本文主要是介绍【C++】数据类型、函数、头文件、断点调试,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
四、基本概念
这部分和C语言重复的部分就简写速过,因为我之前写过一个C语言的系列,非常详细。C和C++这些都是一样的,所以这里不再一遍遍重复码字了。感兴趣的同学可以翻看我之前的C语言系列文章。
1、数据类型
编程的本质就是操作数据。
操作数据就是读数据、进行计算、写数据,其中读和写必然要牵扯到数据的存储。
数据的存储就必须要有数据的名字(变量名)、数据的内容(变量值)、数据的类型(变量类型)。
名字和值好理解,那为啥要类型呢?类型表示给这个变量一个多大的空间去存储它,比如一个字母a就给1个字节(8bit)就可以了,多了就是浪费;一个整数一般给4个字节,就是32位,当然你还可以规定比如第一个位表示符号位,这样就是可以表示正整数和负整数了,那剩下的31位,就能最大存一个2的31次方这个数字,当然如果你存了31个0,那就是0了,如果你存了31个1,那就是数字2的31次方了。也所以不是你想存多大就能存多大的,数字超过2的31次方,就会发生溢出,也就是你存的数字并不是你想存的数字了。
所以数据类型就是指这个数据存放空间的大小。不同的数据类型意味着占用不同大小的内存空间。
下图是基本的数据类型: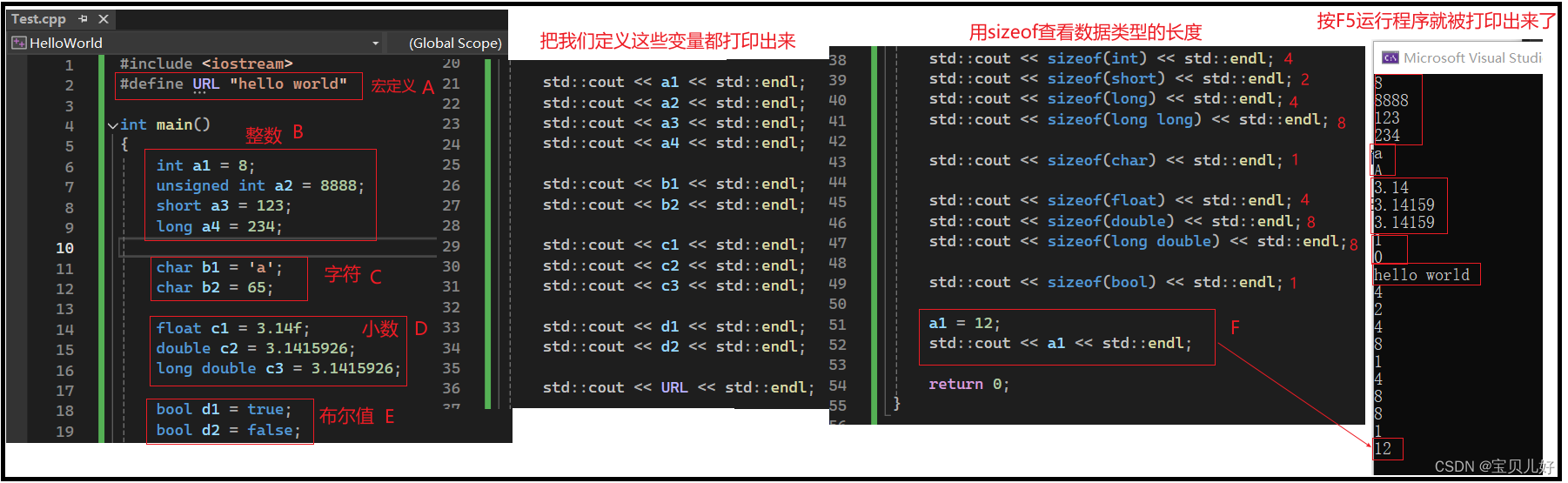
