本文主要是介绍分类模型部署-ONNX,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
分类模型部署-ONNX
- 0 引入:
- 1 模型部署实战测试:
- 1 安装配置环境:
- 2 Pytorch图像分类模型转ONNX-ImageNet1000类
- 3 推理引擎ONNX Runtime部署-预测单张图像:
- 2 扩展阅读
- 参考
0 引入:
在软件工程中,部署指把开发完毕的软件投入使用的过程,包括环境配置、软件安装等步骤。类似地,对于深度学习模型来说,模型部署指让训练好的模型在特定环境中运行的过程。相比于软件部署,模型部署会面临更多的难题:
- 运行模型所需的环境难以配置。深度学习模型通常是由一些框架编写,比如 PyTorch、TensorFlow。由于框架规模、依赖环境的限制,这些框架不适合在手机、开发板等生产环境中安装。
- 深度学习模型的结构通常比较庞大,需要大量的算力才能满足实时运行的需求。模型的运行效率需要优化。
因为这些难题的存在,模型部署不能靠简单的环境配置与安装完成。经过工业界和学术界数年的探索,模型部署有了一条流行的流水线: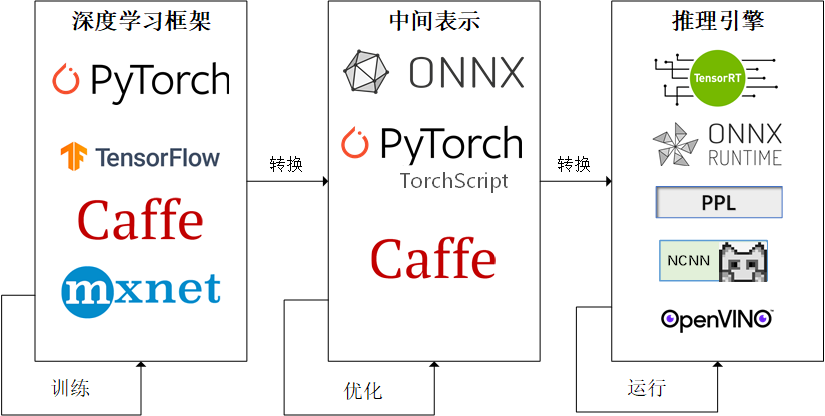
为了让模型最终能够部署到某一环境上,开发者们可以使用任意一种深度学习框架来定义网络结构,并通过训练确定网络中的参数。之后,模型的结构和参数会被转换成一种只描述网络结构的中间表示,一些针对网络结构的优化会在中间表示上进行。最后,用面向硬件的高性能编程框架(如 CUDA,OpenCL)编写,能高效执行深度学习网络中算子的推理引擎会把中间表示转换成特定的文件格式,并在对应硬件平台上高效运行模型。
这一条流水线解决了模型部署中的两大问题:使用对接深度学习框架和推理引擎的中间表示,开发者不必担心如何在新环境中运行各个复杂的框架;通过中间表示的网络结构优化和推理引擎对运算的底层优化,模型的运算效率大幅提升。
1 模型部署实战测试:
这里以部署流水线: Pytorch-ONNX-ONNX Runtime/TensorRT 为流程,进行测试:
流程:分类模型,转成onnx,onnxRuntime部署;
这里以部署分类模型为例,参考同济子豪兄:
1 安装配置环境:
torch
torchvision
onnx
onnxruntime
numpy
pandas
matplotlib
tqdm
opencv-python
pillow
2 Pytorch图像分类模型转ONNX-ImageNet1000类
把Pytorch预训练ImageNet图像分类模型,导出为ONNX格式,用于后续在推理引擎上部署。
导入工具包:
import torch
from torchvision import models# 有 GPU 就用 GPU,没有就用 CPU
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
print('device', device)
载入与训练pytorch图像分类模型:
model = models.resnet18(pretrained=True)
model = model.eval().to(device)
构建一个输入Tensor:
x = torch.randn(1, 3, 256, 256).to(device)
输入pytorch模型推理预测,获得1000个类别的预测结果:
output = model(x)
output.shape
