本文主要是介绍【Tableau系列第(6)篇】使用Tableau Prep进行数据清理、整合(一),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
使用Tableau Prep的整体过程详见:【Tableau系列第(5)篇】用Tableau Prep整理数据全流程初体验
本篇一步一步跟我一起来熟悉更多的Tableau Prep数据清理、整合的操作。
示例excel数据源链接: https://pan.baidu.com/s/17nx3_LPe30oK1l1JsC6Kdw?pwd=AQWF 提取码: AQWF

合并多个表(比如不同时间段的数据)
新建连接-文本文件(.csv文件),orders_south_2015,2016,2017,2018在同一个文件夹下,所以,点击“表”,可以看到这四个文件,选择合并多个表,点应用;
 添加更多个输入
添加更多个输入
Orders_East.xlsx
Orders_West.csv
Orders_Central.csv

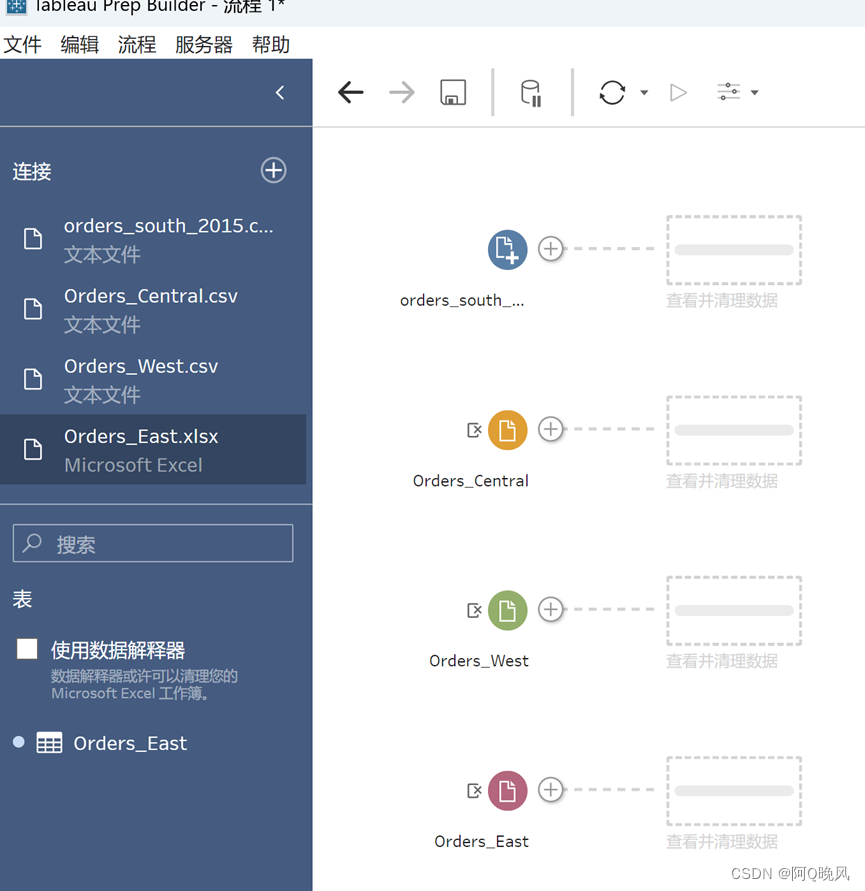
清理订单数据
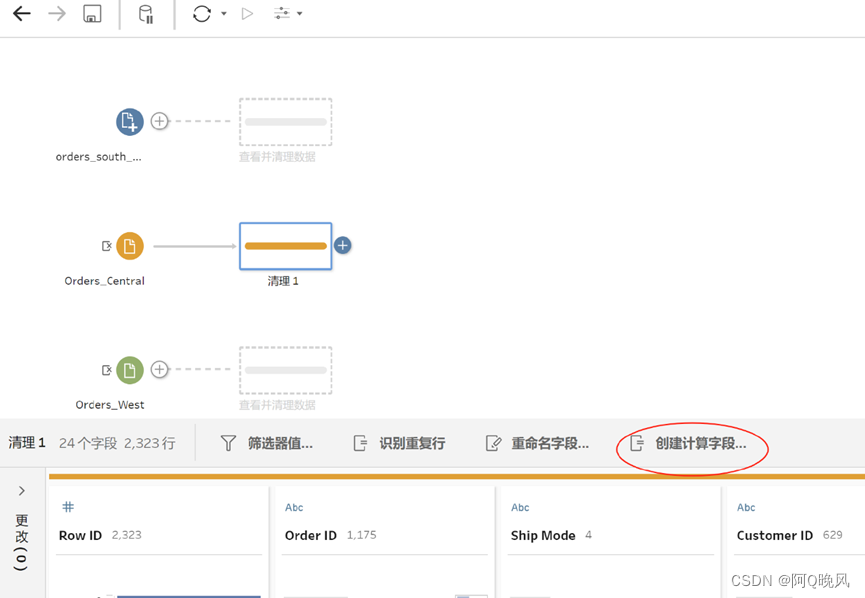
创建计算字段
点击Orders_Central,这个 数据集中没有“Region”字段,而其他数据集中有,所以,要增加这一字段,方面后续分析;
新建标志性字段
字段值输入:Region,字段值:"Central",然后保存;