说明:
(1)数据首先是分为常量和变量。在程序运行的过程中,其值不能被改变的叫常量。可以改变的叫变量,入上图F。
常量我们用宏定义,上图A,宏URL就表示字符串“hello world”。上图中BCDE都是变量。
(2)不管是常量还是变量,对计算机来说最重要的是地址和类型!所谓的变量名其实是给程序员看的。计算机只要知道这个数据的首地址和占用内存的大小即可,它不需要知道这个数据的名称。数据名称只是程序员写的代码和编译器之间的沟通信号。编译器和代码用变量名沟通完毕后,编译器再和cpu传话时,用的就是这个数据的首地址和占用空间了。
(3)如果是整数变量,你可以定义变量的类型为int,short,long,long long这4种类型之一。其中int类型占用4个字节,short类型占2个字节,long类型占4个字节,long long 类型占8个字节。占用字节的大小决定着你这个数字在内存中的存储空间的大小,也就是决定着你存储的数字的上下限。unsigned表示是否有符号位。
同理其他数据类型。
(4)不同的数据类型给分配多大的内存,一般是取决于编译器,不同类型编译器之间会有差异,一般情况下,不会相差太大。
(5)bool类型不是取1就是取0,是不是1个比特位就够用了,为啥给分一个字节的空间呢?因为我们寻址内存的是是按照字节寻找的,找不到位的哈。