torch.Size([1, 1000])
pytorch模型转onnx格式:
with torch.no_grad():torch.onnx.export(model, # 要转换的模型x, # 模型的任意一组输入'resnet18_imagenet.onnx', # 导出的 ONNX 文件名opset_version=11, # ONNX 算子集版本input_names=['input'], # 输入 Tensor 的名称(自己起名字)output_names=['output'] # 输出 Tensor 的名称(自己起名字))
验证onnx模型导出成功:
import onnx# 读取 ONNX 模型
onnx_model = onnx.load('resnet18_imagenet.onnx')# 检查模型格式是否正确
onnx.checker.check_model(onnx_model)print('无报错,onnx模型载入成功')
以可读的形式打印计算图:
print(onnx.helper.printable_graph(onnx_model.graph))
graph main_graph (%input[FLOAT, 1x3x256x256]
) initializers (%fc.weight[FLOAT, 1000x512]%fc.bias[FLOAT, 1000]%onnx::Conv_193[FLOAT, 64x3x7x7]%onnx::Conv_194[FLOAT, 64]%onnx::Conv_196[FLOAT, 64x64x3x3]%onnx::Conv_197[FLOAT, 64]%onnx::Conv_199[FLOAT, 64x64x3x3]%onnx::Conv_200[FLOAT, 64]%onnx::Conv_202[FLOAT, 64x64x3x3]%onnx::Conv_203[FLOAT, 64]%onnx::Conv_205[FLOAT, 64x64x3x3]%onnx::Conv_206[FLOAT, 64]%onnx::Conv_208[FLOAT, 128x64x3x3]%onnx::Conv_209[FLOAT, 128]%onnx::Conv_211[FLOAT, 128x128x3x3]%onnx::Conv_212[FLOAT, 128]%onnx::Conv_214[FLOAT, 128x64x1x1]%onnx::Conv_215[FLOAT, 128]%onnx::Conv_217[FLOAT, 128x128x3x3]%onnx::Conv_218[FLOAT, 128]%onnx::Conv_220[FLOAT, 128x128x3x3]%onnx::Conv_221[FLOAT, 128]%onnx::Conv_223[FLOAT, 256x128x3x3]%onnx::Conv_224[FLOAT, 256]%onnx::Conv_226[FLOAT, 256x256x3x3]%onnx::Conv_227[FLOAT, 256]%onnx::Conv_229[FLOAT, 256x128x1x1]%onnx::Conv_230[FLOAT, 256]%onnx::Conv_232[FLOAT, 256x256x3x3]%onnx::Conv_233[FLOAT, 256]%onnx::Conv_235[FLOAT, 256x256x3x3]%onnx::Conv_236[FLOAT, 