜出。
- 如果逻辑时钟和数据ID都相同的情况下,那么比较服务器ID(编号),值大则胜出。
🕒 4. Hadoop高可用集群
🕘 4.1 YARN资源管理框架
🕤 4.1.1 体系结构
YARN(Yet Another Resource Negotiator,另一种资源协调者)是一个通用的资源管理系统和调度平台,它的基本设计思想是将MRv1(Hadoop1.0中MapReduce)中的JobTracker拆分为两个独立任务,这两个任务分别是全局的资源管理器ResourceManager和每个应用程序特有的ApplicationMaster。
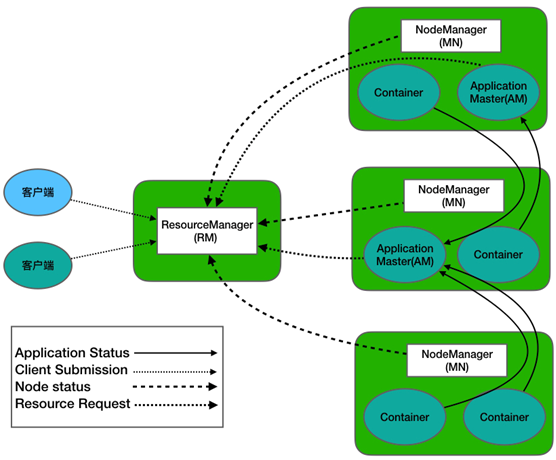
ResourceManager是一个全局的资源管理系统,它负责的是整个Yarn集群资源的监控、分配和管理工作。其内部包含了两个组件,分别是调度器(Scheduler)和应用程序管理器(Application Manager)。NodeManager是每个节点上的资源和任务管理器,一方面,它会定时向ResourceManager汇报所在节点资源使用情况;另一方面,它会接收并处理来自ApplicationMaster容器(Container)启动、停止等各种请求。- 用户提交的每个应用程序都包含一个
ApplicationMaster,它负责协调来自ResourceManager的资源,把获得的资源进一步分配给内部的各个任务,从而实现“二次分配”。
🕤 4.1.2 工作流程
YARN的底层工作流程是由核心组件互相协调管理,它们各尽其职,为Hadoop资源调度提供服务,其工作流程图如下所示。
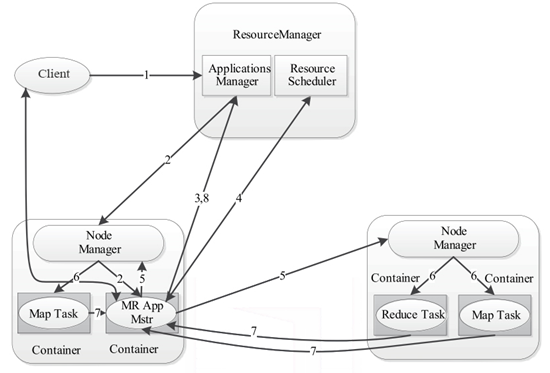
- 用户通过客户端Client向YARN提交应用程序Applicastion。
- YARN中的ResourceManager接收到客户端请求后,其内部的调度器会为应用程序分配一个容器运行本次程序对应的ApplicationMaster。
- ApplicationMaster被创建后,首先向ResourceManager注册信息,用户通过ResourceManager查看应用程序的运行状态。
- ApplicationMaster采用轮询方式通过RPC协议向ResourceManager申请资源。
- ResourceManager向提出申请的ApplicationMaster分配资源。
- NodeManager为任务设置好运行环境后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
- 各任务通过RPC协议向ApplicationMaster汇报自己的运行状态,从而在任务失败时,ApplicationMaster可重新启动任务。
- 应用运行结束后,ApplicationMaster向ResourceManager注销并关闭自己。
🕘 4.2 HDFS的高可用架构☆
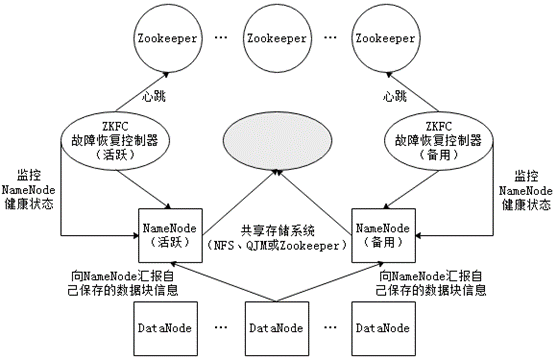
在HDFS分布式文件系统中,NameNode是系统核心节点,存储各类元数据信息,并负责管理文件系统的命名空间和客户端对文件的访问。若NameNode发生故障,会导致整个Hadoop集群不可用,即单点故障问题。为了解决单点故障,Hadoop2.0中HDFS中增加了对高可用的支持。
