本文主要是介绍如何使用大模型做重排?[草稿],希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
如何使用大模型做重排?
- https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_reranker/finetune_for_instruction
- https://github.com/LongxingTan/open-retrievals
看这个prompt, 是理解大模型如何做重排的第一步

数据
单个样本:
- query
- positive
- negative: list

query:
Prompt+answer:
最后的9583就是 Yes的编码

dataset中的item结果,包括input_id与label

collator
Loss
- rank_logits
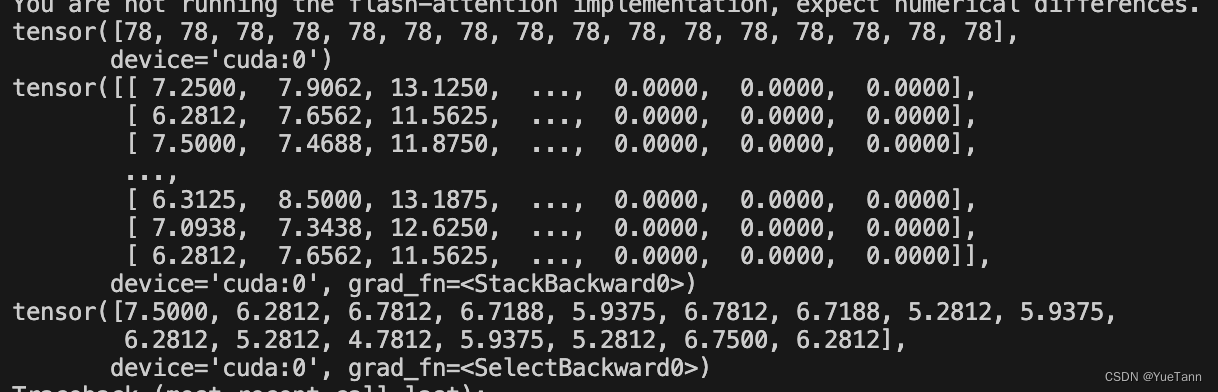
def encode(self, features):# input('continue?')if features is None:return Noneoutputs = self.model(input_ids=features['input_ids'],attention_mask=features['attention_mask'],position_ids=features['position_ids'] if 'position_ids' in features.keys() else None,output_hidden_states=True)_, max_indices = torch.max(features['labels'], dim=1)predict_indices = max_indices - 1logits = [outputs.logits[i, predict_indices[i], :] for i in range(outputs.logits.shape[0])]logits = torch.stack(logits, dim=0)scores = logits[:, self.yes_loc]return scores.contiguous()
- label:
target = torch.zeros(self.train_batch_size, device=grouped_logits.device, dtype=torch.long)
outputs: 大模型根据输入,应该输出的是yes或no.
max_indices: 就是yes所在的位置
predict_indices | logits | scores如图
这篇关于如何使用大模型做重排?[草稿]的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