合并字段
Orders_Central这个数据集中,订单年份、月、日是3个单独的字段,需要把它们合并成一个字段Order Date,格式为"MM/DD/YYYY",赋值:MAKEDATE([Order Year],[Order Month],[Order Day])
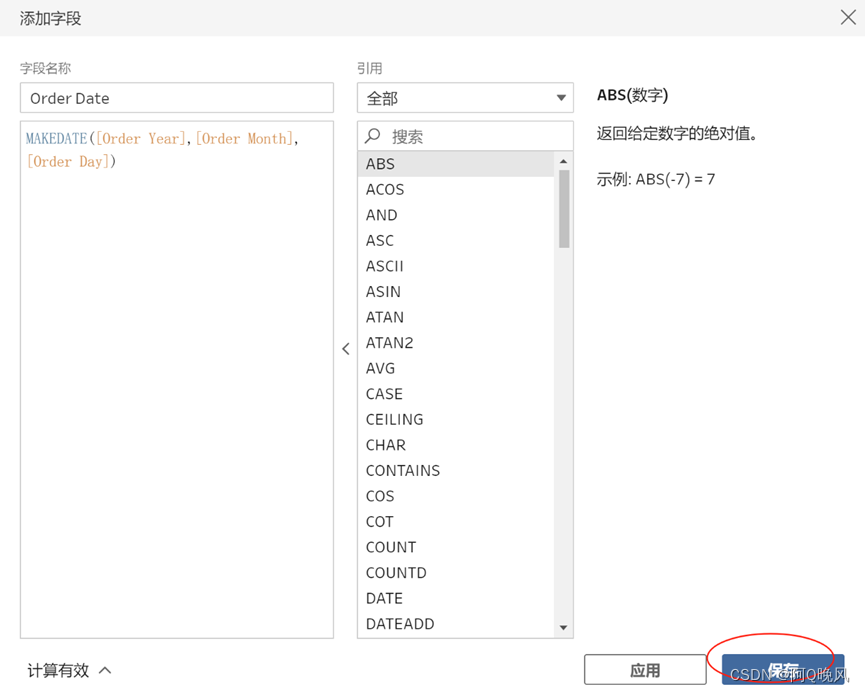
移除字段
需要移除订单年份、月、日是3个单独的字段,在搜索框中输入Order,按住Ctrl多选Order Year,Order Month,Order Day,右键——移除;

类似的,Orders_Central这个数据集中,发货年份、月、日也是3个单独的字段,需要把它们合并成一个字段Ship Date,格式为"MM/DD/YYYY",赋值:MAKEDATE([Ship Year],[Ship Month],[Ship Day])
修改字段类型
Orders_Central这个数据集中,系统给Discounts折扣字段分配的数据类型有问题,它应该是数字类型,但是系统分配的是字符串类型,这是为什么呢,原来,无折扣的情况,字段值是“None”;