(6)除了上面展示的数据类型,你也可以创建自定义数据类型,但你自定义的类型都是在这些基本类型之上创建的。
(7)数据转化为指针或引用。指针通过一个*号来声明,引用用&表示。说来话长,这些以后要专门聊。
2、函数
函数就是我们写的代码块,被设计用来执行特定的任务。
如果函数被放到类里面了,就叫做方法了。所以这里我们讲的是函数不是方法。
为啥要函数?避免重复写相同的代码。你就理解为把某项特定的功能封装起来。你啥时候想用这个功能了,你调用这个函数就可以了。下面用例子展示: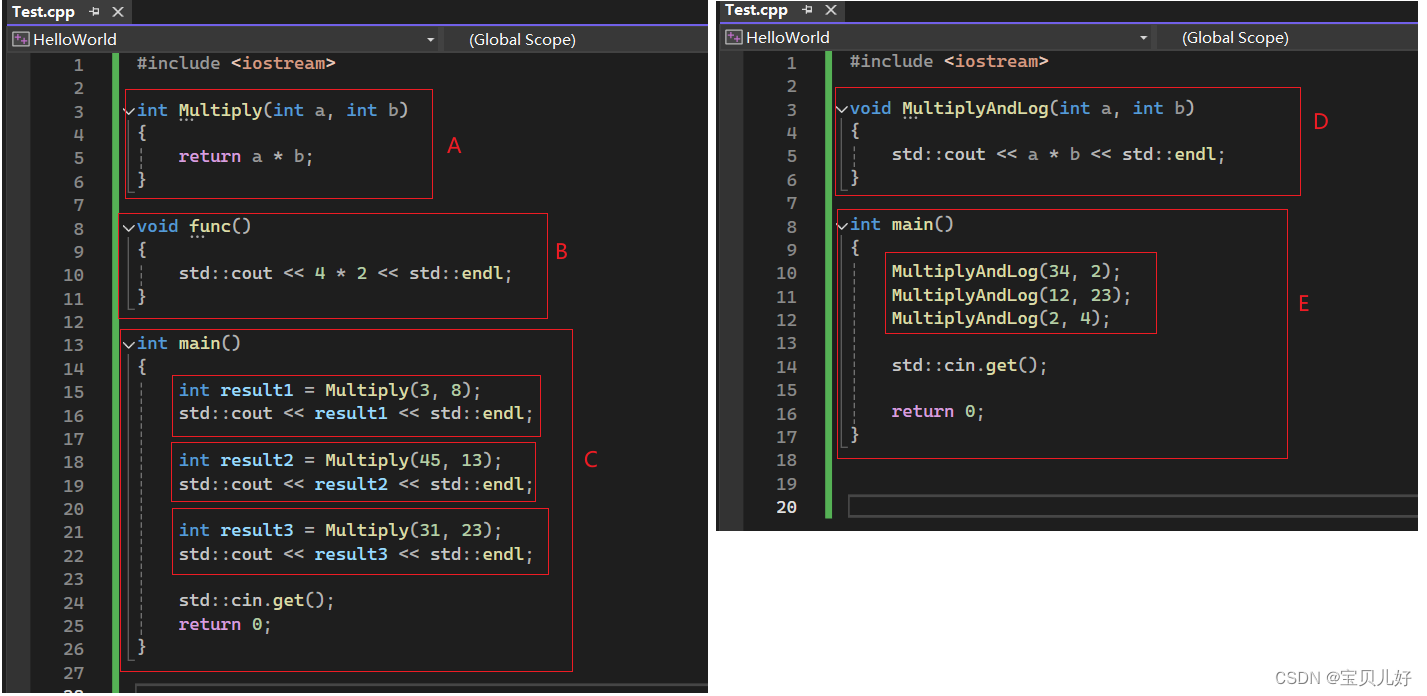 左图所示:我写了3个函数A、B、C。函数A的名字是Multiply,名字前面的int表示函数的返回值的类型是整型,名字后面的括号里是参数。这个函数有两个参数,a和b,参数a和b的类型都是int类型。函数B的名字是func,这个函数只是要实现在屏幕上打印一个4x2的结果,所以也不需要什么参数,所以小括号里面啥参数也不用写。又因为这个函数也不返回啥,所以函数名前面的返回值类型是void,void就是啥也没有的意思。函数C就是我们常说的main函数,是一个程序的入口函数,因为不需要传入任何参数,所以后面小括号里面啥也不用写,又因为其返回值是0,所以main前面是int。
