本文主要是介绍跟着刘二大人学pytorch(第---12---节课之RNN基础篇),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 0 前言
- 0.1 课程视频链接:
- 0.2 课件下载地址:
- 1 Basic RNN
- 1.1 复习DNN和CNN
- 1.2 直观认识RNN
- 1.3 RNN Cell的内部计算方式
- 2 具体什么是一个RNN?
- 3 使用pytorch构造一个RNN
- 3.1 手动构造一个RNN Cell来实现RNN
- 3.2 直接使用torch中现有的RNN模块来实现RNN
- input维度
- h0维度
- output维度
- hn维度
- numLayers的解释
- 代码注释
- 参数配置
- 模型构造
- 输入序列的构造
- 隐藏层的构造
- 输出的解释
- 最后一个隐藏层输出的解释
- 执行代码的结果
- 例子1:训练一个RNN 做seq2seq任务
- 第1步 字符向量化
- 参数配置
- 准备数据
- 设计模型
- 构造损失函数和优化器
- 设置训练Cycle
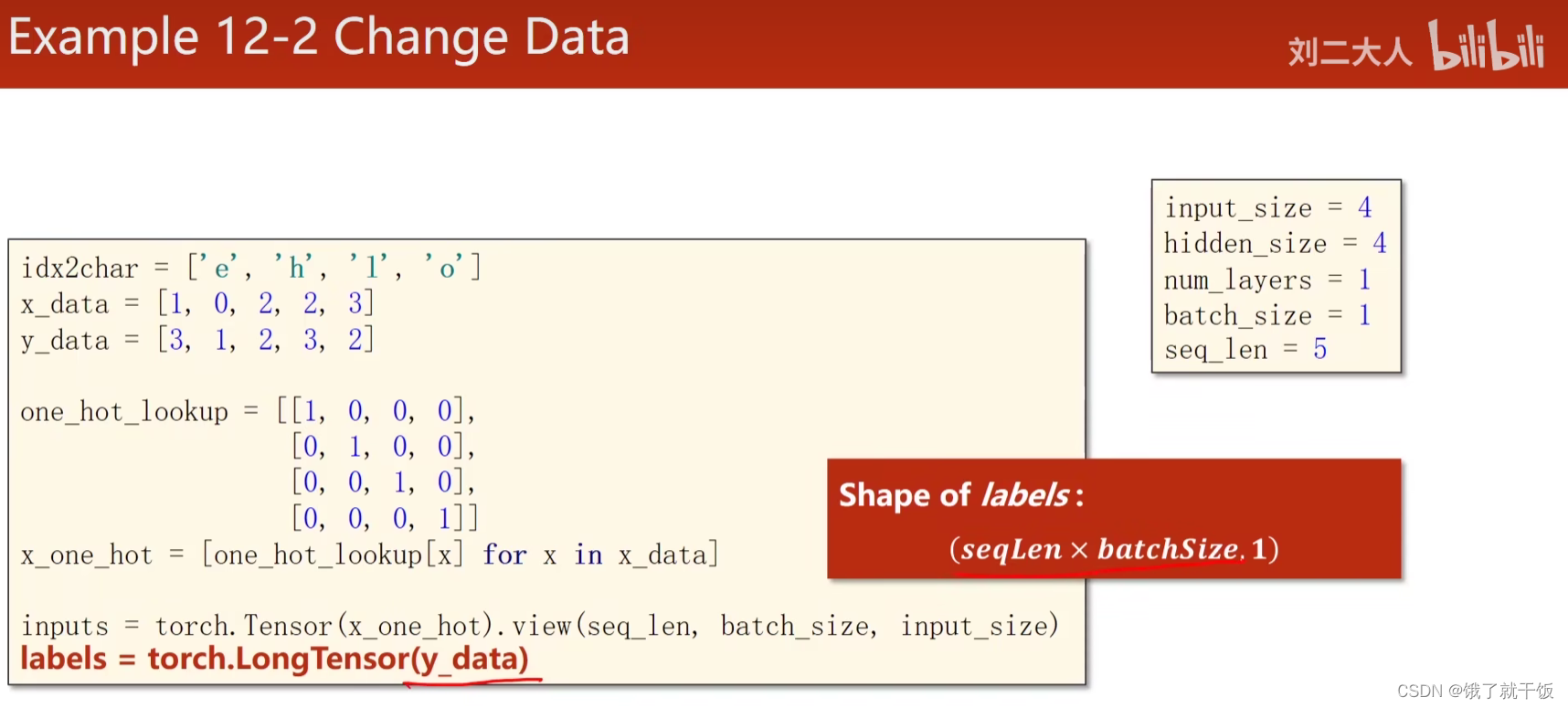
- 改变数据
- Embedding
- 例12-3 使用embedding和线性层的RNN
- 构造模型、损失函数、优化器
- 训练
- 练习1:LSTM
- 联系2:GRU
0 前言
0.1 课程视频链接:
《PyTorch深度学习实践》完结合集
大佬的笔记:大佬的笔记
pytorch=0.4
0.2 课件下载地址:
链接:https://pan.baidu.com/s/1_J1f5VSyYl-Jj2qIuc1pXw
提取码:wyhu
1 Basic RNN

