本文主要是介绍有监督对比学习的一个简单的例子,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
点击上方“AI公园”,关注公众号,选择加“星标“或“置顶”
因公众号更改了推送规则,记得读完点“在看”~下次AI公园的新文章就能及时出现在您的订阅列表中
作者:Dimitre Oliveira
编译:ronghuaiyang
导读
使用有监督对比学习来进行木薯叶病害识别。
论文链接:https://arxiv.org/abs/2004.11362

监督对比学习(Prannay Khosla等人)是一种训练方法,它在分类任务上优于使用交叉熵的监督训练。
这个想法是,使用监督对比学习(SCL)的训练模型可以使模型编码器从样本学习更好的类表示,这应该导致更好的泛化,并对于图像和标签的错误更具鲁棒性。
在本文中,你将了解什么是监督对比学习,以及监督对比学习是如何工作的,你会看到代码实现、一个应用程序的例子,最后将看到SCL和常规交叉熵之间的比较。
简而言之,SCL就是这样工作的:
在嵌入空间中将属于同一类的聚类点聚在一起,同时将来自不同类的样本簇分离。
有许多对比学习方法,如" 监督对比学习"," 自监督对比学习"," SimCLR "等,它们的比对部分都是共同的,它们学习来自一个域的样本和来自另一个域的样本的差别,但SCL以监督的方式利用标签信息完成这项任务。
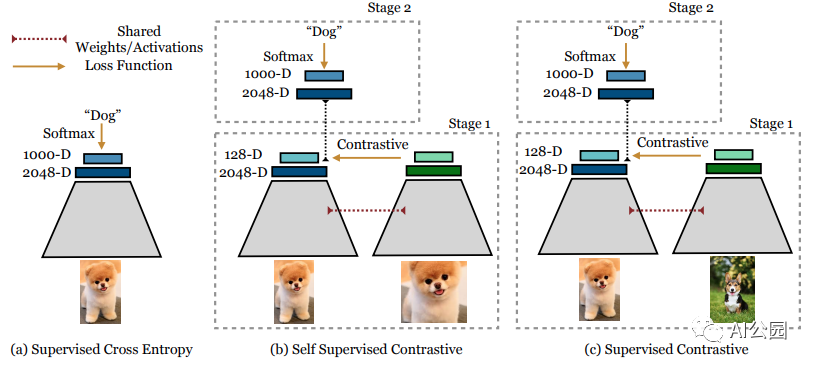
本质上,用监督对比学习对分类模型进行训练分为两个阶段:
训练编码器,学习生成输入图像的向量表示,这样,同类别图像的表示将比不同类别图像的表示更加相似。
在参数冻结的编码器上训练一个分类器。
例子
我们将把监督比较学习应用于Kaggle竞赛的数据集(Cassava Leaf Disease Classification),目的是将木薯叶的图像分类为5类:
0: Cassava Bacterial Blight (CBB)
1: Cassava Brown Streak Disease (CBSD)
2: Cassava Green Mottle (CGM)
3: Cassava Mosaic Disease (CMD)
4: Healthy
我们有四种疾病和一种健康的叶子,下面是一些图像样本:

数据有21397图像用于训练,大约有15000图像用于测试集。
实验设置
数据:图像分辨率512 × 512像素。
模型(编码器):EfficientNet B3。
你可以在这里查看:https://www.kaggle.com/dimitreoliveira/cassava-leaf-supervised-contrastive-learning
通常,对比学习方法能更好地工作,如果每个训练一个batch都有每个类的样本,这将有助于编码器学会对比不同域之间的差别,这意味着需要使用一个大的batch size,在这种情况下,我已经对每个类进行了过采样,所以每个batch的样本中每个类样本的概率大致相同。

数据增强通常有助于计算机视觉任务,在我的实验中,我也看到了数据增强的改进,这里我使用剪切,旋转,翻转,作物,剪切,饱和度,对比度和亮度的变化,它可能看起来很多,但图像没有和原始图像有太大不同。