左图所示:我写了3个函数A、B、C。函数A的名字是Multiply,名字前面的int表示函数的返回值的类型是整型,名字后面的括号里是参数。这个函数有两个参数,a和b,参数a和b的类型都是int类型。函数B的名字是func,这个函数只是要实现在屏幕上打印一个4x2的结果,所以也不需要什么参数,所以小括号里面啥参数也不用写。又因为这个函数也不返回啥,所以函数名前面的返回值类型是void,void就是啥也没有的意思。函数C就是我们常说的main函数,是一个程序的入口函数,因为不需要传入任何参数,所以后面小括号里面啥也不用写,又因为其返回值是0,所以main前面是int。
左图的Multiply函数就是一个“实现两个数相乘计算出结果”这个功能的函数。我们在C函数体内调用了3次Multiply函数。但是有没有发现,在main函数里写了3遍cout,是不是很麻烦。所以右图我们再写一个MutiplyAndLog函数,把A和B的功能都包含进来,是不是右图的main函数就简洁了很多!对这就是函数的封装打包,就是为了避免重复写代码!
函数有声明和定义。声明通常存储在头文件中,我们在翻译单元或cpp文件中编写定义
函数很重要,每个程序都是由一系列函数组成的。所以这里简单过一下函数调用过程中的堆栈:
堆(Heap)与栈(Stack)是开发人员必须面对的两个概念,不同场景下,堆与栈代表不同的含义。一般情况下,有两层含义:
(1)程序内存布局场景下,堆与栈表示两种内存管理方式;