直接双击None,把None改为0,按回车键完成;
再去修改Discounts的数据类型,如下图,左键单击“Abc”,选择“数字(小数)”;

在金额字段里移除货币符号
给Orders_East新增一个清理步骤,查看字段,会发现销售额“Sales”字段值中包含了货币符号,Tableau Prep将这个字段解读为了字符串类型;
下面,来快速移除所有字段值中的货币符号,点“…”-清理-移除字母:

然后将Sales的数据类型修改为数字。
添加字段值-映射原始字段值
给Orders_West新增一个清理步骤,查看字段会发现State字段值使用了缩写,如果要和其他文件合并,需要修改为完整的拼写;
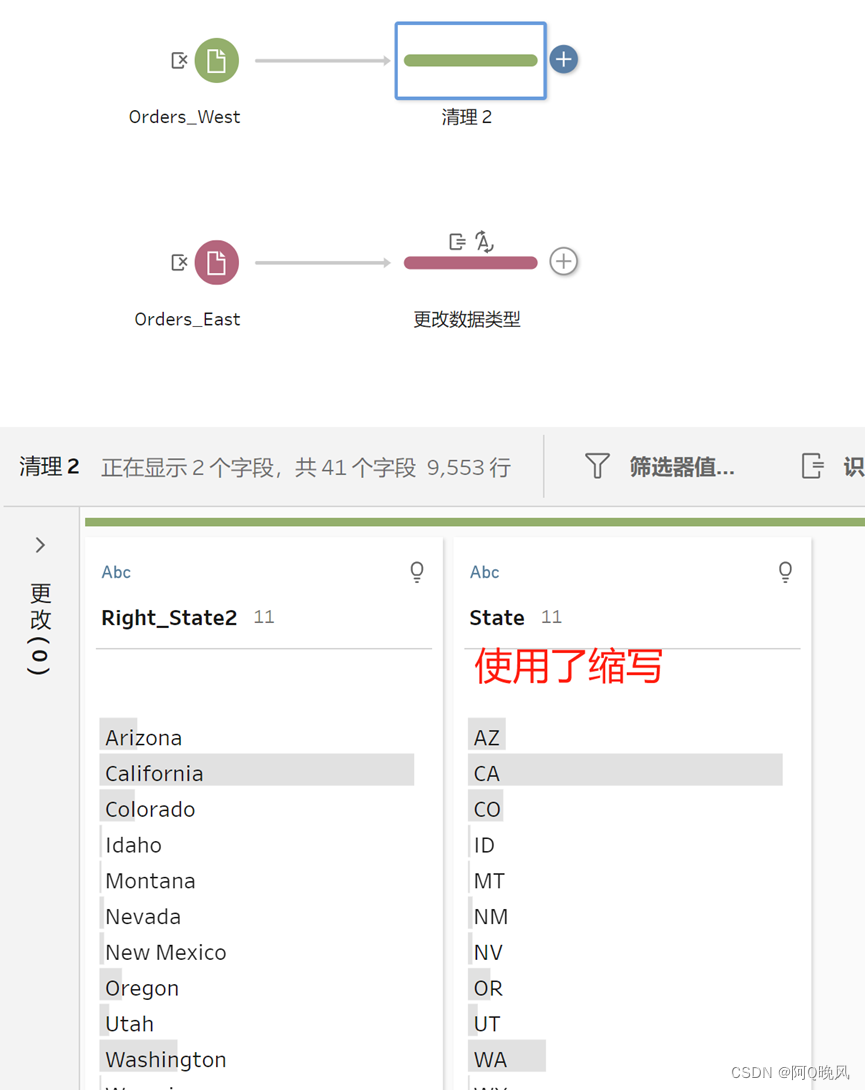
点“…”-将值分组-手动选择;
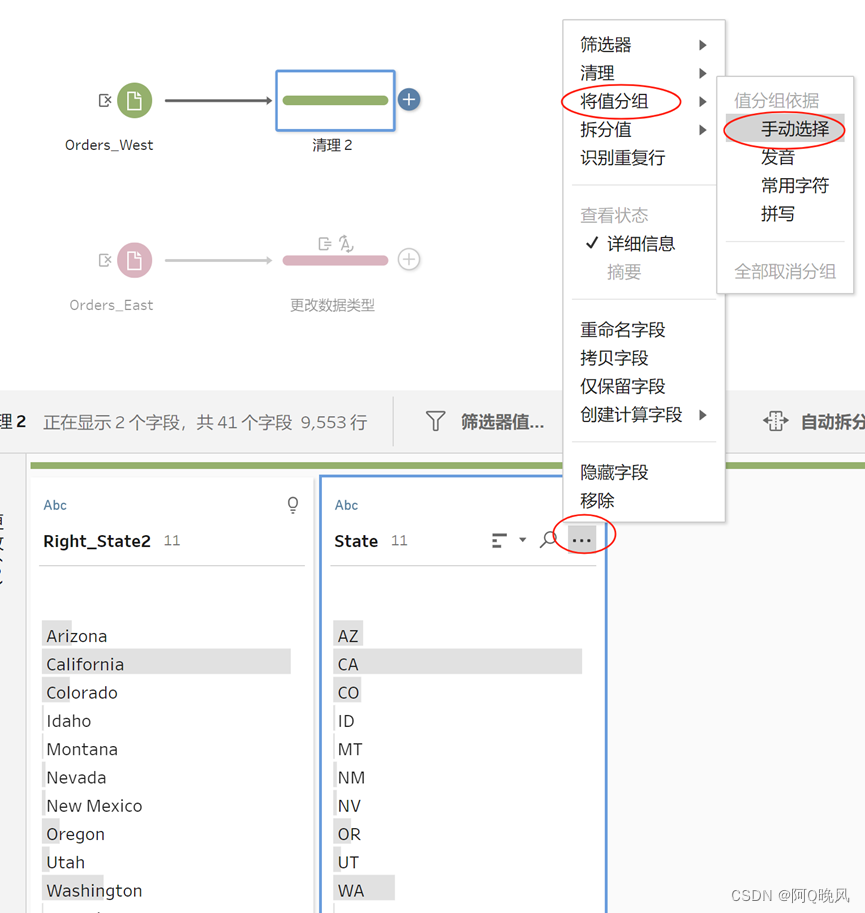
双击AZ,修改为Arizona,这样就把AZ映射到了新值Arizona;