现在我们可以看看代码了
编码器
我们的编码器将是一个“EfficientNet B3”,但是在编码器的顶部有一个平均池化层,这个池化层将输出一个2048大小的向量,稍后它将用于检查编码器学习到的表示。
def encoder_fn(input_shape):inputs = L.Input(shape=input_shape, name=’inputs’)base_model = efn.EfficientNetB3(input_tensor=inputs, include_top=False,weights=’noisy-student’, pooling=’avg’)model = Model(inputs=inputs, outputs=base_model.outputs)return model
投影头
投影头位于编码器的顶部,负责将编码器嵌入层的输出投影到更小的尺寸中,在我们的例子中,它将2048维的编码器投影到128维的向量中。
def add_projection_head(input_shape, encoder):inputs = L.Input(shape=input_shape, name='inputs')features = encoder(inputs)outputs = L.Dense(128, activation='relu', name='projection_head', dtype='float32')(features)model = Model(inputs=inputs, outputs=outputs)return model
分类头
分类器头用于的可选的第二阶段训练,在SCL 训练阶段之后,我们可以去掉投影头,把这个分类器头加到编码器上,并使用常规的交叉熵损失来finetune模型,这样做的时候,需要冻结编码器层。
def classifier_fn(input_shape, N_CLASSES, encoder, trainable=False):for layer in encoder.layers:layer.trainable = trainableinputs = L.Input(shape=input_shape, name='inputs')features = encoder(inputs)features = L.Dropout(.5)(features)features = L.Dense(1000, activation='relu')(features)features = L.Dropout(.5)(features)outputs = L.Dense(N_CLASSES, activation='softmax', name='outputs', dtype='float32')(features)model = Model(inputs=inputs, outputs=outputs)return model
监督对比学习损失
这是SCL损失的代码实现,这里唯一的参数是temperature,“0.1”是默认值,但它可以调整,较大的temperatures可以导致类更分离,但较小的temperatures 有益于较长的训练。
class SupervisedContrastiveLoss(losses.Loss):def __init__(self, temperature=0.1, name=None):super(SupervisedContrastiveLoss, self).__init__(name=name)self.temperature = temperaturedef __call__(self, labels, ft_vectors, sample_weight=None):# Normalize feature vectorsft_vec_normalized = tf.math.l2_normalize(ft_vectors, axis=1)# Compute logitslogits = tf.divide(tf.matmul(ft_vec_normalized, tf.transpose(ft_vec_normalized)), temperature)return tfa.losses.npairs_loss(tf.squeeze(labels), logits)
训练
我将跳过Tensorflow样板训练代码,因为它非常标准,但是你可以在这里:https://www.kaggle.com/dimitreoliveira/cassava-leaf-supervised-contrastive-learning/notebook#Training-(supervised-contrastive-learning查看完整的代码。
