本文主要是介绍ByteTrack跟踪理解,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
1.ByteTrack 核心思路
(1)区分高置信度检测框与低置信度检测框,不同置信度检测框采取不同处理方式。
(2)保留低置信度检测框,在后续可能会重新确认为 confirm 状态。而不是像传统 MOT 算法选择删除。
2.bytetrack跟踪流程
(1)把检测的bbox按照置信度阈值分成高低分两组D_high,D_low。
a.其中高分阈值th_h,thd_l,在工程中设置为0.6和0.1
b. th_h<bbox_score的为高分组, th_l<bbox_score<th_h为低分组。
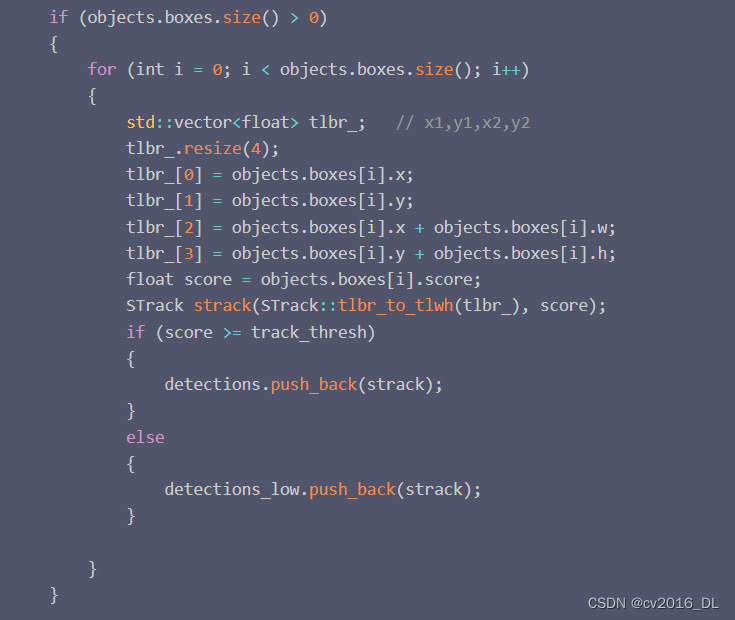
(2)使用高分组的bbox和轨迹track进行匹(第一次匹配),保留未匹配上的bbox D_remain和未匹配上的高分轨迹T_remain。
a.匹配仅仅使用IOU作为相似性计算。(在人群密集和遮挡严重的场景appearance model并明显,作者没有使用Re-ID)
b.IOU匹配的阈值是0.2
(3)使用低分组bbox和T_remain继续进行匹配,继续保留未匹配上的轨迹T_remain。
a.此时可以过滤掉误检测的背景,因为其没有对应tracklet。同时可以恢复被遮挡的目标。
(4)对于未匹的轨迹保留一定生命周期(30帧),期间如果没有匹配到bbox,则删除。
(5)对于未匹配到轨迹的高分bbox(大于阈值th_theta=0.7)的,继续观察帧,如果能连续检测到,分配tracklet。
(6)轨迹插补
a.对于遮挡严重的目标,真值中会消失,这里采用线性插值的方法的补齐这个bbox。用于插值的前后帧间隔不能间隔太大,因为人的运动不一定是线性,短时间内可以近似为线性的。通过这种方法,对跟踪器性能也是有提升的。
3.bytetrack代码理解
(1)新的航迹
只有是高(大于 high_thrash) 置信度框才可以新起航迹。区分高低置信度检测框阈值是 track_thresh = 0.5。但一般high_thresh设定的值要比 track_thresh 大。如high_thresh = 0.6。新起的航迹中 state = Tracked,只第一帧新起航迹 is_activated =True,否则is_activated = false。
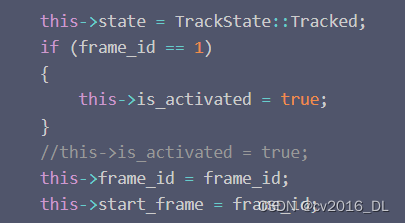
总结:当第一帧时,航迹本身为空时,只有置信度超过 high_thresh 时,才新起始航迹, 此时state = Tracked,is_activated = true。后续只有未匹配的且置信度很高(超过high_thresh )时才新起始航迹,此时state = Tracked,is_activated = false。
(2)预测
合并is_activated = true 与 state = Lost 航迹。合并后进行预测,预测遵循kalman滤波预测。