在高可用HDFS中,通常有两台或两台以上机器充当NameNode,无论何时,都要保证至少有一台处于活动(Active)状态,一台处于备用(Standby)状态。Zookeeper为HDFS集群提供自动故障转移的服务,给每个NameNode都分配一个故障恢复控制器(简称ZKFC),用于监控NameNode状态。若NameNode发生故障,Zookeeper通知备用NameNode启动,使其成为活动状态处理客户端请求,从而实现高可用。
🕒 5. Hive数据仓库
🕘 5.1 简介
Hive是建立在Hadoop文件系统上的数据仓库,它提供了一系列工具,能够对存储在HDFS中的数据进行数据提取、转换和加载(ETL),这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的工具。Hive定义简单的类SQL查询语言(即HQL),可以将结构化的数据文件映射为一张数据表,允许熟悉SQL的用户查询数据,允许熟悉MapReduce的开发者开发mapper和reducer来处理复杂的分析工作,与MapReduce相比较,Hive更具有优势。
🕘 5.2 系统架构
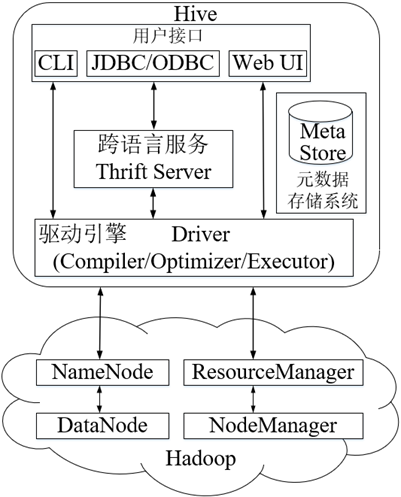
Hive是底层封装了Hadoop的数据仓库处理工具,运行在Hadoop基础上,其系统架构组成主要包含4部分,分别是用户接口、跨语言服务、底层驱动引擎及元数据存储系统。
🕘 5.3 数据模型
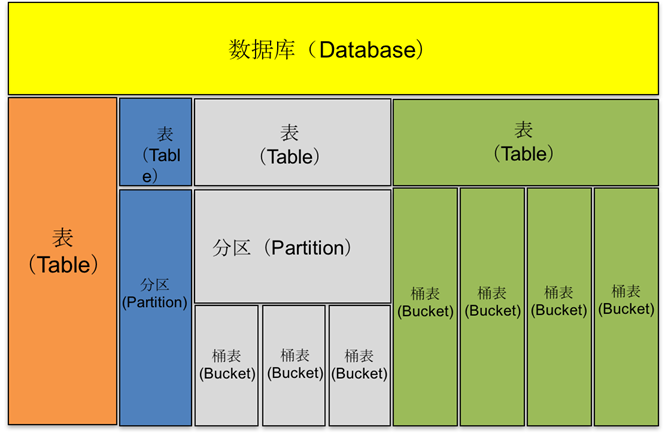
Hive中所有的数据都存储在HDFS中,它包含数据库(Database)、表(Table)、分区表(Partition)和桶表(Bucket)四种数据类型。
Q:简述Hive的特点是什么。
A:Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能,可以将SQL语句转换为MapReduce任务进行运行。其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
Q:简述Hive中内部表与外部表区别。
A:创建表阶段:
外部表创建表的时候,不会移动数到数据仓库目录中(/user/hive/warehouse),只会记录表数据存放的路径,内部表会把数据复制或剪切到表的目录下。
删除表阶段:
外部表在删除表的时候只会删除表的元数据信息不会删除表数据,内部表删除时会将元数据信息和表数据同时删除
编程题:创建字段为id、name的用户表,并且以性别gender为分区字段的分区表。
解答:
create table t_user (id int, name string)
partitioned by (gender string)
row format delimited fields terminated by ',';
🕒 6. Flume日志采集系统
🕘 6.1 简介
Apache Flume不仅只限于日志数据的采集,由于Flume采集的数据源是可定制的,因此Flume还可用于传输大量事件数据,包括但不限于网络流量数据、社交媒体生成的数据、电子邮件消息以及几乎任何可能的数据源。 Flume-ng版本在实际开发中应用最为广泛,采用三层架构,分别为agent,collector和storage,每一层均可以水平扩展。
