本文主要是介绍NetSuite Saved Search 之 Filter By Summary,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在某些业务场景中,用户需要一个TOP X的报表。例如,过去一段时间内,最多数量的事务处理类型。这就需要利用Saved Search中的Filter By Summary功能。
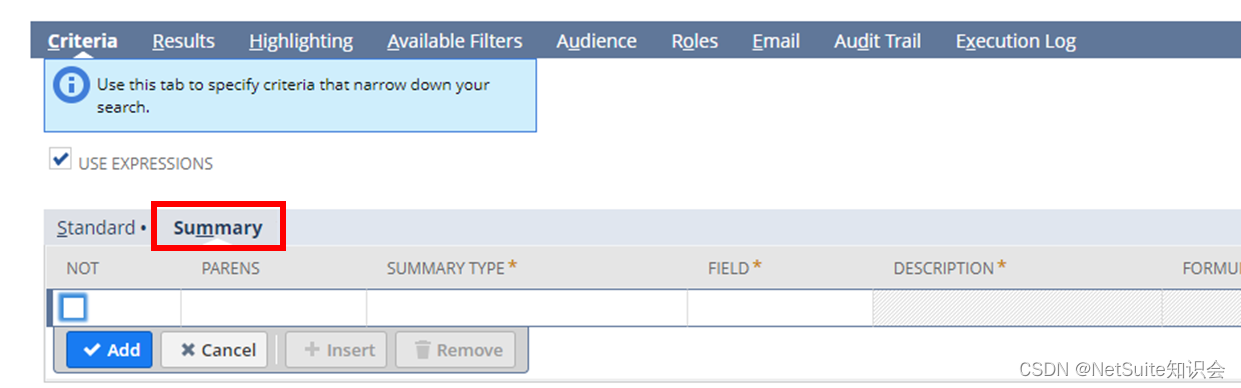
这在Criteria下的Summary页签里可以定义。其作用是对Result中Summary类型的结果进行过滤。也就是利用Summary类型的Criteria去过滤Summary类型的Result。举例来说,所谓Top X一定是在Result中按照某个Group来Count嘛,只是Count出来的结果从1到X都存在,我们只需要Top的几个,所以需要在Criteria中滤掉那些尾部的量。
下面举个例子。
场景
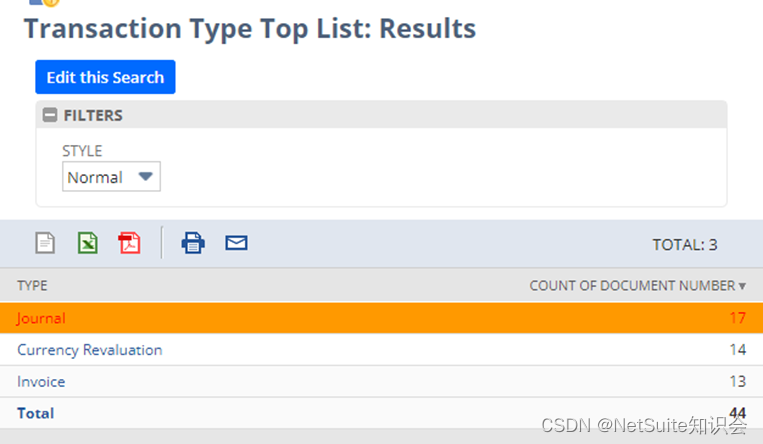
统计一下Top 3的事务处理类型。把最多的一种事务处理类型高亮显示。
Saved Search定义
1. 首先,在Results中定义Summary Type为Count的事务处理数量。

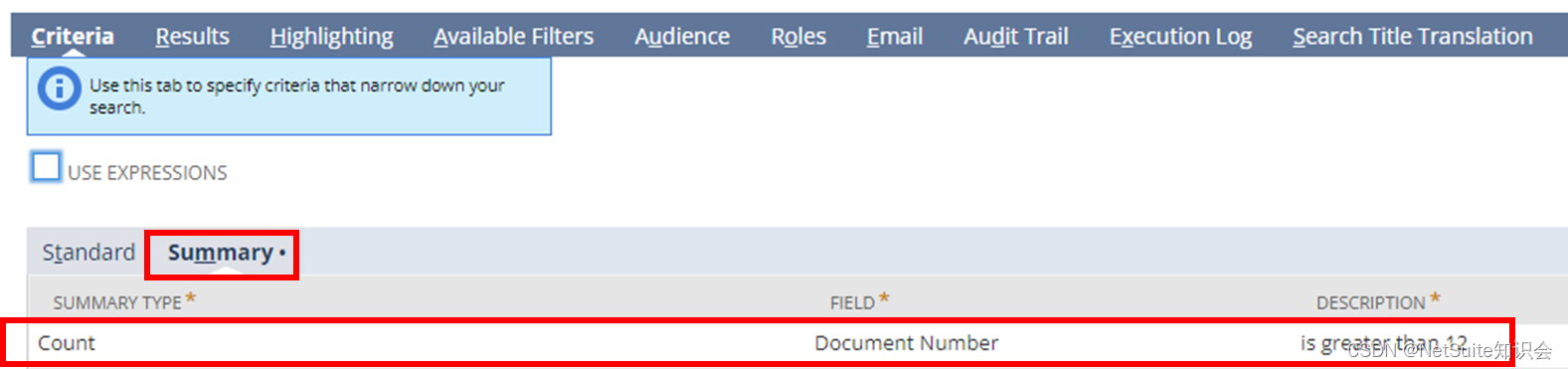
2. 在Criteria的Summary与之对应设置。需要相同的Summary Type(Count),相同的字段(Document Number。关键是“条件”,这里设为大于12。也就是过滤掉事务处理数量在12及以下的事务处理类型。
3. 在Highlighting中,一样要通过Summary条件来定义在什么条件下高亮显示。

结果
如果有任何关于NetSuite的问题,欢迎来谈。邮箱:service@truston.group
这篇关于NetSuite Saved Search 之 Filter By Summary的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