256]%onnx::Conv_238[FLOAT, 512x256x3x3]%onnx::Conv_239[FLOAT, 512]%onnx::Conv_241[FLOAT, 512x512x3x3]%onnx::Conv_242[FLOAT, 512]%onnx::Conv_244[FLOAT, 512x256x1x1]%onnx::Conv_245[FLOAT, 512]%onnx::Conv_247[FLOAT, 512x512x3x3]%onnx::Conv_248[FLOAT, 512]%onnx::Conv_250[FLOAT, 512x512x3x3]%onnx::Conv_251[FLOAT, 512]
)
也可以使用netron可视化模型结构: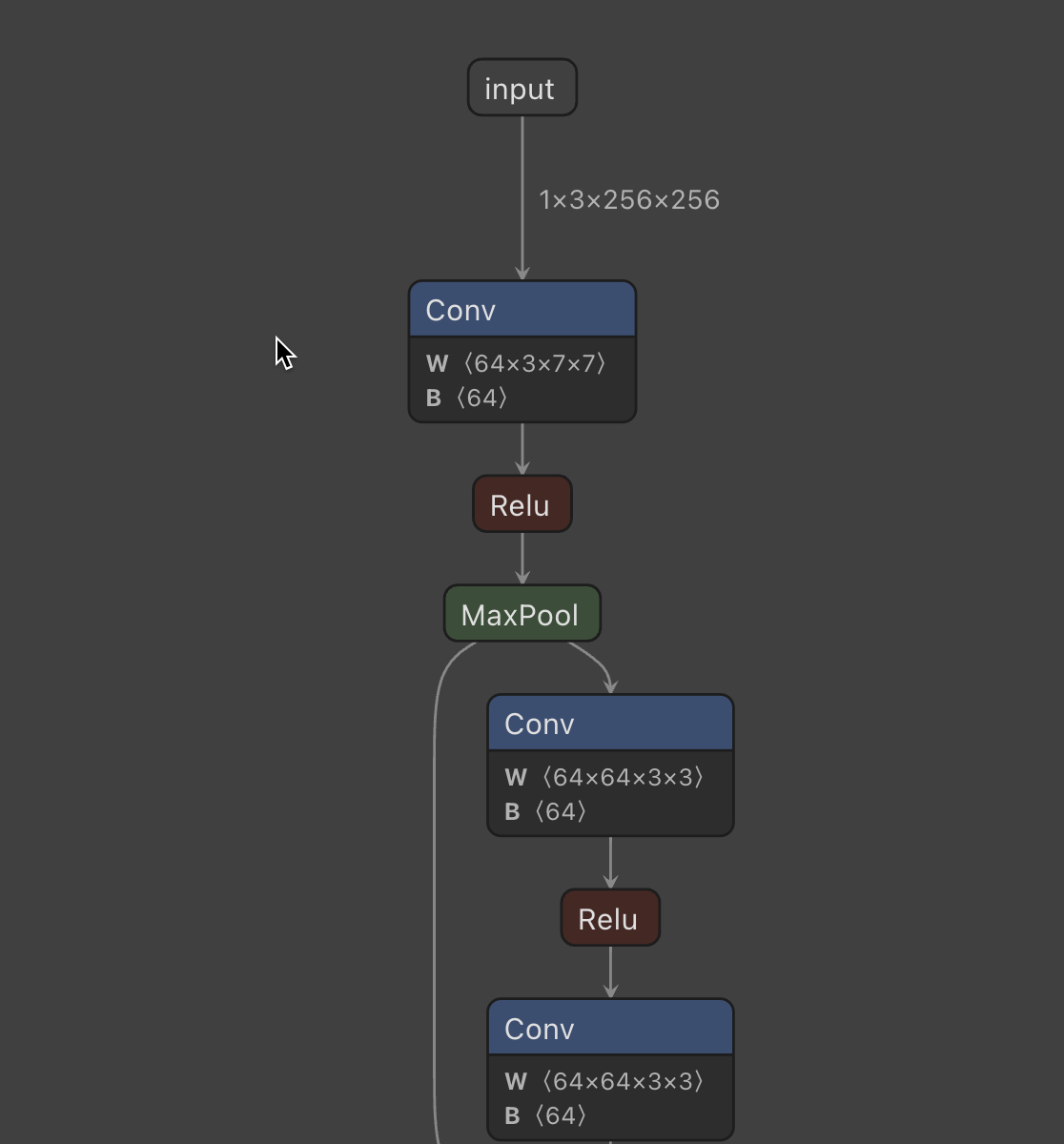
3 推理引擎ONNX Runtime部署-预测单张图像:
使用推理引擎,ONNX Runtime,读取 ONNX 格式的模型文件,对单张图像文件进行预测。
应用场景:
以下代码在需要部署的硬件上运行(本地PC、嵌入式开发板、树莓派、Jetson Nano、服务器)
只需把`onnx`模型文件发到部署硬件上,并安装 ONNX Runtime 环境,用下面几行代码就可以运行模型了。
导入工具包:
import onnxruntime
import numpy as np
import torch
import torch.nn.functional as Fimport pandas as pd
载入Onnx模型,获取 ONNX Runtime 推理器
ort_session = onnxruntime.InferenceSession('resnet18_imagenet.onnx')
构造随机输入,获取输出结果:
x = torch.randn(1, 3, 256, 256).numpy()
x.shape
# onnx runtime 输入
ort_inputs = {'input': x}# onnx runtime 输出
ort_output = ort_session.run(['output'], ort_inputs)[0]
注意,输入输出张量的名称需要和 torch.onnx.export 中设置的输入输出名对应
ort_output.shape
(1, 3, 256, 256)
(1, 1000)
载入真实图片预处理;
img_path = 'banana1.jpg'# 用 pillow 载入
from PIL import Image
img_pil = Image.open(img_path)from torchvision import transforms#预处理
# 测试集图像预处理-RCTN:缩放裁剪、转 Tensor、归一化
test_transform = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(256),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])input_img = test_transform(img_pil)
input_img.shape
input_tensor = input_img.unsqueeze(0).numpy()
input_tensor.shape推理预测:
# ONNX Runtime 输入
ort_inputs = {'input': input_tensor}# ONNX Runtime 输出
