本文主要是介绍模型压缩明珠:二值化网络,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
二值化网络(BNN)

- 老板:量化到INT8又怎么样!还不够小!我要把AI模型放在耳机手表里面!!
- 员工:那我们用二值化网络!!一切都是0和1!!
二值化网络跟低比特量化一样,目的是让模型更小,小到有着最为极端的压缩率和极低的计算量。那什么是二值呢?二值指的是仅仅使用+1和-1(或者是0和1)两个值,来表示权重和激活的神经网络。
相比于全精度(FP32)表示的神经网络,二值化可以用XNOR(逻辑电路中的异或非门)或者是简单的计数操作(pop Count),极其简单的组合来代替FP32的乘和累加等复杂的运算来实现卷积操作,从而节省了大量的内存和计算,大大方便了模型在资源受限设备上的部署。
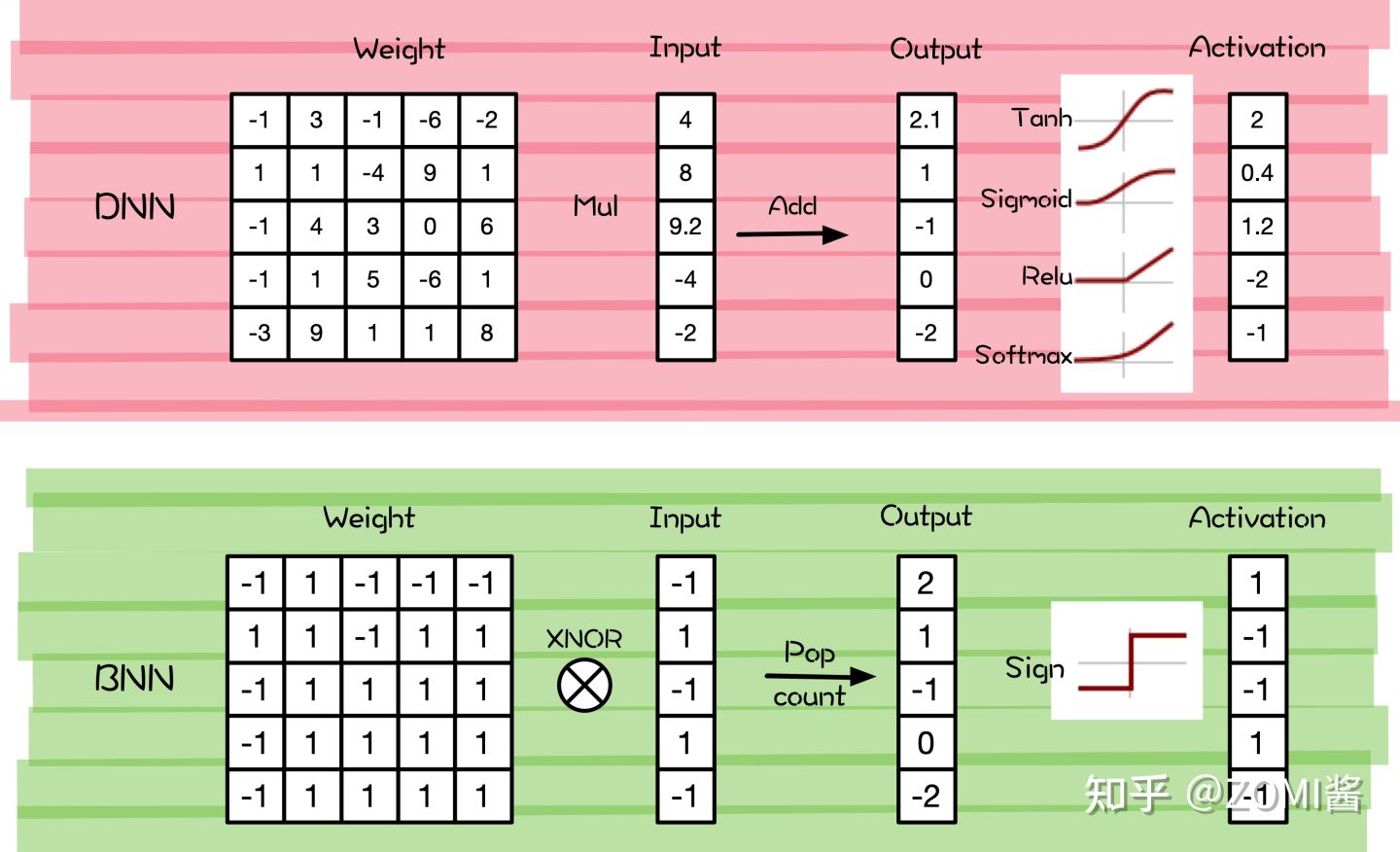
BNN由于可以实现极高的压缩比和加速效果,所以是推动以深度神经网络为代表的人工智能模型,在资源受限和功耗受限的移动设备上落地应用的一门非常具有潜力的技术啦。
不过呢,目前BNN仍然存在着很多不足,例如模型精度仍然比全精度低,无法有效地泛化到更复杂的任务上,依赖于特定的硬件架构和软件框架等。但同时也能看到,BNN从2016年首次提出时,ImageNet上只有27%的Top1准确率,到2020年提出的ReActNet-C有着71.4%准确率的进步!
