本文主要是介绍JMU 数科 数据库与数据仓库期末总结(4)实验设计题,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
E-R图
实体-关系图
E-R图的组成要素主要包括:
-
实体(Entity):实体代表现实世界中可相互区别的对象或事物,如顾客、订单、产品等。在图中,实体通常用矩形表示,并在矩形内标注实体的名称。
-
属性(Attribute):属性描述实体的特征或性质,比如顾客的姓名、年龄、地址等。属性在E-R图中一般位于实体的下方,用椭圆表示,并通过连线与实体相连。
-
关系(Relationship):关系表示实体之间的联系,例如一个顾客可以有多个订单。关系用菱形表示,并附有描述关系的文本标签,通过连线连接相关的实体。关系可以有一对一、一对多、多对一或多对多等多种类型。
举个栗子
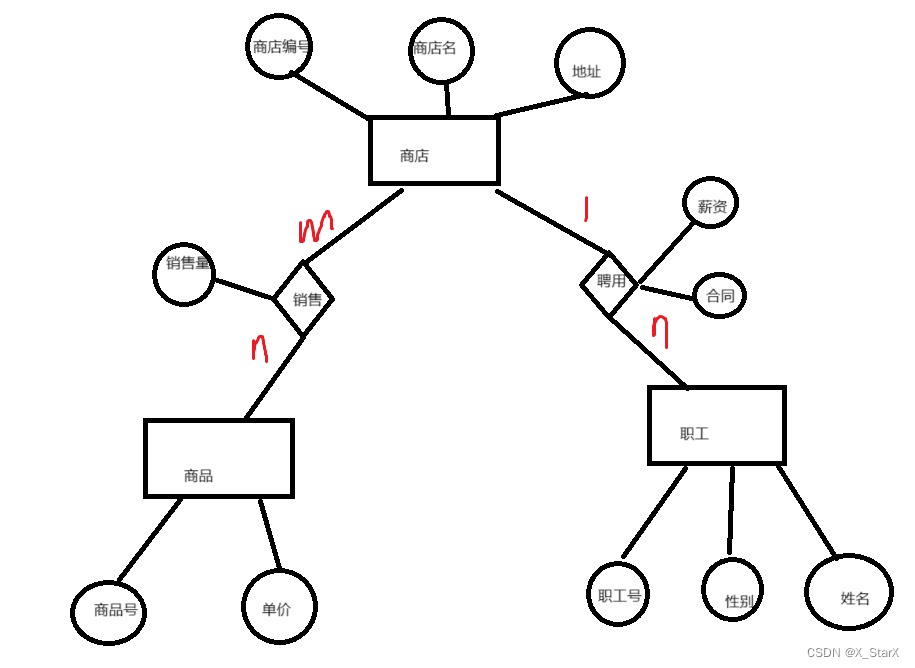
商店:商店编号,商店名,地址
商品:商品号,单价
职工:职工号,名字,性别
有以下关系:一个商品可以提供给多个商店,一个商店可以销售多个商品,会产生月销售量。职工只能在一个商店工作,商店可以聘用多个员工,聘用时会签合同,谈薪资。
分析:
上述中,实体为商店,商品,职工;
属性有各个实体的属性;
关系有 销售(多对多),聘用(一对多);
E-R图如下:
将E-R图转为表
还是上面的例子。
首先每个实体都各自为一张表。
若1对1,则任选其一将对方的主键作为自己的外键,且将关系里的属性放入自己。
若1对多,则选多的那一方,将对方的主键作为自己的外键,且将关系里的属性放入自己。
若多对多,则此关系另成一张表,外键为跟这个关系连着的实体的主键。
分析:
如上关系,成以下表:
商店:商品编号,商店名,地址。
销售:销售量,商店号,商品号。
商品:商品号,单价。
职工:职工号,姓名,性别,商店号,合同,薪资。
(红色为主键,橙色为外键)
SQL写代码
创建数据库:
CREATE DATABASE SDSystem;创建商店表并添加约束:
CREATE TABLE SD(sdid INT PRIMARY KEY,sdname VARCHAR(50) NOT NULL,dz VARCHAR(50)
);创建商品表并添加约束:
CREATE TABLE SP(spid INT PRIMARY KEY,dj INT
);创建销售表并添加约束:
CREATE TABLE XS(xsl INT,FOREIGN KEY (sdid) REFERENCES SD (sdid),FOREIGN KEY (spid) REFERENCES SP (sdid));创建职工表并添加约束:
CREATE TABLE ZG(zgid INT PRIMARY KEY,name VERCHAR(50) NOT NULL,sex CHAR(1) CHECK(sex in ('M','F') ),xz INT,ht VARCHAR(50),FOREIGN KEY (sdid) REFERENCES SD (sdid)
);增删改查修改:
向商店表添加记录
INSERT INTO SD (sdid, sdname, dz) VALUES (1, '北京店', '北京市朝阳区');向商品表添加记录
INSERT INTO SP (spid, dj) VALUES (101, 100);向销售表添加记录
INSERT INTO XS (xsl, sdid, spid) VALUES (1, 1, 101);向职工表添加记录
INSERT INTO ZG (zgid, name, sex, xz, ht, sdid) VALUES (1, '张三', 'M', 5, '销售经理', 1);从商店表删除记录
DELETE FROM SD WHERE sdid = 1;修改职工的薪资
UPDATE ZG SET xz = 8 WHERE zgid = 1;查询所有职工信息
SELECT * FROM ZG;查询特定商店下的所有商品销售记录
SELECT XS.xsl, SP.dj, SD.sdname
