本文主要是介绍HTTP 抓包工具——Fiddler项目实战,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
网络爬虫实质上是模拟浏览器向 Web 服务器发送请求。对于一些简单的网络请求,我们
可以通过查看 URL 地址来构造请求,但对于一些稍复杂的网络请求,仍然通过观察 URL 地
址将无法构造正确。因此我们需要对这些复杂的网络请求进行捕获分析,这个操作也称为抓
包。常用的抓包工具有 Fiddler 、 Charles 、 Wireshark 等,其中 Fiddler 在 Windows 平台上应用
得较多。
1.Fiddler 的工作原理
Fiddler 是一个 HTTP 调试代理工具,它能够记录浏览器和 Web 服务器之间的所有 HTTP
请求,支持对网络传输过程中发送与接收的数据包进行截获、重发、编辑、转存等操作。与
浏览器自带的开发者工具(如 Chrome 浏览器的 F12 工具)相比, Fiddler 具有以下特点。
- 可以监听 HTTP 和 HTTPS 的流量,捕获浏览器发送的网络请求。
- 可以查看捕获的请求信息。
- 可以伪造浏览器请求发送给服务器,也可以伪造一个服务器的响应发送给浏览器,主
要用于前后端调试。
- 可以测试网站的性能。
- 可以对基于 HTTPS 的网络会话进行解密。
- 支持第三方插件,可以极大地提高工作效率。
Fiddler 以代理服务器的形式工作,它会在浏览器和 Web 服务器之间建立代理服务器。这
个代理服务器默认使用的代理地址为 127.0.0.1 ,端口为 8888 。 Fiddler 启动时会自动设置代理,
退出时会自动注销代理,这样就不会影响其他程序。 Fiddler 的工作原理如图 2-14 所示。
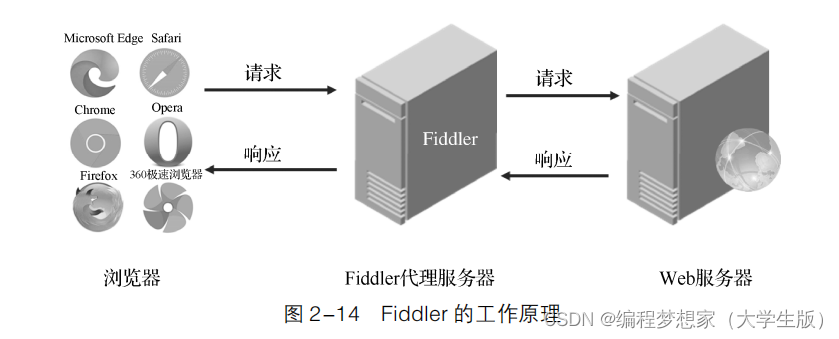
2-14 中的 Fiddler 代理服务器位于浏览器和 Web 服务器之间,它记录了浏览器和 Web服务器之间产生的所有 HTTP 请求和 HTTP 响应。观察图 2-14 中箭头的流向可知,浏览器首 先向 Web 服务器发送 HTTP 请求,这个请求会先经过 Fiddler 代理服务器; Fiddler 代理服务器捕获浏览器发送的请求信息,捕获后可以根据需求对 HTTP 请求做一些处理,处理完以后转 发给 Web 服务器; Web 服务器处理完请求以后返回响应信息,这个响应也会先经过 Fiddler 代理服务器;Fiddler 代理服务器会捕获服务器返回的响应信息,捕获后也可以根据需求对 HTTP 响应做一些处理; Fiddler 代理服务器处理完响应信息后转发给浏览器。