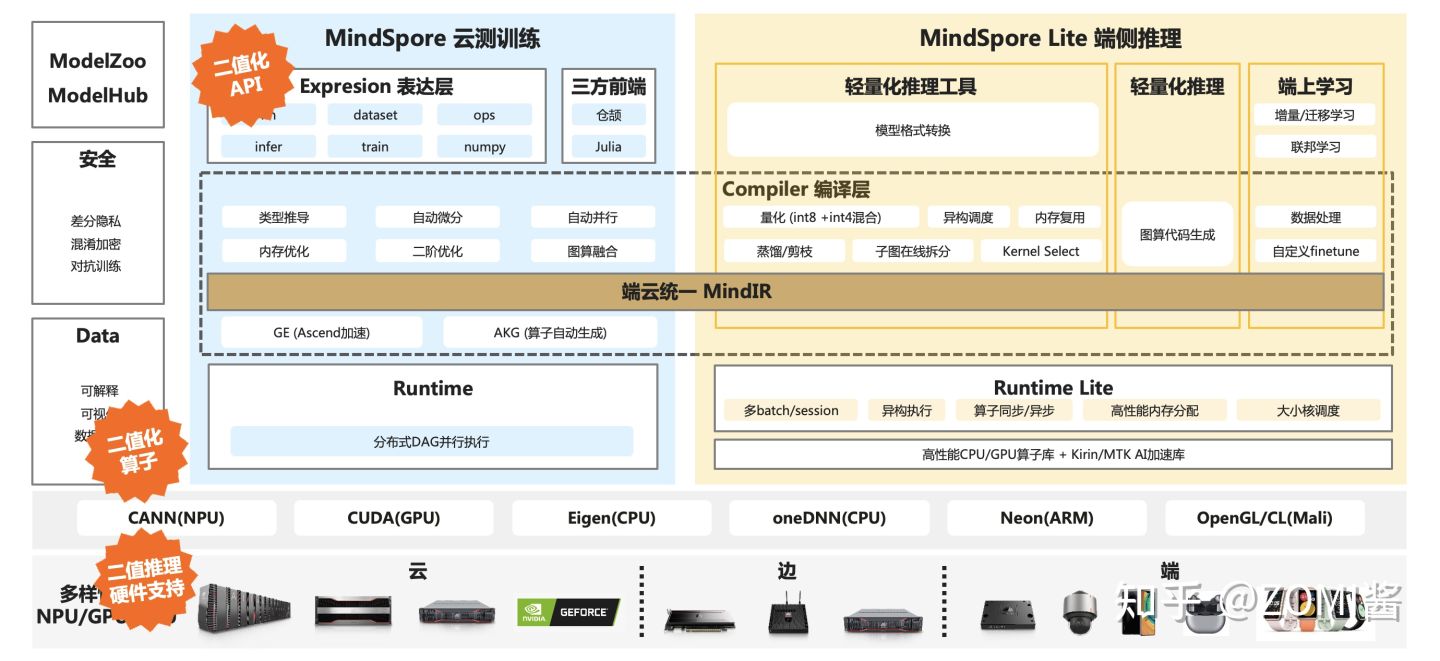
下面来看看BNN在AI系统全栈/AI框架中的一个位置,橙色标签的地方是BNN所在的位置。从图中可以知道,在表达层API需要提供二值化网络模型使用到的API接口;接着在中间边一层和runtime其实没有太多的区别,最主要是底层需要提供二值化相关的算子或者是二值化推理的专用硬件电路。
1. BNN基本介绍
BNN最初由Yoshua Bengio[1]在2016年的时候首次提出来,论文中表示使用随机梯度下降的方式来训练带有二值化的权重weight和激活act参数的神经网络模型。
1.1 前向计算
为了解决二值化权重weight计算中梯度的传递问题,论文中提出在训练过程中保持一个实值(FP32)的权重,然后使用一个sign函数来获得二值化的权重参数。WR 为FP32, 为二值化后的值:
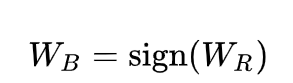
其中sign函数为只要输入的参数大于等于0则为1,否则都是-1:
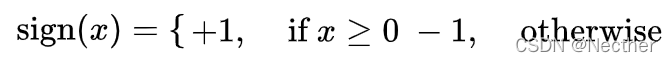
