本文主要是介绍(创新)基于VMD-CNN-BiLSTM的电力负荷预测—代码+数据,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、主要内容:
二、运行效果:
三、VMD-BiLSTM负荷预测理论:
四、代码+数据下载:
一、主要内容:
本代码结合变分模态分解( Variational Mode Decomposition,VMD) 和卷积神经网络(Convolutional neural network, CNN)-双向长短时记忆神经网络( Bi-Long Short-Term Memory,Bi-LSTM) 算法,建立了一种短期负荷预测模型( VMD-CNN-BiLSTM) 。首先采用 VMD 技术将输入负荷数据分解为多个有限带宽的本征模态分量,分解结果表明了人们生产生活中不同的用电习惯,并且分离了数据中的噪声和信号,然后对每个模态分量建立 CNN-BiLSTM 神经网络进行预测,结合模型输出重构预测结果。其中,CNN用于提取负荷分量中的用电特征信息,BiLSTM用于提取负荷分量中的用电时序信息。
本代码基于Matlab平台,建立了VMD-CNN-BiLSTM模型进行负荷预测,并和传统的单一CNN-BiLSTM模型进行对比,充分说明本文所提方法的有效性。
-
注释详细,几乎每一关键行都有注释说明,适合小白起步学习
-
直接运行Main函数即可看到所有结果,使用便捷
-
编程习惯良好,程序主体标准化,逻辑清晰,方便阅读代码
-
附带一年365天的负荷数据,所有数据均采用Excel格式输入,替换数据方便,适合懒人选手.
-