2.有道翻译网站项目实战
我们以有道翻译网站 为例,为大家演示如何使用 Fiddler 工具捕获翻译单词时发送的请求,具体步骤如下。
(1 )在浏览器中打开有道翻译网站。该页面中有两个灰色的区域,左侧区域用于输入要
翻译的文本,右侧区域用于展示翻译后的结果。在左侧区域中输入 python ,单击“翻译”按
钮后,右侧区域展示了 python 的翻译结果,如图 2-39 所示。

( 2 )启动 Fiddler 工具,清空会话窗口中的会话列表。在浏览器中再次单击“翻译”按钮,
切换到 Fiddler 后可以看到捕获的所有网络请求,如图 2-40 所示。
在图 2-40 中,方框标注的请求是单击“翻译”按钮后发送的请求。
( 3 )双击图 2-40 中标注的请求,可以看到 Fiddler 右侧的 Request 窗口和 Response 窗口中
分别显示了该网络请求的请求信息与响应信息,如图 2-41 所示。

 在图 2-41 中,Request 窗口默认展示了 Inspectors 面板,该面板用于查看请求头的相关内
在图 2-41 中,Request 窗口默认展示了 Inspectors 面板,该面板用于查看请求头的相关内
容; Response 窗口中默认展示了 Headers 面板,该面板用于查看响应头的相关内容。由图 2-41
可知,此时捕获请求采用的方法是 POST 。
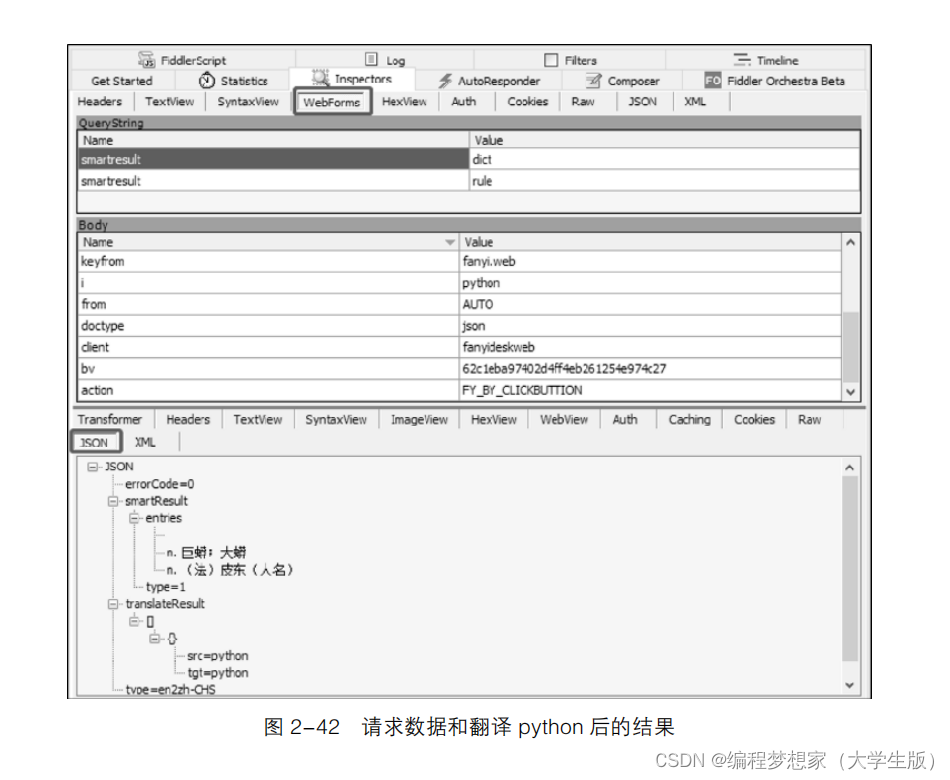
(4 )在图 2-41 的 Request 窗口中单击“ WebForms ”选项卡打开 WebForms 面板,该面板
展示了请求数据的具体内容;在 Response 窗口中单击“ JSON ”选项卡打开 JSON 面板,该面
板展示了翻译 python 后的结果,如图 2-42 所示。
这篇关于HTTP 抓包工具——Fiddler项目实战的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