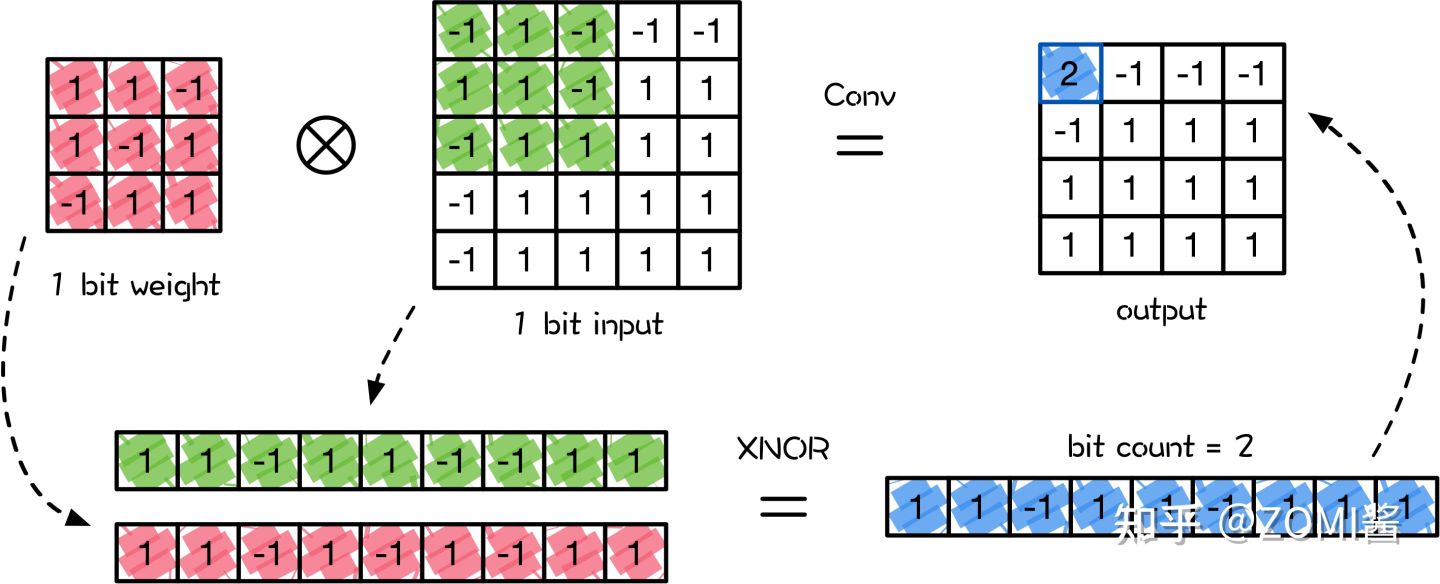
下面图中上面的是二值化权重和二值化输入的一个3X3卷积操作,二值化操作则是对卷积核和输入数据的窗口进行平铺展开,然后进行XNOR操作,接着进行bit count计数得到卷积结果。
1.2 反向传播
跟感知量化训练的方式类似,sign函数在0处不可导,导数为0时会遇到没有办法计算梯度,于是论文中提出了直通估计 (straight through estimator STE),即当梯度传递遇到sign函数时,直接跳过这个函数:
![]()
使用了直通估计STE之后,可以使用与全精度神经网络相同的梯度下降方法直接训练二值神经网络。权重参数可以使用常见的优化器来进行更新,同时考虑到训练过程权重参数是没有进行截断的,这样权重参数可能会一直累加到特别大的值,从而与二值化的权重之间的量化误差越来越大,因此论文对训练过程中的权重增加截断函数,将其限制在-1和+1之间,这样使得训练过程中权重参数和二值化的权重参数的误差偏差不会过大:![]()
既然对FP32训练的过程有嵌入式的修改,那么肯定会导致训练的时间更长了,而且最终的实验结果准确率没有FP32那么高,有什么用吗?