每个新的检测信息都会初始化一个 STrack 对象,此对象是否能新起航迹前文已经明确了。

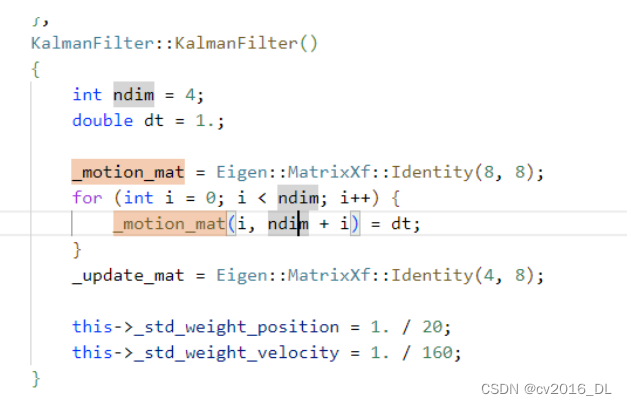
此时 _motion_mat 为一个 8*8 的矩阵。对应运动状态方程为匀速。
box 状态 mean为:(xCenter,yCenter,w/h,h,Vx,Vy,Vr,Vh)。 预测predict 获得新状态 new_mean = _motion_mat * mean.T
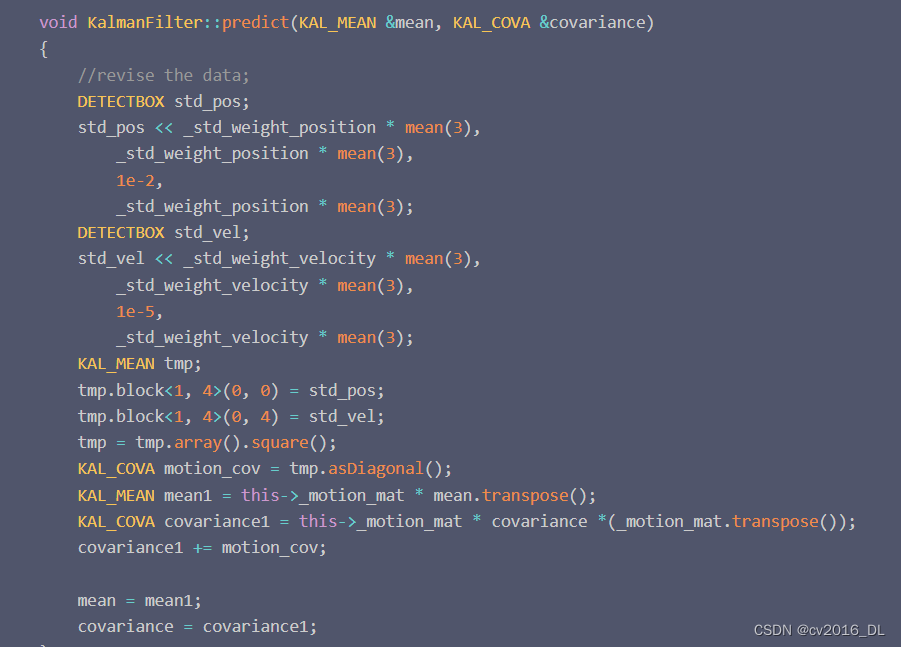
更新协方差 covariance = _motion_mat * convariance *_motion_mat.T + motion_cov 。 montion_cov为过程噪声矩阵。一般可以保持不变,初始化时可以设定,源码中设定为与 w/h 相关的对角矩阵。
(3)匹配
i.第一次匹配 预测框与高置信度检测框
(2)中的跟踪预测框。他们state为Tracked或Lost
高置信度检测框:置信度大于track_thresh中的检测框,文中track_thresh 设定为0.5。
文中采取了计算 iou 进行匹配,预测框与检测框的交并比。 当预测框匹配上时,此时state = Tracked,is_activated = true。 匹配上后需要更新框的状态mean与协方差covariance。
kalman中update:
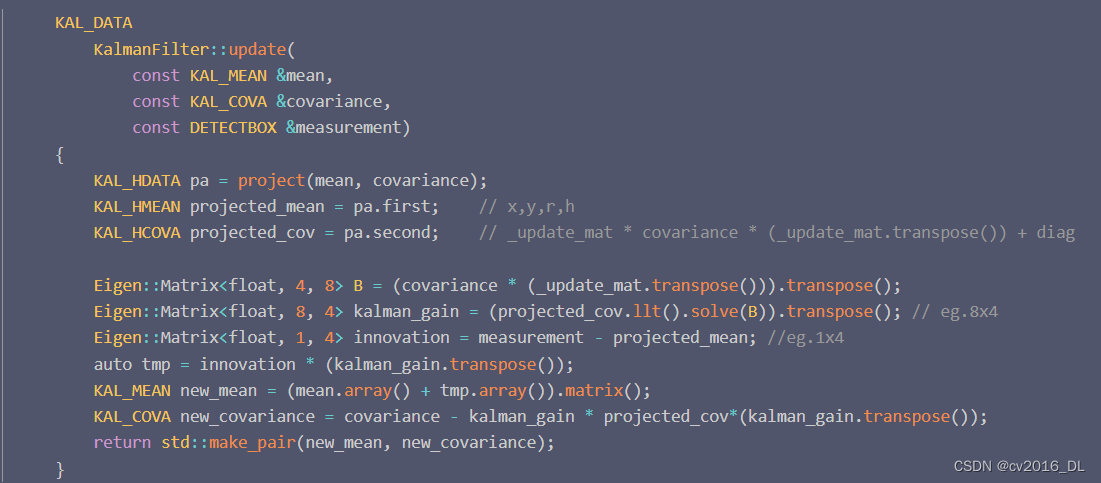

mean 1*8矩阵(xCenter, yCenter, w/h, h, Vx, Vy, Vr, Vh)
mean1 相当于提取了 mean 中前四个元素。
covariance1 是为了方便后续更新 covariance 一个中间量。
diag 为测量噪声协方差,文中设定与过程噪声矩阵类似。
kalman_gain 为卡尔曼增益,原本需要求 projected_cov 的逆矩阵,再与 B 矩阵相乘求得,这里直接通过解线性方程组的形式求的,省略了一些计算步骤。
new_mean 与 new_covariance 为新的 box 状态与 新的协方差。 预测框与高置信度检测框匹配成功后,无论此时目标 state 为Tracked 还是 Lost,都需更新为Tracked状态,且is_activated 均更新为 true。且都需要进行 kalman 中 update 操作。 一旦目标匹配后:
a.目标的state 均变为 Tracked
b.目标的is_activated 均变为true
c.目标的mean与covariance均需update
第一次未匹配上的预测框与检测框额外缓存。方便后续操作。
ii.第二次匹配 :第一次未匹配的预测框与低置信度检测框
第一次未匹配的预测框:第一次未匹配上,state为Tracked的预测框。state为Tracked表明该目标为上一帧匹配上的目标