100%原创,出图详细、丰富、美观,可直观查看运行效果
二、运行效果:
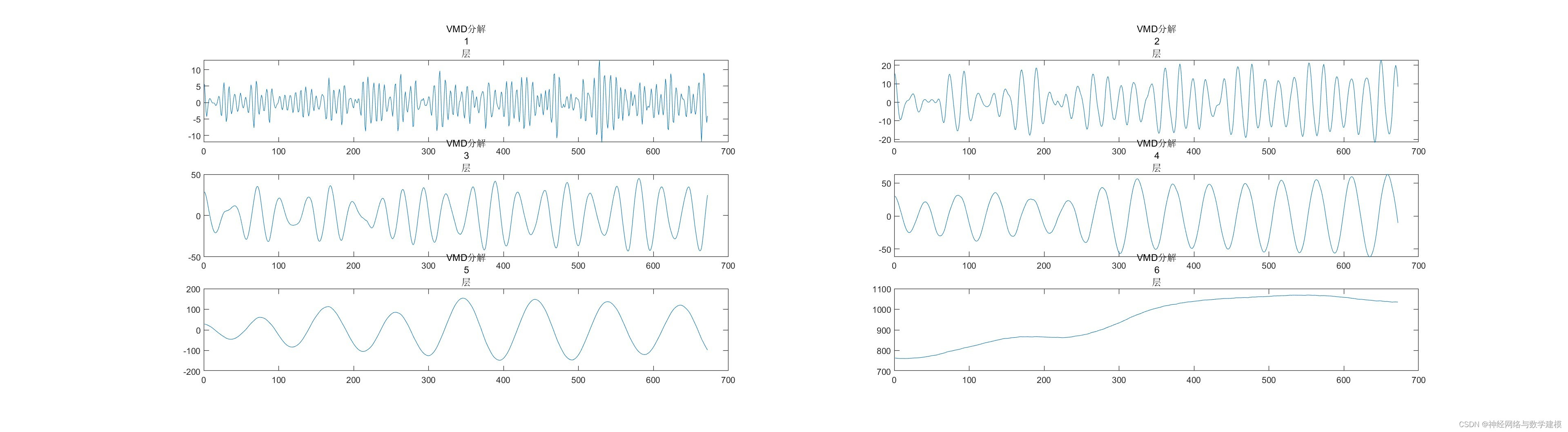
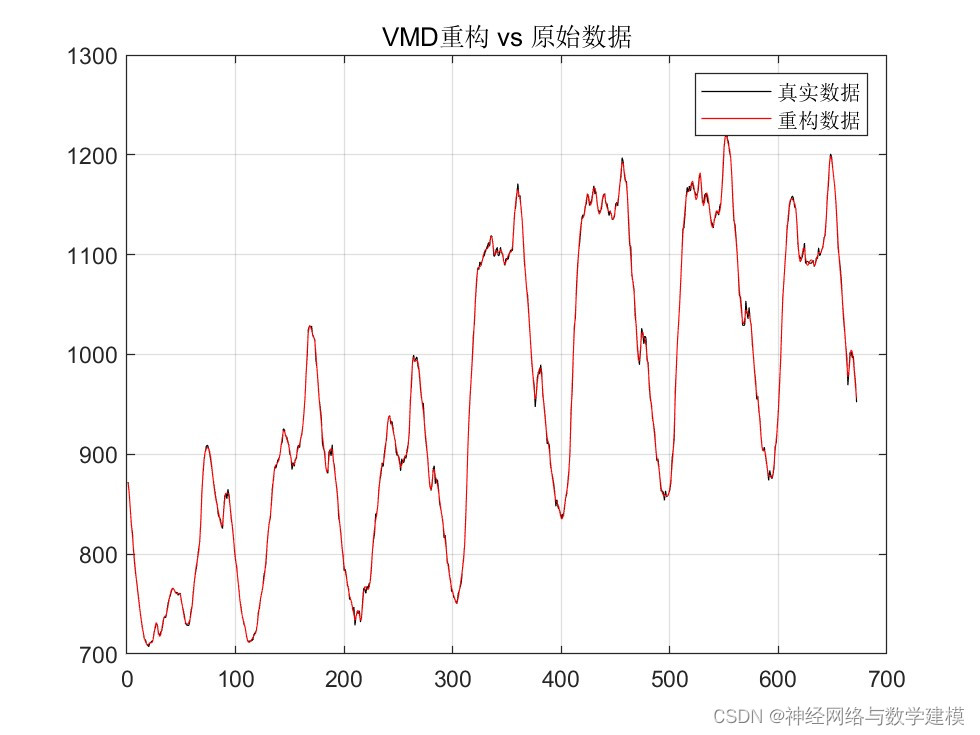
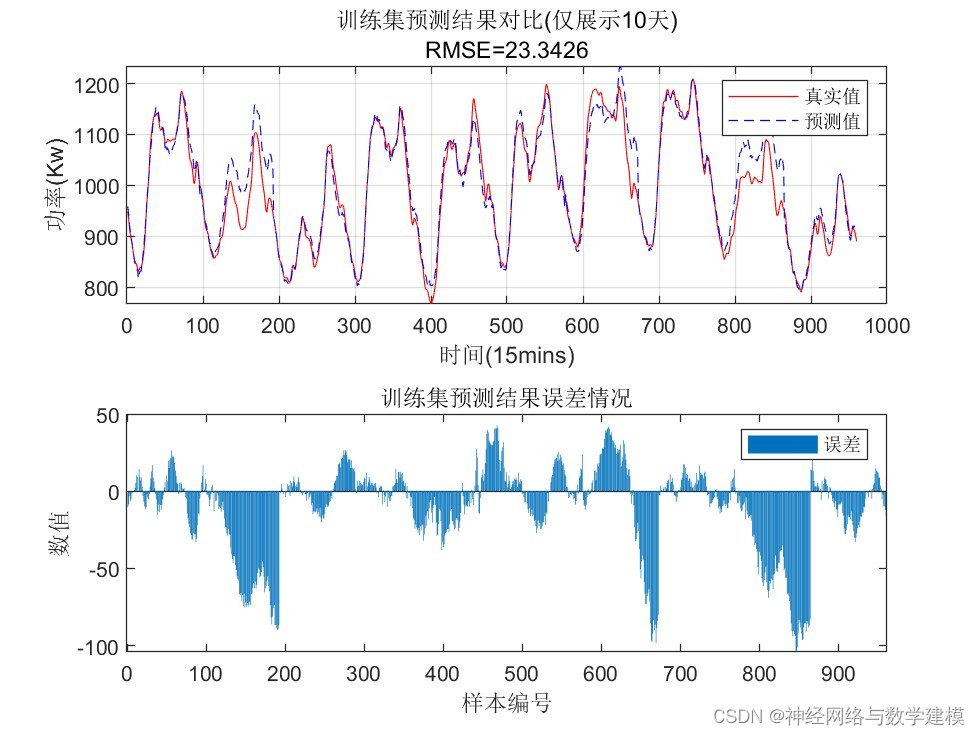
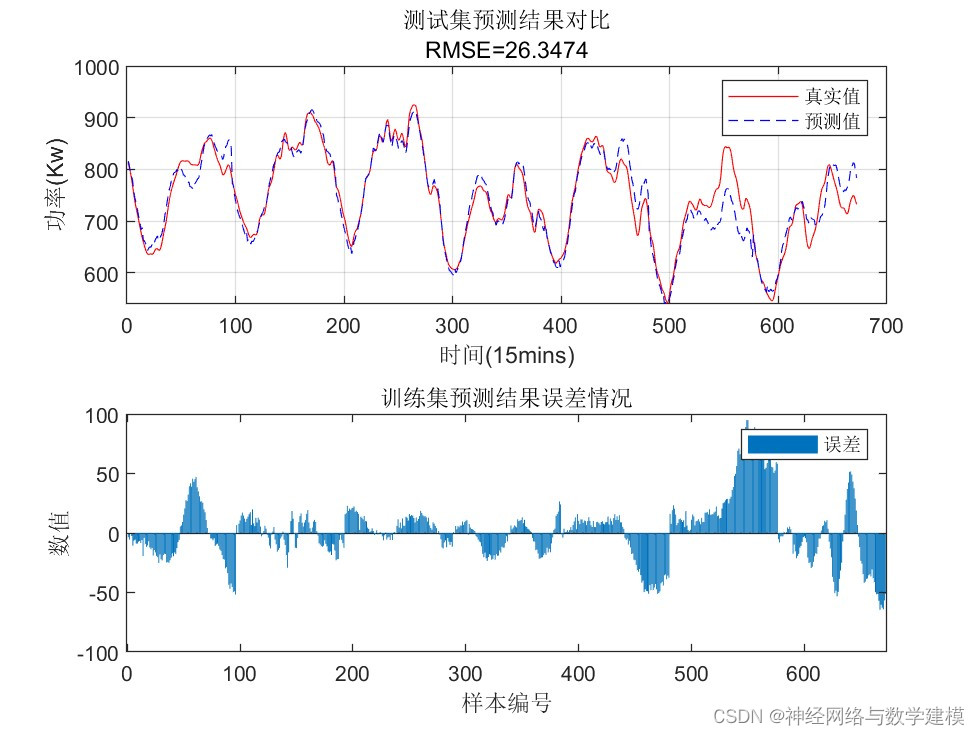
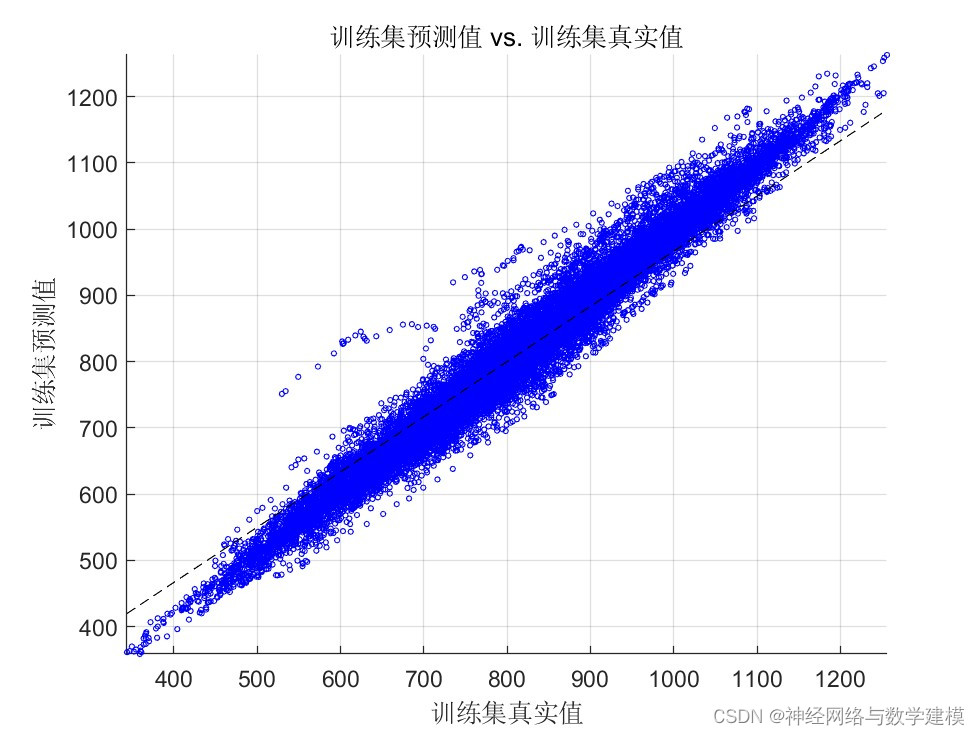