这里翻译翻译,其实最大的作用是前向的图所示,可以1 bit的异或非和pop count操作,来代替FP32的卷积进行乘和累加操作,在实际模型部署和推理的时候,不仅能减少32倍的内存参数存储,还能跑的比马都快!
3. BNN网络结构
近年来,各种各样的二值神经网络方法被提出,从使用预定义函数直接对权重和输入进行量化的朴素二值化方法,到使用基于多种角度和技术的基于优化的二值化方法,其中包括通过最小化量化误差来近似全精度值、通过修改网络损失函数来限制权重、和通过减小梯度误差来学习离散参数。
其中北京航空航天大学最新综述文章 Binary Neural Networks: A Survey 已经对很多二值化的网络模型写了个比较好的综述了,下面ZOMI简单介绍个我觉得比较精彩的BNN网络模型结构。
4. 硬件实现
从二值化网络的流程来看,BNN的主要加速原因就是用XNOR与Pop Count操作来代替了传统卷积算法中,使用昂贵的乘法-累加MAC操作。
而通用的x86计算架构,基本上都是对FP32全精度类型数据的计算,进行底层的硬件和编译执行优化,所以直接将BNN部署在通用的x86计算平台收益其实并不明显,甚至可能不仅没有加速效果,甚至比同等的FP32网络模型执行还慢。
下面分别看在ARM CPU和FPGA平台的一个简单分析。
ARM CPU
BNN其实目前聚焦部署在移动端。BMXNet 2017[3]由来自德国Hasso Plattner Institute的研究员Haojin Yang等开发,其为一个基于MXNet的二值化开源框架。支持使用CuDNN进行训练,并使用二值运算符XNOR和Pop Count做推理。不足之处是二值化内核并未经过专门调优,因此在ARM CPU上的速度表现并不突出。
Dabnn 2019[4]由京东AI研究院推出,基于汇编调优后的BNN推理工具。它有效提升了BNN在ARM框架端上的推理速度,但是这个工具并不能用于模型训练,需要使用其它工具进行训练。
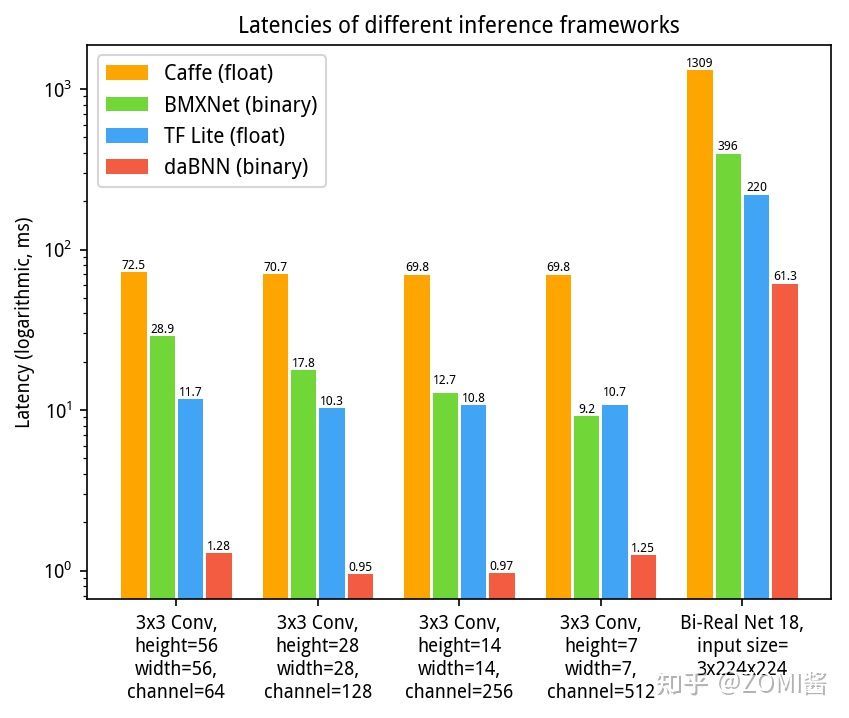
BMXNet-v2 2019[9],Bethge和Yang等开源了支持Gluon API的第二版。该框架采用的一系列改进大大降低了模型训练难度,大大减小了MXNet同步的成本。第二版不仅提升了效率,同时继续支持模型的压缩和二值化推理,可将模型部署在多种边缘设备上。
FPGA和ASIC
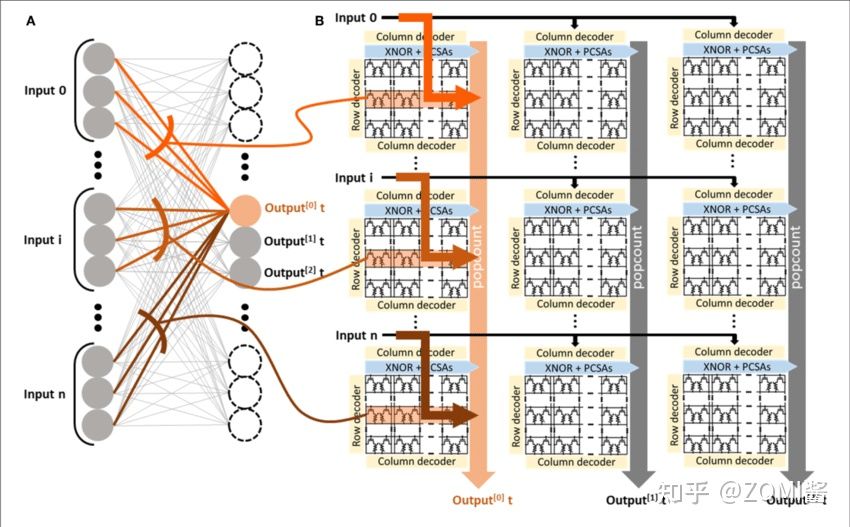
相比于传统的CPU,FPGA在硬件架构设计方面很灵活,可以支持bits-wise的高效运算,而且功耗很低,其对应的终极版的专用集成电路ASIC更是如此,可以比FPGA运算更高效,更节能。
目前用FPGA设计AI加速器基本都是以Xilinx的器件和开发工具为主,而他们也为二值化神经网络专门设计了一款架构FINN,开发者可以利用高层次综合工具(HLS),用C语言进行开发,直接将二值化模型部署到FPGA上。