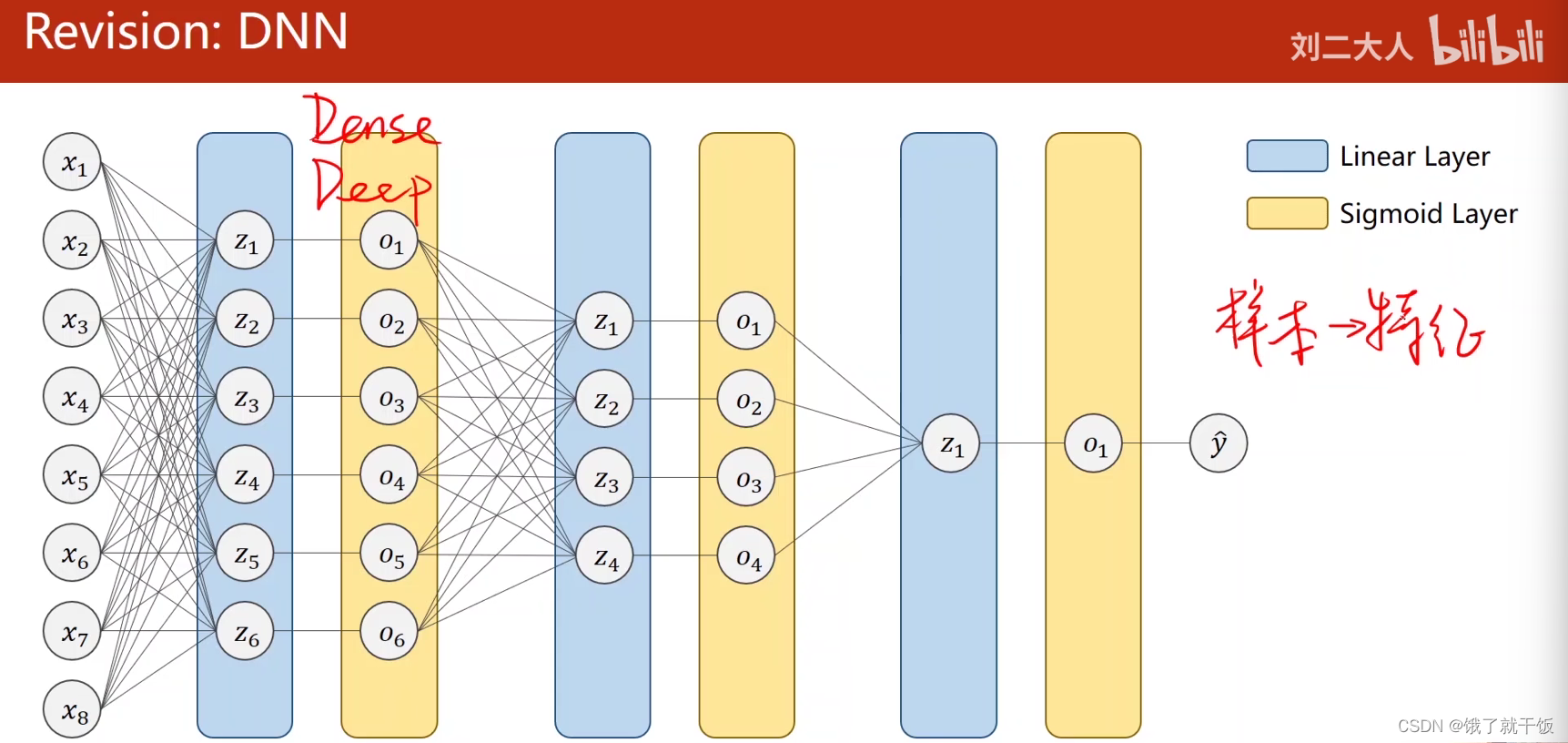
1.1 复习DNN和CNN
全连接网络也称为稠密网络,Dense Network,也称为Deep Neural Network
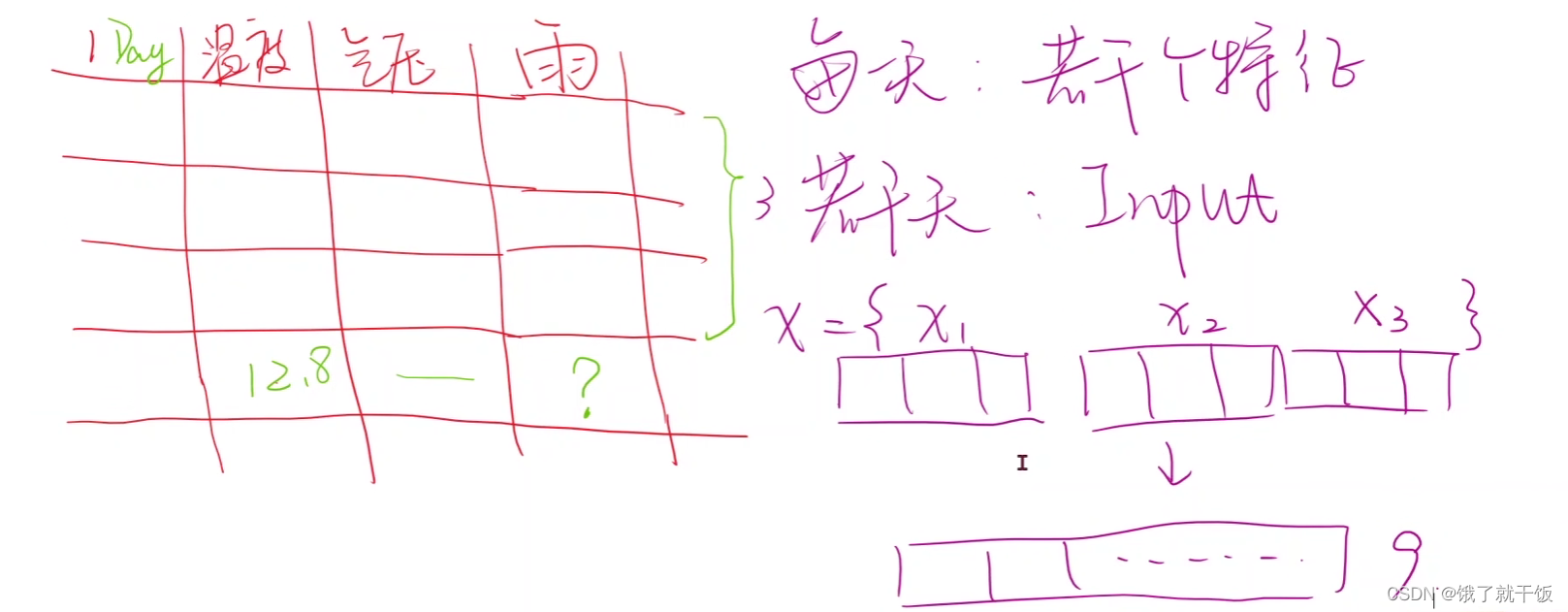
现在有一个表,里面的数据是每天每隔一个小时的天气数据,平均温度,气压,预测目标是是否下雨
根据某一时刻的温度和气压数据预测该时刻是否下雨,这件事情意义不太大,预测下雨这件事应提前进行预测。
我们需要若干天(如3天)的数据作为模型的输入,其中每一天的数据应该包含若干个(如3个)特征。
使用全连接进行预测。如果序列很长且x1,x2,x3的维度很高的话,这对网络的训练是一个很大的挑战,原因是全连接网络是稠密的网络,里面的权重是最多的。
CNN中输入通道是128,输出通道是64,使用的是5×5的卷积,权重为25×2^13=20w,
全连接层假设输入是4096,输出是1024,则全连接权重为4096*1024=420w,这样的比较CNN使用的参数要少得多
因此在使用神经网络时需要明确一点:全连接网络的参数在神经网络中所占的比例是最大的,所以之后计算存储、推理很大的瓶颈是来自全连接层
CNN中使用的参数为什么较少呢:有 权重共享的概念
