本文主要是介绍【Gradio】使用 Gradio 进行表格数据科学工作流,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
简介
表格数据科学是机器学习中最广泛使用的领域,涉及的问题从客户细分到流失预测不等。在表格数据科学工作流的各个阶段,与利益相关者或客户沟通您的工作可能会很麻烦;这阻止了数据科学家专注于重要的事情,如数据分析和模型构建。数据科学家可能会花费数小时构建一个仪表板,该仪表板接收dataframe 并返回plots图表,或返回数据集中的群集的预测或图表。在本指南中,我们将介绍如何使用 gradio 来改进您的数据科学工作流程。我们还将讨论如何使用 gradio 和 skops 仅用一行代码构建接口!
先决条件
确保您已经安装了 gradio Python 包。
让我们创建一个简单的界面!
我们将看看如何创建一个简单的 UI,根据产品信息预测故障。
# 导入gradio、pandas、joblib和datasets库
import gradio as gr
import pandas as pd
import joblib
import datasets# 创建Gradio的输入与输出界面,输入是一个数据表格,输出是预测结果的数据表格
inputs = [gr.Dataframe(row_count=(2, "dynamic"), col_count=(4, "dynamic"), label="输入数据", interactive=1)]
outputs = [gr.Dataframe(row_count=(2, "dynamic"), col_count=(1, "fixed"), label="预测结果", headers=["故障数"])]# 从“model.pkl”加载预训练的模型
model = joblib.load("model.pkl")# 从datasets库中加载样例数据集“merve/supersoaker-failures”
df = datasets.load_dataset("merve/supersoaker-failures")
df = df["train"].to_pandas()# 定义预测函数,将从Gradio接口接收到的输入数据用预训练的模型进行预测
def infer(input_dataframe):return pd.DataFrame(model.predict(input_dataframe))# 创建Gradio界面,设置函数、输入与输出方式,并给出样例数据
gr.Interface(fn=infer, inputs=inputs, outputs=outputs, examples=[[df.head(2)]]).launch()让我们分解上面的代码。
fn:一个推理函数,它接受输入数据框并返回预测。inputs:我们用来取输入的组件。我们将输入定义为一个有 2 行 4 列的数据框,最初它看起来像一个空的数据框,有上述的形状。当row_count设置为dynamic时,你不必依赖于你输入到预定义组件的数据集。outputs:存储输出的数据框组件。这个 UI 可以取单个或多个样本进行推断,并且在一列中为每个样本返回 0 或 1,所以我们在上面给row_count为 2 和col_count为 1。headers是一个由数据框的表头名称组成的列表。examples:你可以通过拖放 CSV 文件,或者通过示例传递一个 pandas 数据框,其表头将被界面自动获取。
我们现在将创建一个最简数据可视化仪表板的例子。您可以在相关空间中找到一个更全面的版本。
# 导入gradio、pandas、datasets、seaborn和matplotlib.pyplot库
import gradio as gr
import pandas as pd
import datasets
import seaborn as sns
import matplotlib.pyplot as plt# 从datasets库中加载样例数据集“merve/supersoaker-failures”,并把空值所在行删除
df = datasets.load_dataset("merve/supersoaker-failures")
# 将"datasets"库加载的数据集转换为pandas的DataFrame格式
df = df["train"].to_pandas()
