本文主要是介绍【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【11】ElasticSearch,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
持续学习&持续更新中…
守破离
【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【11】ElasticSearch
- 简介
- 基本概念
- ElasticSearch概念-倒排索引
- 安装
- 基本命令
- ik 分词器
- SpringBoot整合
- 测试存储数据:
- 测试复杂检索
- 同步与异步调用
- 参考

简介
Elasticsearch 是一个高度可扩展且开源的全文检索和分析引擎。它可以让您快速且近实时地存储,检索以及分析海量数据。它通常用作那些具有复杂搜索功能和需求的应用的底层引擎或者技术。(我们得把MySQL中的数据给ES也存储一份,这样ES才能检索这些数据)
- https://www.elastic.co/cn/what-is/elasticsearch
- 全文搜索属于最常见的需求,开源的 Elasticsearch 是目前全文搜索引擎的首选。
- 它可以快速地储存、搜索和分析海量数据。维基百科、Stack Overflow、Github 都采用它
- Elastic 的底层是开源库 Lucene。但是,你没法直接用 Lucene,必须自己写代码去调用它的接口。
- Elastic 是 Lucene 的封装,提供了 REST API 的操作接口,开箱即用。
- REST API:天然的跨平台。
- 官方文档:https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html
- 官方中文:https://www.elastic.co/guide/cn/elasticsearch/guide/current/foreword_id.html
- 社区中文:
- https://es.xiaoleilu.com/index.html
- http://doc.codingdict.com/elasticsearch/0/
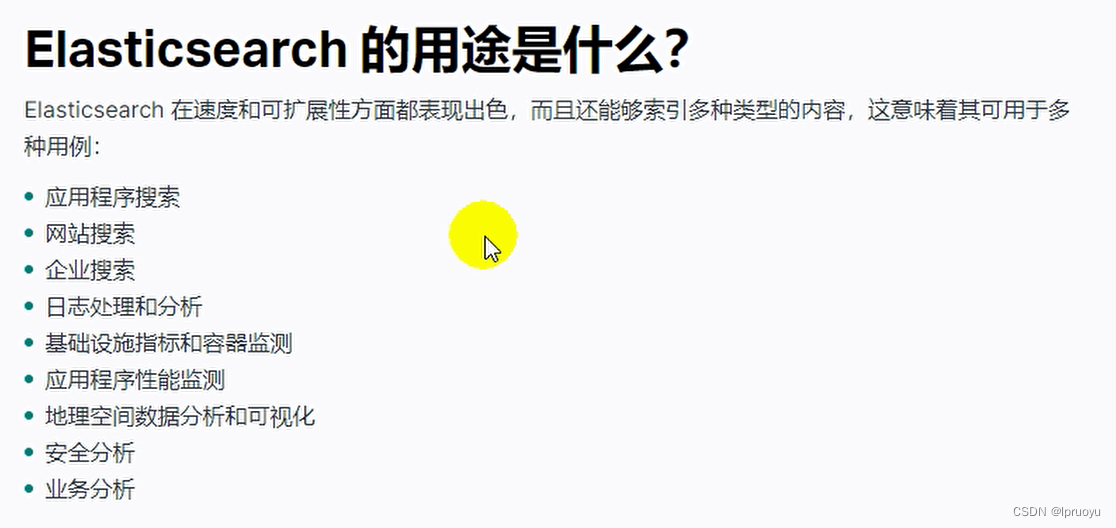


基本概念

类比MySQL数据库:索引 ============= 数据库
类型 ============= 数据表
文档 ============= 行记录(数据)
属性 ============= 列名
一个 Elasticsearch 可以 包含多个 索引 ,相应的每个索引可以包含多个 类型 。 这些不同的类型存储着多个 文档 ,每个文档又有 多个 属性 。【这些文档都是json】