重复这个步骤,完成11个州的修改,然后点击完成;
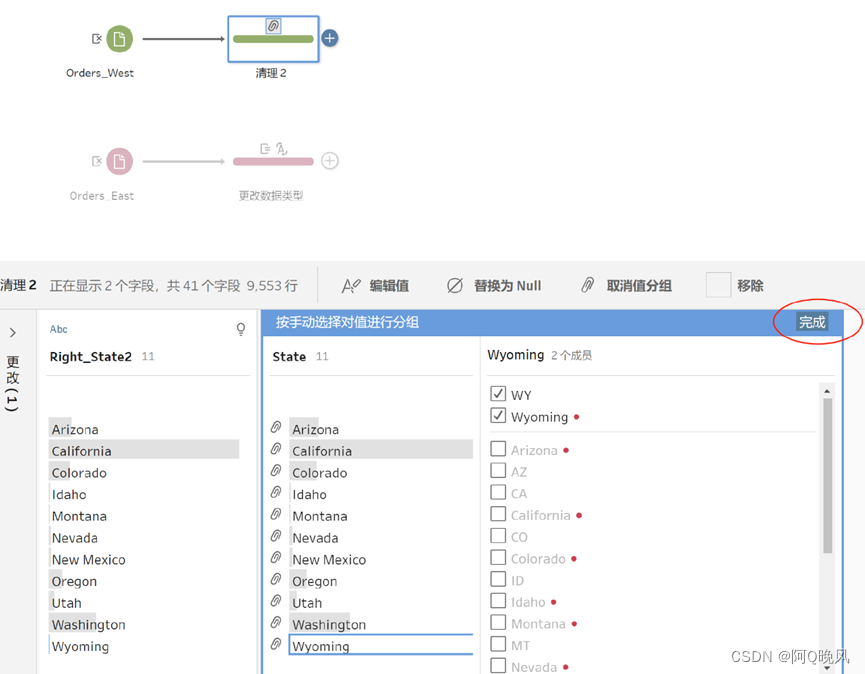
合并数据
将“重命名State值”拖动到“更改数据类型”步骤(放在“并集”上)
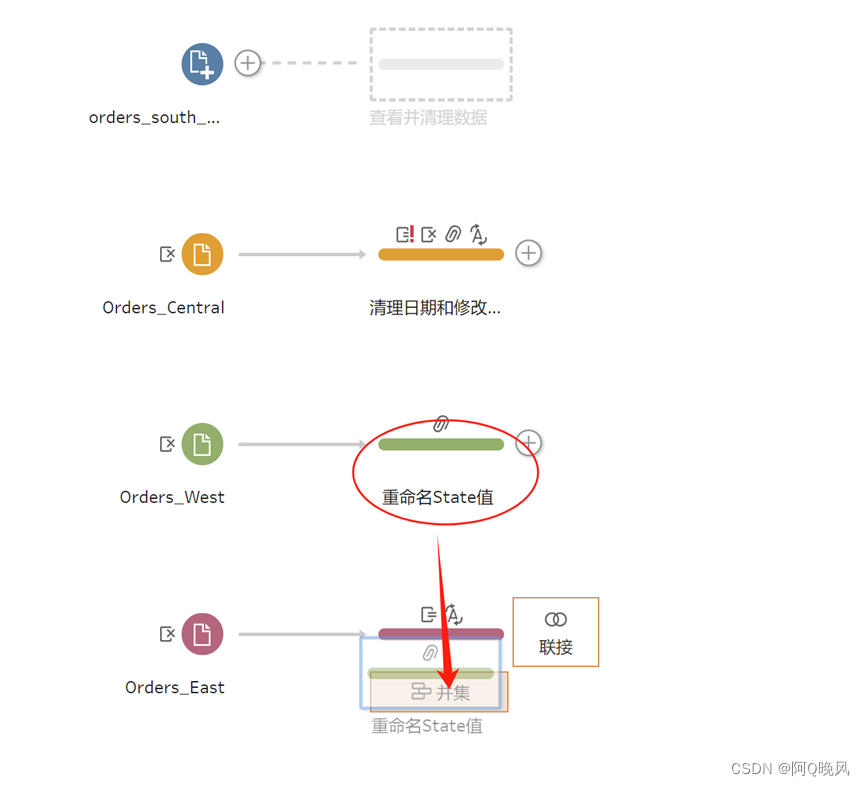