总结
虽然BNN在近5年来已经取得了很大的进步啦,但是比较大的问题就是精度的损失仍然是个头痛的问题,尤其是对于大型网络和数据集而言。主要原因可能包括:
1)目前还没有SOTA的二值化网络模型,不确定什么样的网络结构才合适做二值化;
2)即使有用于二值化的梯度估计或近似函数,在离散空间中优化二值网络是一个难题。
另外,随着移动设备广泛使用,将出现更多针对这些应用进行的研究工作,以实现不同的任务以及模型在不同硬件上的部署。例如在耳机进行触感分析、点击分析这种大部分都是对信号进行分类操作,其实不需要大模型,反而这个时候二值化网络,能够很好地对信号数据进行高精度分类,去判断到底是双击停止播放音乐还是拖动放大声音。
最后,对可解释机器学习的研究表明,神经网络的推理中存在关键路径,并且不同的网络结构遵循不同的模式。因此,根据层的重要性设计混合精度策略,并设计出对二值神经网络的信息流友好的新网络结构,也具有重要意义。
参考文献
- [1] Courbariaux, Matthieu, et al. "Binarized neural networks: Training deep neural networks with weights and activations constrained to+ 1 or-1." arXiv preprint arXiv:1602.02830 (2016).
- [2] Qin, Haotong, et al. "Binary neural networks: A survey." Pattern Recognition 105 (2020): 107281.
- [3] Yang, Haojin, et al. "Bmxnet: An open-source binary neural network implementation based on mxnet." Proceedings of the 25th ACM international conference on Multimedia. 2017.
- [4] Zhang, Jianhao, et al. "dabnn: A super fast inference framework for binary neural networks on arm devices." Proceedings of the 27th ACM international conference on multimedia. 2019.
- [5] https://zhuanlan.zhihu.com/p/27
这篇关于模型压缩明珠:二值化网络的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







