本文主要是介绍数据链路层【Linux网络复习版】,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
目录
一、数据链路层主要解决的是什么问题?
二、什么是以太网?
三、什么是MAC地址?
四、以太网帧的格式是什么?
五、 什么是MTU?
六、MTU和分片
MTU对IP协议的影响?
如何分片?
如何组装?
如何识别有无丢失?
怎么知道第一个是不是被分片了?
怎么避免分片?MSS
七、局域网内主机如何通信?
交换机
八、ARP协议
ARP协议的工作原理
ARP协议报头
ARP请求发送过程
ARP应答发送过程
ARP欺骗
一、数据链路层主要解决的是什么问题?
直接相连的主机(同一网段的主机-路由器)进行数据交付的过程。
二、什么是以太网?
以太网(Ethernet)是一种局域网技术。既包含数据链路层的内容,也包含了一些物理层的内容。除了以太网以外,还有令牌环网,无线LAN等。
三、什么是MAC地址?
MAC地址用来识别数据链路层中相连的节点,在网卡出厂时就确定了,不能修改,具有全球唯一性(虚拟机中的MAC地址不是真实的MAC地址,可能会有冲突;也有写网卡支持用户配置MAC地址)
MAC地址长度为48位,即6字节,一般用16进制数字加上冒号的形式来表示。
四、以太网帧的格式是什么?
以太网帧首部由 目的mac地址、源mac地址和类型组成。
帧类型:该字段的值通常是一个16位的十六进制数,对应不同的协议使用不同的值。例如:
- 0x0800:表示IP数据报,会把有效载荷交给上层 ------ 网络层
- 0x0806:表示ARP请求/响应,发起ARP请求/应答。

五、 什么是MTU?
以太网中规定数据长度最小为46字节,最大为1500字节,ARP数据包长度如果不够46字节,就要在后面补填充位。
MTU就是以太网的最大传输单元:1500(不包括以太网首部),不同的网络类型有不同的传输单元。
六、MTU和分片
MTU对IP协议的影响?
由于数据链路层MTU的限制,网络层就要对较大数据包进行分片。
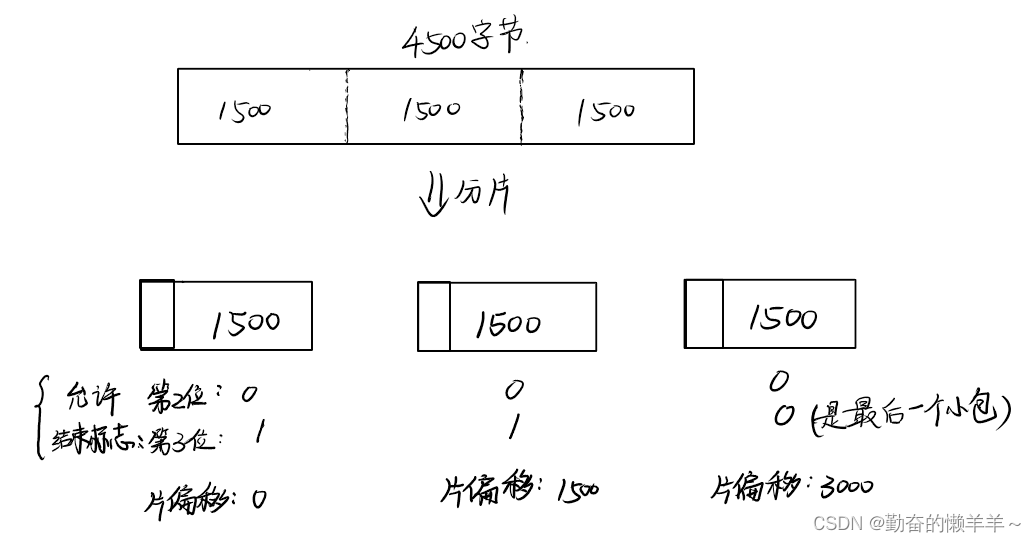
如何分片?
3位标志:第二位表示是否允许分片(0允许);第三位是结束标记(当前是否是最后一个小包,0是/1不是)
13位片偏移:比如4500字节的数据要进行分片,那么第一片的片偏移就是0,第二片的片偏移是1500,第三片的片偏移就是3000。
如何组装?
a.将分片全聚在一起
b.根据片偏移排序
如何识别有无丢失?
根据片偏移计算。
一旦这些小包中任意一个小包丢失,接收段重组就会失败,但IP层不负责重传。
怎么知道第一个是不是被分片了?
片偏移为0且接结束标记为1。
怎么避免分片?MSS
分片会增加丢包概率,因为ip中任何一个分片丢失,都要上层重发。所以尽量不分片。
双方tcp三次握手时,协商好双方mss的较小值,就能避免分片。
以太网的mtu是1500(有效载荷)
则 IP的最大有效长度 = 1500 - IP报头(20Byte)= 1480
则 TCP的最大有效长度 = 1480 - TCP报头(20Byte)= 1460
1460数据就是MSS,通信双方的MSS尽量保持一致,减少分片。
七、局域网内主机如何通信?
