本文主要是介绍数据资产入表-数据分类分级标准-数据分级,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
前情提要:2021年9月1日,《中华人民共和国数据安全法》正式施行,明确规定“国家建立数据分类分级保护制度”,数据分级分类是数据安全管理的重要措施,它涉及到对数据资产的识别、分类和定级,是保障数据合规的前提。
数据分类:根据数据的属性或特征,按照一定的原则和方法进行区分和归类的过程,目的是为了更好地管理和使用数据。
数据分级:根据数据的敏感程度和遭到篡改、破坏、泄露或非法利用后对国家安全、企业利益和个人隐私的影响程度,按照一定的原则和方法进行定级的过程。
上一讲完成了数据分类的介绍,本讲来到数据分级的介绍。
数据分级的依据
数据分级的依据可以按照三个维度分析,分别是数据安全共享、数据价值、数据质量;
1.数据安全共享维度
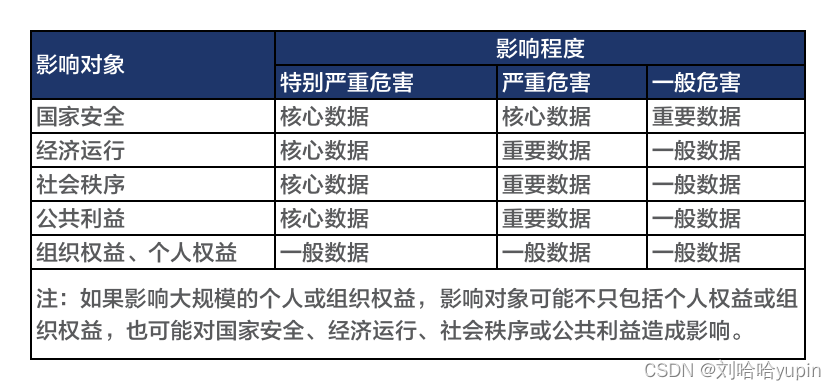
根据数据在经济社会发展中的重要程度,以及一旦遭到泄露、篡改、损毁或者非法获取、非法使用、非法共享,对国家安全、经济运行、社会秩序、公共利益、组织权益、个人权益造成的危害程度,将数据从高到低分为核心数据、重要数据、一般数据三个级别。
2.组织内部数据价值维度
组织内部对于数据应用场景可能会存在不同的依赖度,存在主数据、特色场景数据、高频使用数据、市场同质情况不多的高价值数据等诸多情况,可以按照数据使用频率、产品竞争力两个维度进行等级划分,区分出核心数据、重要数据、一般数据三个级别;
3.数据质量管理维度
数据质量管理维度主要是围绕技术角度,为保障数据的一致性和唯一性,需要识别出组织内部的主数据内容、业务主键信息、外键关联信息三大维度;区分出重要数据和一般数据;
