本文主要是介绍c++编程(18)——deque的模拟实现(2)容器篇,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
欢迎来到博主的专栏——c++编程
博主ID:代码小豪
文章目录
- deque的数据结构
- deque的构造
- 默认构造
- 填充构造
- deque的其他操作
- deque的插入、删除
- push_back和push_front
- pop_back和pop_front
- clear、erase和insert操作
- 传送门
在上一篇中,我们已经实现了deque最核心的部分,即deque的迭代器,在deque容器当中,迭代器充当了非常重要的角色,在deque的大多数操作当中,都是对迭代器进行操作
deque的数据结构
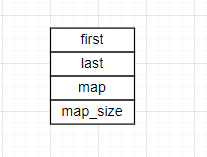
回到deque容器,我们知道deque的成员有以下几个
- 迭代器first,指向首元素
- 迭代器last,指向末尾元素的后一个
- 中控数组map,管理缓冲区
- 中控数组个数mapsize,管理缓冲区个数’
deque的构造
我们先来看看如何构造一个空的deque容器,即deque的默认构造。
一个未初始化的deque是这样的
如何初始化出一个空的deque容器呢?首先我们要为map分配出多个未使用的缓冲区,然后初始化出map的中间部分的缓冲区,并将first和last迭代器指向缓冲区的中间位置。
为什么一定要用map的中间部分呢?在前面我们已经讲过了,deque是一个双端队列,那么deque必须要做到头尾插入,如果我们不选择中间部分作为初始空间,那么deque会出现某一端的效率变低。
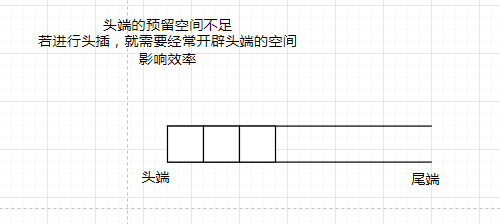
所以正确的方式应该是在中间部分进行初始化

我们先为map配置好缓冲区,并且安排好deque的结构,将这部分的操作写成一个函数,命名为CreateMapAndNode。意思是创建中控数组,并且生成缓冲区(注意这个函数会经常出现在deque的构造当中)。
void CreateMapAndNode(size_t elementNum)
{size_t nodeNum = elementNum / bufsize + 1;//判断待使用的缓冲区有几个mapsize = nodeNum < 8 ? 8 : nodeNum + 2;//预留缓冲区,提高效率map = new pointer[mapsize];//开辟mapsize个缓冲区//计算出[nstart,nfinish]的区间map_poniter nstart = map + (mapsize - (elementNum / bufsize)) / 2;map_poniter nfinsh = nstart + nodeNum - 1;//初始化这个区间map_poniter tmp = nstart;while (tmp <= nfinsh){*tmp = new T[bufsize];//生成缓冲区tmp++;}//初始化迭代器strat和finish,使得这两个迭代器指向deque的起始地址和结尾地址start.setnode(nstart);finish.setnode(nfinsh);start.cur = start.first;finish.cur = finish.first + (elementNum % bufsize);
}
先来解释一下这个函数中出现的几个重要参数吧。
(1)elementNum,为deque容器初始化的元素个数。(2)nodeNum,初始化这些元素个数需要多少个缓冲区(3)nstart,nfinish,这是一个区间的两个边界,[nstart,nfinsh]是这些元素所在的缓冲区区间。
要注意CreateNodeAndMap是一个只在为deque容器初始化的时候才能用,即只会出现在deque的构造函数当中。因此这个函数的行为其实就是一个初始化的行为,因此不会有插入元素的操作。只是开辟map和缓冲区的空间。