ElasticSearch概念-倒排索引

比如检索“红海特工行动”,会发现,4号记录命中了一次,1/2/3/5分别命中了两次,但是,5号记录是四个单词命中了两次,3号记录是三个单词命中了两次,那么3号记录的相关性得分就更高;查询出的结果会按照相关性得分从高到低排序。
安装
老师安装在虚拟机中,由于内存原因,我安装在Windows下
elasticsearch:7.4.2
https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.4.2-windows-x86_64.zip
elasticsearch.yml:
path.data: G:\elasticsearch\data
path.logs: G:\elasticsearch\logs
http.cors.enabled: true
http.cors.allow-origin: "*"
jvm.options:
-Xms64m
-Xmx512m
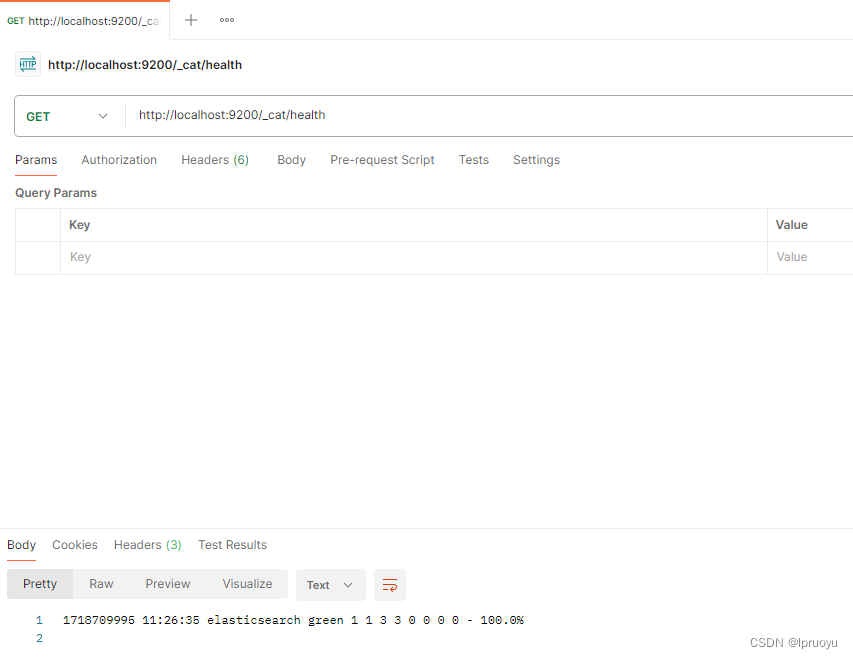
kibana:7.4.2
https://artifacts.elastic.co/downloads/kibana/kibana-7.4.2-windows-x86_64.zip


基本命令
保存一个数据,保存在哪个索引的哪个类型下,指定用哪个唯一标识
PUT customer/external/1;在 customer 索引下的 external 类型下保存 1 号数据为
{ "name": "John Doe"
}

PUT 和 POST 都可以,
- POST 新增。如果不指定 id,会自动生成 id。指定 id 就会修改这个数据,并新增版本号
- PUT 可以新增可以修改。PUT 必须指定 id;由于 PUT 需要指定 id,我们一般都用来做修改操作,不指定 id 会报错。
查询文档


ik 分词器
https://github.com/infinilabs/analysis-ik/releases?after=v6.4.2&page=11
放到G:\software\elasticsearch-7.4.2-windows-x86_64\elasticsearch-7.4.2\plugins目录下并解压,然后改目录名为analysis-ik

使用分词器对比:(默认分词器:standard)



能够看出不同的分词器,分词有明显的区别,所以以后定义一个索引不能再使用默认的 mapping 了,要手工建立 mapping, 因为要选择分词器。
自定义词库:
利用 nginx 发布静态资源,按照请求路径,创建对应的文件夹以及文件,放在nginx的html目录下

