本文主要是介绍2024 年最新 Python 使用 Flask 和 Vue 基于腾讯云向量数据库实现 RAG 搭建知识库问答系统,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
腾讯云向量数据库
腾讯云向量数据库(Tencent Cloud VectorDB)是一款全托管的自研企业级分布式数据库服务,专为存储、检索和分析多维向量数据而设计。
地址:https://buy.cloud.tencent.com/vector
新建安全组

创建向量数据库实例
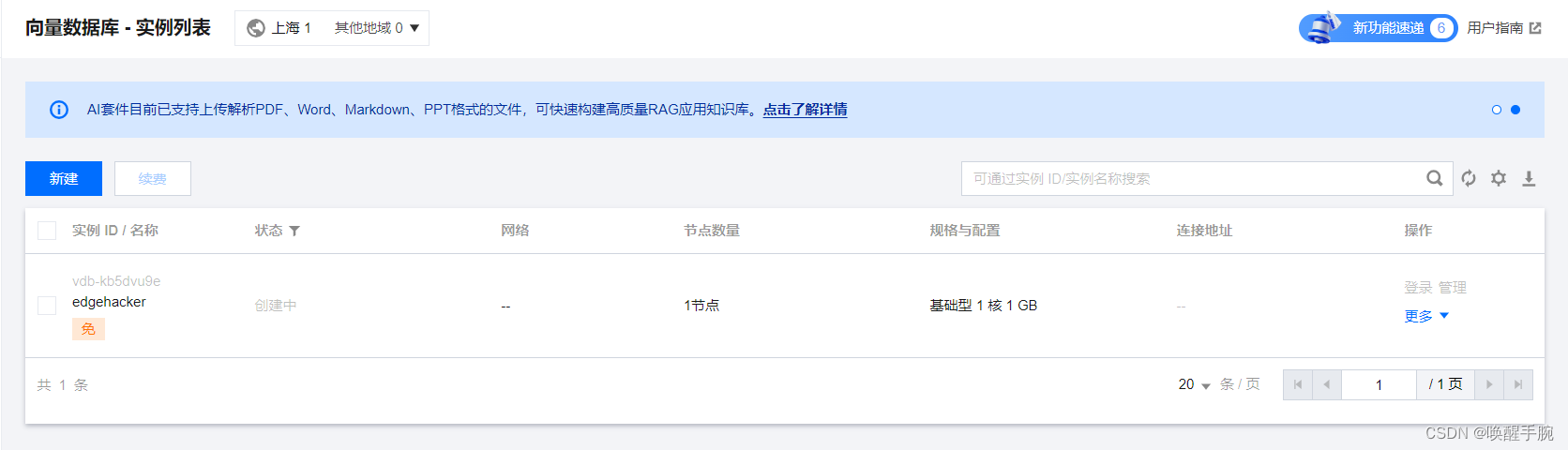
查看密钥

腾讯云 AI 套件
官方文档:https://cloud.tencent.com/document/product/1709/102189
什么是 AI 套件?
AI 套件是腾讯云向量数据库(Tencent Cloud VectorDB)提供的一站式文档检索解决方案,包含自动化文档解析、信息补充、向量化、内容检索等能力,并拥有丰富的可配置项,助力显著提升文档检索召回效果。用户仅需上传原始文档,数分钟内即可快速构建专属知识库,大幅提高知识接入效率。
设计思想
AI 套件检索方案提供完整的文档预处理和灵活的内容检索能力。用户只需上传 Markdown 格式的文档文件。腾讯云向量数据库将自动进行文本切分(Split)、信息补充、向量化(Embedding)和索引构建等一系列操作,完成知识库的建立。在进行检索时,会先基于切分后的内容进行相似度计算,并结合词(Words)向量进一步对检索结果进行精排,最终返回排名靠前的 Top K 条数据和其上下文内容。这种综合利用词级别做精排的检索方式,提供了更专业、更精确的内容检索体验。
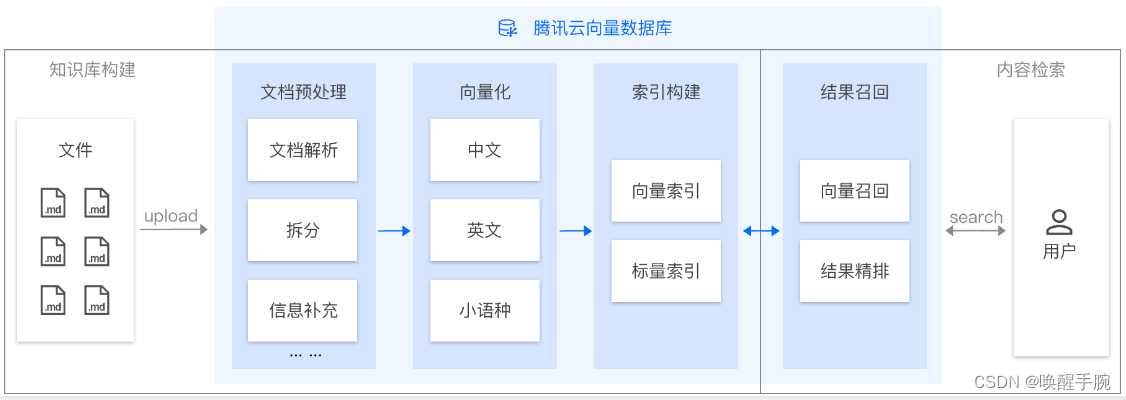
AI 类 Database
AI 类 Database 是专门用于 AI 套件上传和存储文件的向量数据库系统,可用于构建知识库。用户可以直接将文件上传至 AI 类 Database 下的 CollectionView 中,自动构建个性化的知识库。
CollectionView 集合视图
AI 类数据库文档组的集合视图,由多个 DocumentSet 组成,每个 DocumentSet 存储一组数据,对应一个文件数据。多个 DocumentSet 构成一个 CollectionView。
DocumentSet 文档集合
相对 Document 来说 DocumentSet 是 AI 类数据库中存储在 CollectionView 中的非结构化数据,是文件被拆分成多个 Document 的集合。每个DocumentSet 存储一组数据,对应一个文件,是 CollectionView 下存储文件的最小单元。
Metadata 文件元数据
文件元数据 指上传文件时所携带的文件元数据信息,可以包括文件的名称、作者、创建日期、文件类型等信息。所有元数据被自动解析为标量字段,以Key-Value格式存储。用户可根据元数据构建标量字段的 Filter 索引,以检索并管理文件。
Word 词语
词语 是智能文档检索中最小的分割粒度,通常由一个或多个字符组成。在结果召回时,将对召回段落中所有 Words 进行相似性计算,以便于根据词向量进一步对检索结果做精排。
当前支持导入数据库的文件类型包含: Markdown、PDF、Word、PPT
使用 AI 套件上传文件、检索
GitHub 地址:https://github.com/Tencent/vectordatabase-sdk-python
pip install tcvectordb

设置环境变量文件 .env
URL=http://······.clb.ap-shanghai.tencentclb.com:10000
KEY=mgeZvc1uQFaKVfnicx0roPaqPkVD3c9Hgy89······
操作向量数据库教程
连接数据库
import os
import tcvectordb
import dotenv
dotenv.load_dotenv(".env")vdbclient = tcvectordb.VectorDBClient(url=os.getenv("URL"), key=os.getenv("KEY"), username="root")
