本文主要是介绍DuckDB,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
DuckDB库教程
DuckDB 是一个内嵌的、支持 SQL 的数据库管理系统,特别适合分析工作负载。它的设计目标是提供轻量级、高性能的SQL查询能力,并且可以直接在Python环境中使用,类似于SQLite。它支持多种数据格式,包括CSV、Parquet等,且能无缝集成Pandas等数据科学工具。
官方文档链接
DuckDB官方文档
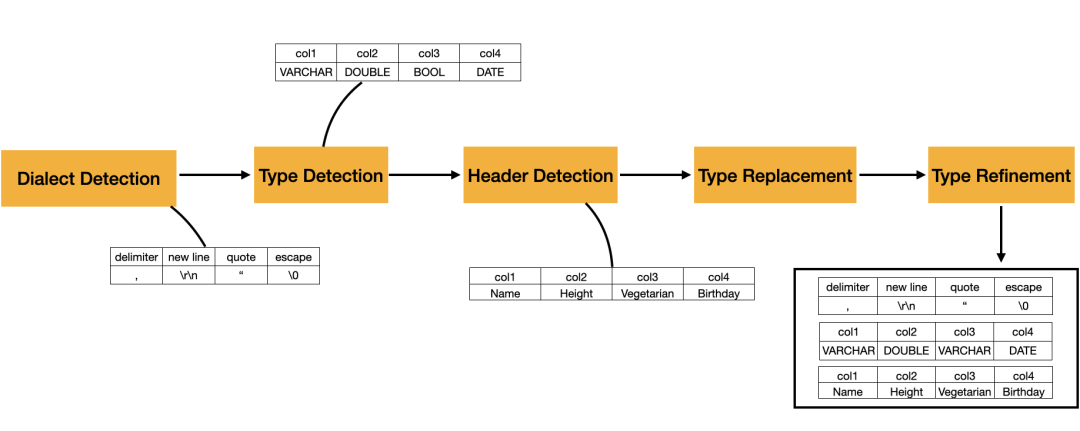
架构概述
DuckDB 的主要特点包括:
- 内嵌数据库:不需要单独的服务器进程,直接在应用程序中嵌入。
- 高性能:针对分析工作负载进行了优化。
- 灵活的数据格式支持:支持CSV、Parquet等格式的数据读取和写入。
- 与数据科学工具集成:可以与Pandas、NumPy等库无缝结合使用。
基础功能
- 安装DuckDB
首先,你需要安装DuckDB。可以使用pip来安装:
pip install duckdb
- 连接数据库
import duckdb# 创建或连接一个DuckDB数据库文件
con = duckdb.connect('example.db')# 也可以创建一个内存数据库
con = duckdb.connect(':memory:')
- 创建表
# 创建一个表
con.execute('''CREATE TABLE users (id INTEGER,name VARCHAR,age INTEGER)
''')
- 插入数据
# 插入数据
con.execute('INSERT INTO users VALUES (1, "Alice", 30)')
con.execute('INSERT INTO users VALUES (2, "Bob", 25)')
- 查询数据
# 查询数据
result = con.execute('SELECT * FROM users').fetchall()
print(result)
- 读取CSV文件
# 读取CSV文件
con.execute('''CREATE TABLE users_from_csv AS SELECT * FROM read_csv_auto('path/to/your/file.csv')
''')
进阶功能
- 与Pandas集成
import pandas as pd# 创建一个Pandas DataFrame
df = pd.DataFrame({'id': [3, 4],'name': ['Charlie', 'David'],'age': [35, 40]
})# 将DataFrame插入到DuckDB中
con.execute('CREATE TABLE users_from_df AS SELECT * FROM df')
- 查询结果转换为Pandas DataFrame
# 将查询结果转换为Pandas DataFrame
df_result = con.execute('SELECT * FROM users').df()
print(df_result)
- 读取Parquet文件
# 读取Parquet文件
con.execute('''CREATE TABLE users_from_parquet AS SELECT * FROM read_parquet('path/to/your/file.parquet')
''')
高级教程
- 高级SQL查询
# 使用DuckDB进行复杂的SQL查询
con.execute('''SELECT age, COUNT(*)FROM usersGROUP BY ageHAVING COUNT(*) > 1
''').fetchall()
- 创建索引
虽然DuckDB不需要显式地创建索引,但你可以通过创建主键或唯一约束来优化查询性能。
# 创建唯一约束
con.execute('''CREATE TABLE unique_users (id INTEGER PRIMARY KEY,name VARCHAR UNIQUE)
''')
- 扩展DuckDB功能
DuckDB支持多种扩展,例如,使用Python UDFs(用户自定义函数)来扩展其功能。
# 定义一个Python函数
def add_one(x):return x + 1# 注册这个函数到DuckDB
con.create_function('add_one', add_one)# 使用这个函数在SQL查询中
con.execute('SELECT add_one(age) FROM users').fetchall()
总结
DuckDB是一个功能强大且灵活的内嵌数据库,适合数据分析和处理。通过本文介绍的基础功能、进阶功能和高级教程,开发者可以轻松上手并熟练运用DuckDB进行各种数据操作。更多详细信息和示例请参考官方文档。
这篇关于DuckDB的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!