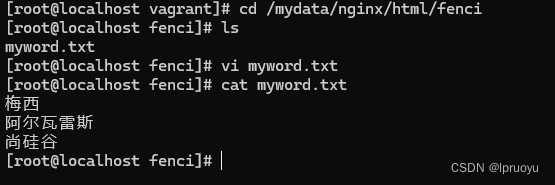
修改G:\software\elasticsearch-7.4.2-windows-x86_64\elasticsearch-7.4.2\plugins\analysis-ik\config\IKAnalyzer.cfg.xml
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd">
<properties><comment>IK Analyzer 扩展配置</comment><!--用户可以在这里配置自己的扩展字典 --><entry key="ext_dict"></entry><!--用户可以在这里配置自己的扩展停止词字典--><entry key="ext_stopwords"></entry><!--用户可以在这里配置远程扩展字典 --><!-- http://192.168.56.10/fenci/myword.txt 80断口是nginx端口,把这个txt放在nginx中的html目录下 --><entry key="remote_ext_dict">http://192.168.56.10/fenci/myword.txt</entry><!--用户可以在这里配置远程扩展停止词字典--><entry key="remote_ext_stopwords">words_location</entry>
</properties>
重启elasticsearch和kibana后,测试自定义的词库使用效果:

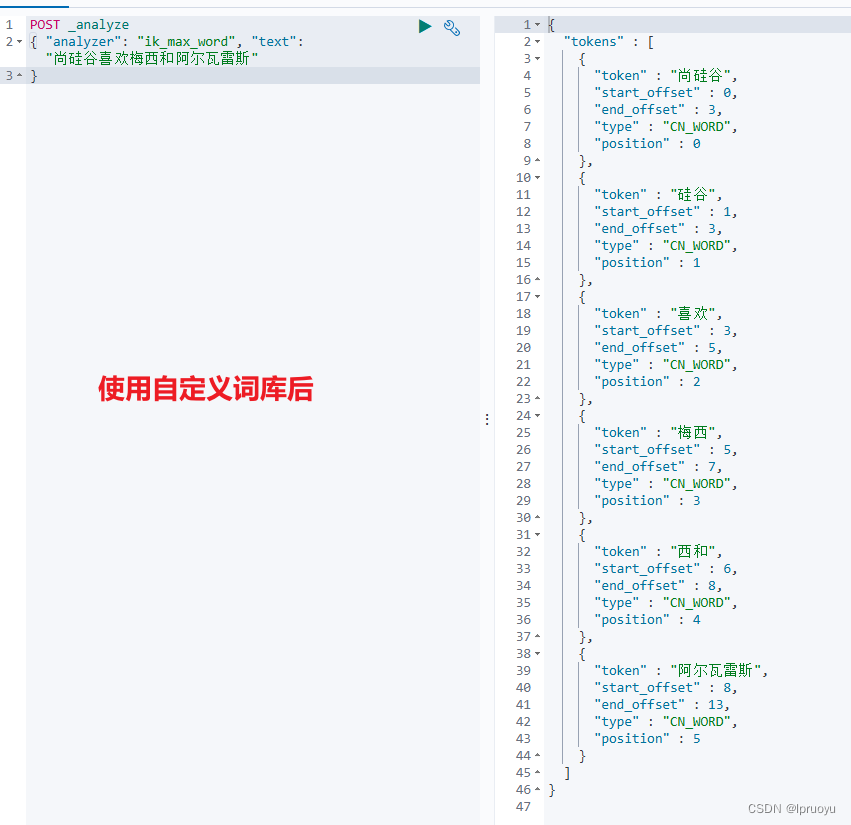
注意:
更新完成后,es 只会对新增的数据用新词分词。历史数据是不会重新分词的。如果想要历史数据重新分词。需要执行:
POST my_index/_update_by_query?conflicts=proceed
SpringBoot整合


