本文主要是介绍Postgre 调优工具pgBadger部署,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
一,简介:
pgBadger(日志分析器)类似于oracle的AWR报告(基于1小时,一天,一周,一月的报告),以图形化的方式帮助DBA更方便的找到隐含问题。
pgbadger是为了提高速度而构建的,具有来自pg日志文件的完整报告,他是一个小型的Perl脚本(linux需要安装perl),性能优于任何其他pg日志分析器。
pgBadger 可以自动检测日志文件格式( syslog、 stderr、 csvlog或 jsonlog)。它被设计用来解析巨大的日志文件和压缩文件。支持的压缩格式有gzip、bzip2、lz4、xz、zip和zstd。
还可以使用命令行选项将 pg Badger限制为仅报告错误或删除报告(可以自定义)的任何部分。
pgbadger支持在 postgresql. conf文件中通过 log_ line_ prefix自定义的任何格式,只要它至少指定%t和%p模式。
pgbadger允许通过使用指定CPU数量的j选项并行处理单个日志文件或多个文件。
如果要保存系统性能,也可以使用 log_ duration替代 og_min_ duration_statement来仅报告持续时间和查询数。
二,特性




三,报告模式
四,部署

perl Makefile.PL这个时候可能报一个错:

yum -y install perl-ExtUtils-MakeMaker再次执行perl Makefile.PL

make && make install
五,配置postgresql.conf配置
--目的只要是为了让pg主动收集日志,PG中的日志分为三种,log,clog,xlog,运行日志log默认不打开。



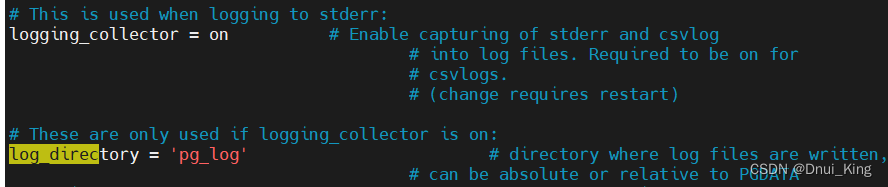


这个参数默认-1不记录,改成0,把所有sql语句记下来,如果改成30,则把慢于30ms的sql记下来,与慢sql原理相同。
根据提示修改后重启pg。

可以看到data目录下已经有了pg_log。
六,如何产生报告
方式一:当有许多小的日志文件和许多CPU时,一次将一个内核专用于ー个日志文件会更快要启用此行为,必须改用-N选项。对于每个10MB的200个日志文件,-J选项的使用开始变得非常有效,有8个内核。使用此方法,您将确保不会丢失报表中的任何查询。个在服务器上完成的基准测试,有8个CPU和9.5GB的单个文件。

可以看到,并行可以大量缩短产生分析日志时间。
方式二:产生大量日志,通过阐述log_rotation_size 参数控制,刚才在配置文件中已经配置过,意思就是到了10M就重新生成一个文件。

两种方式各有优缺点,我选用第二种方法,日志记录在我们自己定义的目录pg_log下。

每次登录和执行sql语句都会被记下来(和oracle种的enable_ddl_logging感觉差不多)

产生报告:产生一个小时的报告(可以选中不同日志产生不同时间段内的报告)pgbadger -q /usr/local/pgsql/data/pg_log/postgresql-2024-06-16_05*.log \-o /home/postgres/www/pg_reports/day-06-16-05.html产生每日和每周的日志报告:pgbader -I -q /usr/local/pgsql/data/pg_log/* \-O /home/postgres/www/pg_reports/ \-f stderr在这种模式下, pgbadger将在输出目录中创建一个自动增量文件。这意味着可以在每周旋转的日志文上每天以这种模式运行 pgbadger,并且它不会对日志条目计数两次可以使用 crontab进行定时运行。


