本文主要是介绍AI技术在词典笔上的应用实践,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
本文包括以下几个内容
1.扫描和点查
2.离线翻译
3.高性能端侧机器学习计算库EMLL(Edge ML Library)
扫描和点查
扫描识别
扫描识别和常见的字符识别场景不一样

一秒钟100张图像
算法需要从快速从拍摄的图像中提取文字

全景拼接
拼接效果对识别影响很大

全景拼接
像素级检测:对每个像素位置进行文字和背景分类
中心组行:基于分类结果和位置信息,将扫描的中心文字连接并组合成行
矫正切行:将文本行从复杂的背景中切分出来
复杂的应用场景
• 特殊字体,形近字,背景都会干扰识别

检测模块+识别模块+纠正模块

超快点查
问题
• 超大广角点查导致广角畸变、光照不均
超快点查
• 根据采集图像预设变换参数
• 将采集图像逆变换得到无畸变图像
• 对阴影进行补偿

离线翻译
• 离线翻译的需求
• 无网络环境
• 低时延
• 节省带宽
• 隐私
在线翻译模型
• 编码器-解码器架构
• 多个编码器层和解码器层
• 很宽的维度
• 参数量达到上亿规模

• 神经网络模型存在一定冗余

• 裁剪模型
• 共享参数
• 量化
• 知识蒸馏
• Lite Transformer
裁剪模型
• 编码器相对更重要
• 更多压缩解码器
• 减少深度的同时减少宽度
共享参数
词向量的共享

不同层之间的共享

量化
• 高精度的浮点类型转化为低精度的整型计算
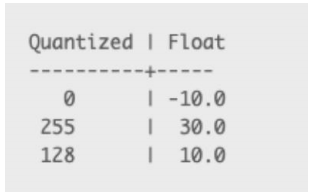
• 浮点数运算使用量化运算
• 计算量减少,对NPU,DSP芯片友好
• 存储规模减少
• 使用训练感知量化对质量影响也较小
知识蒸馏
• 模型压缩导致质量下降

• 利用教师模型提升学生模型性能
• 教师模型:大而慢
• 学生模型:小而快

蒸馏的方法
• Word-level KD
• Sentence-level KD

高性能端侧机器学习计算库EMLL(Edge ML Library)
端侧AI面临的挑战
• 算力、内存有限
• 功耗限制
• 算法更新
• 多应用部署
端侧AI芯片
端侧AI芯片
• ARM CPU
• 当前端侧AI落地主流平台
• NPU、DSP、GPU
• 受生态环境影响,当前可落地的AI应用较少
• 未来发展趋势
• 端侧AI底层主要耗时计算
• gemm(全连接层、卷积层)
• 扁平矩阵乘
• 第三方blas库gemm针对端侧AI场景下计算性能较差

EMLL
• EMLL(Edge ML Library)——高性能端侧机器学习计算库
• 为加速端侧AI推理而设计
• 为端侧AI常见的扁平矩阵的计算做了专门的优化
• 支持fp32、fp16、int8等数据类型
• 针对ARM cortex-A7/A35/A53/A55/A76等处理器进行汇编优化
• 支持端侧运行OS:Linux和Android
EMLL优化方法
访存
• 展开外层循环 – 计算/访存比
• 重排元素 – 顺序访存
• 多级分块 – 利用缓存
• 针对扁平矩阵的优化
计算
• SIMD 指令
• 指令顺序
• 指令并发
• 多线程(动态负载)
EMLL功能
• 支持的计算函数
• 支持的架构
• ARMv7a
• ARMv8a
• 支持的端侧OS
• Linux

EMLL GEMM 性能

离线NMT量化效果

这篇关于AI技术在词典笔上的应用实践的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!