将“清理日期和修改字段”拖到上面创建的并集步骤(放在“添加”上);

同样的,将orders_south输入步骤 拖动到并集步骤(放在“添加”上);

Tableau Prep会自动匹配具有相同名称和类型的字段;

还会发现,新增了一个Table Names(表名称)字段,表示该行数据来自于哪个表;
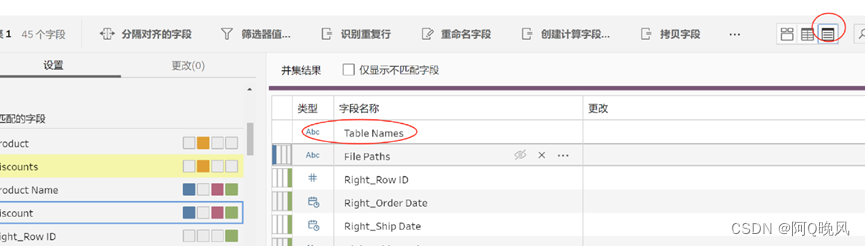
检查不匹配的字段Discount和Discounts,原来是因为字段名不同,那就可以把它们合并;

选择Discount字段,拖动到Discounts字段上进行合并;

类似的,将Product和Product Name合并;
完成了数据合并,将步骤“并集1”重命名为“所有订单”。
拆分字段值
完成了订单清理和合并,接下来处理退货数据,发现数据有一点杂乱;
新建连接,选择“Microsoft Excel”,选择return_reasons_new.xlsx
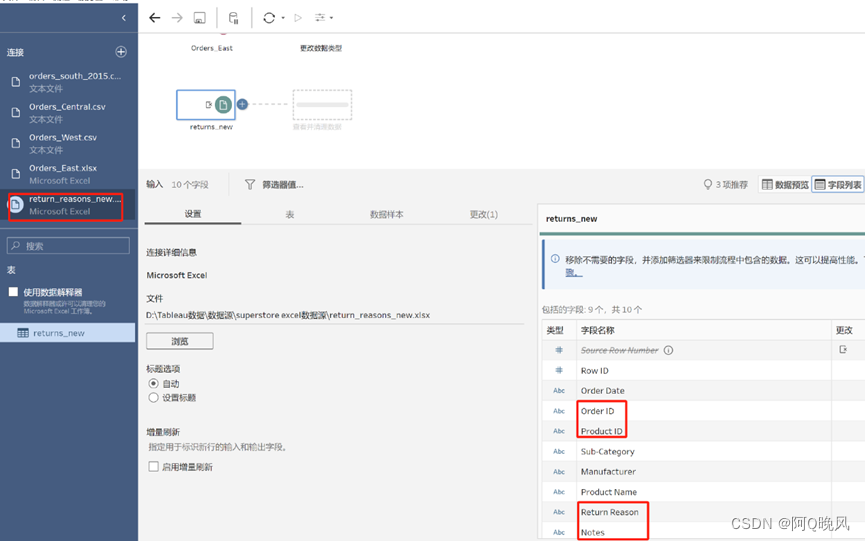
新增一个清理步骤,观察Notes(注释)的取值,发现里面包含了审批者,可以把这个信息单独拎出来,放在另一个字段中更好的利用;

首先移除额外的空格:

然后拆分注释和审批者,由于这个数据有明显的分隔符,所以可以选“自动拆分”,当然也可以手动拆分;
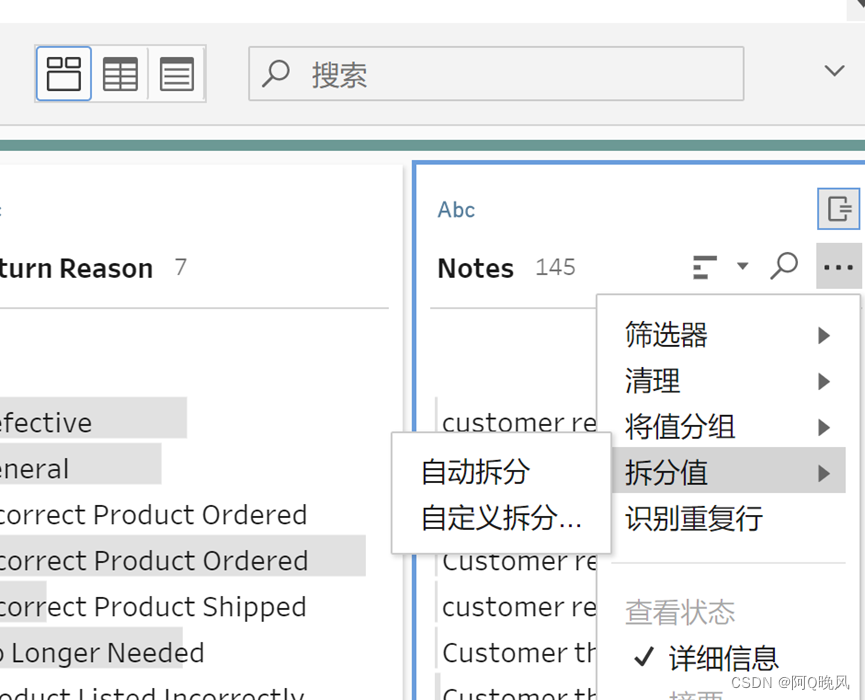
拆分后,双击字段给字段重命名为Return Notes和Approver(审批者)

移除原始的Notes字段:

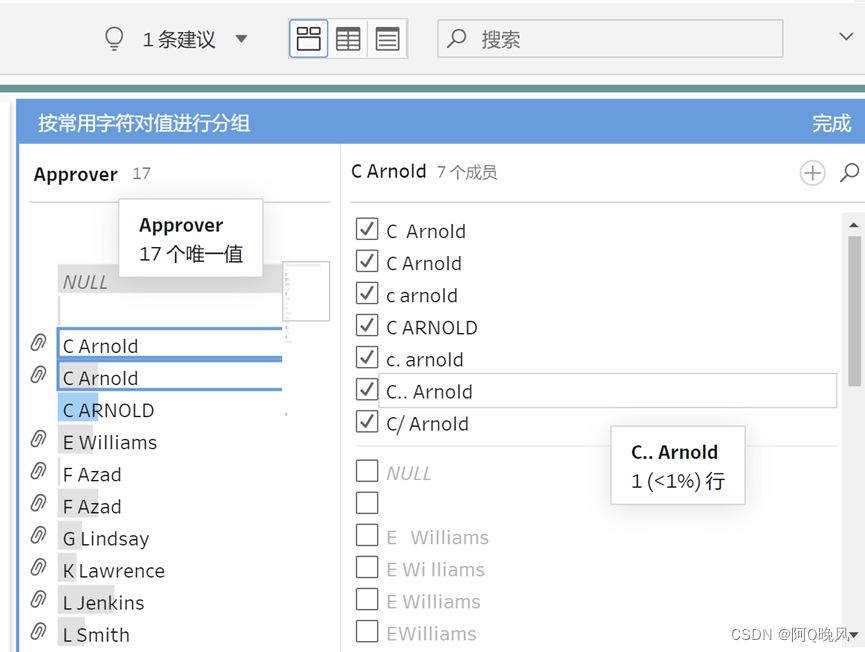
观察到审批人取值里有点问题,相同的人名好像写法不一样:

发现Tableau Prep把相同人名的不同写法分为了一组,很不错,检查一下,完成;
联接数据
将退货数据和订单数据联结起来,想要联结两个表,它们需要有共同的字段,比如Order ID和Product ID,将退货清理步骤拖动到所有订单,放在“联接”上;

添加“联接子句”

“内部联接”,仅包括两个文件中都存在的值,没有匹配退货的订单数据被排除;

需要改为“左”联接,数据要包括“所有订单”合并步骤中所有数据、以及“退货订单(清理注释)”中的匹配数据;

清理联接结果
移除多余字段
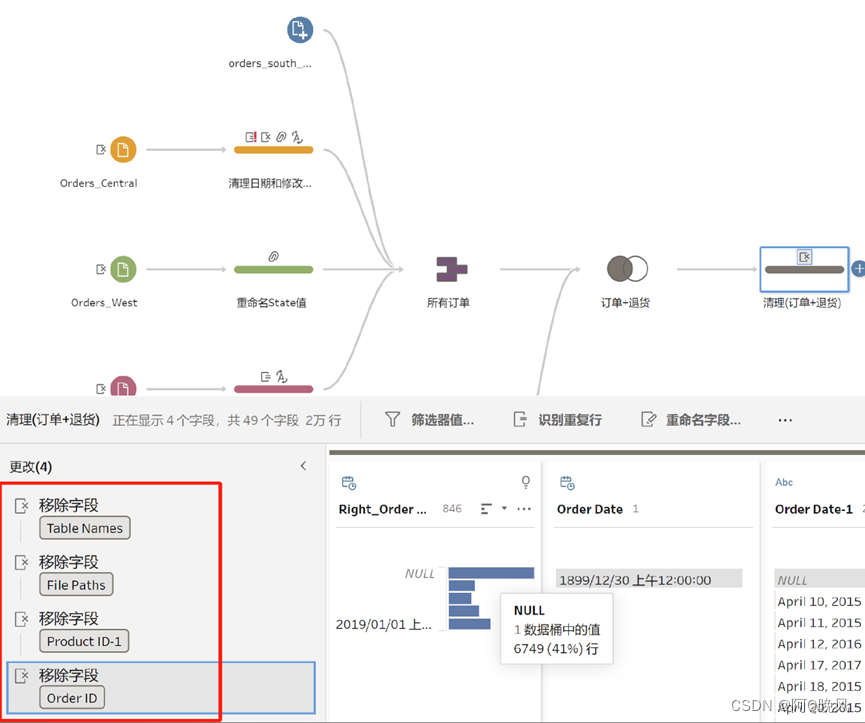
将字段Order ID-1重命名为Order ID;
添加一个值为"Yes"和"No"的字段来表示是否已退货;
创建计算字段 Return?
赋值If ISNULL([Return Reason])=FALSE THEN "Yes" ELSE "No" END