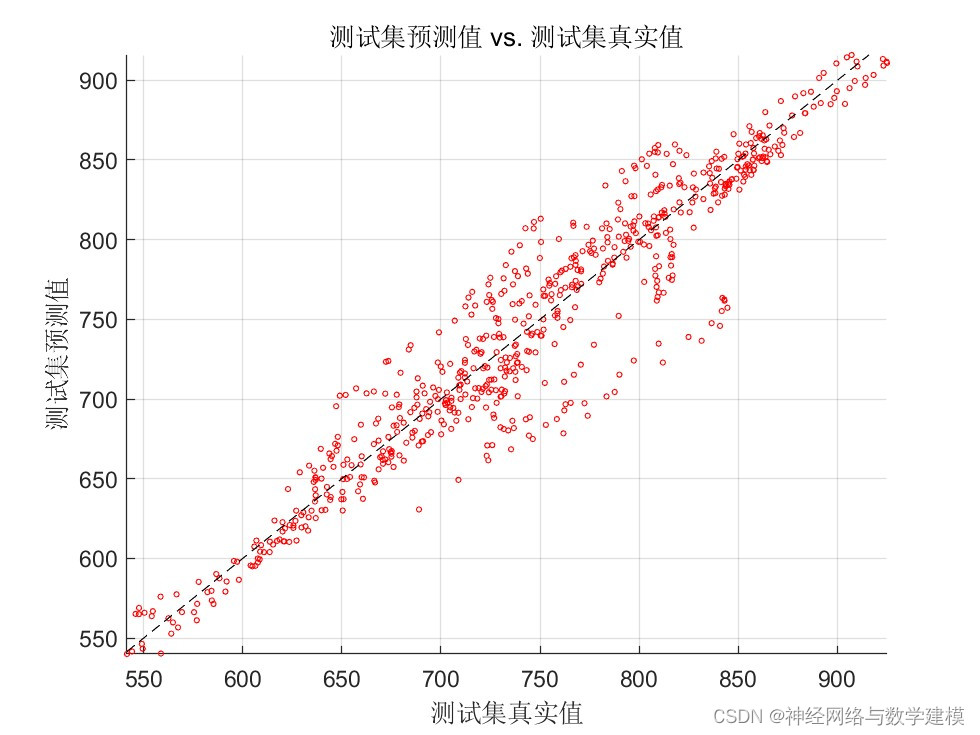
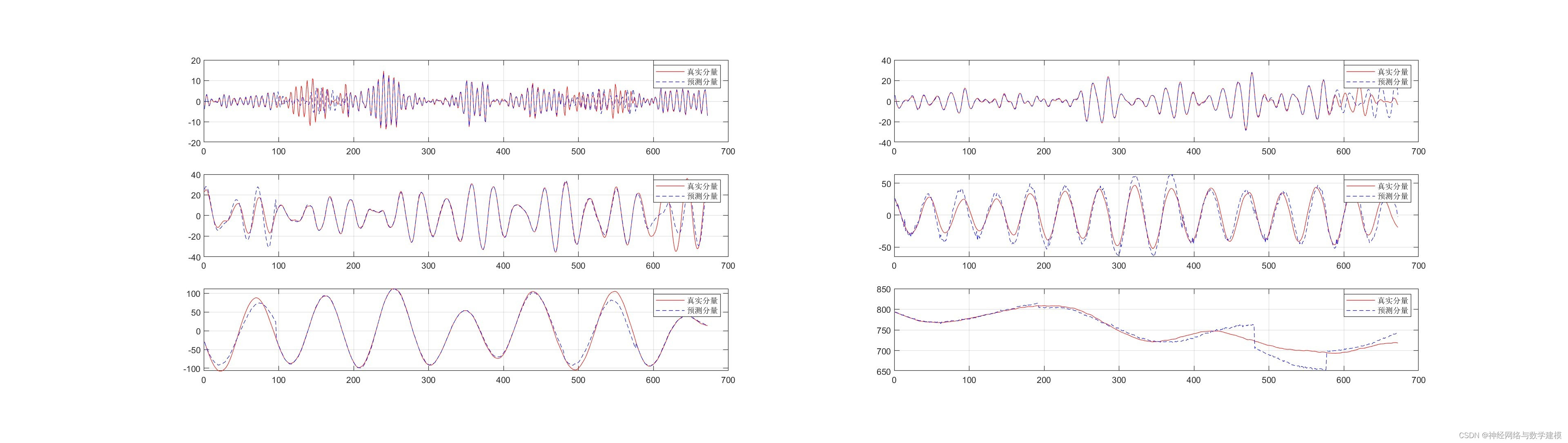
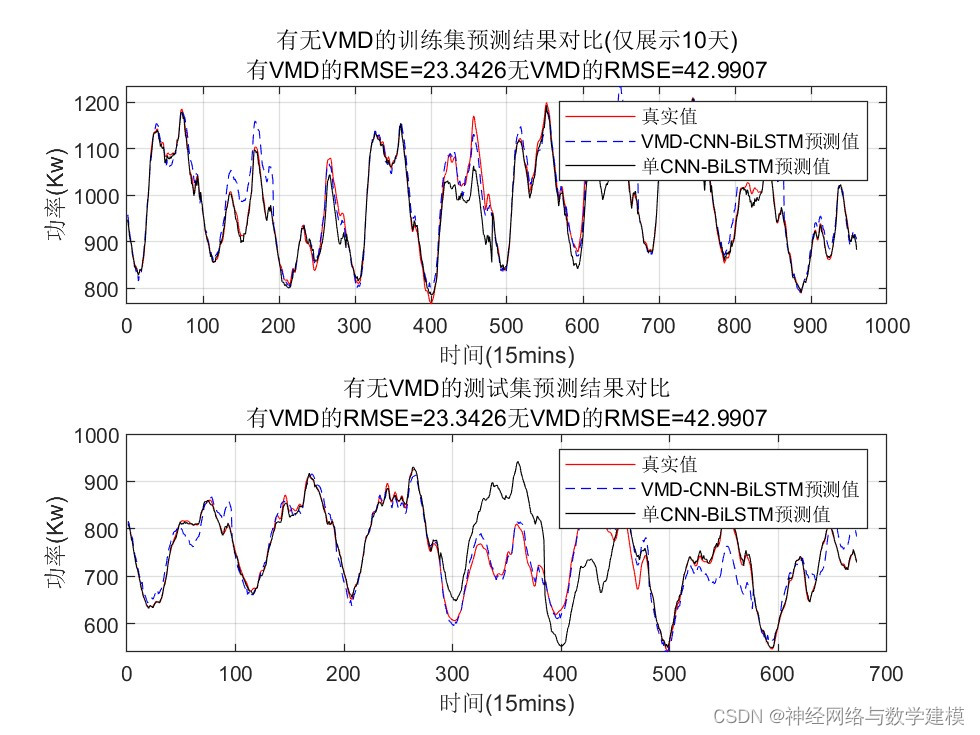
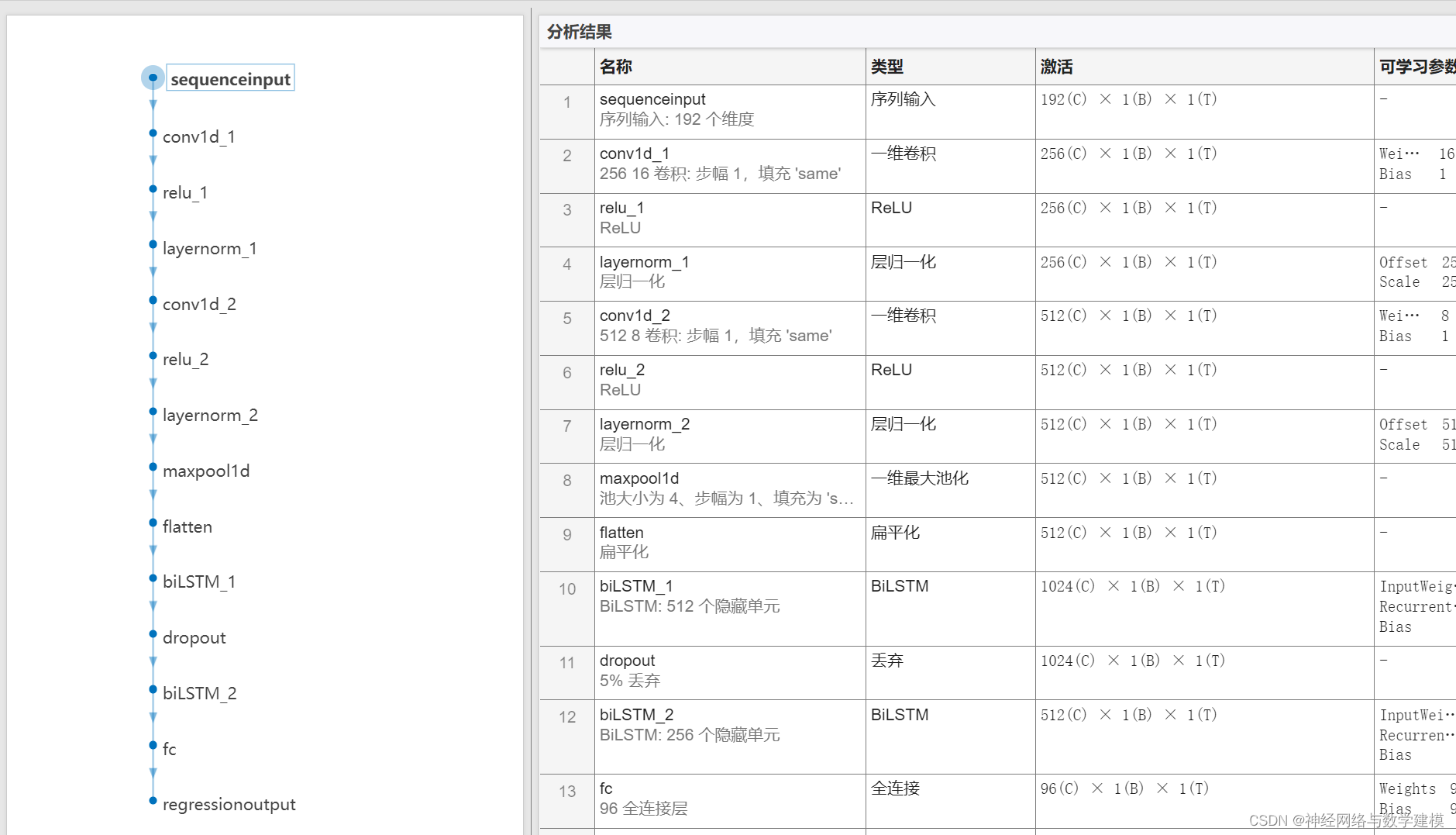
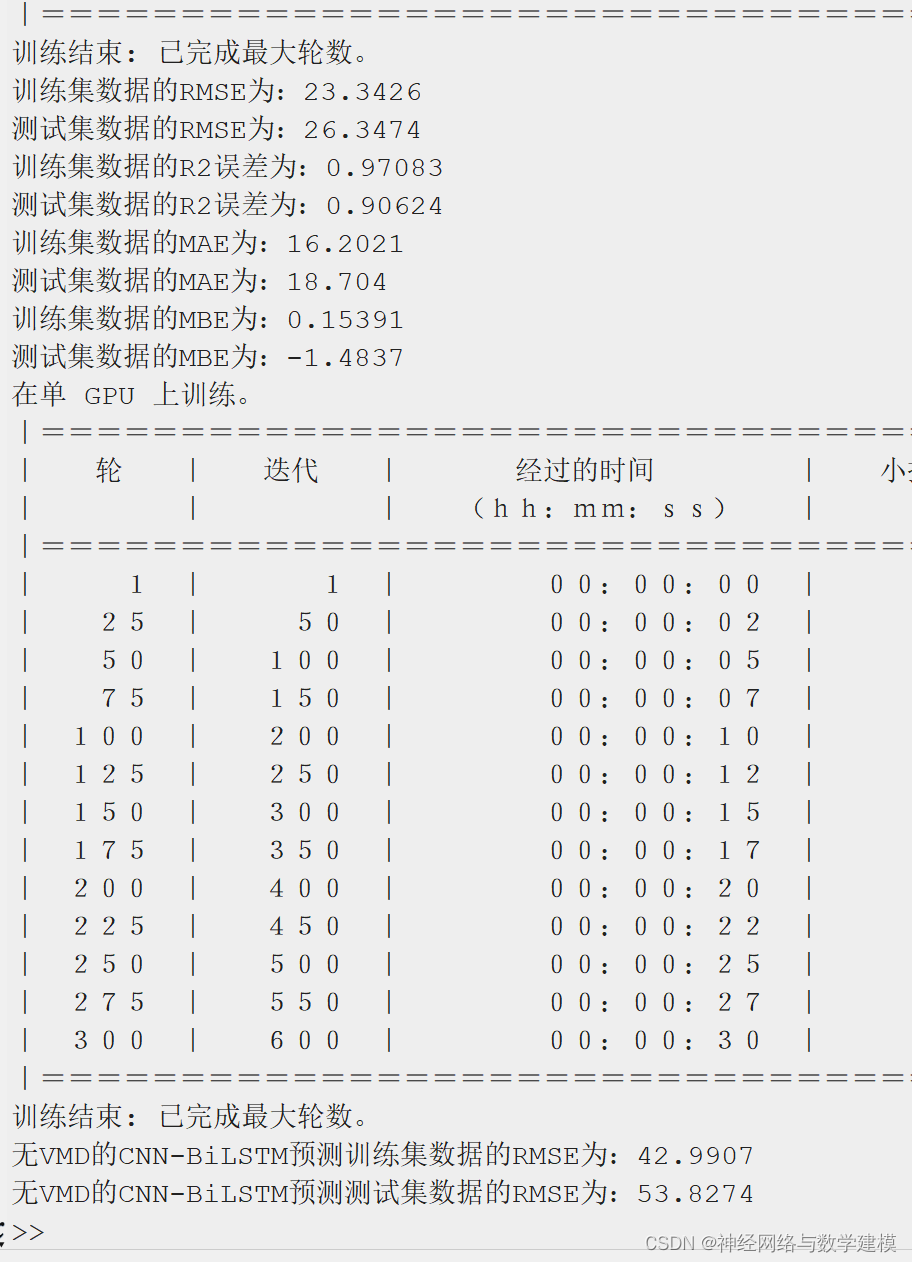
三、VMD-BiLSTM负荷预测理论:
为分离负荷数据中的信号和噪声,提高预测模型的精度,本文首先采用变分模态分解技术 将历史负荷数据分解成若干个本征模态分量,使其频率带宽之和最小化。然后利用深度学习神经网络CNN-BiLSTM分别对分解出的模态分量建模,CNN由于具有强大的特征筛选能力可以提取出信号中的关键特征信息,从而给后续网络提供更加精确的输入变量。BiLSTM神经网络由于具有记忆单元可以提取出更长的时间尺度上数据之间的关联性,在处理时间序列预测问题上能获得更高的精度。步骤如下:
(1)利用 VMD 技术将输入负荷分解成多个不同频率的本征模态分量
(2)对分解出的每个模态的负荷数据进行归一化处理。
(3)针对每个模态分量分别建立 CNN-BiLSTM 模型, 以当前时间之前48小时负荷序列为模型输入,预测未来24小时的负荷值。
(4)结合每个模型的输出,重构预测结果。
四、代码+数据下载:
这篇关于(创新)基于VMD-CNN-BiLSTM的电力负荷预测—代码+数据的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