低置信度检测框:置信度小于track_thresh中的检测框,文中track_thresh = 0.5。
匹配仍然计算iou匹配。匹配上的目标与第一次匹配类似处理。未匹配上的目标会被标记,state后续可能会被修改为Lost。
iii.第三次匹配 is_activated=false 的跟踪框与第一次未匹配的高置信度检测框
is_activated=false的跟踪框:上一帧新起的目标,只有上一帧新起的目标is_activate才为false,且此时的框并未做predict处理,也就是说用的上一帧的原始检测框匹配
第一次未匹配的高置信度检测框:置信度大于track_thresh,但是第一次未与状态为is_activated跟踪目标匹配。
如果目标匹配上,则
a.state = Tracked
b.is_activated = true
c.mean 与 covariance 均 update。
如果目标未匹配上,此时状态会变为 Removed,此目标会被永久移除。为了要连续两规避偶尔出现某一帧假阳性,至少需帧高置信度的检测才可被 confirm,有机会参与后续计算。
(4)结果发布
在发布结果前,需要变更BYTETrack类成员变量的值。
a.当 Lost 状态超过 max_time_lost时,state 从 Lost 变为 Removed,此目标被永久遗忘。max_time_lost 构造函数时就已经设定。设定10或者30,根据实际情况调整。
b.当成员 state 从 Lost 变为 Tracked 或 Remove d时,this->lost_stracks 需剔除id一致的。

当有重复路径时,存活帧数一致,航迹相似。也需剔除此lost航迹。 输出结果:只有当 is_activated = true、state=Tracked 时,才会输出目标
(5)总结
a.检测目标未匹配上时,只有当置信度大于 0.6 才可以新起航迹,其他情况直接被遗忘。此时新起航迹 is_activated 为 false(第一帧不同,第一帧新起航迹 is_activated 默认为 true),当与下一帧置信度大于 0.5 的检测目标在第三次匹配匹配上时(is_activated=false 的目标没资格参与前两次匹配),此时 is_activated 变为 true。此时被标记为 confirm,才有资格被输出。
b.跟踪航迹在匹配中成功匹配,此时无论 state = tracked、is_activated=true。可以参与下一帧匹配中的前两次匹配。如果前两次匹配都未成功,则此时 state = Lost,只能参与下一帧第一次匹配,如果连续 max_time_lost 帧在第一次匹配都未匹配上,此时会被遗忘 Removed,永久移除此航迹。
参考:【目标跟踪】ByteTrack详解与代码细节-腾讯云开发者社区-腾讯云
这篇关于ByteTrack跟踪理解的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