查询数据库
dbs = vdbclient.list_databases()
for db in dbs:print(db.database_name)
删除数据库
vdbclient.drop_ai_database(database_name="test_ai")
注意:drop_ai_database 和 drop_database 区别
读取文档更新 VectorDB
upload_dataset.py
import argparse
import os
import dotenv
from tcvectordb import VectorDBClientif os.path.exists(".env"):dotenv.load_dotenv(".env")vdbclient = VectorDBClient(url=os.getenv("URL"), key=os.getenv("KEY"), username="root")def isExisted_database(client: VectorDBClient, database_name: str):dbs = client.list_databases()for db in dbs:if db.database_name == database_name:return Truereturn Falsedef list_files_in_dir(fileDir: str):filename_list = []for filename in os.listdir(fileDir):if os.path.isfile(os.path.join(fileDir, filename)):filename_list.append(filename)return filename_listdef init_local_file(fileDir: str):if not isExisted_database(client=vdbclient, database_name="test_db"):db = vdbclient.create_ai_database("test_db")else:db = vdbclient.database(database="test_db")db.drop_collection_view(collection_view_name="test_coll_view")collectionView = db.create_collection_view(name="test_coll_view")for filename in list_files_in_dir(fileDir=fileDir):collectionView.load_and_split_text(local_file_path=f"{fileDir}/{filename}")print(f"{fileDir}/{filename} upload success")print('upload all the files success')if __name__ == "__main__":parser = argparse.ArgumentParser(description='数据集路径')parser.add_argument('--dataset-path', type=str, help='数据集路径')args = parser.parse_args()if 'dataset_path' in args and args.dataset_path:if os.path.exists(args.dataset_path):init_local_file(fileDir=args.dataset_path)else:print("read cmd dataset_path in error")else:if os.getenv("DATASET_PATH"):init_local_file(fileDir=os.getenv("DATASET_PATH"))else:print("read `.env` dataset_path in error")print("程序暂停,请按任意键继续...")input()print("程序继续执行...")