(2)数据结构场景下,堆与栈表示两种常用的数据结构。
这里的堆栈通常称为调用栈或执行栈,是由操作系统和编译器共同管理的一种数据结构,用于存储函数调用的上下文信息。下面展示一个函数调用的粒子:
可见一个程序的运行一般是在内存中跳来跳去执行函数的。函数的prologue、epilogue是自动由编译器生成的,它的具体实现细节可能因编程语言、编译器、目标架构和调用约定的不同而有所变化。例如,在x86架构的C语言中,函数prologue和函数 epilogue 的典型汇编代码可能如下:
3、头文件
头文件通常用于声明一些函数。头文件中有很多函数声明,使我们在多个.cpp文件中使用。头文件就是我们声明函数的一个公共地方。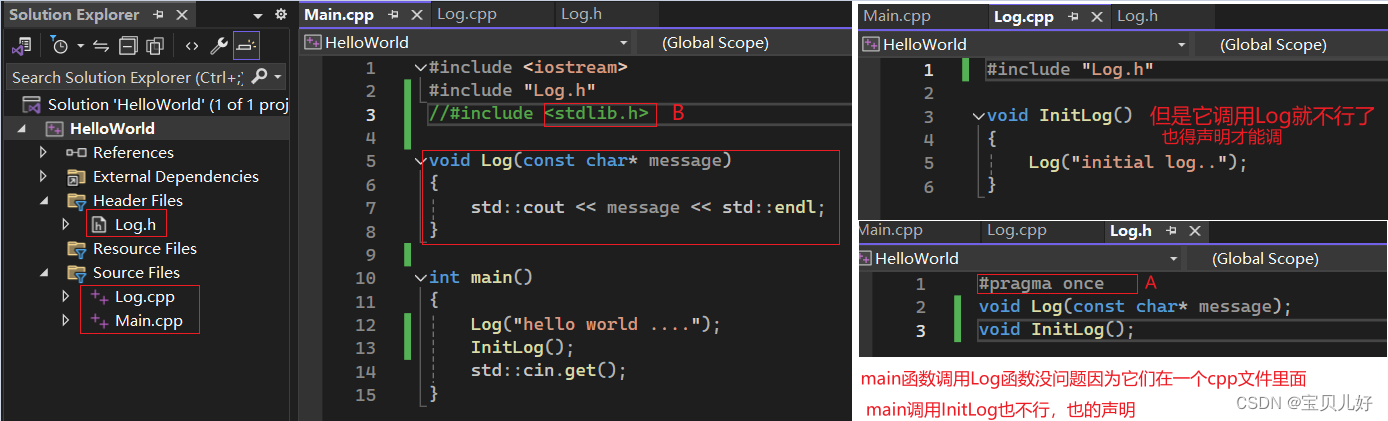
如上图所示,如果每个.cpp文件用到的函数都得声明一下,就非常麻烦,所以我们所有的函数的声明都放到.h文件中,然后在.cpp中include这个头文件,当预编译时就相当于是声明了。
A:这条语句的意思是只声明一次。当我们有多个头文件时,很难保证多个头文件中的声明函数没有重复的,当我们把多个头文件都include到.cpp文件中时,就会出现重复声明,就会报错,pragma once可以避免多次声明。
B:有的有头文件有后缀.h,有的头文件没有后缀,这是因为C++标准库和C标准库的区分。C++标准库的头文件文件名都没有扩展名,以此和C标准库进行区分。