数据共享安全维度-数据分级方法
数据安全共享维度层面,具体可参考以下步骤进行数据分级:
a)确定分级对象:确定待分级的数据,如数据项、数据集、衍生数据、跨行业领域数据等。
注1:数据项通常表现为数据库表某一列字段等。数据集是由多个数据记录组成的集合,如数据库表、数据库一行或多行记录集合、数据文件等。
注2:跨行业领域数据是指某个行业领域收集或产生的数据流转到另一个行业领域,以及两个或两个以上行业领域的数据融合加工产生的数据。
b)分级要素识别:结合自身数据特点,识别数据涉及的分级要素情况。
c)数据影响分析:结合数据分级要素识别情况,分析数据一旦遭到泄露、篡改、损毁或者非法获取、非法使用、非法共享,可能影响的对象和影响程度。
d)综合确定级别:基于上述逻辑综合确定数据级别。


组织内部数据价值维度-数据分级方法
组织内部的数据价值维度判断可以按照数据使用频率、产品竞争力两个维度进行等级划分,按照组织内部对于数据价值的定义和分类区分出核心数据、重要数据、一般数据三个级别;
数据质量管理维度-数据分级方法
数据质量管理维度主要是围绕技术角度,为保障数据的一致性和唯一性,需要识别出组织内部的主数据内容、业务主键信息、外键关联信息三大维度。其中主数据定义为核心数据,业务主键、关联外键两类定义为重要数据,其余的可以定义为一般数据;
已上三类中,其中一个条件满足核心数据的条件则为核心数据;其中一个条件满足为重要数据的则为重要数据,其余的为一般数据;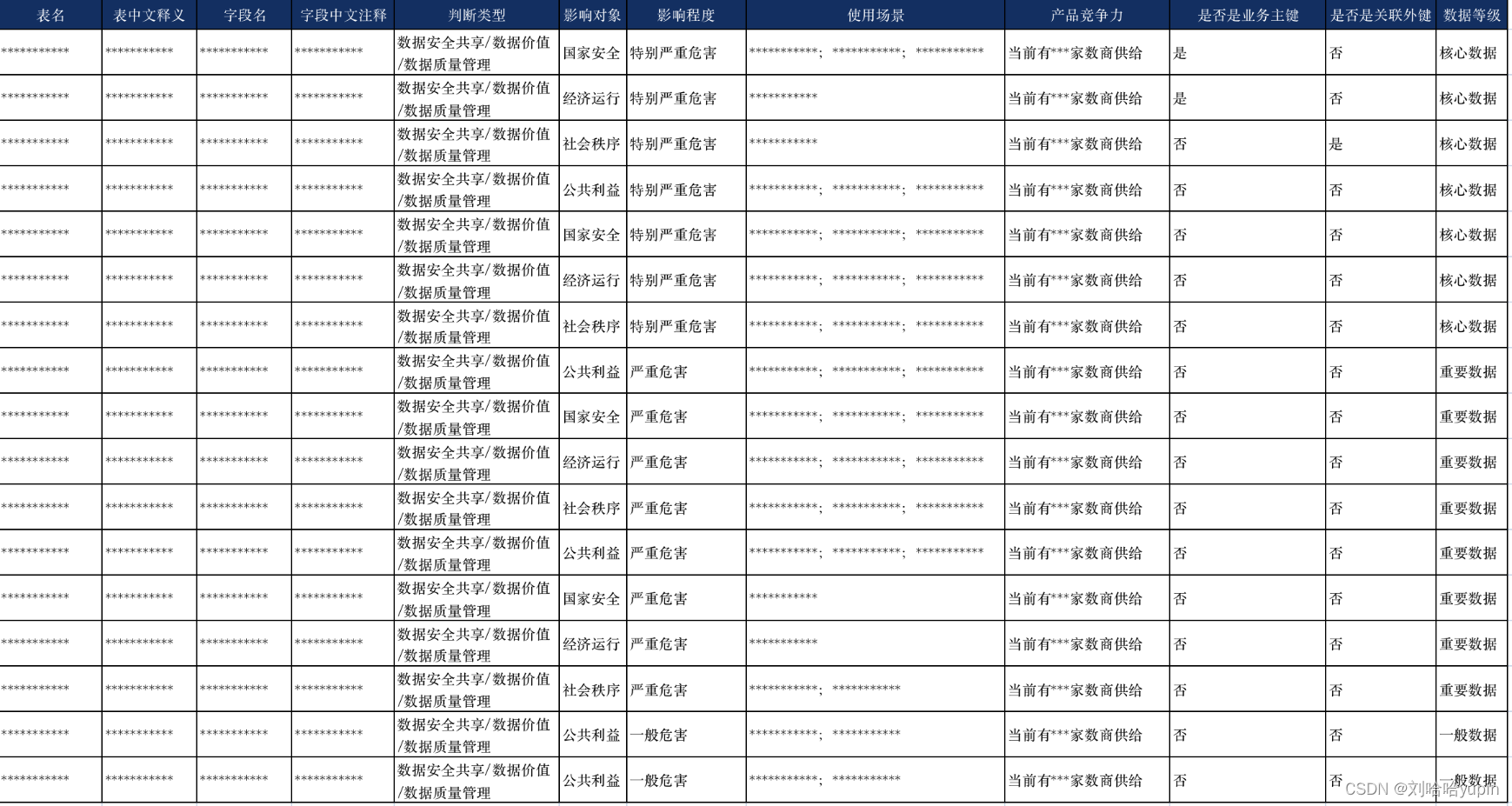
这篇关于数据资产入表-数据分类分级标准-数据分级的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