假如在处理视频时,每一帧的图像如果都使用全连接网络去处理,那参数量将是天文数字,这种方法是不可行的
RNN是专门处理序列型的数据,也会使用权重共享的概念,减少需要训练的权重的数量
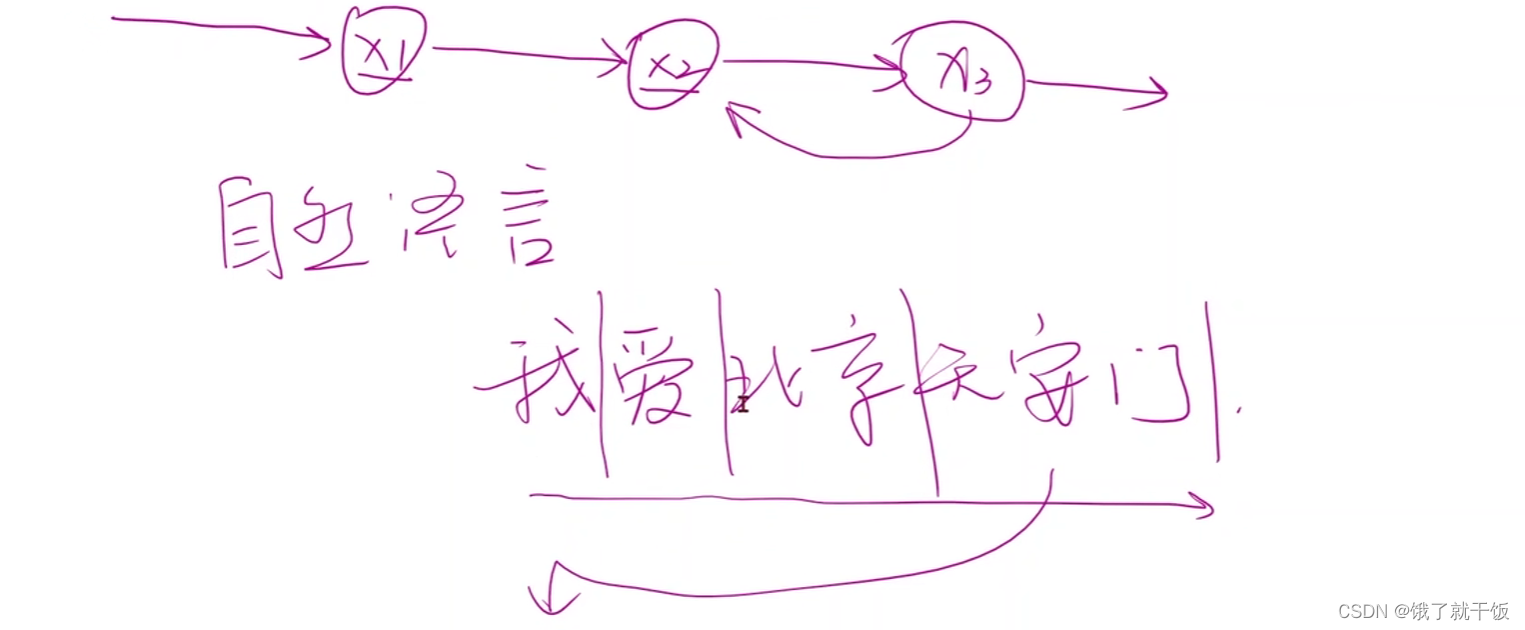
x1,x2,x3是一个序列,是有先后顺序,x2部分依赖x1,x3部分依赖x2,RNN来处理序列相关的数据,类似于语言、天气、股票
理解语言需要依赖文字的顺序
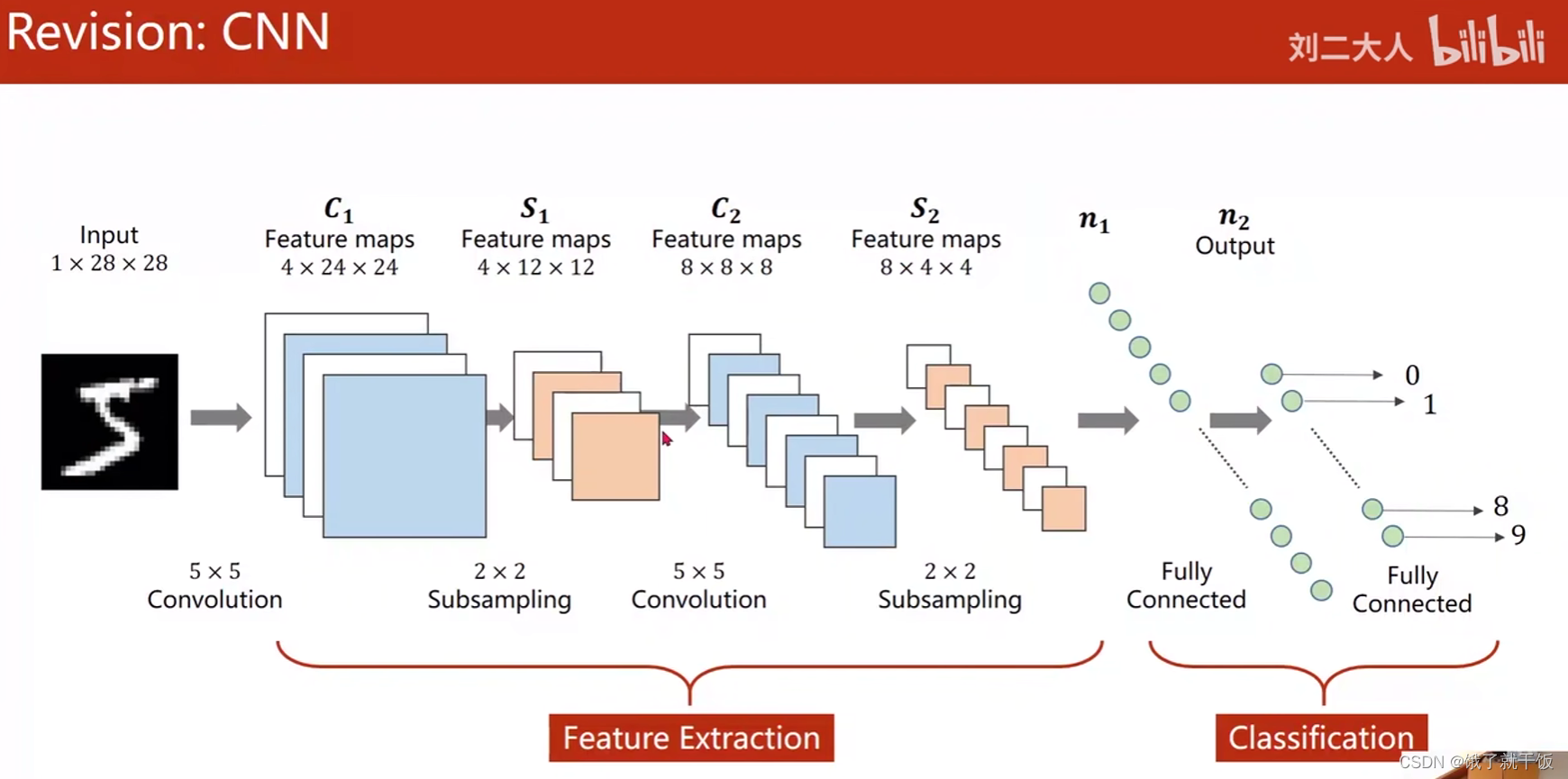
回顾一下CNN
1.2 直观认识RNN
例如输入xt的维度是3维的,经过RNN Cell之后输出的ht是5维的,那么RNN Cell本质上还是一个线性层,但是和普通的线性层的区别是RNN Cell这个线性层的权重是共享的。
h0是先验知识,如果有先验知识的话就需要将先验知识作为h0输入给RNN,如图生文本,CNN+FC处理图像,生成h0,再传给RNN,此时即可做“看图说话”
如果没有先验知识的话,直接将h0的维度设置为和ht的维度一样,然后设置成0向量即可。
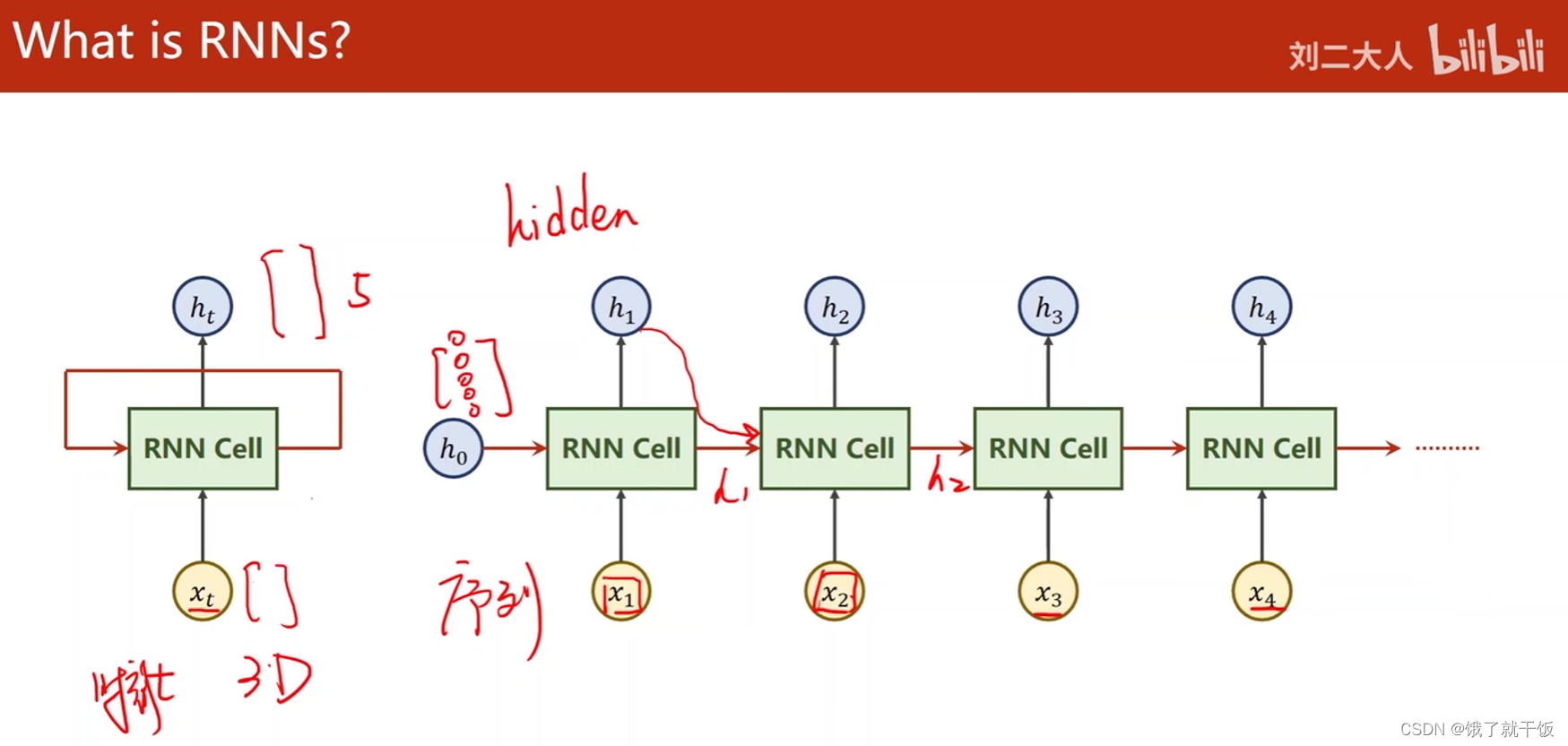
上图中的RNN Cell是同一个
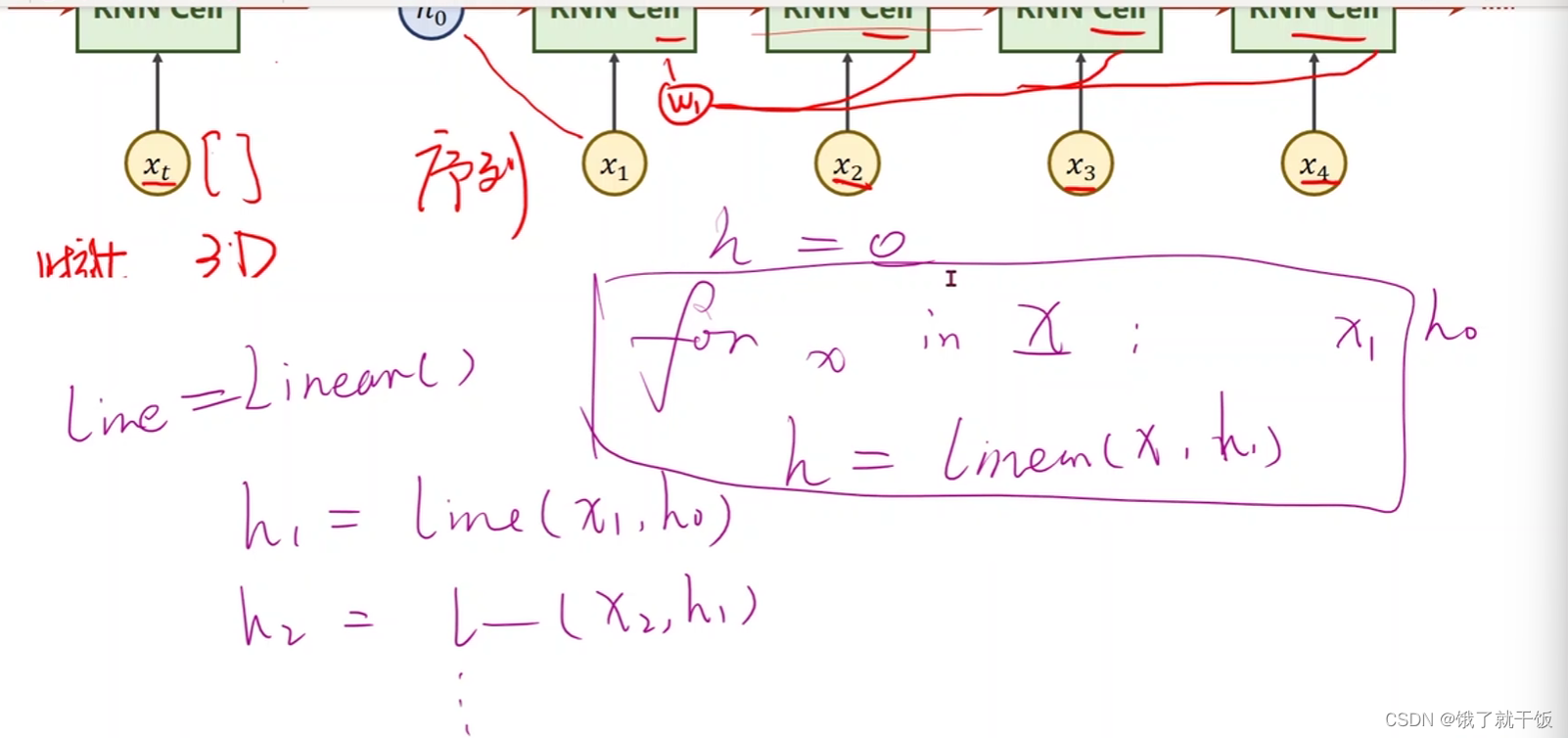