🕘 6.2 运行机制☆
Flume的核心是把数据从数据源(例如Web服务器)通过数据采集器(Source)收集过来,再将收集的数据通过缓冲通道(Channel)汇集到指定的接收器(Sink)。
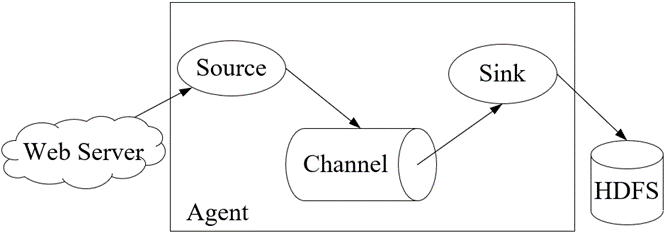
Flume基本架构中有一个Agent(代理),它是Flume的核心角色,Flume Agent是一个JVM进程,它承载着数据从外部源流向下一个目标的三个核心组件:Source、Channel和Sink。
Source:用于采集数据源的数据,并将数据写入到Channel。一个Source可以连接一个或多个Channel。Channel:用于缓存Source写入的数据,并将数据写入到Sink,待Sink将数据写入到存储设备或者下一个Source之后,Flume会删除Channel中缓存的数据。Sink:用于接收Channel写入的数据,并将数据写入到存储设备。
在整个数据传输过程,即Source→Channel→Sink,Flume将流动的数据封装到一个事件(Event)中,它是Flume内部数据传输的基本单元。
🕘 6.3 系统结构
在实际开发中, Flume需要采集数据的类型多种多样,同时还会进行不同的中间操作,所以根据具体需求,可以将Flume日志采集系统分为简单结构和复杂结构。
简单结构通常应用于采集数据的数据源单一,数据内容简单,并且采集数据的存储设备单一,这时在Flume日志采集系统中,可以直接使用一个Agent来实现。
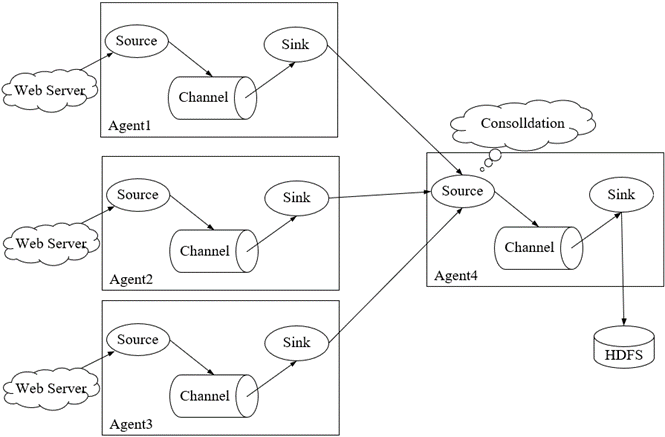
Flume复杂结构–多Agent:在某些实际应用场景中,Flume日志采集系统需要采集数据的数据源分布在不同的服务器上,可以再分配一个Agent来采集其他Agent从Web Server采集的日志,对这些日志进行汇总后写入到存储系统。
🕘 6.4 可靠性保证
🕤 6.4.1 负载均衡
配置的采集方案是通过唯一一个Sink作为接收器接收后续需要的数据,但会出现当前Sink故障或数据收集请求量较大的情况,这时单一Sink配置可能就无法保证Flume开发的可靠性。因此,Flume 提供Flume Sink Processors解决上述问题。
Sink处理器允许定义Sink groups,将多个sink分组到一个实体中,Sink处理器就可通过组内多个sink为服务提供负载均衡功能。
负载均衡接收器处理器(Load balancing sink processor)提供了在多个sink上进行负载均衡流量的功能,它维护一个活跃的sink索引列表,需在其上分配负载,还支持round_robin(轮询)和random(随机)选择机制进行流量分配,默认选择机制为round_robin。
🕤 6.4.2 故障转移
故障转移接收器处理器(Failover Sink Processor)维护一个具有优先级的sink列表,保证在处理event时,只需有一个可用的sink即可。
故障转移机制工作原理是将故障的sink降级到故障池中,在池中为它们分配一个冷却期,在重试之前冷却时间会增加,当sink成功发送event后,它将恢复到活跃池中。
