本文主要是介绍一文详解扩散模型,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 1、常见的生成模型
- 2、变分推断简介
- 3、文生图的评价指标
- 4、Diffusion Models
- 5、其他
- 技术交流群
- 精选
节前,我们星球组织了一场算法岗技术&面试讨论会,邀请了一些互联网大厂朋友、参加社招和校招面试的同学。
针对算法岗技术趋势、大模型落地项目经验分享、新手如何入门算法岗、该如何准备、面试常考点分享等热门话题进行了深入的讨论。
合集:
《大模型面试宝典》(2024版) 正式发布!
《AIGC 面试宝典》已圈粉无数!
1、常见的生成模型
如图1所示,常见的生成模型有四种:GAN(Generative Adversarial Network)、VAE(Variational Autoencoder)、Flow-Based Models、Diffusion Models。
今天我们讲一讲扩散模型(DM,Diffusion Models)的原理。
DM和VAE一样,都是属于变分推断(VI,Variational Inference)的理论框架。

2、变分推断简介
2.1、统计学简介
在统计学中,一切都是分布(Distribution),到处都是分布。
统计学的根本目的就是获得数据分布。 只要得到了数据的分布,那一切问题都迎刃而解。
但现实数据的分布往往是不可得的,是极其复杂的,所以统计学在应用中到处充满假设:假设样本服从独立同分布原理;假设噪声服从高斯分布;假设特征之间相互独立等。翻开机器学习或者数理统计的书籍,到处充满着假设。没办法,现实问题太复杂!
如何获得复杂的未知分布呢? 最常用的方法就贝叶斯推断。
2.2、贝叶斯推断
贝叶斯推断的目的就是:找出复杂的未知分布。
贝叶斯推断有两类方法:一是MCMC采样;二是变分推断(VI,Variational Inference)。如图2所示。
MCMC属于采样的方法,成本高。变分推断属于数学优化的方法,成本相对较对低。

3、文生图的评价指标
文生图领域有两个评价指标:FID和CLIP。
3.1、FID
FID:Frechet Inception Distance。 用一个训练过的CNN网络提取图片的隐层特征,分别得到两个隐层特征的集合。一个是真实图片的隐层特征集合,一个是生成图片的隐层特征集合。再把这两个集合看作分布,计算两个分布的距离。
FID值越小越好。 如图3所示。

3.2、CLIP
CLIP:Contrastive Language-Image Pretraining。
一个预训练的图文对模型。基于4亿个图文对进行了对比学习。
CLIP得分越大越好。
3.3、优缺点
FID的评价很准确,但需要大量的数据,才能进行评估。
CLIP可以对单张图片进行评价,但只适用于图文对的场景。
4、Diffusion Models
4.1、Diffusion-生成过程
Diffusion生成目标对象的过程,称为生成过程、去噪过程、后向过程等。Diffusion的生成过程从噪声开始。本文都以图片生成为例。
首先, 从标准高斯分布中采样得到一张全是噪声的图片XT。
然后, 从XT 中去掉一点噪声,得到一张噪声更少的图片XT-1。**如此重复T步,**最后直到X1就是一张生成的图片。
意大利著名的雕塑家米开朗基罗说过:“塑像本来就在石头里,我只是把不需要的部分去掉。” Diffusion的生成过程与此类似,图片本来就在噪声里,Diffusion模型只是把不需要的噪声去掉,让图片显露出来!