用代码来表示是上面这样的,x是需要从X中循环的
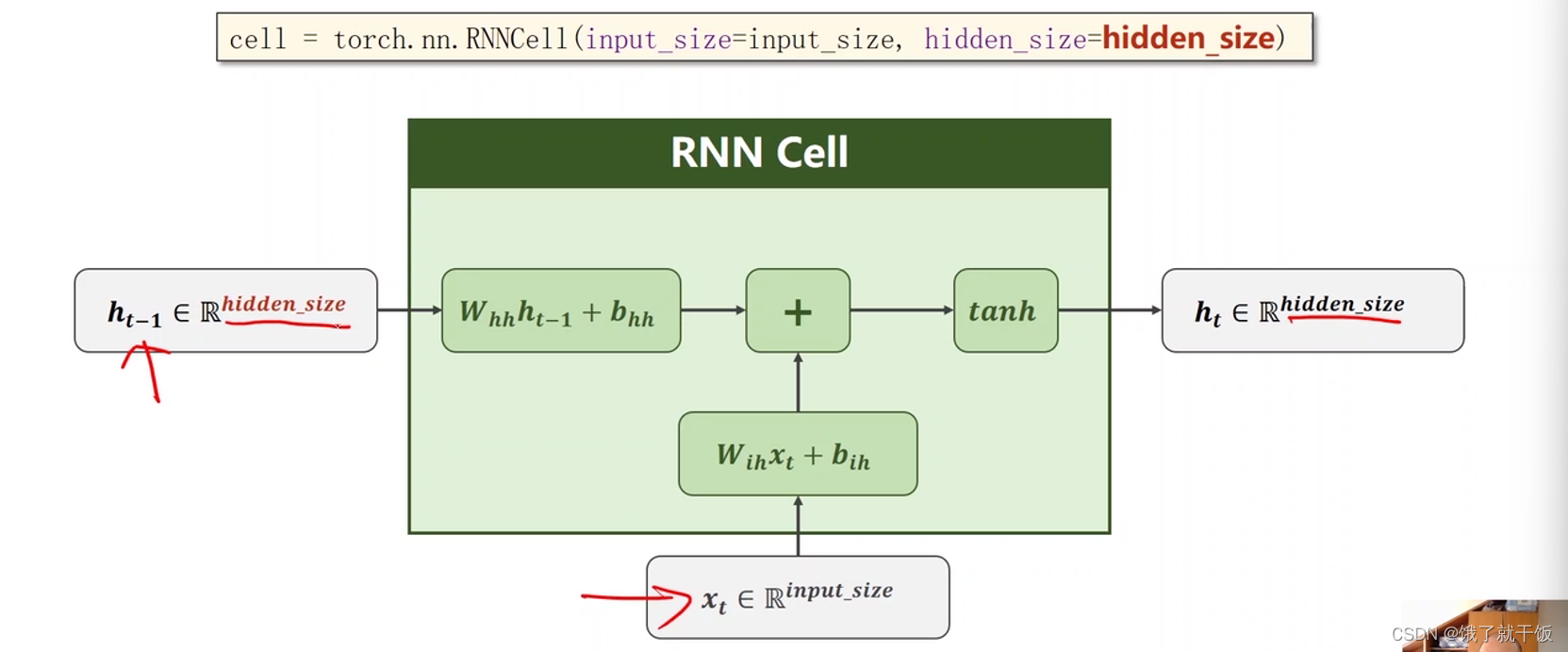
1.3 RNN Cell的内部计算方式
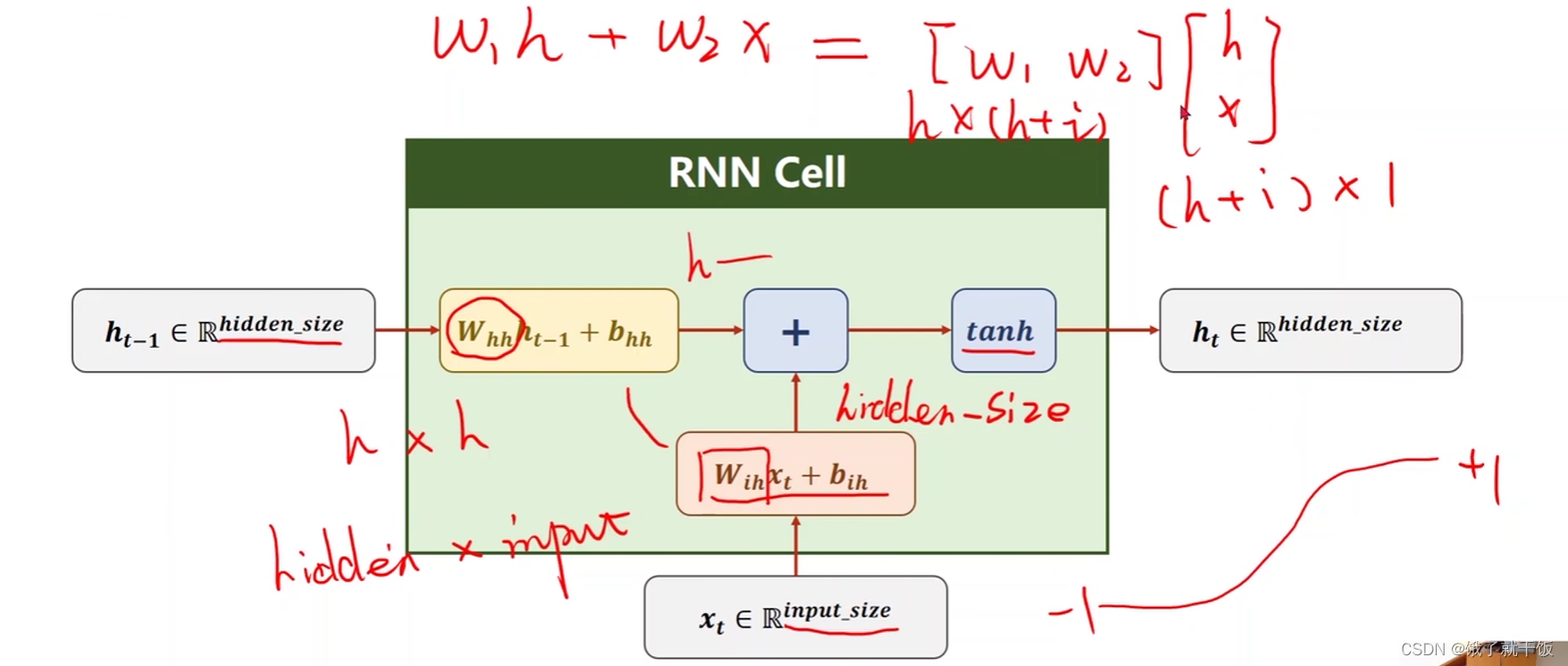
Whhht-1+bhh 和Wihxt+bih是两个线性层,他们可以合并成一个线性层,见上图的红色公式
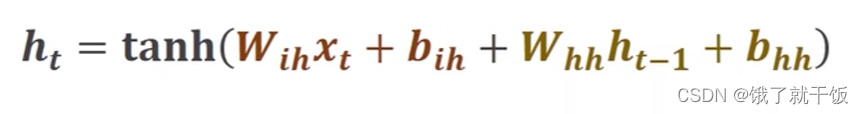
即上式可以简写。
2 具体什么是一个RNN?
把RNN Cell以循环的方法,把序列送进去,依次算出隐层的过程称为一个循环神经网络。
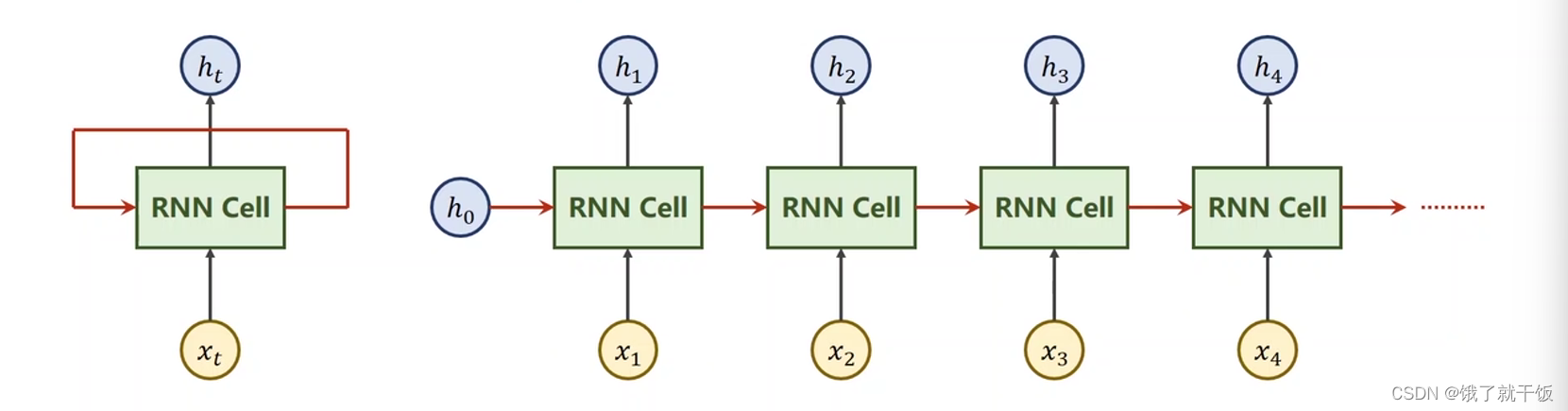
3 使用pytorch构造一个RNN
两种方法:1、自己构造RNN Cell,然后写来处理序列的循环 2、直接使用RNN
3.1 手动构造一个RNN Cell来实现RNN
创建一个Cell的方式
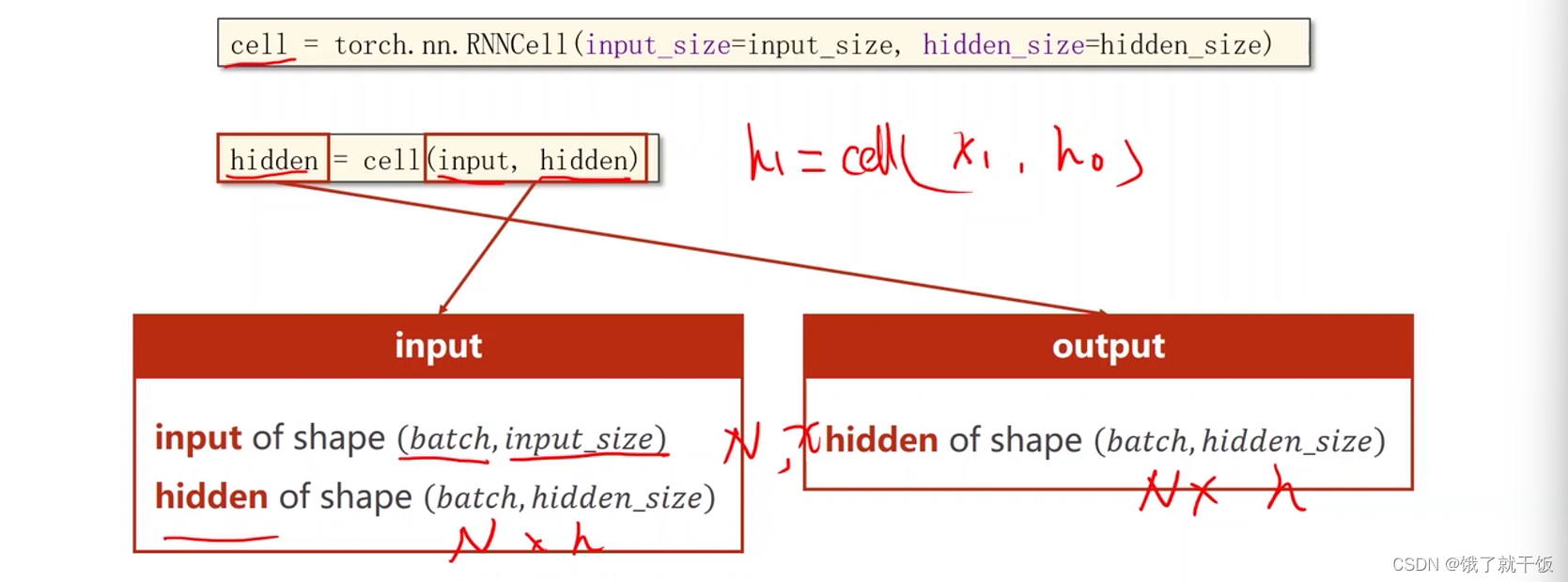
创建一个RNN Cell需要的参数:输入的维度,隐藏层的维度
构造完cell之后,一个cell的输入是x和上一个隐藏状态,两者的维度要求见下图
例如一个RNNCell的配置为