FROM XS
JOIN SP ON XS.spid = SP.spid
JOIN SD ON XS.sdid = SD.sdid
WHERE SD.sdid = 1;注释一下:
-- 查询销售表(XS)、商品表(SP)以及商店表(SD)的相关信息
SELECT -- 选取销售记录的编号(xsl)XS.xsl, -- 选取商品的单价(dj)SP.dj, -- 选取商店的名称(sdname)SD.sdname FROM -- 从销售表开始查询XS -- 首先通过商品ID(spid)将销售表(XS)与商品表(SP)进行连接,-- 这样就可以获取与每条销售记录相对应的商品信息JOIN SP ON XS.spid = SP.spid -- 然后,通过商店ID(sdid)进一步将上述结果与商店表(SD)连接,-- 使得每条销售记录都能关联到其发生的商店信息JOIN SD ON XS.sdid = SD.sdid -- 最后,通过WHERE子句过滤出特定条件的记录,
-- 本例中只选取那些发生在商店ID为1的销售记录
WHERE SD.sdid = 1;单表查询示例
查询商店表中所有的商店名称
SELECT sdname FROM SD;多表查询示例
多表查询通常涉及JOIN操作,用来从两个或多个相关联的表中获取数据。
查询每个商品的名称及其所属商店的名称
SELECT SP.spname, SD.sdname
FROM SP
JOIN SD ON SP.sdid = SD.sdid;创建一个视图,显示每个商店的销售总额
这个视图将汇总每个商店的销售总额,假设XS表中有一个字段je(金额)记录了每次销售的具体金额。
CREATE VIEW VW_SalesByStore AS
SELECT SD.sdid, SD.sdname, SUM(XS.je) AS TotalSalesAmount
FROM SD
JOIN XS ON SD.sdid = XS.sdid
GROUP BY SD.sdid, SD.sdname;注释一下:
-- 创建一个名为VW_SalesByStore的视图,用于展示每个商店的销售总额
--AS用来定义别名
CREATE VIEW VW_SalesByStore AS
-- 从商店表(SD)和销售表(XS)中选择数据
SELECT -- 选择商店的ID(sdid)SD.sdid, -- 选择商店的名称(sdname)SD.sdname, -- 计算并汇总每个商店的销售总额,这里假设销售表中有字段'je'表示销售金额SUM(XS.je) AS TotalSalesAmount FROM -- 首先从商店表开始SD -- 使用INNER JOIN将销售表与商店表连接起来,基于商店ID(sdid)相等的条件JOIN XS ON SD.sdid = XS.sdid -- 使用GROUP BY语句按商店ID和商店名称分组
GROUP BY SD.sdid, SD.sdname;视图的应用示例:使用视图查询销售表现最佳的商店
我们可以利用第一个创建的视图VW_SalesByStore来快速查询销售总额最高的商店
SELECT *
FROM VW_SalesByStore
ORDER BY TotalSalesAmount DESC
LIMIT 1;注释一下:
-- 从先前创建的视图VW_SalesByStore中选择所有列
SELECT *
FROM -- 视图名称为VW_SalesByStore,它提供了每个商店的销售总额信息VW_SalesByStore -- 使用ORDER BY子句对结果集进行排序
ORDER BY -- 按照TotalSalesAmount列(即每个商店的销售总额)进行降序排序TotalSalesAmount DESC -- 使用LIMIT子句限制返回的结果数量(销售额最高的那个商店)
LIMIT 1;这篇关于JMU 数科 数据库与数据仓库期末总结(4)实验设计题的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