如图5所示:
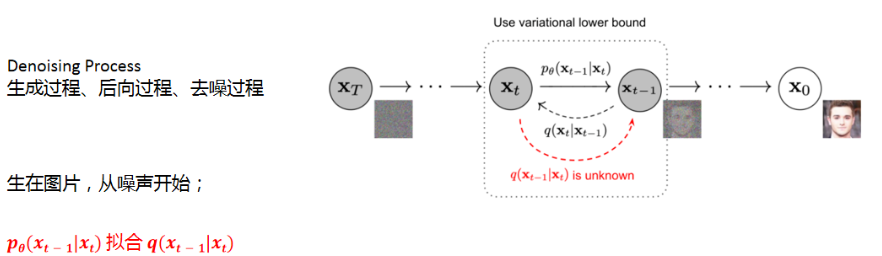
图5 Diffusion 去噪过程
4.2、Diffusion-扩散过程
Diffusion的扩散过程,也称为前向过程、加噪过程。 如图6所示。
扩散过程为模型的训练提供了有标注的样本。前面说过,生成过程是从噪声中逐步去噪声,最后生成图片。那模型怎么知道该去什么样的噪声,去多少噪声呢?这就是扩散过程的作用。扩散过程往已知的图片中逐步加入噪声,直到图片完全变成标准高斯噪声。这个加噪声的过程是人为控制的,所加的噪声也是知道的,所以反过来就用这个噪声作为标准,指导模型去噪,这相当于是一个有监督的学习过程。
总之,扩散过程是一个事先预定义的确定过程,用来给生成过程提供有监督的样本。
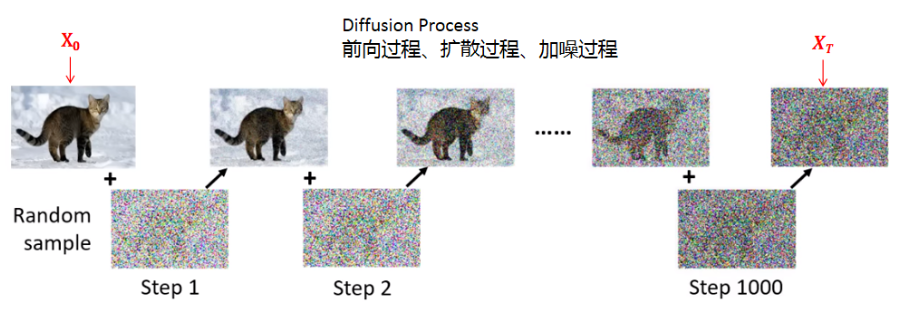
图6 Diffusion Model 加噪过程
4.3、Diffusion-模型训练
模型训练如图7所示。训练的神经网络是一个噪声预测器(Noise Predicter)。
Noise Predicter输入有两个:一是带噪声的图片;二是当前的步数。在Conditional的场景下,还会输入生成条件。
Noise Predicter的输出为:当前图片中所包含的噪声大小。
训练的优化目标为:预测出来的噪声与扩散过程中所加入的真实噪声之间的均方误差MSE(Mean-Square Error)。
4.4、Diffusion-模型推理
模型推理,就是生成数据的过程。确切的生成算法如图8所示。
Algorithm2来源于论文DDPM-《Denoising Diffusion Probabilistic Models》。
DDPM的主要问题是效率低下,因为必须要经过T步,才能生成最终图片。
从图中可以看出,Noise Predicter预测出图片的噪声后,用Xt减去噪声,就得到了去噪后的图片。
但去噪声后,又给图片加上了一点高斯噪声。这是为什么呢?通常认为这是算法落地中的一个Trick。在机器学习中,这种Trick很常见,如dropout。这样通常能增加模型的泛化性。另一种解释是,Diffusion整体上是一个自回归Autoregressive过程,与GPT类似。在AR模型中,每一步都喜欢加一点随机性,如GPT中常用的BeamSearch。
4.5、三种解释
Diffusion Models是一个马尔可夫层次化变分自编码器(Markovian Hierarchical Variational Autoencoder)。

优化EBLO等价于优化以下任意一种目标函数:
1. 优化对原始数据x0的预测结果;—在Discrete Diffusion Models会用到;
2 优化对原始噪声的预测结果;—连续Diffusion Models中最常用;
3. 优化对分数函数的预测结果;—基于热力学能量函数的推导时用到。
4.7、Diffusion-Conditional
前面讨论的是论文DDPM中原生的Diffusion Models。但实践使用时,我们是要根据条件来生成目标数据。如文生图,需要根据给定的文本来生成目标图片。
从原理上来看,根据给定的条件生成数据,和原生的DDPM是完全一样的。只是拟合目标由后验概率分布转化为条件后验概率分布。这两者的理论推导是完全相同的。
在实现上,Noise Predicter的输入中增加了一个条件项,如输入的文本。当然这个条件项往往是其它模态的,需要进行Embedding才能输入到Noise Predicter的神经网络里面。
5、其他
5.1
DDPM的改进
DDPM最大的问题就是它的生成过程速度慢,效率低。需要一步一步地进行Denoising。为此,论文DDIM(Denosing Diffusion Implicit Models)对它进行了改进。
DDPM通常需要1000步来生成一张图片,但DDIM通过只需要5-20步即可。当然DDIM的图片质量略差于DDPM。
5.2
离散场景
图片是一种典型的连续场景,因为每个像素的取值在给定的范围(如0-1)之间可以随便选取。但还有很多离散的场景,如Text、Graph等。在离散场景中如何使用Diffusion Models呢?这还是一个新兴的研究方向,常用的做法是改变噪声的形式。