第一个训练步骤 (编码器 + 投影头)
第一阶段的训练是用编码器+投影头,使用有监督对比学习损失。
构建模型
with strategy.scope(): # Inside a strategy because I am using a TPUencoder = encoder_fn((None, None, CHANNELS)) # Get the encoderencoder_proj = add_projection_head((None, None, CHANNELS),encoder)# Add the projection head to the encoderencoder_proj.compile(optimizer=optimizers.Adam(lr=3e-4), loss=SupervisedContrastiveLoss(temperature=0.1))
训练
model.fit(x=get_dataset(TRAIN_FILENAMES, repeated=True, augment=True), validation_data=get_dataset(VALID_FILENAMES, ordered=True), steps_per_epoch=100, epochs=10)
第二个训练步骤 (编码器 + 分类头)
对于训练的第二阶段,我们删除投影头,并在编码器的顶部添加分类器头,现在该编码器已经训练了权值。对于这一步,我们可以使用常规的交叉熵损失,像往常一样训练模型。
构建模型
with strategy.scope():model = classifier_fn((None, None, CHANNELS), N_CLASSES, encoder, # trained encodertrainable=False) # with frozen weights model.compile(optimizer=optimizers.Adam(lr=3e-4),loss=losses.SparseCategoricalCrossentropy(), metrics=[metrics.SparseCategoricalAccuracy()])
训练
和之前几乎一样
model.fit(x=get_dataset(TRAIN_FILENAMES, repeated=True, augment=True), validation_data=get_dataset(VALID_FILENAMES, ordered=True), steps_per_epoch=100, epochs=10)
可视化输出向量
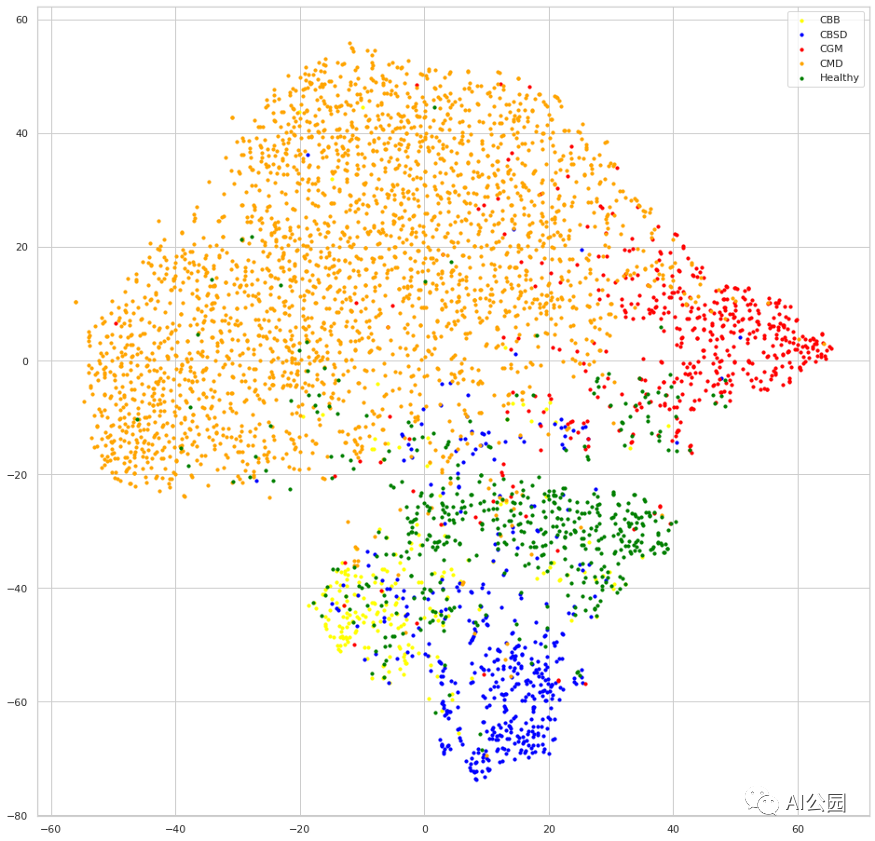
评估编码器的学习表示的一种有趣的方法是可视化特征嵌入的输出,在我们的例子中,它是编码器的最后一层,即平均池化层。在这里,我们将比较用SCL训练的模型和另一个用常规交叉熵训练的模型,你可以在:https://www.kaggle.com/dimitreoliveira/cassava-leaf-supervised-contrastive-learning中看到完整的训练。可视化是通过在验证数据集的嵌入输出上应用t-SNE生成的。
交叉熵的嵌入
监督对比学习的嵌入
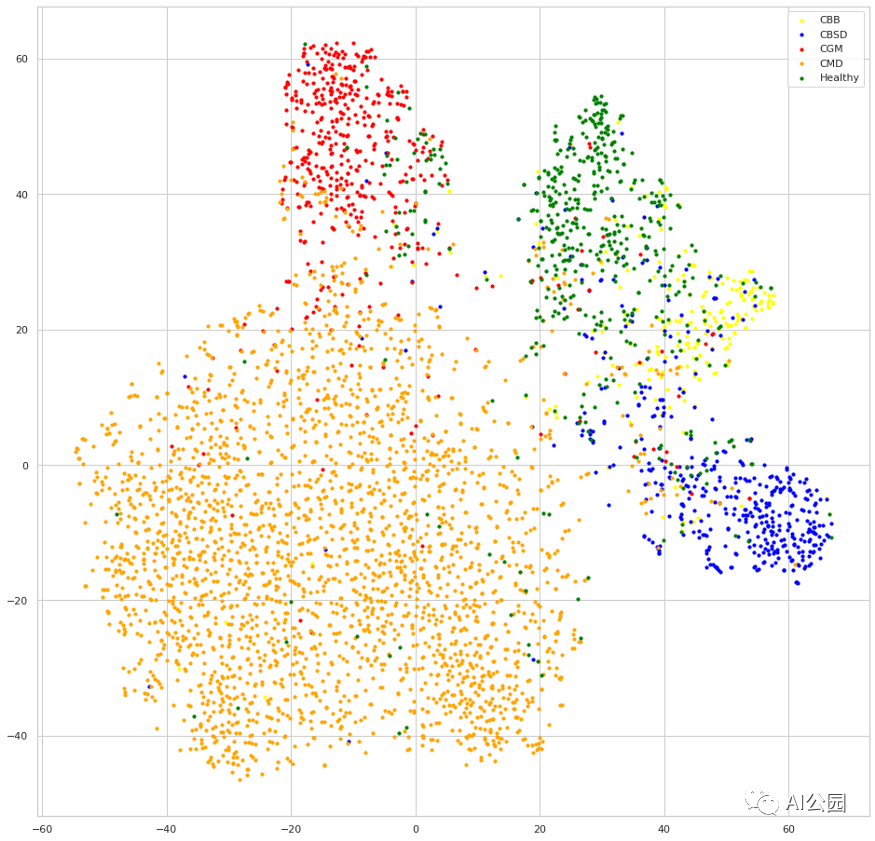
我们可以看到,两种模型在对每个类进行样本聚类的时候似乎都可以做的不错,但看下SCL模型训练出来的嵌入,每个类的簇相互之间的距离要更远,这就是对比学习的效果。我们也可以认为,这种行为将导致更好的泛化,因为类的判别边界会更清晰、如果去尝试画一下类别之间的边界,就可以得到一个很直观的理解。
总结
我们看到,使用监督对比学习方法的训练既容易实现又有效,它可以带来更好的准确性和更好的类表示,这反过来也可以产生更健壮的模型,能够更好地泛化。

—END—
英文原文:https://pub.towardsai.net/supervised-contrastive-learning-for-cassava-leaf-disease-classification-9dd47779a966

请长按或扫描二维码关注本公众号
喜欢的话,请给我个在看吧!
这篇关于有监督对比学习的一个简单的例子的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