也可以给他指定并行,加快分析流程:
给8个cpu并行分析:
pgbadger -j 8 -q /usr/local/pgsql/data/pg_log/postgresql-2024-06-16_05*.log \-o /home/postgres/www/pg_reports/day-06-16-05.html
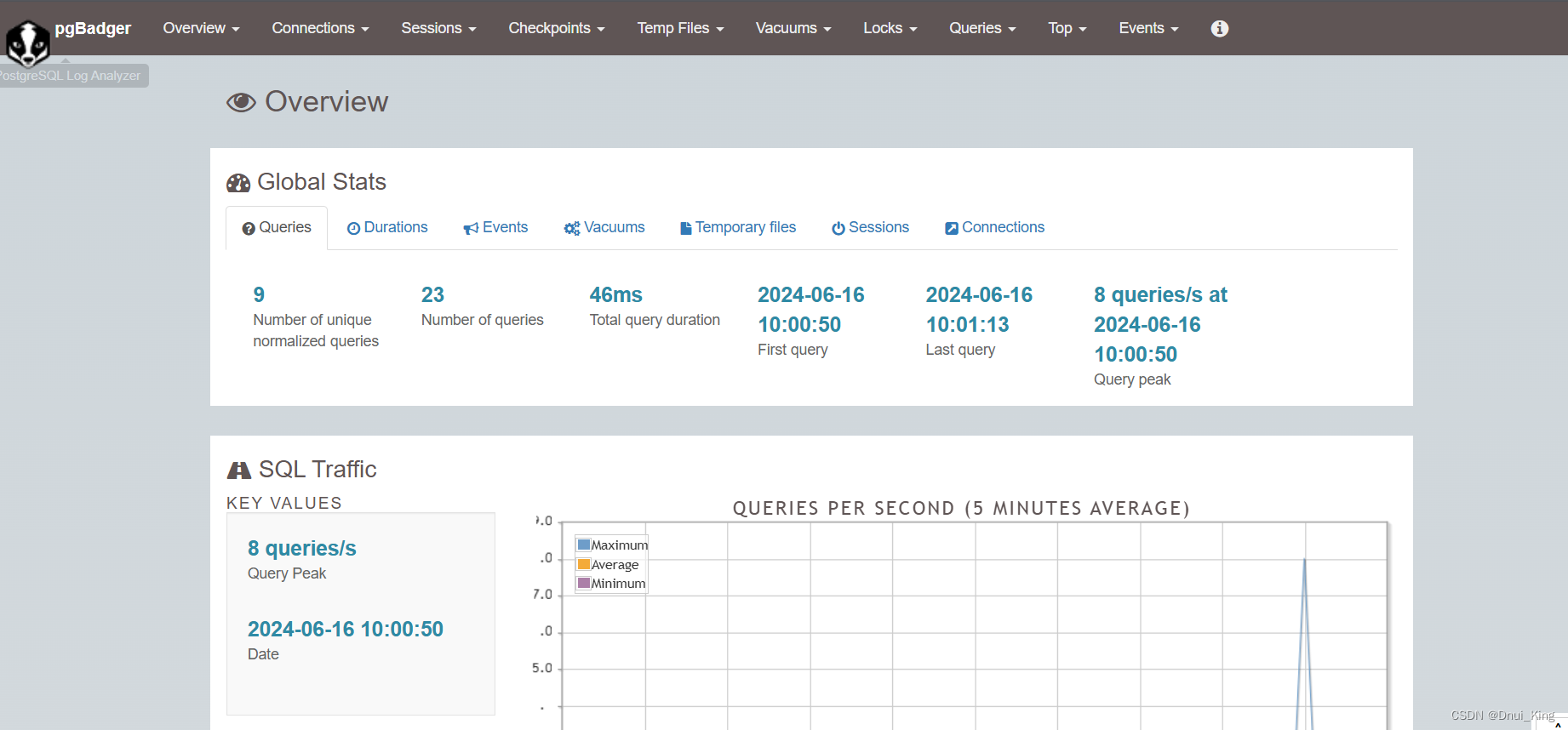
看一下界面:这个数据库并没有用过,所以生成是空的

写几个语句再看看
这篇关于Postgre 调优工具pgBadger部署的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!