因此输入的构造见下图

隐藏状态的构造见下图

序列数据的维度的构造应该如下

代码:
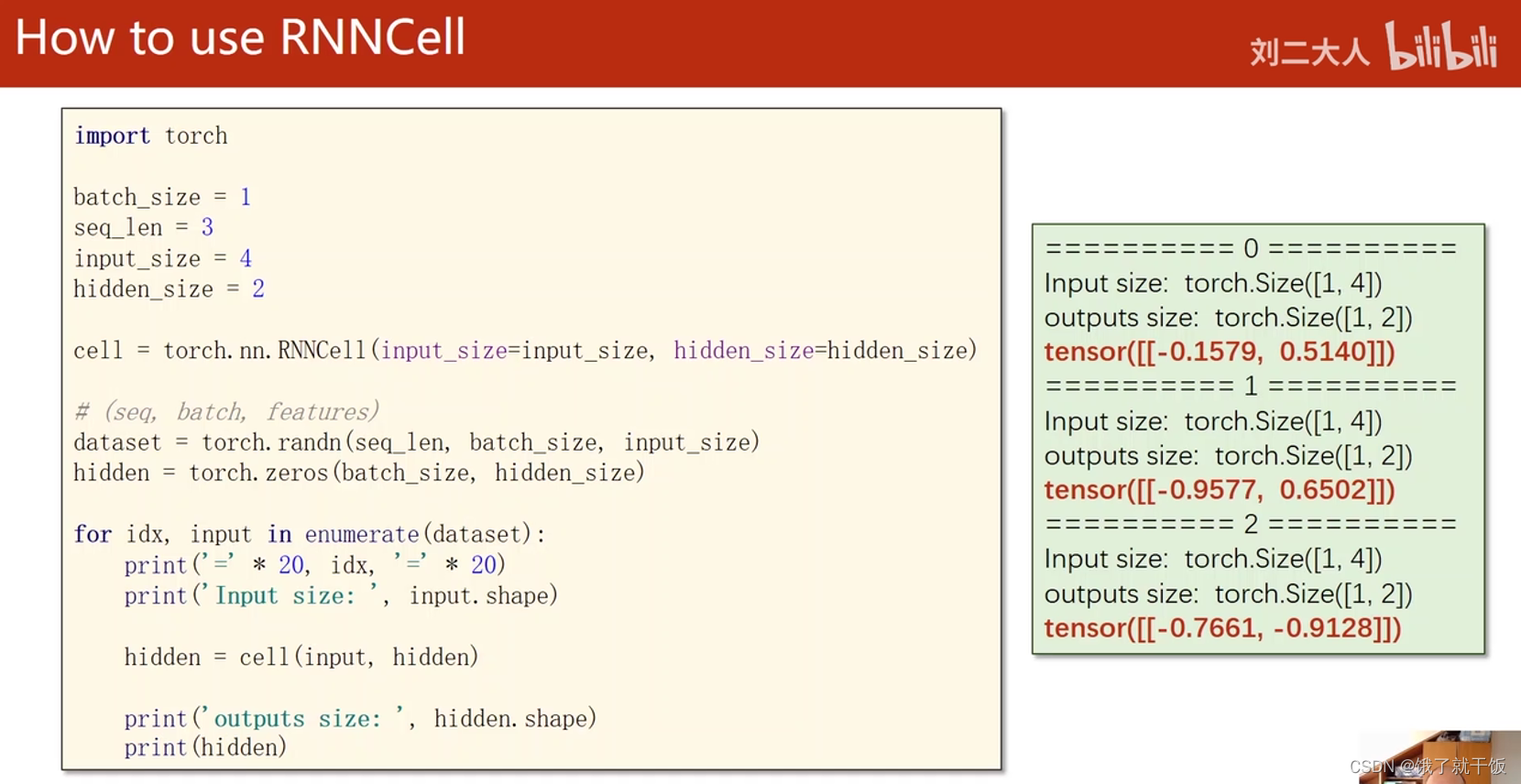
torch.randn用法:torch.randn()函数
示例代码:
import torch# 定义配置项
batch_size = 5
seq_len = 3
input_size = 4
hidden_size = 2# 构造一个RNN Cell
cell = torch.nn.RNNCell(input_size = input_size, hidden_size = hidden_size)print(cell)# 生成5个序列长度为3,每个token的为4的张量作为1个batch
dataset = torch.randn(seq_len, batch_size, input_size)
print(dataset)hidden = torch.zeros(batch_size, hidden_size)
print(hidden)for idx, input in enumerate(dataset):print("="*20, idx, "="*20)print("input size:", input.shape)hidden = cell(input, hidden)print("output size:", hidden.shape)print(hidden)
输出:
D:\Anaconda3\envs\env_pytorch04\python.exe "D:/000 简历/000 自己的项目/3 刘二教程/第12节课 手动定义一个RNN Cell.py"
RNNCell(4, 2)
tensor([[[ 0.4408, -0.7577, 0.9077, -0.0779],[ 0.5080, -0.1057, 0.5581, -0.4546],[ 0.8382, 1.3444, 1.1445, -2.0313],[ 0.4016, 1.0184, 0.0556, 0.6046],[ 1.9827, 0.6735, -0.6609, -0.0764]],[[-0.8133, -1.3837, -0.6933, -0.6390],[ 0.7617, -0.2478, -0.1682, -1.2478],[ 0.1389, -0.5334, 1.7906, 0.8992],[-0.7540, 0.0293, -0.5835, 1.0606],[-0.5817, 0.2823, -1.0507, 0.3087]],[[-0.5872, 0.1241, -0.2446, -0.5430],[-0.6749, 0.6816, -0.1754, -1.1233],[ 0.1708, -1.6483, 0.8012, 0.3567],[-0.1961, -1.0277, -0.2133, -0.7144],[-1.3309, 0.6177, 1.5205, -0.4169]]])
tensor([[0., 0.],[0., 0.],[0., 0.],[0., 0.],[0., 0.]])
==================== 0 ====================
input size: torch.Size([5, 4])
output size: torch.Size([5, 2])
tensor([[-0.2558, -0.4498],[-0.3951, 0.0840],[ 0.1652, 0.9352],[-0.8041, -0.1019],[-0.6620, 0.7436]], grad_fn=<TanhBackward0>)
==================== 1 ====================
input size: torch.Size([5, 4])
output size: torch.Size([5, 2])
tensor([[-0.8441, -0.6020],[-0.6114, 0.6291],[-0.3331, -0.8504],[-0.9706, -0.8207],[-0.9807, -0.4315]], grad_fn=<TanhBackward0>)
==================== 2 ====================
input size: torch.Size([5, 4])
output size: torch.Size([5, 2])
tensor([[-0.8825, -0.1003],[-0.9137, 0.3993],[-0.2900, -0.8324],[-0.7844, -0.2764],[-0.7202, -0.4915]], grad_fn=<TanhBackward0>)进程已结束,退出代码为 0
注意:输出中的下列张量,每一个块儿是一个batch,一个块儿是5个向量,表示1个batch是5个输入
tensor([[[ 0.4408, -0.7577, 0.9077, -0.0779],[ 0.5080, -0.1057, 0.5581, -0.4546],[ 0.8382, 1.3444, 1.1445, -2.0313],[ 0.4016, 1.0184, 0.0556, 0.6046],[ 1.9827, 0.6735, -0.6609, -0.0764]],[[-0.8133, -1.3837, -0.6933, -0.6390],[ 0.7617, -0.2478, -0.1682, -1.2478],[ 0.1389, -0.5334, 1.7906, 0.8992],[-0.7540, 0.0293, -0.5835, 1.0606],[-0.5817, 0.2823, -1.0507, 0.3087]],[[-0.5872, 0.1241, -0.2446, -0.5430],[-0.6749, 0.6816, -0.1754, -1.1233],[ 0.1708, -1.6483, 0.8012, 0.3567],[-0.1961, -1.0277, -0.2133, -0.7144],[-1.3309, 0.6177, 1.5205, -0.4169]]])
假如有数据集:
1、我爱你
2、我恨你
3、我吃了
4、我没吃
5、我饿了
。。。。还有其他数据
分词之后:
1、“我”,“爱”,“你”
2、“我”,“恨”,“你”
3、“我”,“吃”,“了”
4、“我”,“没”,“吃”
5、“我”,“饿”,“了”
…
每个词有各自的词向量
配置项中设置每个batch的大小是5,选择前5句话作为1个batch,每句话的序列长度都是3,其中每个词的维度都是4
则1个batch用数字表示就是
tensor([[[ 0.4408, -0.7577, 0.9077, -0.0779], # 我 【1】[ 0.5080, -0.1057, 0.5581, -0.4546], # 我 [ 0.8382, 1.3444, 1.1445, -2.0313], # 我[ 0.4016, 1.0184, 0.0556, 0.6046], # 我[ 1.9827, 0.6735, -0.6609, -0.0764]], # 我[[-0.8133, -1.3837, -0.6933, -0.6390], # 爱 【1】[ 0.7617, -0.2478, -0.1682, -1.2478], # 恨[ 0.1389, -0.5334, 1.7906, 0.8992], # 吃[-0.7540, 0.0293, -0.5835, 1.0606], # 没[-0.5817, 0.2823, -1.0507, 0.3087]], # 饿[[-0.5872, 0.1241, -0.2446, -0.5430], # 你 【1】[-0.6749, 0.6816, -0.1754, -1.1233], # 你[ 0.1708, -1.6483, 0.8012, 0.3567], # 了[-0.1961, -1.0277, -0.2133, -0.7144], # 吃 [-1.3309, 0.6177, 1.5205, -0.4169]]]) # 了
暂时忽略同一个词不同词向量这个问题,以上只示意
3.2 直接使用torch中现有的RNN模块来实现RNN
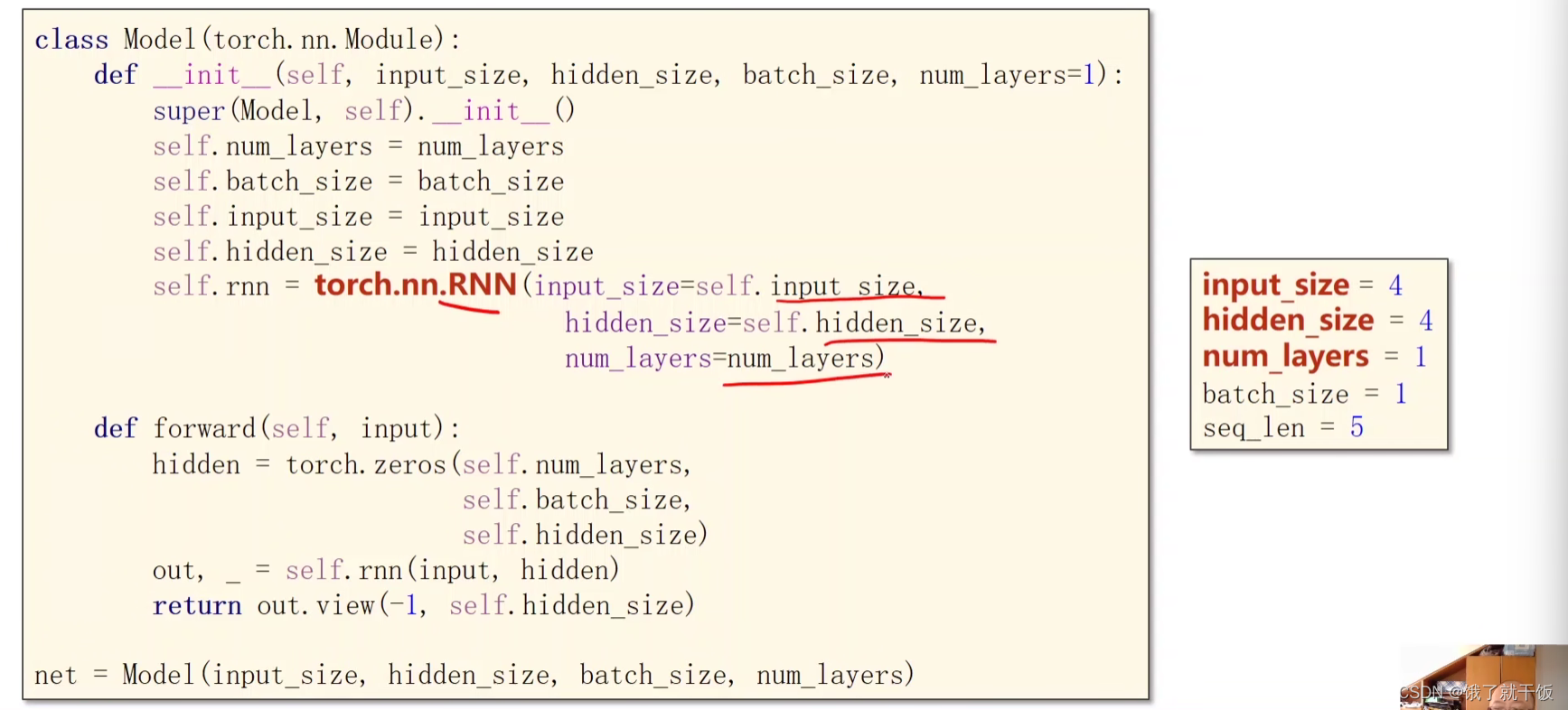
cell = torch.nn.RNN(input_size = inputsize, hidden_size = hidden_size, num_layers = num_layers)
num_layers可以设置RNN是多少层的,层数也不能选太多,因为比较耗时
out,hidden = cell(inputs,hidden)
inputs是包含整个输入序列,out就是输出的整个序列(h1,h2,…,hN),第1个hidden就是hN,第2个hidden就是h0,具体可以见下图
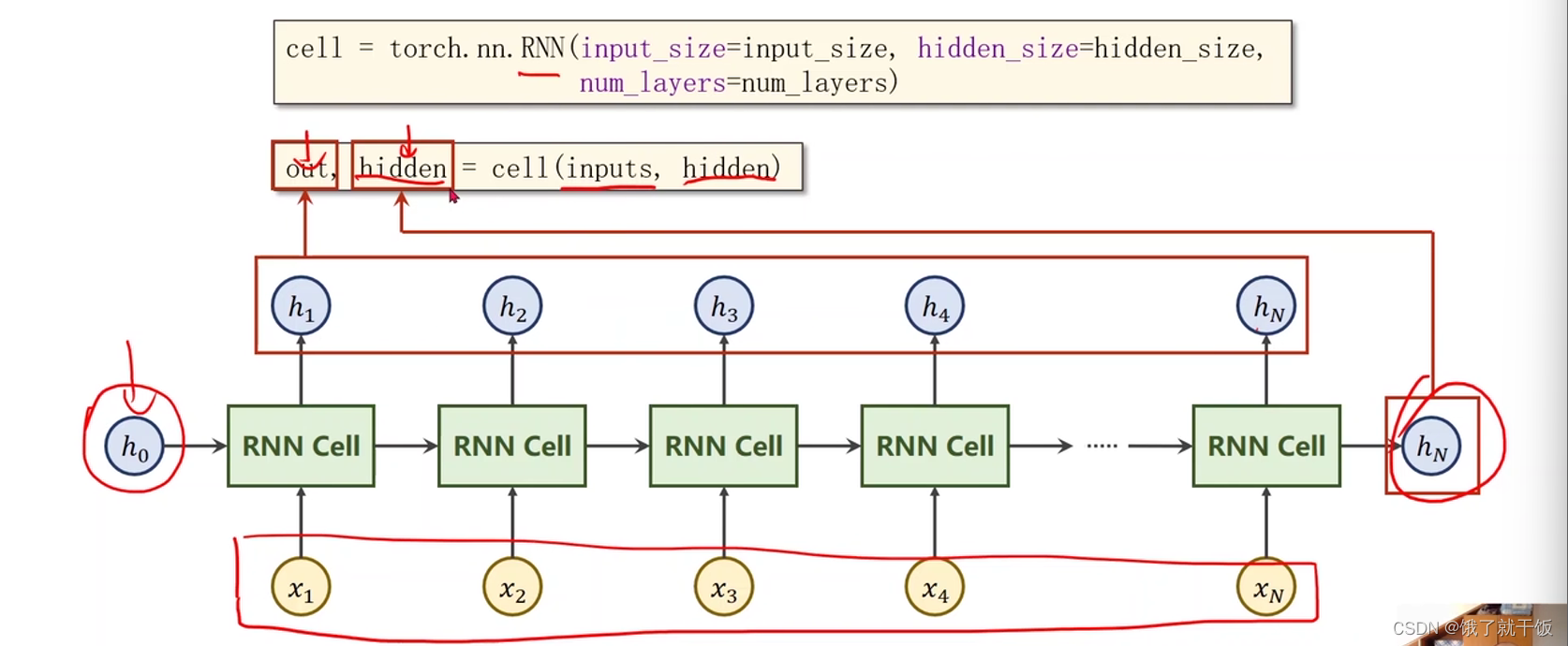
总结:上图中cell输入h0,x1,x2,…,xN,输出h1,h2,…,hN和hN
维度要求,见下图:

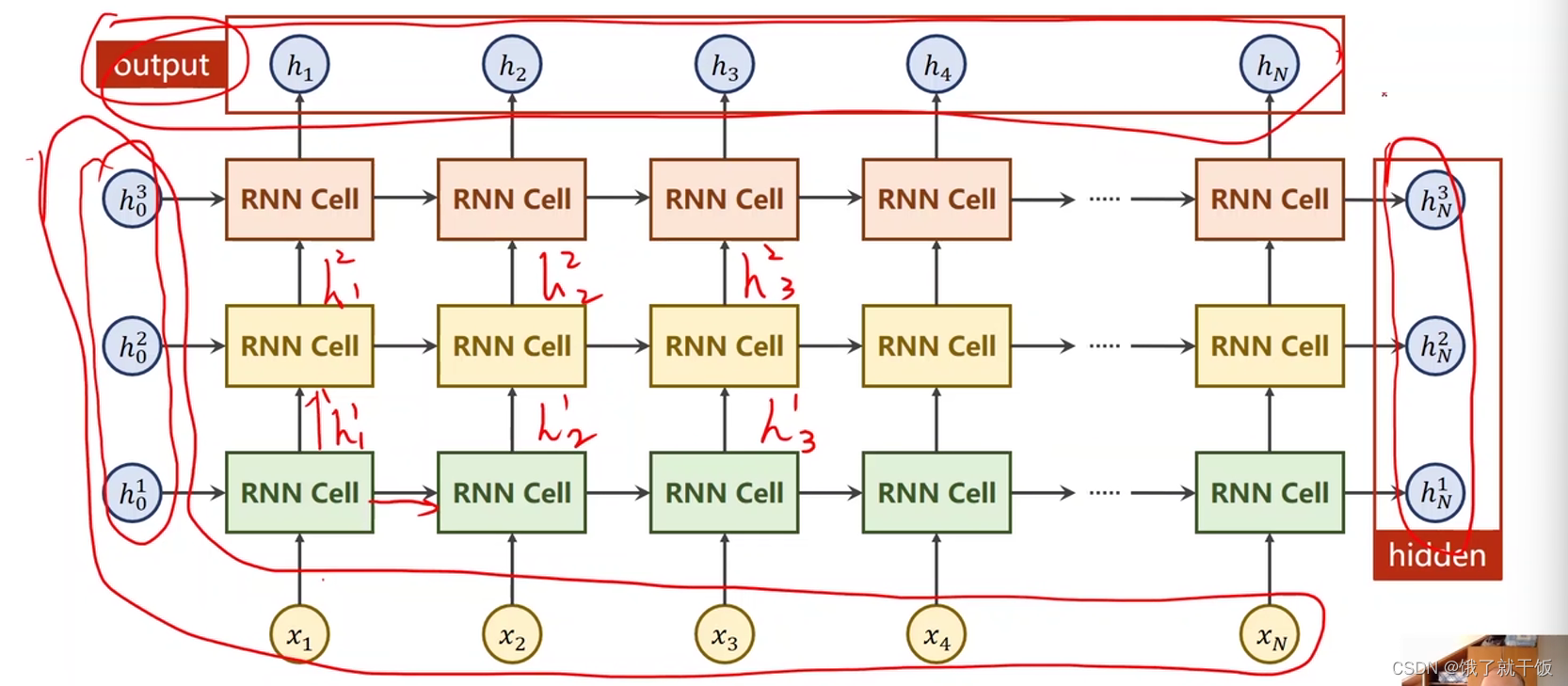
其中numLayers指的就是RNN是多少层的,这个确实有指明的必要,因为RNN有多少层,h就得有多少层
input维度

h0维度

output维度

hn维度

numLayers的解释
同一种颜色的cell是同一个cell,下面例子中的模型看着很复杂,实际就只是3个线性层
代码注释
参数配置

模型构造

输入序列的构造

隐藏层的构造

输出的解释

最后一个隐藏层输出的解释

执行代码的结果

batch_first设置为True的话,在构造数据时需要将batch_size和seq_len进行交换,为什么有这个选项,是因为有些时候这种方式更方便构造数据集(具体原因可再细查),见下图
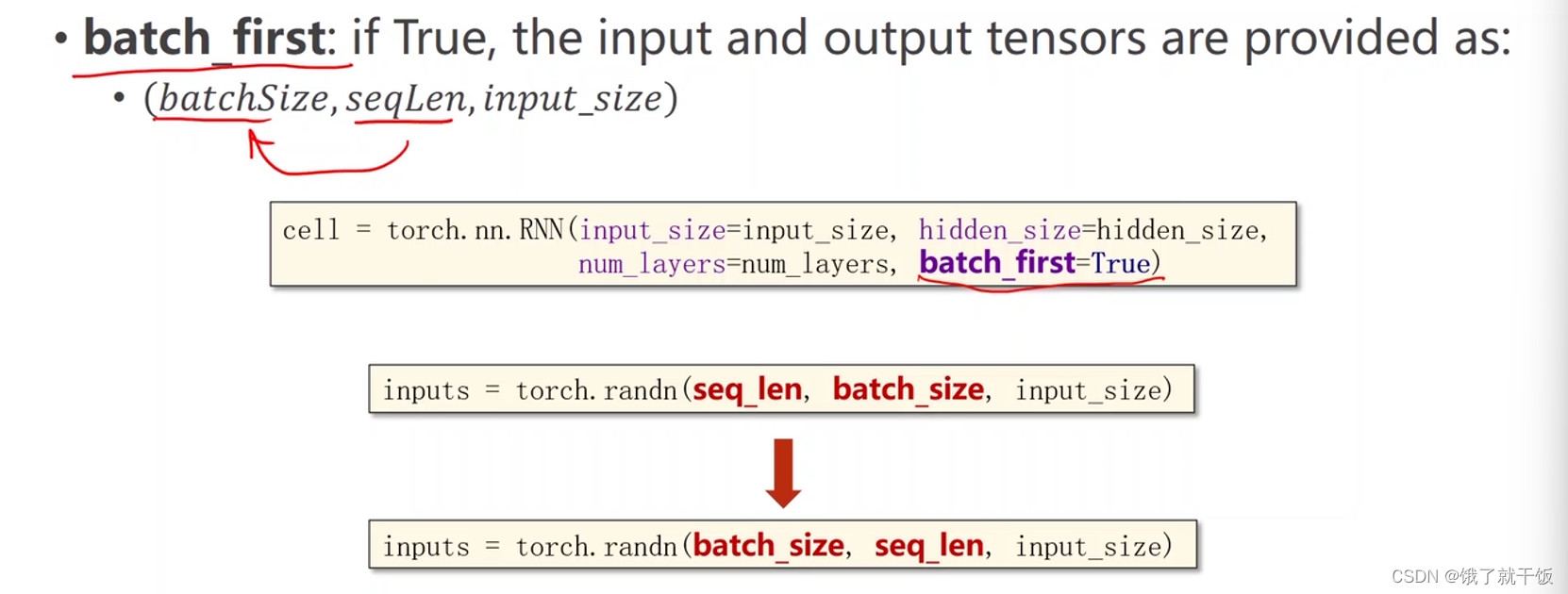
将batch_first设置为True的情况,代码和代码执行结果见下图:

可以看出batch_size和seq_len交换了位置
例子1:训练一个RNN 做seq2seq任务
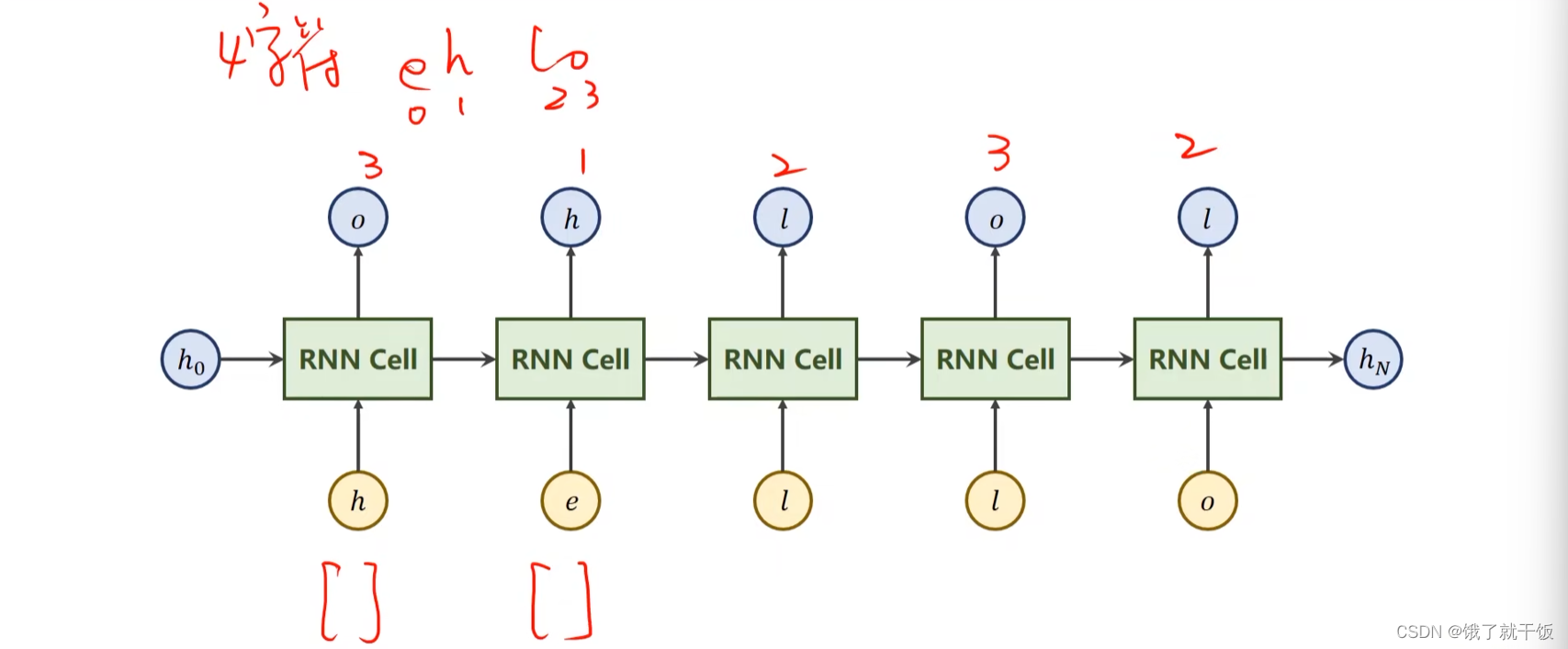
任务训练一个RNN模型,输入是hello,输出是ohlol
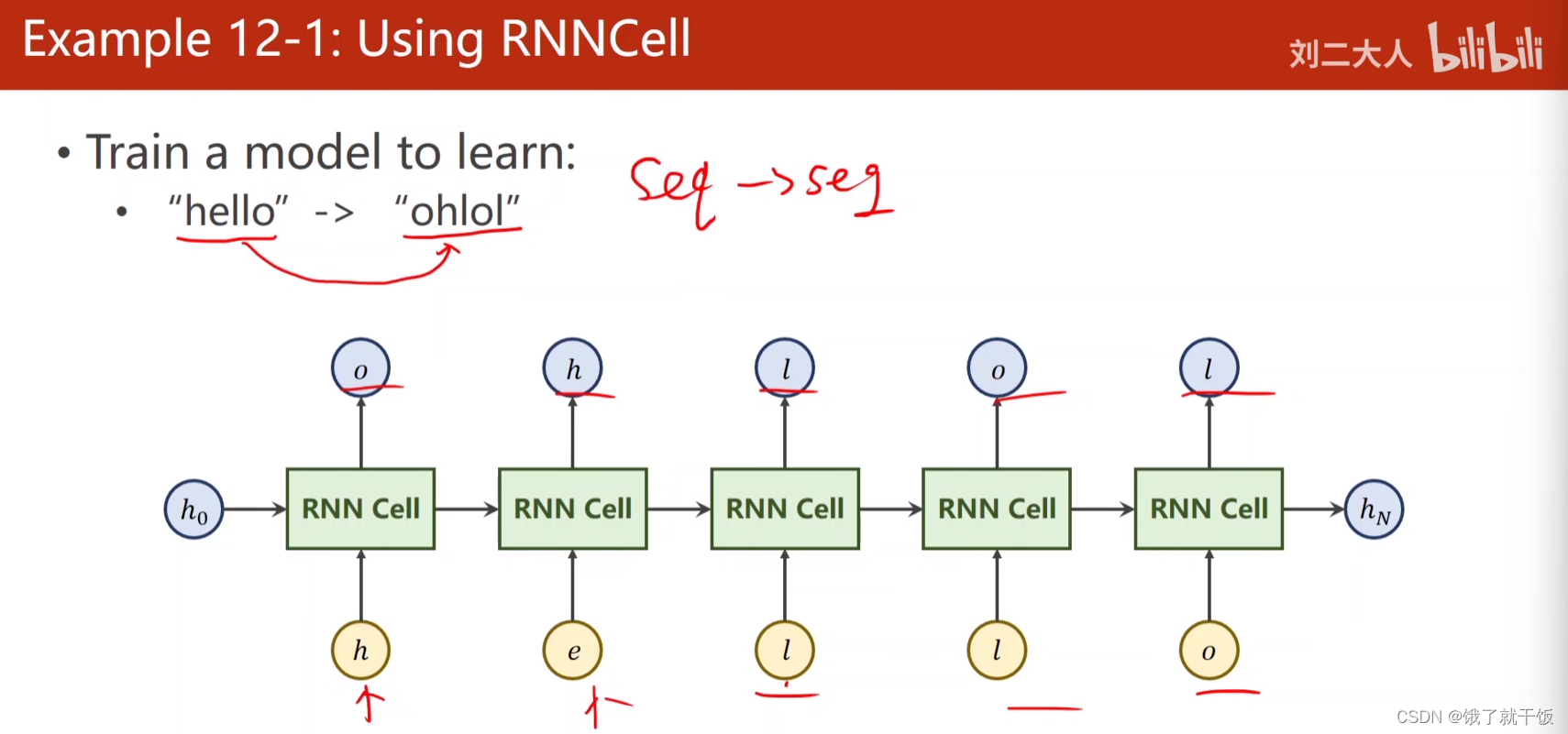
第1步 字符向量化
使用one-hot表示,每个字符使用词表大小的向量来表示