这个函数的逻辑是有点复杂的,博主在这里进行按照顺序梳理一下。
- 先确定deque会初始化多少个元素
- 确定这些元素会占据多少个缓冲区,缓冲区个数=elementNum/bufsize+1
- 为map开辟空间,为了避免频繁扩容导致的时间开销,我们要为map预留出一部分区间,因此可以看到,mapsize如果小于8,就预留8个缓冲区,如果mapsize的个数大于8,就多预留2个缓冲区
- [nstart,nfish]会处在中控数组的中间的区段,因为保持在中间,可以让头尾两端的扩充空间一样,保持头尾插入、删除的效率不变。
- 将[nstart,nfinsh]的空间开辟出来,便于后续插入数据。
默认构造
由于默认构造不需要插入任何数据,因此在调用CreateMapAndNode的时候不需要插入任何的数据,因此传入数据0即可
deque()
{CreateMapAndNode(0);
}
填充构造
填充构造就是在初始化deque容器时,向deque容器插入N个值为val的元素。
deque(size_t n, T val)
{CreateMapAndNode(n);//生成n个元素的空间map_poniter cur;for (cur = start.node; cur < finish.node; cur++){fill(*cur, *cur + bufsize, val);}fill(finish.first, finish.last, val);
}
template<class inputiterator,class T>
void fill(inputiterator first, inputiterator last, T val)
{while (first != last){*first = val;first++;}
}
这个fill的作用是将[first,last)区间内的所有元素都填充为val,放在填充构造当中,就是为缓冲区内的元素都填充为val。
deque的其他操作
iterator begin() { return start; }
iterator end() { return finish; }
T& front(){return *start;}T& back(){iterator tmp = finish;tmp--;return *tmp;
}
T& operator[](size_t pos){assert(pos < size())return *(start+pos);
}size_t size(){return finish - start;}
bool empty() { return finish == start; }
当我们为deque设计好begin(),end()之后,我们可以用范围for(range for)来遍历整个deque。
void testmydeque()
{deque<int> dq1(5, 10);for (auto& e : dq1){cout << e << " ";//10 10 10 10 10 }cout << dq1.front() << endl; //10cout << dq1.back() << endl;//10cout << dq1[5] << endl;//error pos>=size()
}
后续不再提供测试案例,如果感兴趣可以去博主的代码仓库查看,链接将会放在文章末尾。
deque的插入、删除
push_back和push_front
我们先来完成deque的pushback()和popback(),由于在插入的过程中可能会出现缓冲区空间不足的情况,此时我们就需要开辟新的缓冲区,来容纳这些数据。
void push_back(const T& val)