执行脚本
python update_dataset.py --dataset-path 目录地址
常见问题
<ServerInternalError: (code=15202, message=CollectionView create error, collectionView test_collView already exist)>
检索向量数据库
检索查询腾讯云向量数据库 search_vector_db.py
import os
import dotenv
from tcvectordb import VectorDBClientdotenv.load_dotenv(".env")
vdbclient = VectorDBClient(url=os.getenv("URL"), key=os.getenv("KEY"), username="root")def knowledge_search(query):db = vdbclient.database('test_db')collView = db.collection_view('test_coll_view')doc_list = collView.search(content=query, limit=3)result = []knowledge_id = 1for item in doc_list:knowledge = {"knowledge_id": knowledge_id, "knowledge_content": item.data.text}knowledge_id += 1result.append(knowledge)return resultif __name__ == "__main__":query = input("请填写查询内容:")print(knowledge_search(query))
查询测试
请填写查询内容:How to Create a New lRM Document in a BookmarkKnowledge content 1:
Ingredient Statement and Dangerous Good ahead of A8 – NA only|ü(1)|
MRO Assessment (also see 10.2)|ü|ü
DSBP & Artwork Kick Off|ü(2)|
Master Data Set-up (also see 10.13)|ü(3)|
Production Parts|ü|ü
Where aligned with GPS only
Where DSBP in place onlyKnowledge content 2:
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Refer to Newton for approvals and dates. Document is subject to review as relevant after the issue date.Knowledge content 3:
||Sp: Additional information about the Test Method (Text-entry)| |UTGT: When lower and upper target values are provided, the plant/supplier must average within the LTGT and UTGT. These fields should not be used when the TGT field is used (Text-entry)| | | |进程已结束,退出代码0
LLM 模型 invoke
提示模板 prompt_template.txt
Given the following information:{documents}Please answer the question:{question}langchain_local_service.py
import osimport dotenv
from langchain_openai import ChatOpenAI
import datetime
import search_vector_dbdotenv.load_dotenv(".env")temperature = float(os.getenv("TEMPERATURE"))llm = ChatOpenAI()with open("prompt_template.txt") as f:prompt_template = f.read()def write_local_log(query: str = None, documents: str = None, result: str = None):now = datetime.datetime.now(datetime.timezone.utc).astimezone() # 转换为本地时区timestamp = now.strftime('%Y_%m_%d_%H_%M_%S') + f'.{now.microsecond // 1000:03d}' # 毫秒级精度log_path = os.getenv('LOG_PATH')if not log_path:raise ValueError("Environment variable 'LOG_PATH' is not set.")try:with open(f"{log_path}/{timestamp}.txt", mode='w', encoding='utf-8') as f:f.write("USER QUESTION: \n")f.write(query or "")f.write("\n\nRAG DOCUMENTS: \n")f.write(documents or "")f.write("\n\nOPENAI RESULT: \n")f.write(result or "")f.write("\n")except Exception as e:print(f"Failed to write to log file: {e}")def rag_openai_ask(query: str):documents_list = search_vector_db.knowledge_search(query=query)documents = ""for document in documents_list:documents = documents + f"\nKnowledge content {document['knowledge_id']}:\n{document['knowledge_content']}"final_problem = prompt_template.replace("{documents}", documents).replace("{question}", query)result = llm.invoke(input=final_problem, temperature=temperature)write_local_log(query=query, documents=documents, result=result.content)return result.content
Flask 服务器启动
在 Flask 中,通常你会编写一个应用(通常是一个 Python 脚本),然后使用 Flask 的开发服务器来运行它,以便在开发过程中进行测试。然而,Flask 的开发服务器(通过 app.run() 启动)并不是为生产环境设计的,因此在生产环境中你应该使用更稳定、更安全的 WSGI 服务器。
Flask 启动服务器:监听 POST 请求并接收 JSON 数据
import osfrom flask import Flask, request, jsonify
from flask_cors import CORS
from dotenv import load_dotenv
load_dotenv(".env")import langchain_local_serviceapp = Flask(__name__)
CORS(app)@app.route('/message', methods=['POST'])
def post_json():if not request.is_json:return jsonify({"error": "Invalid payload"})data = request.jsonquestion = data['question']result = langchain_local_service.rag_openai_ask(query=question)return jsonify({"code": 200, "data": result})if __name__ == '__main__':print("TianJing ChatBot Server launch successfully.")app.run(host=os.getenv("SERVER_HOST"), port=int(os.getenv("SERVER_PORT")))