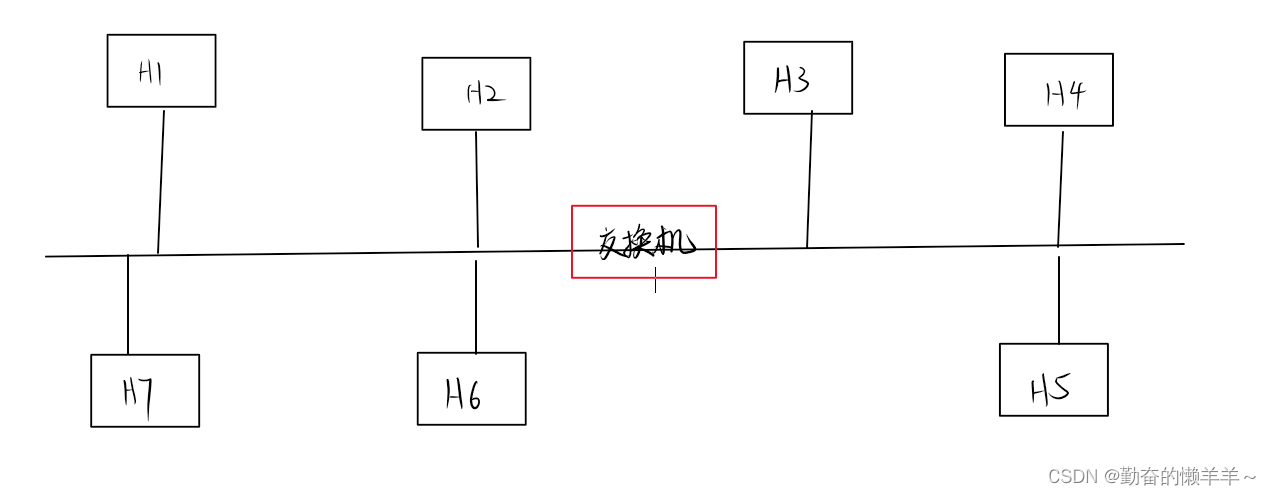
局域网中,是以广播的形式来通信的,就好像在一个班级里,老师说:“xxx过来一下”,此时全班的学生都收到了这条消息,只不过不是告诉自己的,就自动丢弃了。
局域网中任何时刻只允许有一条消息在信道上,否则会产生碰撞(有碰撞检查、碰撞避免算法),那么如果局域网内很多主机,碰撞的概率就会加大,如何缓解?
交换机
划分碰撞域,在概率上减少局域网碰撞。
此时,交换机左侧和右侧主机可以同时进行内部通信(eg:h1发给h2,h3发给h4),此时就能见效冲突概率。
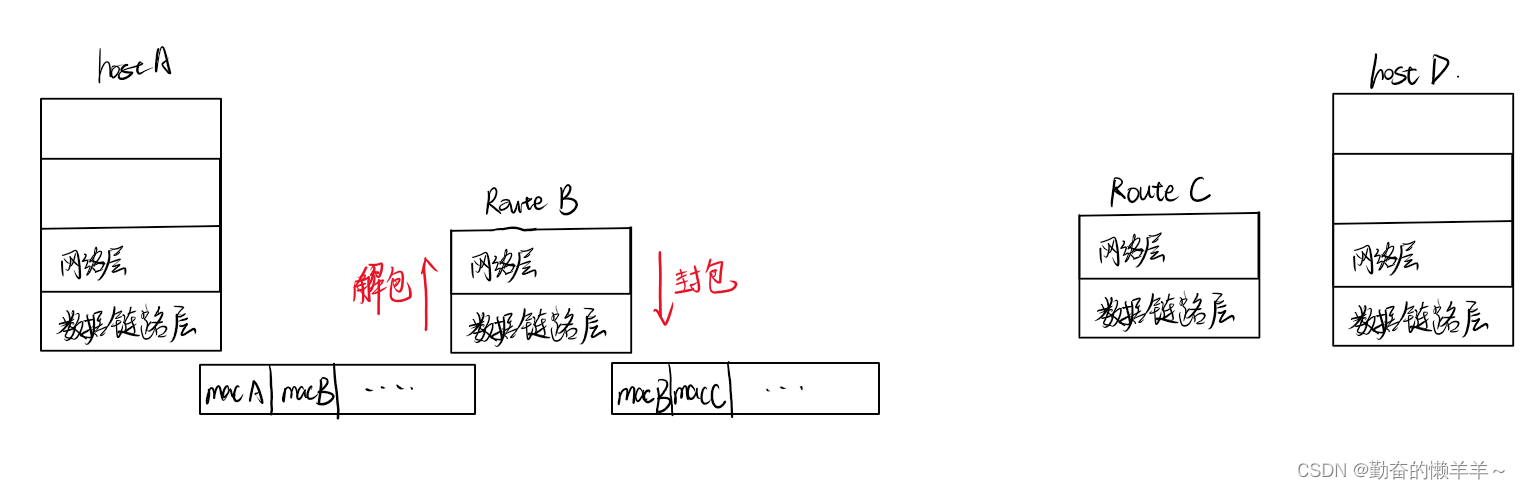
数据包每到达一个路由器都要重新解包和封包,更新下一跳的mac地址,mac帧只在局域网中有效。
八、ARP协议
当主机A想跨网络传输到主机B,当数据包到主机B所在网络的网关路由器时,该路由器只知道源ip和目的ip,它如何在局域网内将该数据包送给主机B呢?这是候就要用到ARP协议,来获得IP对应的mac地址。ARP协议建立的IP和MAC地址的映射关系。
该协议虽然归属数据链路层,但实际是介于数据链路层和网络层之间的协议。
ARP协议的工作原理
在局域网内广播一条消息,问局域网内xxip地址是谁,对应的mac地址是多少。所有主机收到后,根据xxip发现是向我发起的ARP请求,那么就给它响应一条消息,告诉它自己的mac地址是多少。
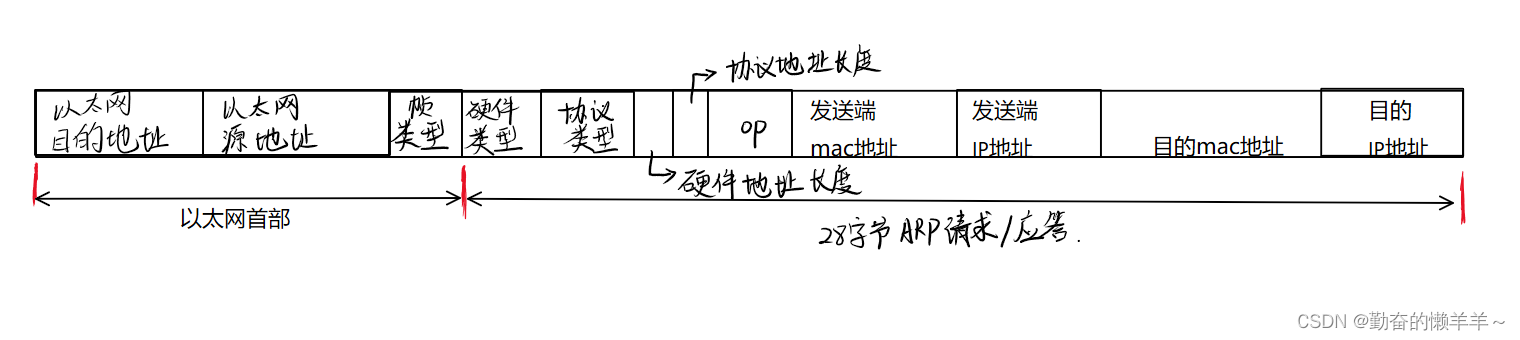
ARP协议报头
硬件类型:数据链路层网络类型,1为以太网。
协议类型:只要转换的地址类型,0x0800为IP;
硬件地址长度:对于以太网为6字节。
协议地址长度:对于IP地址为4字节。
op:1表示ARP请求,2表示ARP应答。
ARP请求发送过程