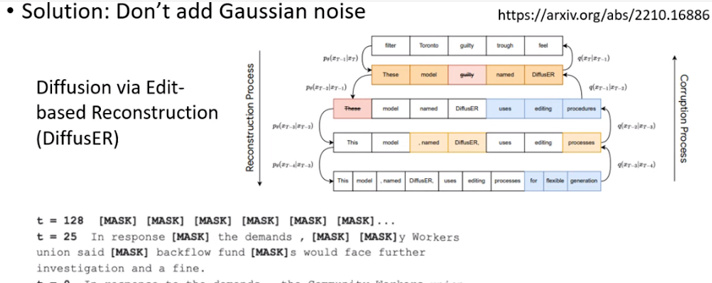
图12 Diffusion + Text
5.3
Stable Diffusion
Stable Diffusion是对原生Diffusion的一种改动。Stable Diffusion原来叫 Latent Diffusion Models。它与Diffusion的最大区别是噪声加在隐状态空间。
Diffusion的噪声与图片是相同尺寸的,它的加噪声和去噪声直接发生在原始数据上。Stable Diffusion会使用一个编码器,先把图片映射到一个低维的隐状态空间中,再在这个隐空间中对图片的Embedding进行加噪声和去噪声。因为隐状态空间的维度低,所以Stable Diffusion的速度比原生的Diffusion更快。但二者的理论基础是相同的!
技术交流群
前沿技术资讯、算法交流、求职内推、算法竞赛、面试交流(校招、社招、实习)等、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企开发者互动交流~
我们建了算法岗技术与面试交流群, 想要大模型技术交流、了解最新面试动态的、需要源码&资料、提升技术的同学,可以直接加微信号:mlc2040。加的时候备注一下:研究方向 +学校/公司+CSDN,即可。然后就可以拉你进群了。
想加入星球也可以如下方式:
方式①、微信搜索公众号:机器学习社区,后台回复:交流
方式②、添加微信号:mlc2040,备注:交流
精选
- 轻松构建聊天机器人,大模型 RAG 有了更强大的AI检索器
- 一文搞懂大模型训练加速框架 DeepSpeed 的使用方法!
- 保姆级学习指南:《Pytorch 实战宝典》来了
- MoE 大模型的前世今生
- 从零解读 SAM(Segment Anything Model)
- AI 绘画爆火背后:扩散模型原理及实现
- 从零开始构建和训练生成对抗网络(GAN)模型
- CLIP/LLaVA/LLaVA1.5/VILA 模型全面梳理!
- 从零开始创建一个小规模的稳定扩散模型!
- Stable Diffusion 模型:LDM、SD 1.0, 1.5, 2.0、SDXL、SDXL-Turbo 等
- 文生图模型:AE、VAE、VQ-VAE、VQ-GAN、DALL-E 等 8 模型
- 一文搞懂 BERT(基于Transformer的双向编码器)
- 一文搞懂 GPT(Generative Pre-trained Transformer)
- 一文搞懂 ViT(Vision Transformer)
- 一文搞懂 Transformer
- 一文搞懂 Attention(注意力)机制
- 一文搞懂 Self-Attention 和 Multi-Head Attention
- 一文搞懂 Embedding(嵌入)
- 一文搞懂 Encoder-Decoder(编码器-解码器)
Reference
1. What are Diffusion Models:https://lilianweng.github.io/posts/2021-07-11-diffusion-models/
2. DDPM:Denoising Diffusion Probabilistic Models:https://arxiv.org/abs/2006.11239
3. Understanding Diffusion Models – A Unified Perspective:https://arxiv.org/pdf/2208.11970.pdf
4. Hungyi Lee 《Diffusion Models》
5. 一文读懂DDIM凭什么可以加速DDPM的采样效率:https://zhuanlan.zhihu.com/p/627616358
这篇关于一文详解扩散模型的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