使用 curl 发送 JSON 数据
curl -X POST -H "Content-Type: application/json" -d "{\"key\": \"value\"}" http://localhost:80/message
Vue 前端 post
Vue.js 是一个流行的前端 JavaScript 框架,用于构建用户界面。Vue 的核心库只关注视图层,不仅易于上手,也便于与第三方库或已有项目整合。当与现代化的工具链以及各种支持类库结合使用时,Vue 能为复杂的单页应用提供驱动
axios.post("http://localhost:80/message", {question: this.question
}).then(res => {if (res.data.code == 200) {······}
})
详细环境变量配置
# 服务器向量数据库公网路径配置
URL=http://······.clb.ap-shanghai.tencentclb.com:10000
# 服务器向量数据库密钥配置
KEY=mgeZvc1uQFaKVfnicx0roPaqPkVD3c9Hgy89······
# OpenAI 密钥配置
OPENAI_API_KEY=sk·····
# OpenAI 源地址配置
OPENAI_BASE_URL=https://······
# 本地数据集目录配置
DATASET_PATH=dataset
# 本地日志地址配置
LOG_PATH=logs
# 随机性水平 0 ~ 1
TEMPERATURE=0.5
SERVER_PORT=80
# 本地服务器端口号(基于内网穿透)不可随意变更
SERVER_HOST=127.0.0.1
部署运行实验
运行截图

日志运行结果
USER QUESTION:
How to Create a New lRM Document in a BookmarkRAG DOCUMENTS: Knowledge content 1:
Ingredient Statement and Dangerous Good ahead of A8 – NA only|ü(1)|
MRO Assessment (also see 10.2)|ü|ü
DSBP & Artwork Kick Off|ü(2)|
Master Data Set-up (also see 10.13)|ü(3)|
Production Parts|ü|ü
Where aligned with GPS only
Where DSBP in place onlyKnowledge content 2:
---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Refer to Newton for approvals and dates. Document is subject to review as relevant after the issue date.Knowledge content 3:
||Sp: Additional information about the Test Method (Text-entry)| |UTGT: When lower and upper target values are provided, the plant/supplier must average within the LTGT and UTGT. These fields should not be used when the TGT field is used (Text-entry)| | | |OPENAI RESULT:
To create a new lRM (Ingredient Risk Management) document in a bookmark, you would need to follow the relevant processes outlined in the Knowledge content 1. This may involve tasks such as Ingredient Statement and Dangerous Good assessment, MRO Assessment, DSBP & Artwork Kick Off, Master Data Set-up, and Production Parts alignment. Additionally, you may need to refer to Newton for approvals and dates, as mentioned in Knowledge content 2. It's important to ensure that all necessary information, such as additional information about the Test Method, is included in the new lRM document.
附加:CURL 网络请求
curl 是一个多功能的命令行工具,主要用于与服务器进行通信,支持多种协议,包括HTTP、HTTPS、FTP等。其名称来自于“Client for URLs”,即URL的客户端。curl 最初在 1997 年发行,作为一个利用 URL 语法在命令行下工作的文件传输工具。它支持文件上传和下载,因此是一个综合传输工具,但传统上常被视为下载工具。
| 用法 | 描述 | 示例 |
|---|---|---|
| 发送 GET 请求 | 获取远程服务器上的数据 | curl https://www.example.com |
| 发送 POST 请求 | 向服务器发送数据 | curl -X POST -d “param1=value1¶m2=value2” https://www.example.com/post |
| 设置请求头 | 在请求中包含特定的头部信息 | curl -H “Content-Type: application/json” -H “Accept: application/json” https://www.example.com |
| 下载文件 | 从 URL 下载文件并保存到本地 | curl -o output.txt https://www.example.com/file.txt |
| 使用自定义文件名保存文件 | 根据远程文件名保存文件 | curl -O https://www.example.com/file.txt |
| 处理 Cookie | 保存服务器发送的Cookie并在后续请求中自动发送 | curl -c cookies.txt https://www.example.com curl -b cookies.txt https://www.example.com |
| 自定义 User-Agent | 设置请求的 User-Agent | curl -A “MyCustomUserAgent/1.0” https://www.example.com |
| 显示请求和响应的详细信息 | 包括头部、请求和响应体 | curl -v https://www.example.com |
| 发送 JSON 数据 | 发送JSON格式的数据到服务器 | curl -X POST -H “Content-Type: application/json” -d ‘{“key”: “value”}’ https://www.example.com/api |
| 跟随重定向 | 自动跟随 HTTP 重定向 | curl -L https://www.example.com/redirect |
| 禁止输出 | 不显示响应内容 | curl -s https://www.example.com |
| 显示响应头 | 仅显示 HTTP 响应的头部信息 | curl -i https://www.example.com |
| 使用 HTTP 认证 | 发送 HTTP 基本认证的用户名和密码 | curl -u username:password https://www.example.com/protected |
| 发送表单文件 | 发送表单文件(如文件上传) | curl -F “file=@/path/to/file.txt” https://www.example.com/upload |
这篇关于2024 年最新 Python 使用 Flask 和 Vue 基于腾讯云向量数据库实现 RAG 搭建知识库问答系统的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