如果局域网内一台主机想知道局域网内另一台主机的mac地址(已知其ip地址),那么它可以发起一个ARP请求。
填充ARP报头:
op填1(请求)
发送端mac地址和发送端ip地址:自己的mac地址和ip地址。
目的mac地址:未知,填全F
目的ip地址:已知的
mac帧报头:
目的mac地址:全F(表示广播)
源mac地址:自己的mac地址

由于以太网mac地址是全F,广播,所以局域网内每台主机都会收到,到达某台主机的mac帧层时,发现它的目的mac地址是广播地址,就把数据帧向上交付给ARP层。
ARP层:
1)先看op字段。
2)发现op字段是请求,那么继续看目的ip地址,如果与当前主机ip地址相同,则说明是发给本主机的,本主机就会给对方回一个ARP应答。
ARP应答发送过程
目标主机收到应答,mac帧层发现是发给自己的,将数据帧向上交给ARP层。
ARP层:
1)先看op字段,发现op是2(即应答)
2)提取发送端mac地址+发送端ip地址
如果是其他主机收到应答,那么它在数据链路层就发现不是发给自己的,就丢弃了。

ARP欺骗
1)如何获得同一网段下的其他所有主机的mac地址?
用自己的ip地址和子网掩码按位与得到网络号,遍历所有的ip地址,ping一下,就ok了。
2)ARP欺骗
ARP的缓存是有时间限制的,且多次发送收到应答时,往往会以最新的为准。
同一个局域网内的hostM(攻击机)可以伪造应答发疯狂发送给hostA,hostA就会以为ipA的mac地址是macM,那么它就会给hostM发送报文。
hostM可以选择丢弃该报文,也可以替hostA向Route R去请求,Route R应答也会发送给我,此时hostM就成了中间人。

这篇关于数据链路层【Linux网络复习版】的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