最终选择 Elasticsearch-Rest-Client(elasticsearch-rest-high-level-client):
https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html
依赖:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 https://maven.apache.org/xsd/maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>com.atguigu.gulimall</groupId><artifactId>gulimall-search</artifactId><version>0.0.1-SNAPSHOT</version><name>gulimall-search</name><description>ElasticSearch检索服务</description><properties><elasticsearch.version>7.4.2</elasticsearch.version></properties><dependencies><!-- 导入es的rest-high-level-client--><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.4.2</version></dependency></dependencies>
</project>
配置类:
/*** 1、导入依赖* 2、编写配置,给容器中注入一个RestHighLevelClient* 3、参照API https://www.elastic.co/guide/en/elasticsearch/client/java-rest/current/java-rest-high.html*/
@Configuration
public class ElasticSearchConfig {public static final RequestOptions COMMON_OPTIONS;static {RequestOptions.Builder builder = RequestOptions.DEFAULT.toBuilder();
// builder.addHeader("Authorization", "Bearer " + TOKEN);
// builder.setHttpAsyncResponseConsumerFactory(
// new HttpAsyncResponseConsumerFactory
// .HeapBufferedResponseConsumerFactory(30 * 1024 * 1024 * 1024));COMMON_OPTIONS = builder.build();}@Beanpublic RestHighLevelClient esRestClient(@Value("${spring.elasticsearch.jest.uris}") String esUrl) {//TODO 修改为线上的地址//final String hostname, final int port, final String scheme/// RestClientBuilder builder = RestClient.builder(new HttpHost("192.168.56.10", 9200, "http"));// RestHighLevelClient client = new RestHighLevelClient(
// RestClient.builder(
// new HttpHost("192.168.56.10", 9200, "http")));return new RestHighLevelClient(RestClient.builder(HttpHost.create(esUrl)));}}
@EnableDiscoveryClient
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
public class GulimallSearchApplication {public static void main(String[] args) {SpringApplication.run(GulimallSearchApplication.class, args);}}
spring:elasticsearch:jest:uris: 127.0.0.1:9200
测试存储数据:
@Testpublic void indexData() throws IOException {IndexRequest indexRequest = new IndexRequest("users");indexRequest.id("1");//数据的id,如果不设置会自动生成id
// indexRequest.source("userName","zhangsan","age",18,"gender","男");User user = new User();user.setUserName("zhangsan");user.setAge(18);user.setGender("男");String jsonString = JSON.toJSONString(user);indexRequest.source(jsonString, XContentType.JSON);//要保存的内容//执行操作IndexResponse index = client.index(indexRequest, ElasticSearchConfig.COMMON_OPTIONS);//提取有用的响应数据System.out.println(index);}




