本文主要是介绍两个让Transformer网络变得更简单,更高效的方法,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
作者:Sainbayar Sukhbaatar, Armand Joulin
编译:ronghuaiyang
导读
Transformer网络给深度学习的许多领域带来了巨大的进步,但它们在训练和推理过程中都非常需要计算资源,今天给大家带来两个使Transformer模型更简单、更高效的方法。
Transformer网络给深度学习的许多领域带来了巨大的进步,包括机器翻译、文本理解、语音和图像处理。尽管这些网络功能强大,但它们在训练和推理过程中都非常需要计算资源,这限制了它们的大规模的使用,尤其是对具有长期依赖关系的序列。Facebook人工智能的一项新研究正在寻找使Transformer模型更简单、更高效的方法。
为了更广泛地使用这种强大的深度学习体系结构,我们提出了两种新方法。第一,adaptive attention span,这是一个让Transformer网络对于长句子更有效率的方法。使用这种方法,我们能够在不显著增加计算时间或内存占用的情况下,将Transformer的注意广度增加到8000多个令牌。第二,all-attention layer,这是一种简化Transformer模型结构的方法。即使是一个简单得多的结构,我们的all-attention网络也可以匹配Transformer网络的性能上。我们认为,这项提高Transformer网络效率的工作是朝着使Transformer网络具有更广泛的应用迈出的重要一步。
Adaptive attention span
本研究的目的是使Transformer网络的计算效率更高,特别是在处理非常长的序列时。我们发现数据中的长期关系的需要更长的注意力的范围。然而,增加注意范围也会增加Transformer的计算时间和内存占用。
在我们对Transformer的实验中,我们发现并不是所有的注意力heads都充分利用了它们的注意范围。事实上,在一项字符级语言建模的任务中,大多数heads只使用了他们注意力范围的一小部分。如果我们能在训练中利用这一特性,我们就能显著减少计算时间和内存占用,因为两者都依赖于注意力范围的长度。不幸的是,我们不知道每个head的注意力范围是多少。在多次尝试启发式地设置注意范围之后,我们意识到,如果我们能从数据本身学到这一点,那是最好的。
由于注意范围是整数(因此是不可微的),我们不能像模型的其他参数那样通过反向传播直接学习它。但是,我们可以使用soft-masking函数将其转换为连续值。这个函数的值平滑地从1到0,这使得它可以对掩模长度求导。我们只需将这个掩模函数插入到每个注意力head中,这样每个head就可以根据数据确定不同的注意力范围。
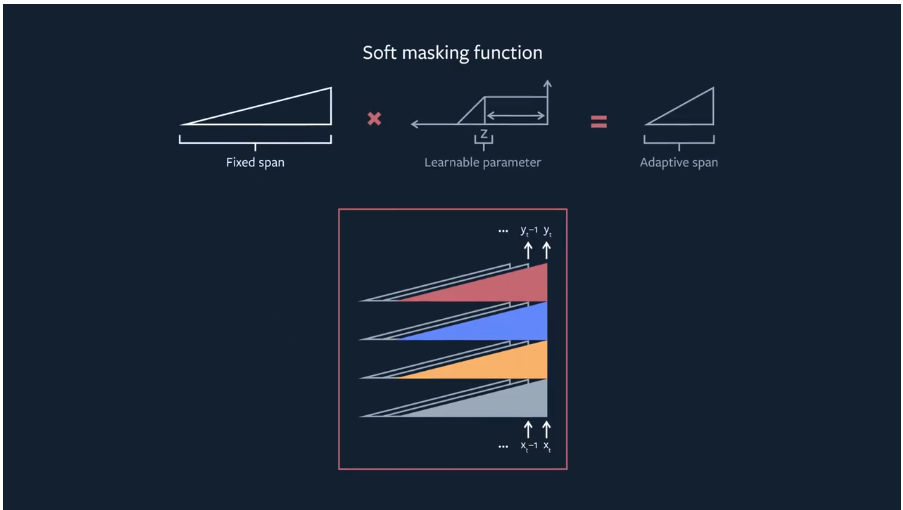