{if (finish.cur != finish.last-1)//判断是否来到了缓冲区边界{*finish = val;++finish;}else {//到达边界,需要开辟新的缓冲区ReserveMapAtBack();//判断一下是否需要在map的后端新增缓冲区*(finish.node + 1) = new T[bufsize];*finish = val;finish.setnode(finish.node + 1);finish.cur = finish.first;}
}
这里的pushback会对下面的三种情况进行不同的操作
情况1:当尾端的缓冲区还有剩余空间时
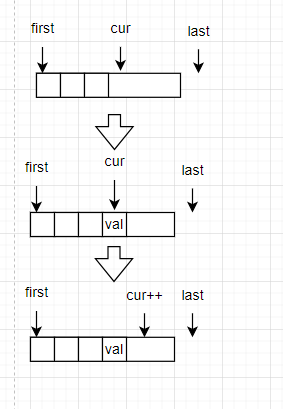
情况2,当缓冲区没有空间,但是map中还有多于的缓冲区
由于并不是map数组管理的所有缓冲区都开辟了空间,因为这可能会导致空间浪费的现象,所以deque采取的策略是,先为map获取多个缓冲区,为已使用的缓冲区开辟空间,盈余的缓冲区不开辟空间,秉承一个用一个缓冲区开一个缓冲区的原则。
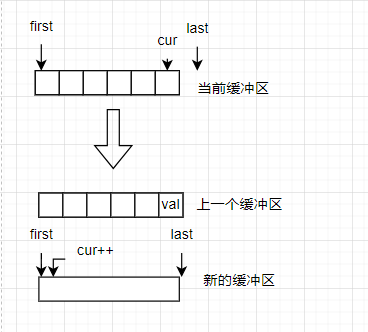
有没有发现deque在尾插时,插入的位置在末尾迭代器finish的上一个,这是由于c++规定STL中的末尾迭代器必须保持[begin,end)的区间,即容器的的末尾迭代器指向的是有效数据的后一位。
情况三:当缓冲区的剩余空间不足,并且map没有多于的后端缓冲区时。
此时需要将重新生成一个map,这个map可以管理更多的缓冲区,接着再将原map的元素转移到新map上。

这个操作我们交给了ReserveMapAtBack()函数。它会判断我们是否需要再尾端添加新的缓冲区。
void ReserveMapAtBack(size_t AddNode = 1)
{if (AddNode > mapsize - (finish.node - map-1))reallocmap(AddNode, false);
}
AddNode是要增加的缓冲区个数。如果满足要增加的缓冲区个数。大于末端缓冲区的盈余个数,就要重新配置一个map。配置新map的操作我们使用reallocmap来实现。
由于不仅仅pushback会重新配置map,pushpop也会重新配置map,因此我们将realoocmap设计成可以在尾端重新配置,也能在头端重新配置。reallocmap函数如下:
void reallocmap(size_t AddNode,bool AllocAtFront)
{size_t oldnodes = finish.node - start.node + 1;//旧的有效缓冲区个数size_t newnodes = oldnodes + AddNode;//新的有效缓冲区个数map_poniter newstart;size_t newmapsize = mapsize+(mapsize > AddNode ? mapsize : AddNode) + 2;//新map的管理缓冲区个数map_poniter newmap = new pointer[newmapsize];//生成新的map数组//计算新的迭代器区间newstart = newmap + (newmapsize - newnodes) / 2+ (AllocAtFront ? AddNode:0);map_poniter newfinish = newstart + oldnodes - 1;copynode(start.node, finish.node + 1, newstart);//将旧缓冲区交给新的map管理delete[] map;//释放旧map//更改迭代器以及容器数据map = newmap;mapsize = newmapsize;start.setnode(newstart);finish.setnode(newfinish);
}
具体步骤如下
- 先计算旧缓冲区的个数
- 再计算新缓冲区的个数,新缓冲区个数=旧缓冲区个数+新增缓冲区个数
- 计算新的map的缓冲区
- 为新map开辟空间
- 计算新缓冲区的区间[newstart,newfinish]
- 将旧map的有效缓冲区交给新map管理