inputsize = 4
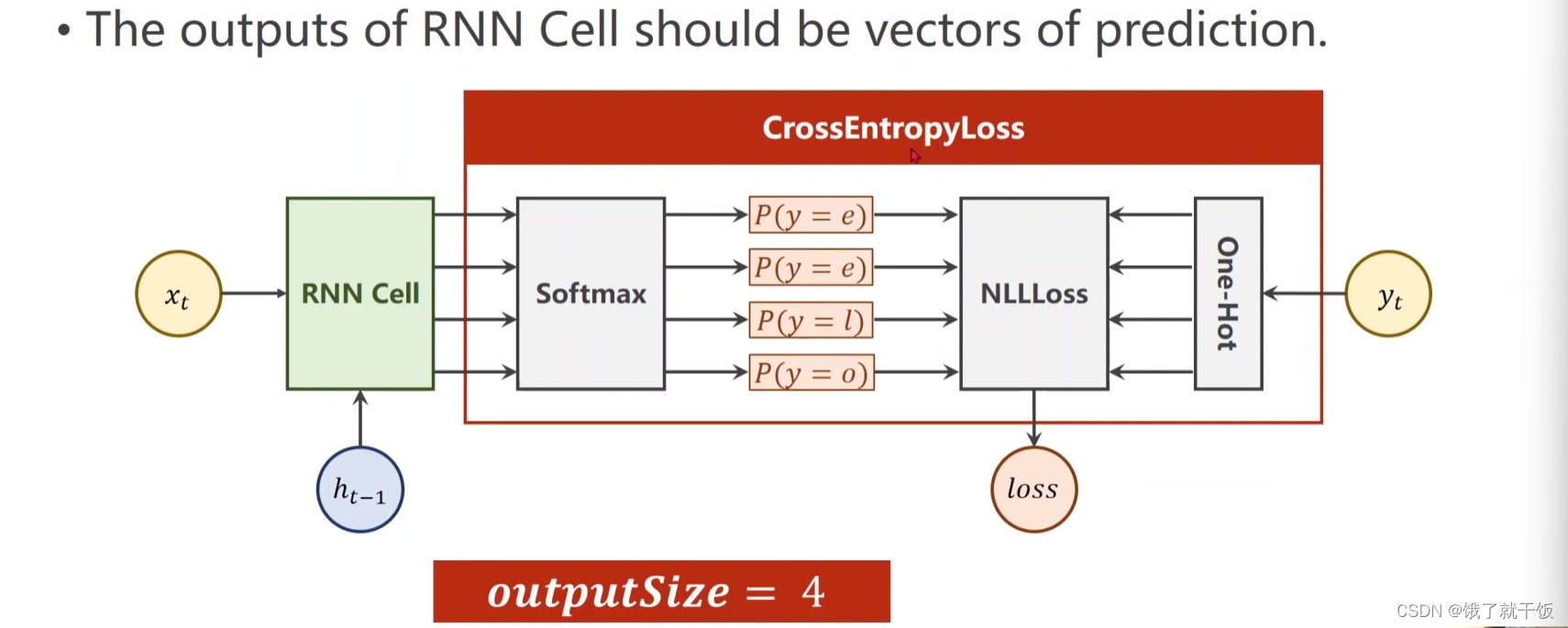
输入的向量维度为4,输出的应该是这4个字符的类别,因此可以令输出向量的维度也为4,这样通过一个softmax即可进行多分类,下图中的输出上写的数字是每个每个输出应该被分类的类别,如o应该被归为第3类,l应该被归类为第1类,等等
预测的向量与真实的向量做一个交叉熵损失值,如下图
参数配置

准备数据
idx2char是一个字典,值为字符,可使用索引作为键
lookup是一个查询表,例如:词表中e的索引为0,则e使用one-hot表示就是lookup中第0行的向量,o的索引为3,则o使用one-hot表示就是lookup中第3行的向量
x_one_hot是将x_data中每个索引对应的字符都表示为one-hot向量,它的维度应该是seq_len×inputsize,因为x_data的维度是seq_len,one-hot向量的维度是inputsize

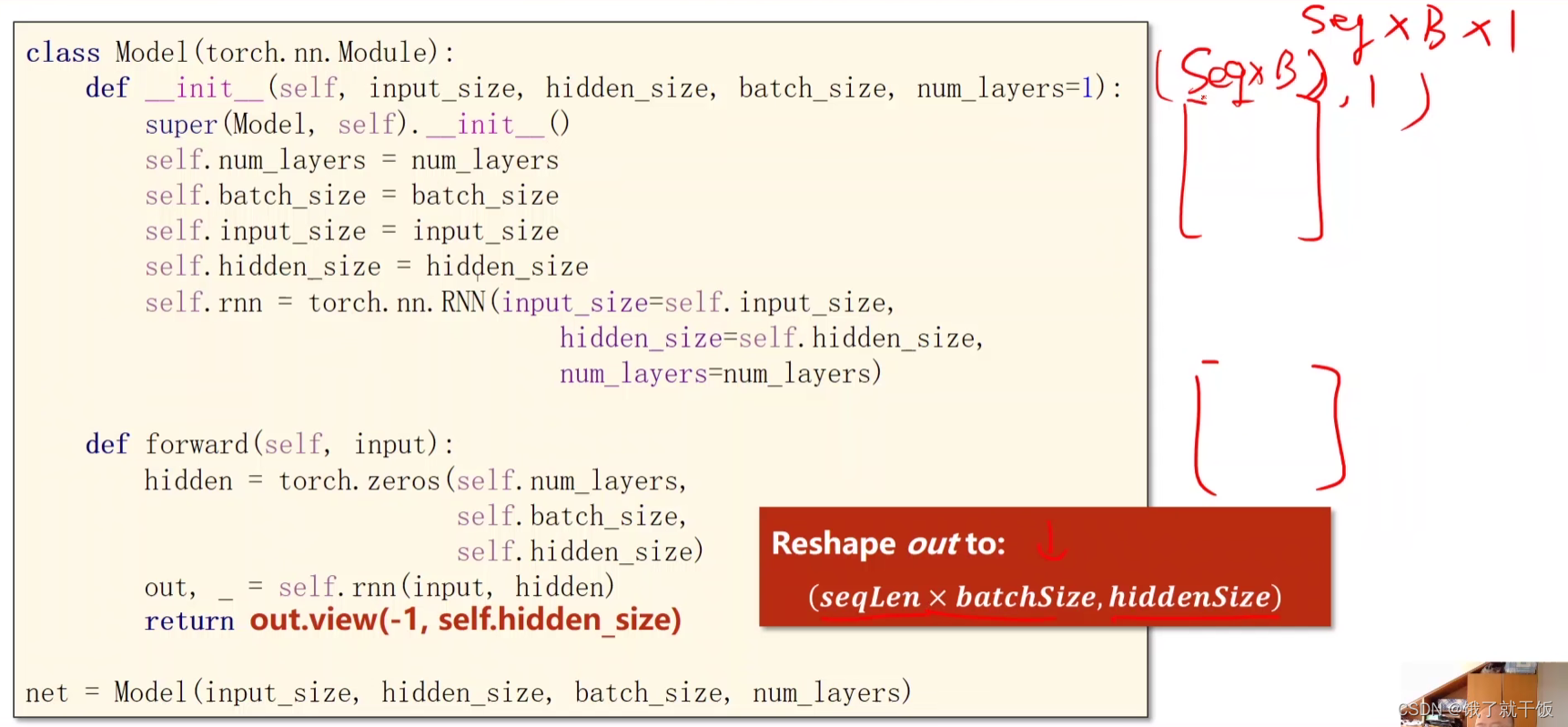
下面这个图中所写的(seqLen,1)应该是写错了,没有写batchsize的大小,