pred_logits = ort_session.run(['output'], ort_inputs)[0]
pred_logits = torch.tensor(pred_logits)
pred_logits.shape
# 对 logit 分数做 softmax 运算,得到置信度概率
pred_softmax = F.softmax(pred_logits, dim=1)
pred_softmax.shape
解析结果:将数字映射到物品种类上:
# 取置信度最高的前 n 个结果
n = 3
top_n = torch.topk(pred_softmax, n)
top_n# 预测类别
pred_ids = top_n.indices.numpy()[0]
pred_ids# 预测置信度
confs = top_n.values.numpy()[0]载入类别ID和类别名称对应关系:
df = pd.read_csv('imagenet_class_index.csv')
idx_to_labels = {}
for idx, row in df.iterrows():idx_to_labels[row['ID']] = row['class'] # 英文
# idx_to_labels[row['ID']] = row['Chinese'] # 中文
打印预测结果:
for i in range(n):class_name = idx_to_labels[pred_ids[i]] # 获取类别名称confidence = confs[i] * 100 # 获取置信度text = '{:<20} {:>.3f}'.format(class_name, confidence)print(text)
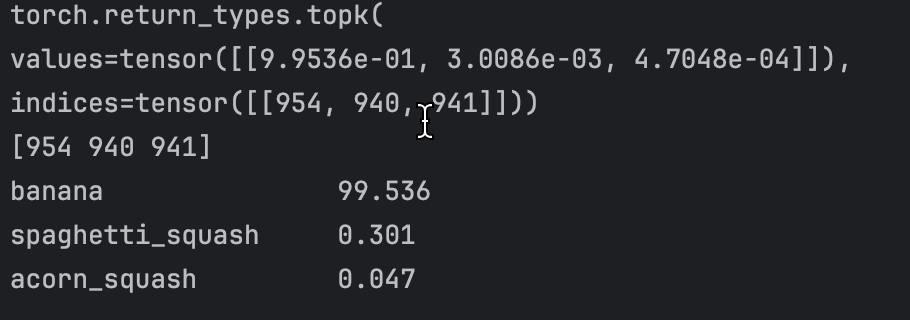
imagenet_class_index.csv
2 扩展阅读
ONNX主页: https://onnx.ai
ONNX Github主页: https://github.com/onnx/onnx
ONNX支持的深度学习框架:https://onnx.ai/supported-tools.html
ONNX支持的计算平台:https://onnx.ai/supported-tools.html
ONNX算子:https://onnx.ai/onnx/operators
模型在线可视化网站 Netron:https://netron.app
Netron视频教程:https://www.bilibili.com/video/BV1TV4y1P7AP
周奕帆博客:
模型部署入门教程(一):模型部署简介
https://zhuanlan.zhihu.com/p/477743341
模型部署入门教程(二):解决模型部署中的难题
https://zhuanlan.zhihu.com/p/479290520
模型部署入门教程(三):PyTorch 转 ONNX 详解
https://zhuanlan.zhihu.com/p/498425043
参考
https://mmdeploy.readthedocs.io/zh-cn/latest/tutorial/01_introduction_to_model_deployment.html
这篇关于分类模型部署-ONNX的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!