- 删除旧map
- 调整迭代器,以及deque的容器数据
copynode函数可以将数据拷贝到指定数据上。
template<class inputiterator, class outputiterator>
void copynode(inputiterator first, inputiterator last, outputiterator dest)
{while (first != last){*dest = *first;dest++;first++;}
}
pushfront()也可以复用这些函数,因此我们写起来会轻松很多。
void push_front(const T&val)
{if (start.cur != start.first){start--;*start = val;}else {ReserveMapAtFront();*(start.node - 1) = new T[bufsize];start--;*start = val;}
}
push_front也有三种情况,但是和push_back面临的问题类似,因此博主不多赘述了。
pop_back和pop_front
void pop_back()
{assert(!empty());//空容器不能调用pop_backif (finish.cur != finish.first){finish--;}else {delete[] finish.first;//释放缓冲区finish.setnode(finish.node - 1);finish.cur = finish.last - 1;}
}
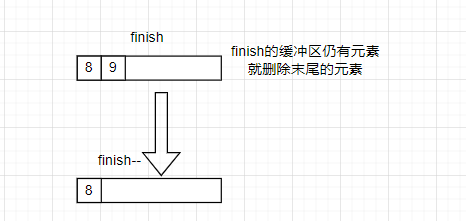
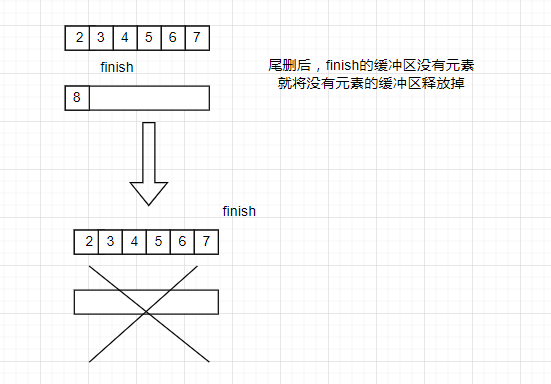
pop_back会出现两种情况。
- 如果尾删后缓冲区仍有元素(即first.cur!=first.first),就让迭代器指向上一个元素
- 如果尾删后缓冲区没有元素,为了继续贯彻用一个缓冲区开一个缓冲区的原则,就需要对没有元素的缓冲区进行释放。
pop_front的操作和pop_back比较类似,也是要判断缓冲区有没有剩余元素
void pop_front()
{assert(!empty());if (start.cur != start.last - 1){start++;}else{delete start.first;start.setnode(start.node + 1);start.cur = start.first;}
}
clear、erase和insert操作
void clear()
{for (map_poniter node = start.node; node <= finish.node; ++node)delete[] * node;//清除所有缓冲区//调整迭代器start和finishmap_poniter node = map + mapsize / 2;*node = new T[bufsize];start.setnode(node);start.cur = start.first;finish = start;
}
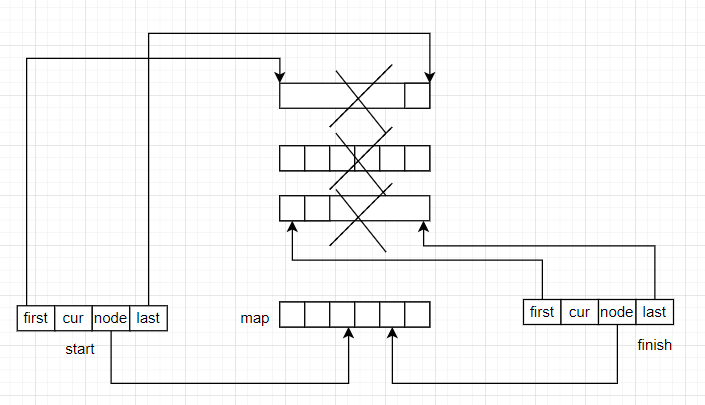
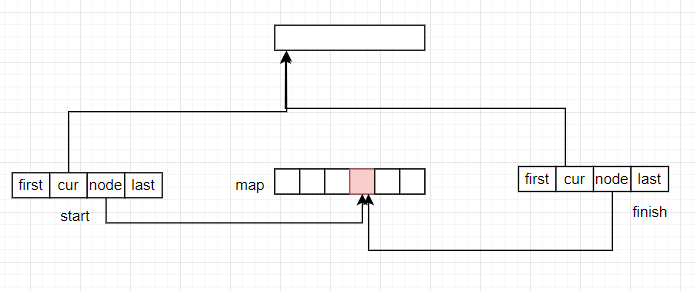
clear操作是清理deque容器的所有元素。具体操作如下:
- 释放当前的所有缓冲区
- 在map数组的中间部分开辟一个新的缓冲区,这个缓冲区为空
- 调整finish和start的迭代区间。

erase操作是删除pos迭代器指向位置的元素,代码如下:
iterator erase(iterator pos)
{iterator next = pos+1 ;int index = pos - start;//偏移量if (index < size() / 2){copyAtFront(start,pos,next);//从前往后拷贝pop_front();//删除前面的冗余元素}else {copy(next, finish, pos);//从后向前拷贝pop_back();}return start + index;