C:include头文件时,有的用尖括号有的用双引号是因为:尖括号只用于编译器包含的默认路径,而如果你使用引号,那就自由很多,你可以写任意的你的相对路径。
4、断点调试
如果你的代码有语法错误,那编译时就会报错,你按照报错信息调试代码即可。但是如果你的代码能顺利运行但就是运行结果非你所想、或者运行过程中系统崩溃等现象,这些你就没法通过报错信息调试了,此时很重要的调试方法就是打断点->读取内存信息,去分析为啥运行过程中没有按照你的预期执行。
设置断点是为了读取内存。断点就是暂停的意思,程序执行到断点处就会挂起执行线程,此时程序的状态,就是你内存的状态。此时你查看内存视图,诊断你程序出问题的原因。
(1)如何进入断点调试模式: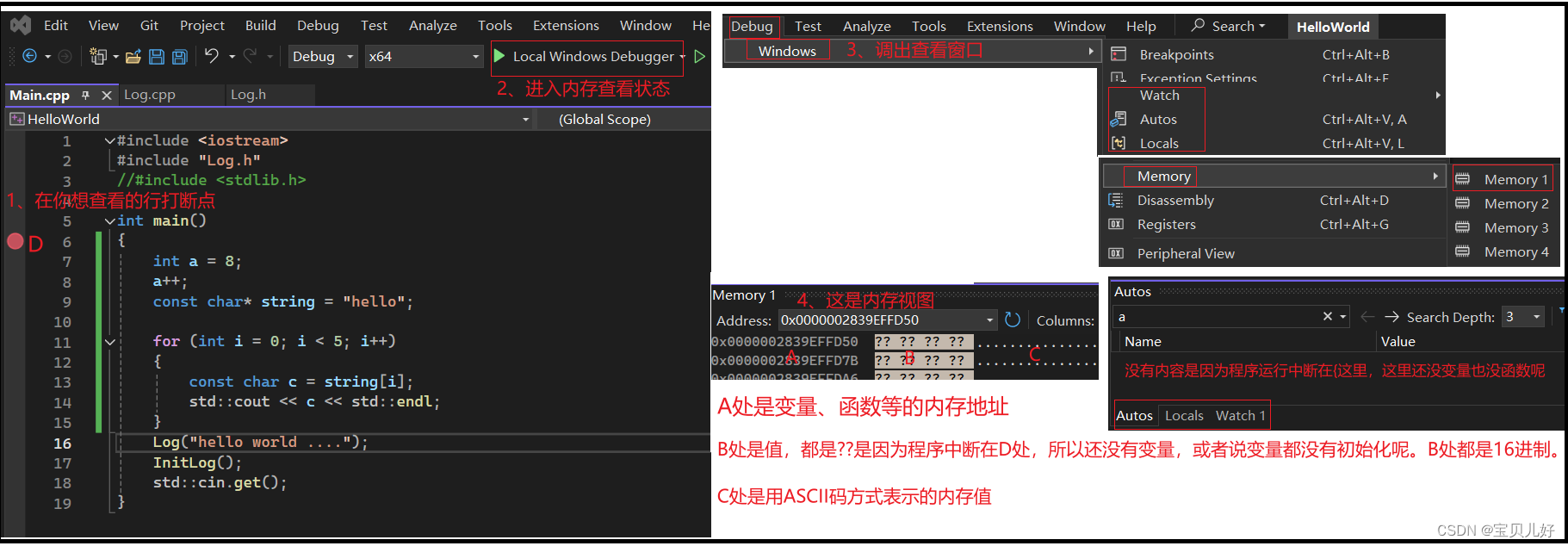
(2)内存查看的基本操作: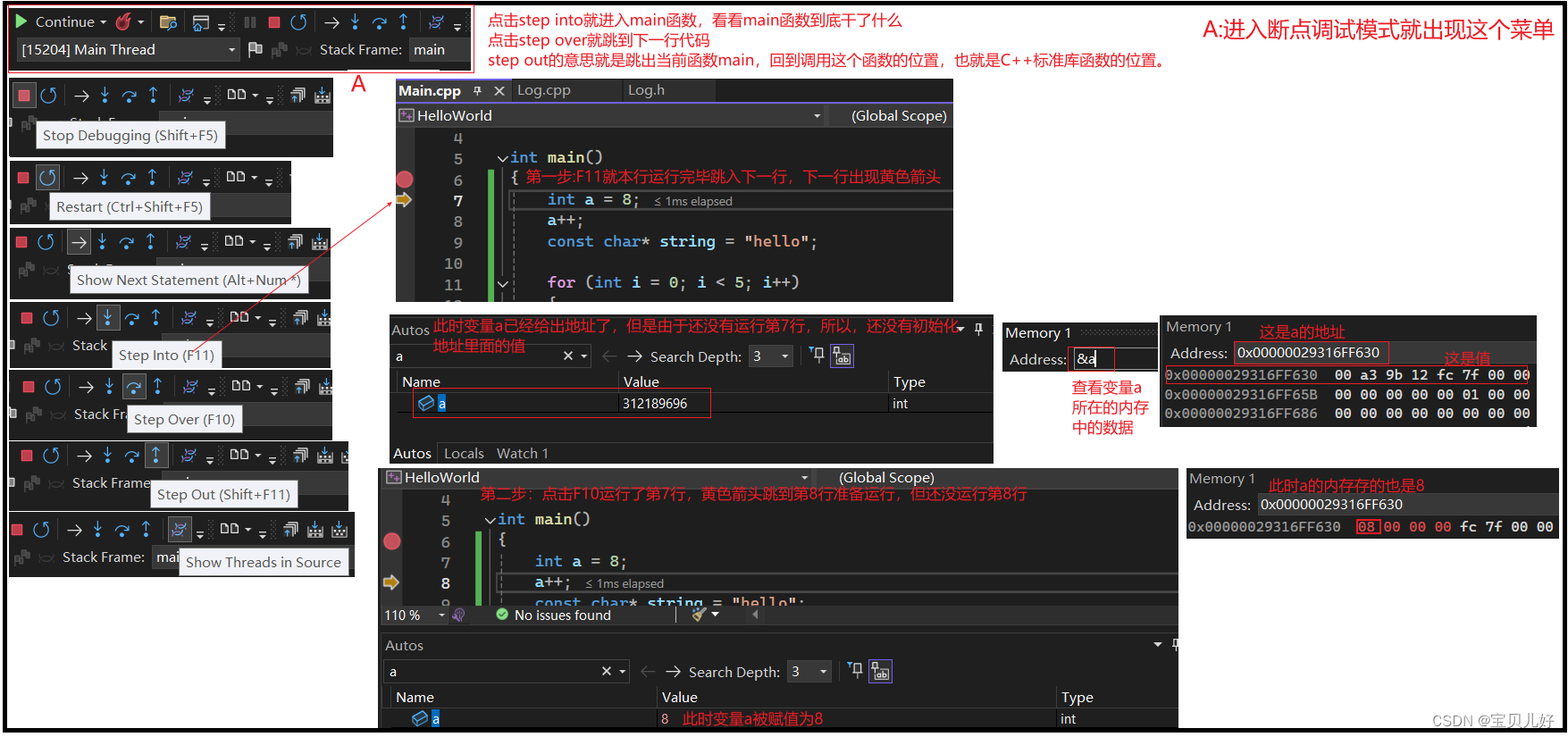
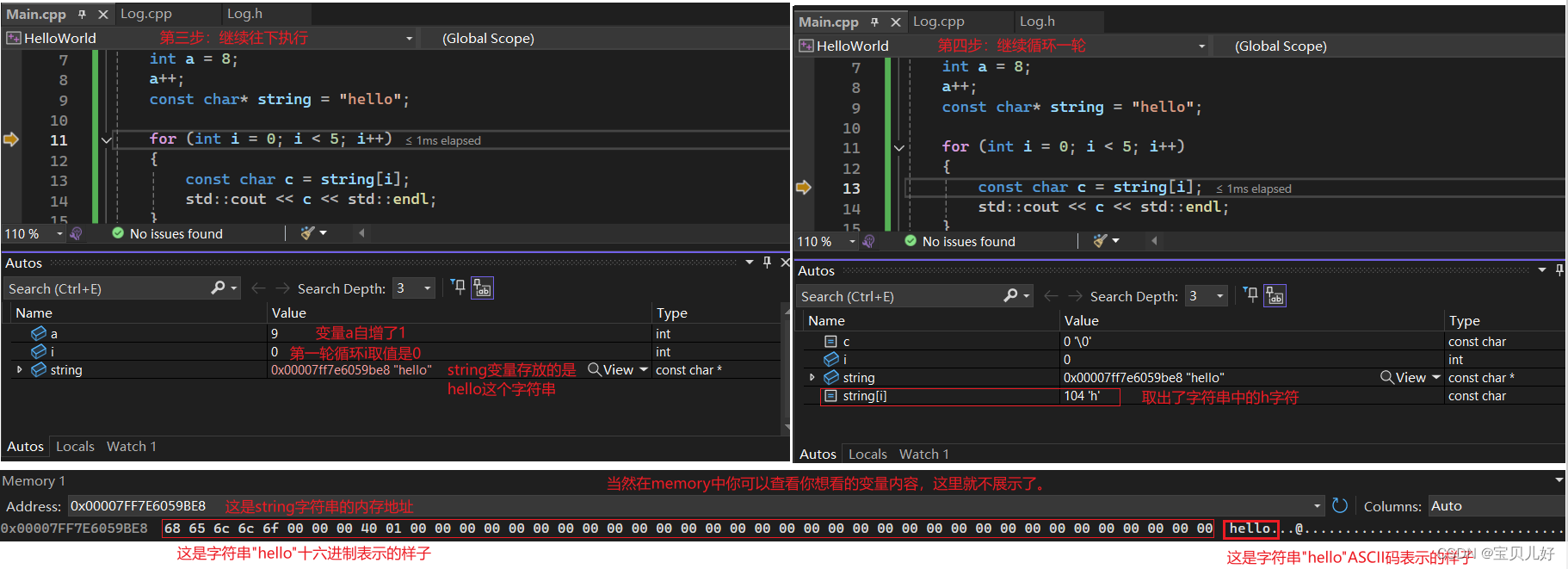
以上就是打断点,读取内存的方法。断点调试的内容很深很深,这里只是入门展示一下。
待续。。。
这篇关于【C++】数据类型、函数、头文件、断点调试的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!