通过我们的自适应注意范围机制,我们设法将Transformer的注意范围提高到超过8000个tokens,而不会显著增加它的计算时间和内存占用。在字符级语言建模任务上,这导致了性能的提高,从而改进了现有技术的状态,使用了更少的参数。
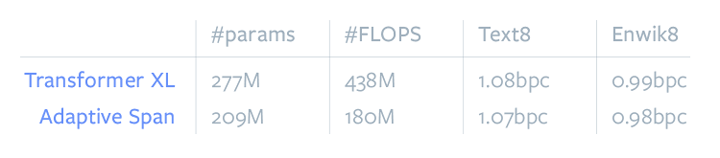
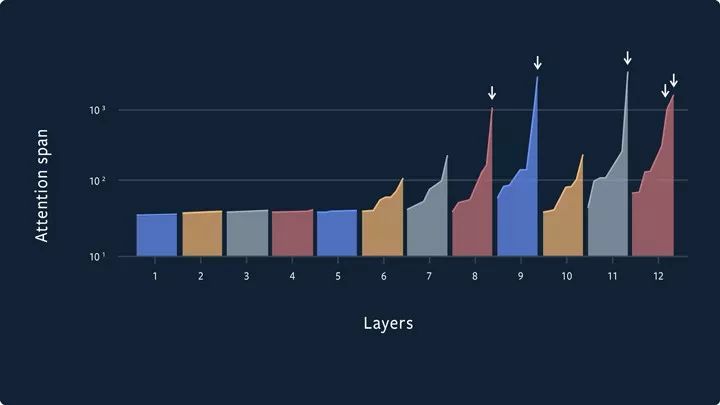
虽然模型中最长的注意力范围超过了8000步,但是平均的注意力范围只有200步左右,这使得模型运行起来更加高效。这反映在每一步的FLOPS上,这对于这些模型来说要小得多。在下面的图中,我们展示了一个这样的学习注意力范围,在一个12层的模型中,每层有8个heads。我们可以看到96个heads中只有5个有超过1000步的跨度。
我们已经发布了论文里的实验代码:https://l.facebook.com/l.php?u=https%3A%2F%2Fgithub.com%2Ffacebookresearch%2Fadaptive-span&h=AT3JCYNSm6Vd_t22nJUI6LUGDJXadI9sASr5E2KXFeVuzC0vkzMFavpGFZNTMFnHjw01Y18-M4TwVhUERft8vEhUI9ntCvHtatJ6M1ByU7ynviyVSDqvNbELeV_yYECjdz9SrJvYC_mxf4KVirIeXA由PyTorch实现,可以方便的集成到其他模型中。
All-attention layer
接下来,我们着重于简化Transformer网络的结构。Transformer由两个子层组成:自注意层和前馈层。虽然自注意层被认为是主要的组件,但是前馈子层对于高性能非常重要,这就是为什么它的大小通常设置为网络其他部分的四倍。
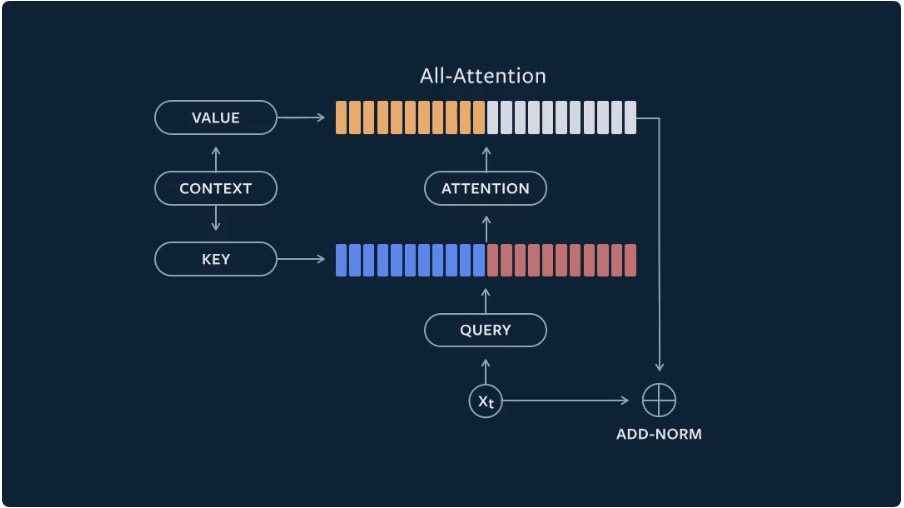
从表面上看,自我注意和前馈子层看起来非常不同。然而,一个简单的改变,前馈子层可以变成一个注意层。将ReLU非线性函数替换为softmax函数,可以将其激活解释为注意权值。此外,我们可以把第一个线性变换看作key向量,把第二个线性变换看作value向量。
利用这个解释,我们将前馈子层合并到自注意层,创建一个统一的注意层,我们称之为“all-attention”层。我们所要做的就是在一个自我注意层的key和value中添加一组额外的向量。这些额外的向量就和前馈子层的权值是一样的:固定的、可训练的和上下文无关的。相反,根据上下文计算的key和value会根据当前上下文动态更改。

—END—
英文原文:https://ai.facebook.com/blog/making-transformer-networks-simpler-and-more-efficient/

请长按或扫描二维码关注本公众号
喜欢的话,请给我个好看吧!![]()
这篇关于两个让Transformer网络变得更简单,更高效的方法的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