df.dropna(axis=0, inplace=True)# 定义函数来创建散点图、条形图和热力图
def plot(df):# 创建散点图plt.scatter(df.measurement_13, df.measurement_15, c = df.loading,alpha=0.5)plt.savefig("scatter.png")# 创建条形图df['failure'].value_counts().plot(kind='bar')plt.savefig("bar.png")# 创建热力图sns.heatmap(df.select_dtypes(include="number").corr())plt.savefig("corr.png")# 指定结果图像的文件路径plots = ["corr.png","scatter.png", "bar.png"]return plots# 创建Gradio的输入和输出格式,输入为数据框,输出为图像画廊
inputs = [gr.Dataframe(label="Supersoaker生产数据")]
outputs = [gr.Gallery(label="分析仪表板", columns=(1,3))]# 使用Gradio创建界面,并启动
gr.Interface(plot, inputs=inputs, outputs=outputs, examples=[df.head(100)], title="Supersoaker故障分析仪表板").launch()
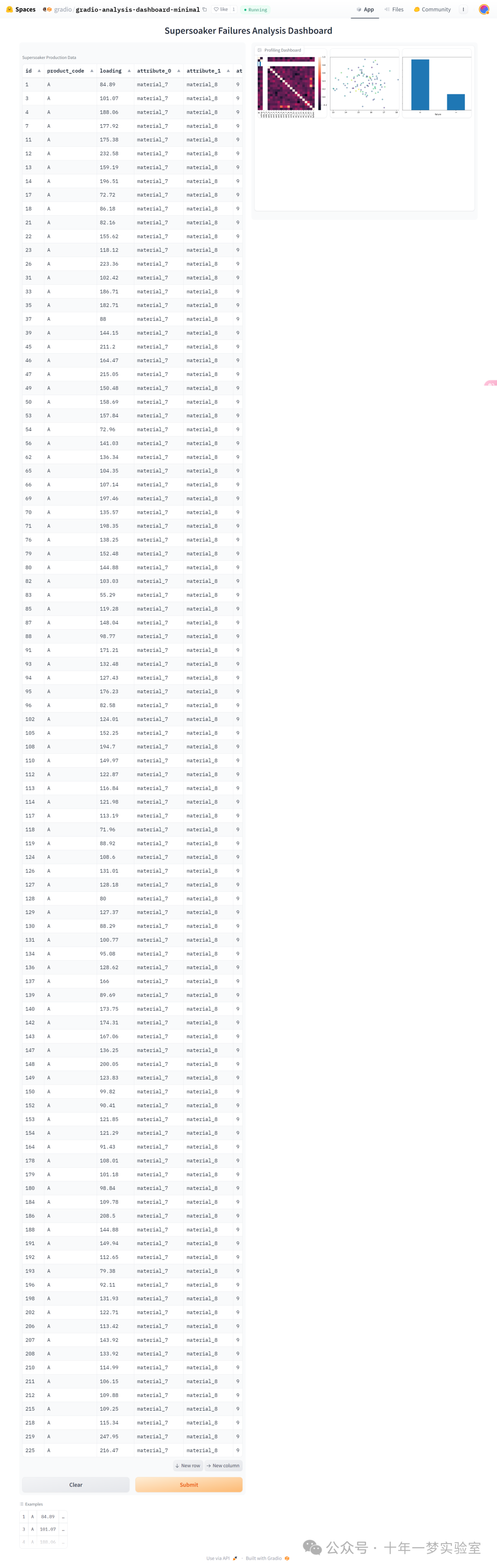
这段代码的作用是创建了一个交互式的分析仪表板,它可以直观地展示数据集“merve/supersoaker-failures”的散点图、条形图和热力图,使用户能更直观地了解数据情况,并帮助用户进行数据分析。
我们将使用训练模型时用的同一数据集,但这次我们将制作一个仪表板来可视化它。
fn:将根据数据创建图表的函数。inputs:我们使用了上面相同的Dataframe组件。outputs:Gallery组件用于保持我们的可视化。examples:我们将以数据集本身为例。
使用 skops 一行代码即可轻松加载表格数据接口
skops 是建立在 huggingface_hub 和 sklearn 之上的库。随着最近 gradio 对 skops 的集成,您可以用一行代码构建表格数据接口!
# 导入Gradio库,用于构建Web GUI
import gradio as gr# title和description是可选的,用于定义Web界面的标题和描述信息
title = "Supersoaker故障产品预测"
description = "该模型预测Supersoaker生产线上的故障。你可以拖拽数据集的任何部分,或者在下方的数据框组件中按需编辑值。"# 使用Gradio的load方法加载一个名为“huggingface/scikit-learn/tabular-playground”的模型
# 并设置了标题和描述。这个模型是从Hugging Face Hub上获取的,用于表格数据的预测
gr.load("huggingface/scikit-learn/tabular-playground", title=title, description=description).launch()使用 skops 推送到 Hugging Face Hub 的 sklearn 模型包括一个 config.json 文件,其中包含带有列名的示例输入,以及正在解决的任务(可以是 tabular-classification 或 tabular-regression )。根据任务类型, gradio 构建 Interface 并使用列名和示例输入来构建它。您可以参考 skops 关于在 Hub 上托管模型的文档,了解如何使用 skops 将模型推送到 Hub。https://skops.readthedocs.io/en/v0.9.0/auto_examples/index.html
这篇关于【Gradio】使用 Gradio 进行表格数据科学工作流的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