}
erase的步骤如下:
- 先计算偏移量,来判断这个删除的元素位于前半段还是后半段
- 如果元素处于后半段,就从后往前挪动数据,调用copy函数
- 如果元素 处于前半段,就从前往后挪动数据,调用coptAtFront函数
- 之所以要分前后半段,主要还是因为挪动的数据越少,效率越高。
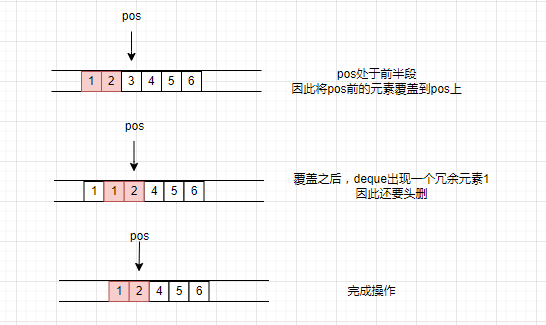
往前挪动的函数是copyAtFront,代码如下:
template<class inputiterator, class outputiterator>
void copyAtFront(inputiterator first,inputiterator last,outputiterator dest)//从后往前拷贝
{while (last != first){--last;--dest;*dest = *last;}
}
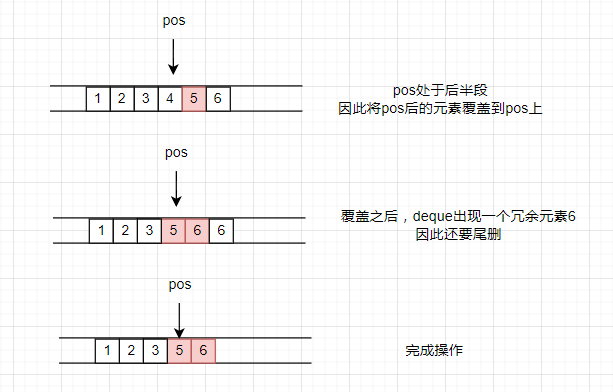
从后往前挪动的代码是copy,实际上这个copy和copynode的代码完全一样,可以用来复用,之所以写成两个不一样的名字,是因为博主希望在文中为其做一个区分,而博主的源代码中。copynode和copy都写成了同一个模板函数,写为copy。
template<class inputiterator, class outputiterator>
void copy(inputiterator first, inputiterator last, outputiterator dest)
{while (first != last){*dest = *first;dest++;first++;}
}
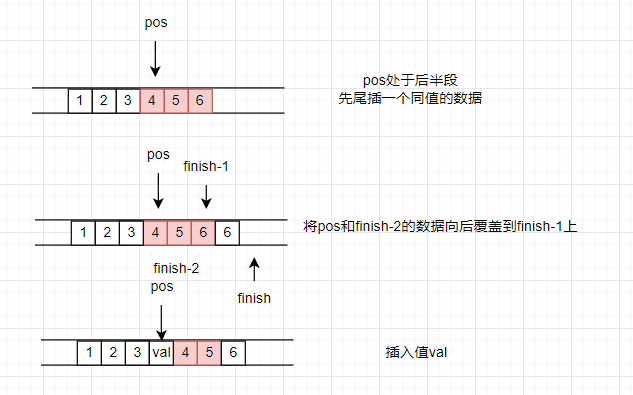
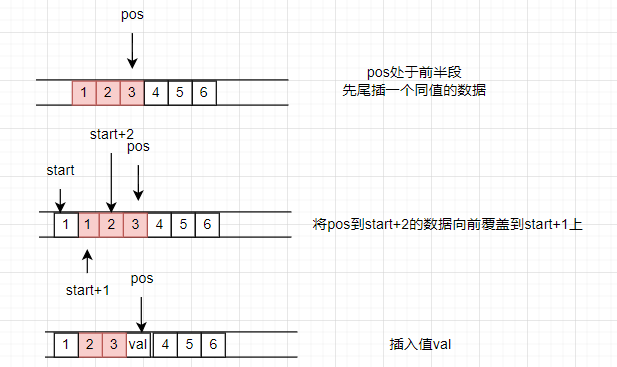
在pos位置上插入一个值为val的元素
iterator insert(iterator pos, const T& val)
{if (pos.cur == start.cur) {//如果插入在开头,交给push_frontpush_front(val);return start;}else if (pos.cur == finish.cur) {//如果插入在末尾,交个push_backpush_back(val);return finish - 1;}else {//插入在中间位置int index = pos - start;//计算偏移量if (index < size() / 2) {push_front(front());//最前端加上与第一个元素同值的元素pos = start + index;//标记一下,待会方便挪动数据iterator pos1 = pos;++pos1;copy(start+2, pos1, start+1);}else{push_back(back());//在尾端加上一个与最后一个元素同值的元素pos = start + index;copyAtFront(pos, finish-2, finish-1);}*pos = val;return pos;}
}
关于头插和尾插的方式博主就不赘述了,关键的点在于如何在中间插入,其实这与erase存在异曲同工之妙。
不要被各种变量吓到了,其实本质上就是为了挪动数据,让数据插入到pos位置中。
传送门
deque的模拟实现——迭代器篇:deque的模拟实现(1)迭代器篇
deque的模拟实现源码:deque的模拟实现源码
这篇关于c++编程(18)——deque的模拟实现(2)容器篇的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


