本文主要是介绍MySQL的数据存储一定是基于硬盘吗?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一、典型回答
不是的,MySQL也可以基于内存的,即MySQL的内存表技术。它允许将数据和索引存储在内存中,从而提高了检验速度和修改数据的效率。优点包括具有快速响应的查询性能和节约硬盘存储空间。此外,使用内存表还可以实现更高的复杂性,从而提高了MySQL的整体性能。
二、什么是数据库存储引擎?
数据库引擎是用于存储、处理和保护数据的核心服务。利用数据库引擎可以控制访问权限并快速处理事务,从而满足企业内大多数需要处理数据的应用程序的要求。
使用数据库引擎创建用于联机事务处理或联机分析处理数据的关系型数据库。这包括创建用于存储数据的表和用于查看、管理和保护数据安全的数据库对象(如索引、视图和存储过程)。
查看MySQL当前使用什么存储引擎命令:show engines;
查看MySQL当前默认的存储引擎:show variables like '%storage_engines%';
查看某个表用了什么引擎:show create table 表名;在显示结果里参数engine后面的就是表示该表当前用的存储引擎。
三、MySQL的存储引擎是基于表的还是基于数据库的?
表
四、MySQL中如何中指定引擎
1、创建表时,可以通过ENGINE来指定存储引擎,在create语句最后加上"engine = 存储引擎;"即可。
例:create table table1(id int(11) primary key auto_increment)engine=MyISAM;
2、修改表时,可以使用"alter table 表名 engine=存储引擎;"来指定存储引擎。
例:alter table table1 engine=InnoDB;
五、MySQL支持哪几种执行引擎,有什么区别
MySQL是开源的,我们可以基于其源码编写我们自己的存储引擎,有以下几种存储引擎。
MyISAM、InnoDB、NDB、MEMORY、Archieve、Fedarated、Maria等。
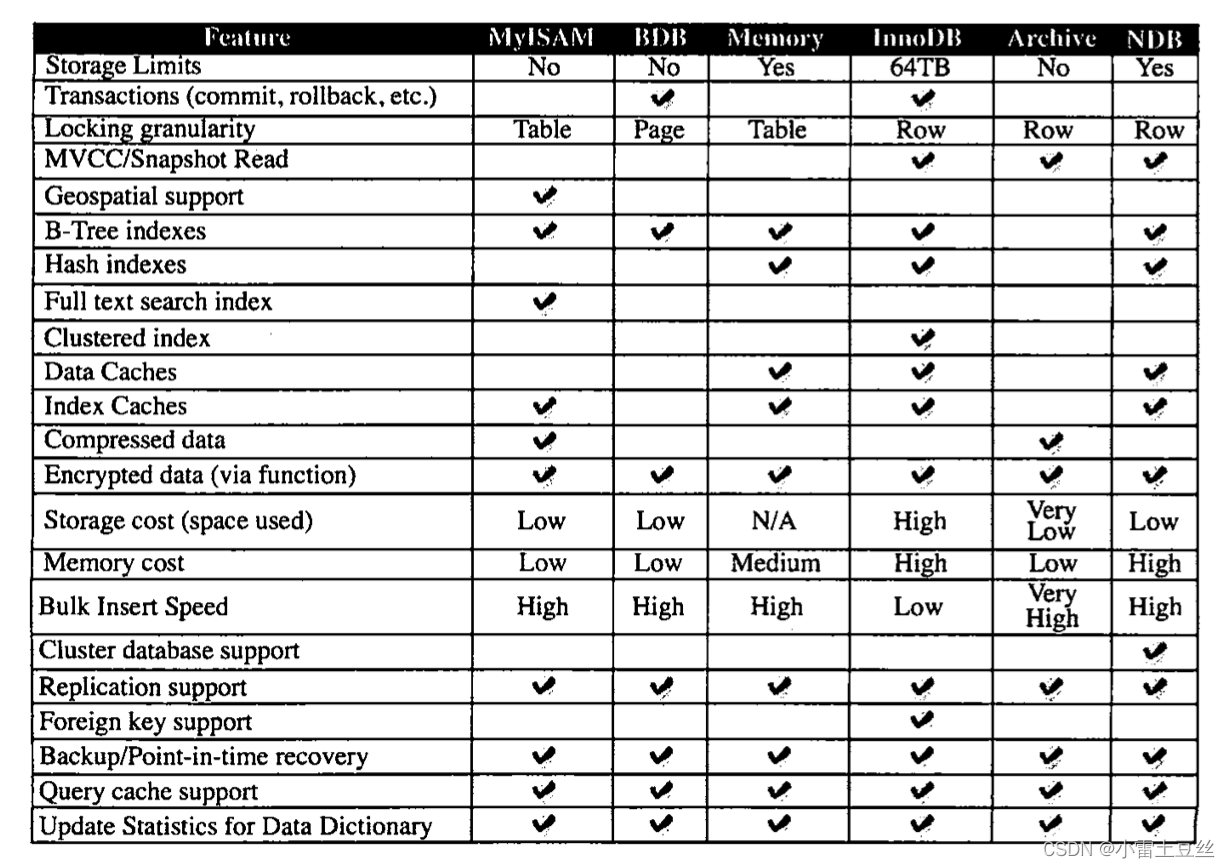
参考:Hollis
这篇关于MySQL的数据存储一定是基于硬盘吗?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