🕒 7. Azkaban工作流管理器
Azkaban工作流管理器由三个核心部分组成,分别是Relational Database(关系型数据库MySQL)、AzkabanWebServer(Web服务器)、AzkabanExecutorServer(执行服务器)。三者关系具体如图所示。
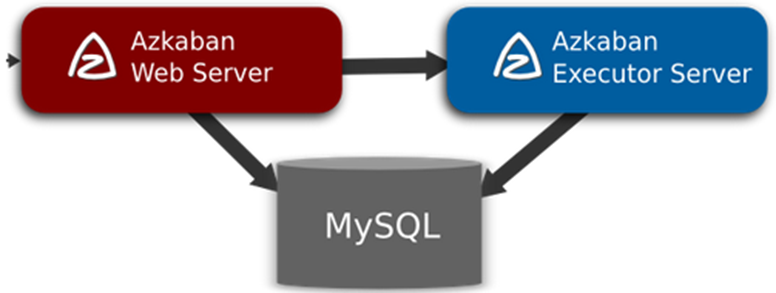
Relational Database负责存储Azkaban相关的数据,包括上传的工作流、作业的执行日志等,Azkaban Web Server和Azkaban Executor Server都会频繁访问Relational Database获取Azkaban相关的数据。Azkaban Web Server是Azkaban的主要管理者,它用于处理项目管理、身份验证、任务调度和触发工作流执行等,同时为用户提供Web界面供用户查看。Azkaban Executor Server主要负责工作流和工作的实际执行。在最初的Azkaban版本中,Azkaban Web Server和Azkaban Executor Server是自动部署在同一台服务器中的,后来由于功能需求和扩展,可以将Azkaban Web Server和Azkaban Executor Server分别部署在不同的服务器中。
Q:简述Azkaban的组成部分,以及各个部分的功能。
A:Azkaban分为三部分,mysql服务器:用于存储项目、日志或者执行计划之类的信息;web服务器:使用Jetty对外部提供web服务,使用户通过WEB UI操作Azkaban系统;executor服务器:负责具体的工作流的提交、执行。
🕒 8. Sqoop数据迁移
Sqoop是关系型数据库与Hadoop间进行数据同步的工具,其底层利用MapReduce并行计算模型以批处理方式加快数据传输速度,并且具有较好的容错性功能,以实现数据的导入和导出。在数据同步的过程中,MapReduce通常只涉及MapTask的处理,并不会涉及ReduceTask的处理,这是因为数据同步时,只涉及数据的读取与加载,并不会涉及到数据合并的操作。
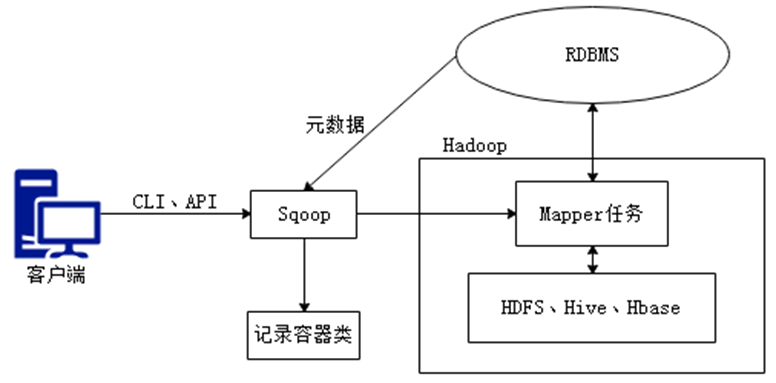
导入原理:在导入数据之前,Sqoop使用JDBC检查导入的数据表,检索出表中的所有列以及列的SQL数据类型,并将这些SQL类型映射为Java数据类型,在转换后的MapReduce应用中使用这些对应的Java类型来保存字段的值,Sqoop的代码生成器使用这些信息来创建对应表的类,用于保存从表中抽取的记录。
导出原理:在导出数据前,Sqoop会根据目标表的定义生成一个Java类,这个生成的类能够从文本中解析出记录数据,并能够向表中插入类型合适的值,然后启动一个MapReduce作业,从HDFS中读取源数据文件,使用生成的类解析出记录,并且执行选定的导出方法。
❗ 转载请注明出处
作者:HinsCoder
博客链接:🔎 作者博客主页
这篇关于【Hadoop大数据技术】——期末复习(冲刺篇)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