将存储的东西转为JSON即可
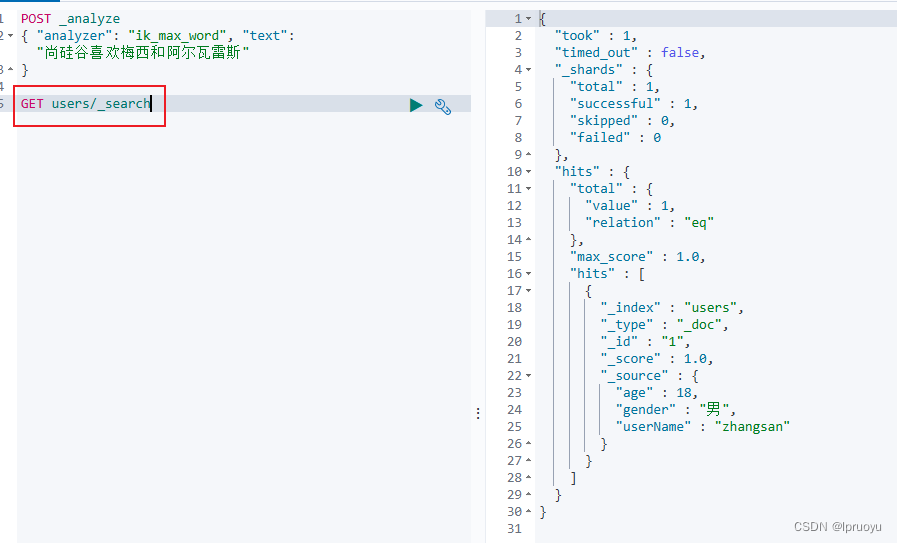
测试复杂检索
@Testpublic void searchData() throws IOException {//1、创建检索请求SearchRequest searchRequest = new SearchRequest();//指定索引searchRequest.indices("bank");//指定DSL,检索条件//SearchSourceBuilder sourceBuilde 封装的条件SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();//1.1)、构造检索条件
// sourceBuilder.query();
// sourceBuilder.from();
// sourceBuilder.size();
// sourceBuilder.aggregation()sourceBuilder.query(QueryBuilders.matchQuery("address","mill"));//1.2)、按照年龄的值分布进行聚合TermsAggregationBuilder ageAgg = AggregationBuilders.terms("ageAgg").field("age").size(10);sourceBuilder.aggregation(ageAgg);//1.3)、计算平均薪资AvgAggregationBuilder balanceAvg = AggregationBuilders.avg("balanceAvg").field("balance");sourceBuilder.aggregation(balanceAvg);System.out.println("检索条件"+sourceBuilder.toString());searchRequest.source(sourceBuilder);//2、执行检索;SearchResponse searchResponse = client.search(searchRequest, ElasticSearchConfig.COMMON_OPTIONS);//3、分析结果 searchResponseSystem.out.println(searchResponse.toString());
// Map map = JSON.parseObject(searchResponse.toString(), Map.class);//3.1)、获取所有查到的数据SearchHits hits = searchResponse.getHits();SearchHit[] searchHits = hits.getHits();for (SearchHit hit : searchHits) {/*** "_index": "bank",* "_type": "account",* "_id": "345",* "_score": 5.4032025,* "_source":*/
// hit.getIndex();hit.getType();hit.getId();String string = hit.getSourceAsString();Accout accout = JSON.parseObject(string, Accout.class);System.out.println("accout:"+accout);}//3.2)、获取这次检索到的分析信息;Aggregations aggregations = searchResponse.getAggregations();
// for (Aggregation aggregation : aggregations.asList()) {
// System.out.println("当前聚合:"+aggregation.getName());
aggregation.get
//
// }Terms ageAgg1 = aggregations.get("ageAgg");for (Terms.Bucket bucket : ageAgg1.getBuckets()) {String keyAsString = bucket.getKeyAsString();System.out.println("年龄:"+keyAsString+"==>"+bucket.getDocCount());}Avg balanceAvg1 = aggregations.get("balanceAvg");System.out.println("平均薪资:"+balanceAvg1.getValue());// Aggregation balanceAvg2 = aggregations.get("balanceAvg");}
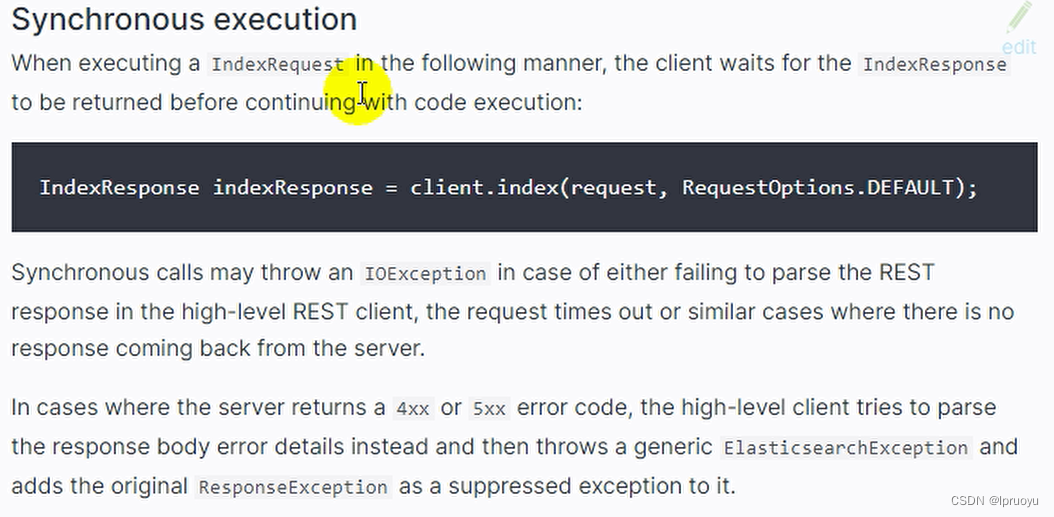
同步与异步调用

参考
雷丰阳: Java项目《谷粒商城》Java架构师 | 微服务 | 大型电商项目.
本文完,感谢您的关注支持!
这篇关于【雷丰阳-谷粒商城 】【分布式高级篇-微服务架构篇】【11】ElasticSearch的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