可能为了分析,还想要知道下单到发货间隔天数,
看一下订单日期和发货日期,有点问题:
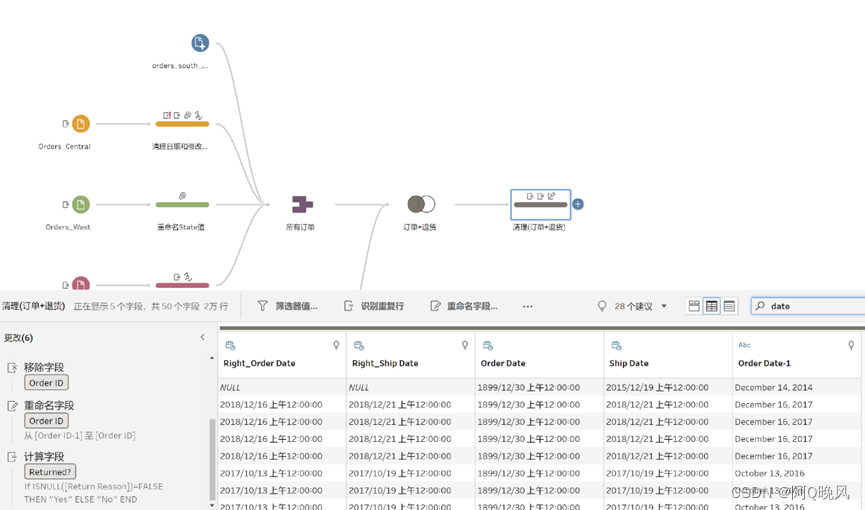
修正一下:

新建字段“Days to Ship”,赋值为:
DATEDIFF('day',[Order Date],[Ship Date]),完成之后:
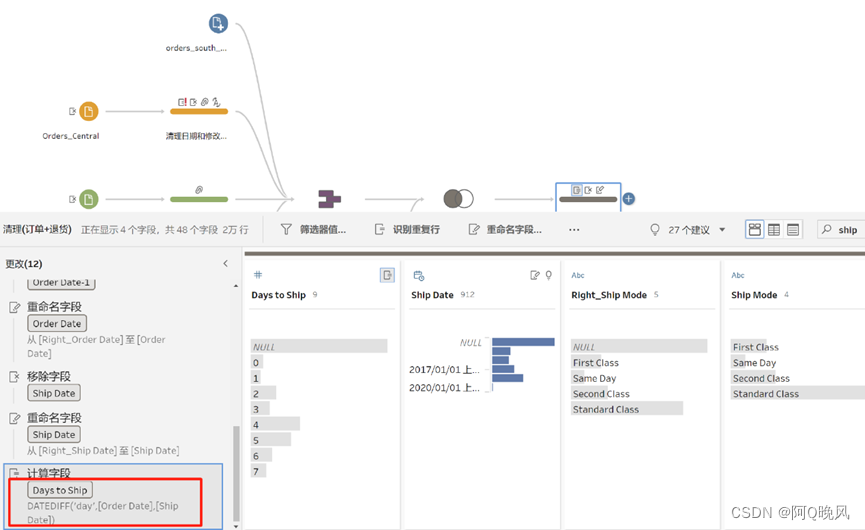
处理完之后,可以输出数据。
基本操作见:【Tableau系列第(5)篇】用Tableau Prep整理数据全流程初体验
最后,给你一个完整的Tableau Prep帮助文档,更多的操作问题可以根据需要从中查找答案;
链接: 百度网盘 请输入提取码 提取码: AQWF
这篇关于【Tableau系列第(6)篇】使用Tableau Prep进行数据清理、整合(一)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