实际上应该写成(seqLen,batchSize,hiddenSize),即(-1,1,4),为什么这么写的原因可以见下图:
设计模型
1、初始化参数
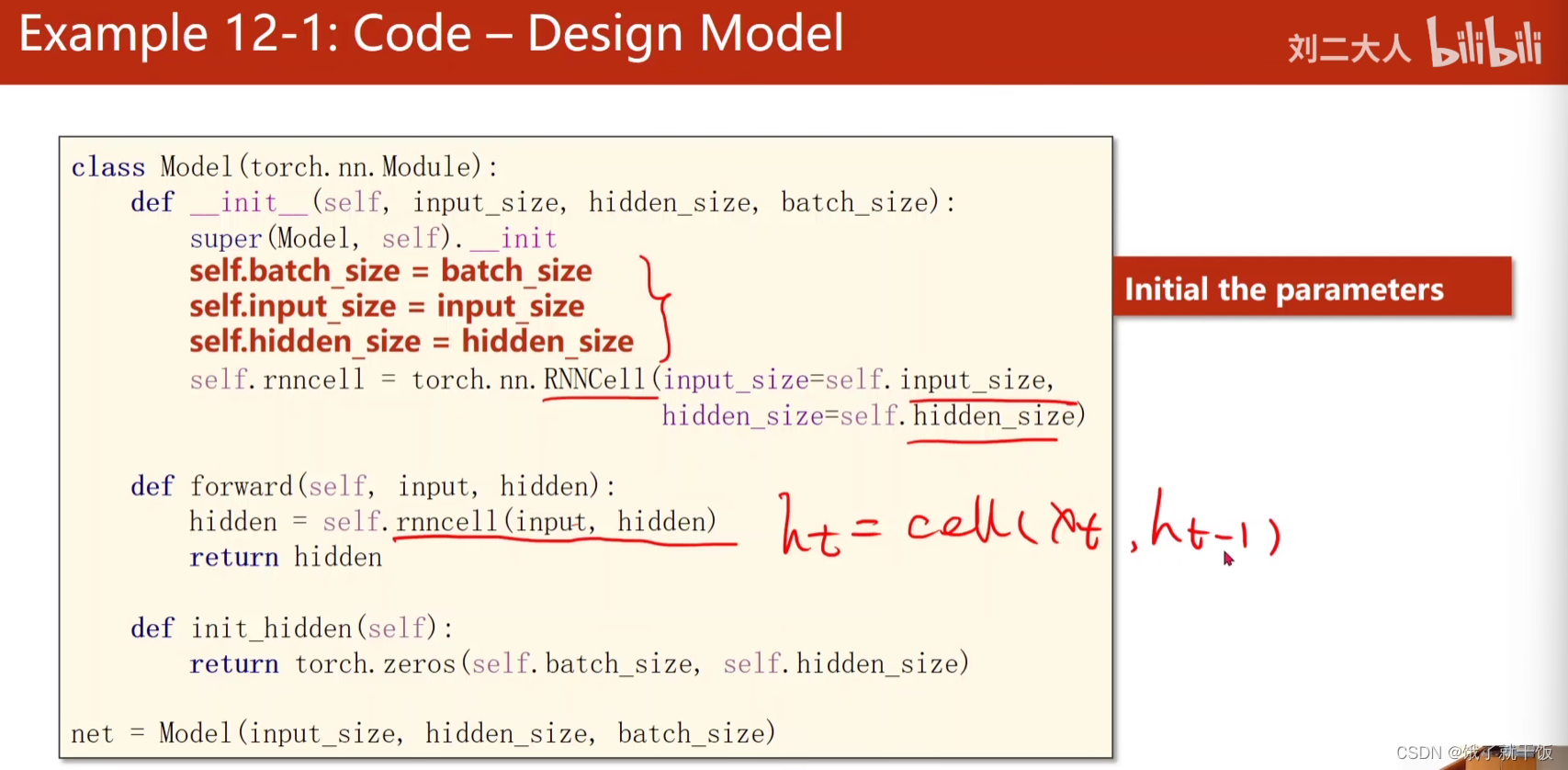
2、RNNCell的输入输出维度要求

3、初始化h0
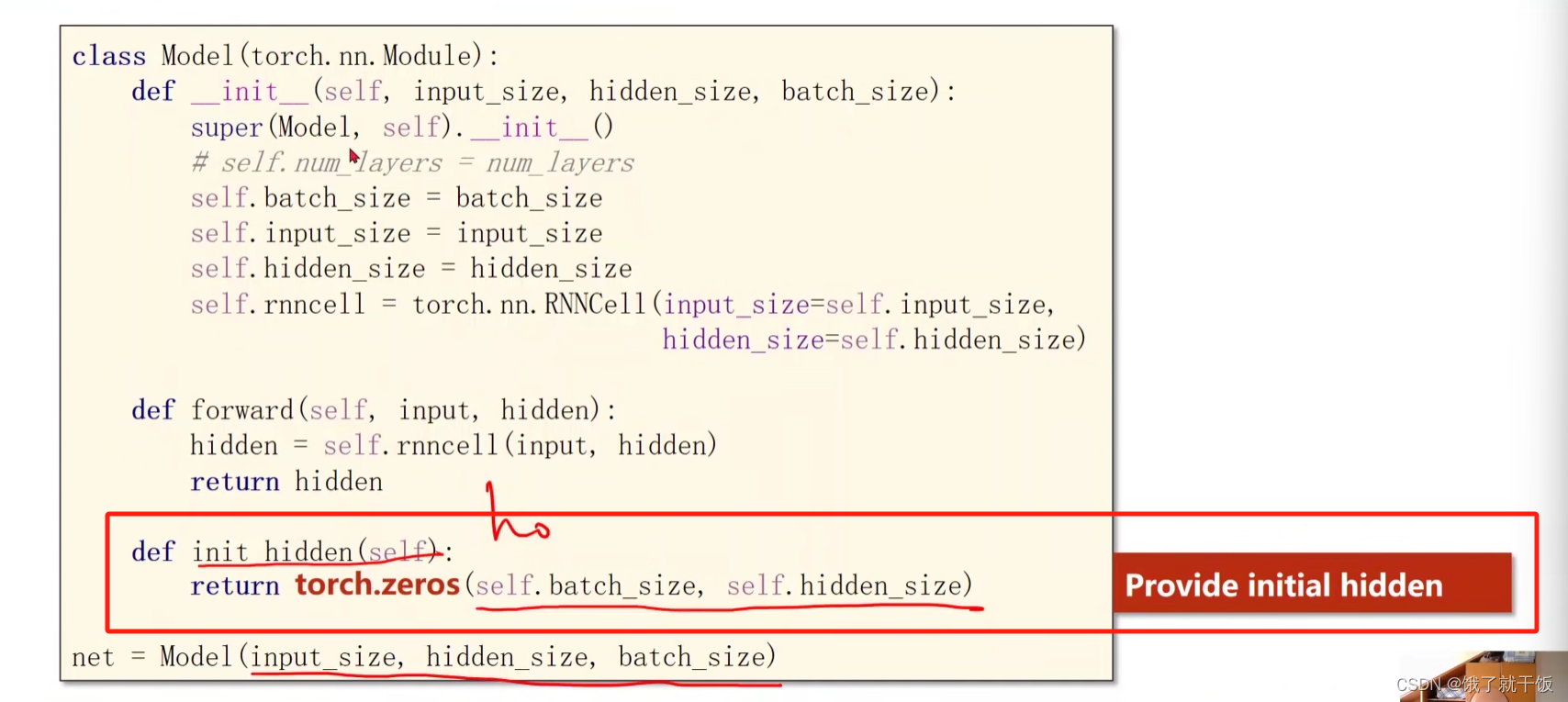
这里面的参数有一个batch_size,只有在构造h0的时候才会需要用到,在初始化和forward的时候不会用到这个参数
构造损失函数和优化器
使用交叉熵作为损失函数,Adam作为优化器

设置训练Cycle
optimizer.zero_grad():优化器的梯度归零
每一个epoch开始之后先算一个h0,对于每一步的损失值都加到一起,loss.backup进行梯度的反向传播,参数更新

注意下列数据的维度大小


lable只要给出类别数字即可,不需要one-hot,原因在于交叉熵的过程,这个地方需要查一下CrossEntropyLoss()的操作

hidden.max()就是找hidden中的找最大值,hidden是4维的向量

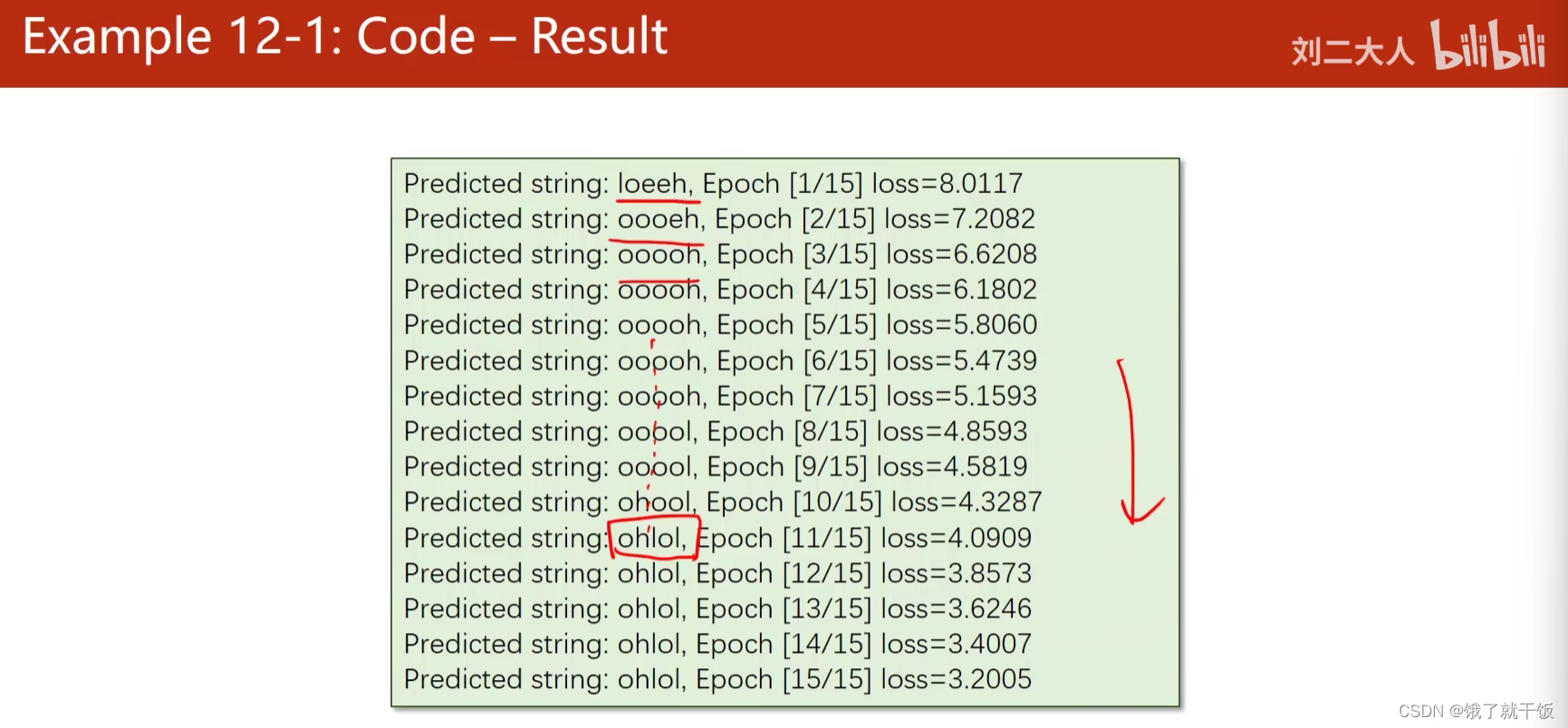
例2 使用RNN Module

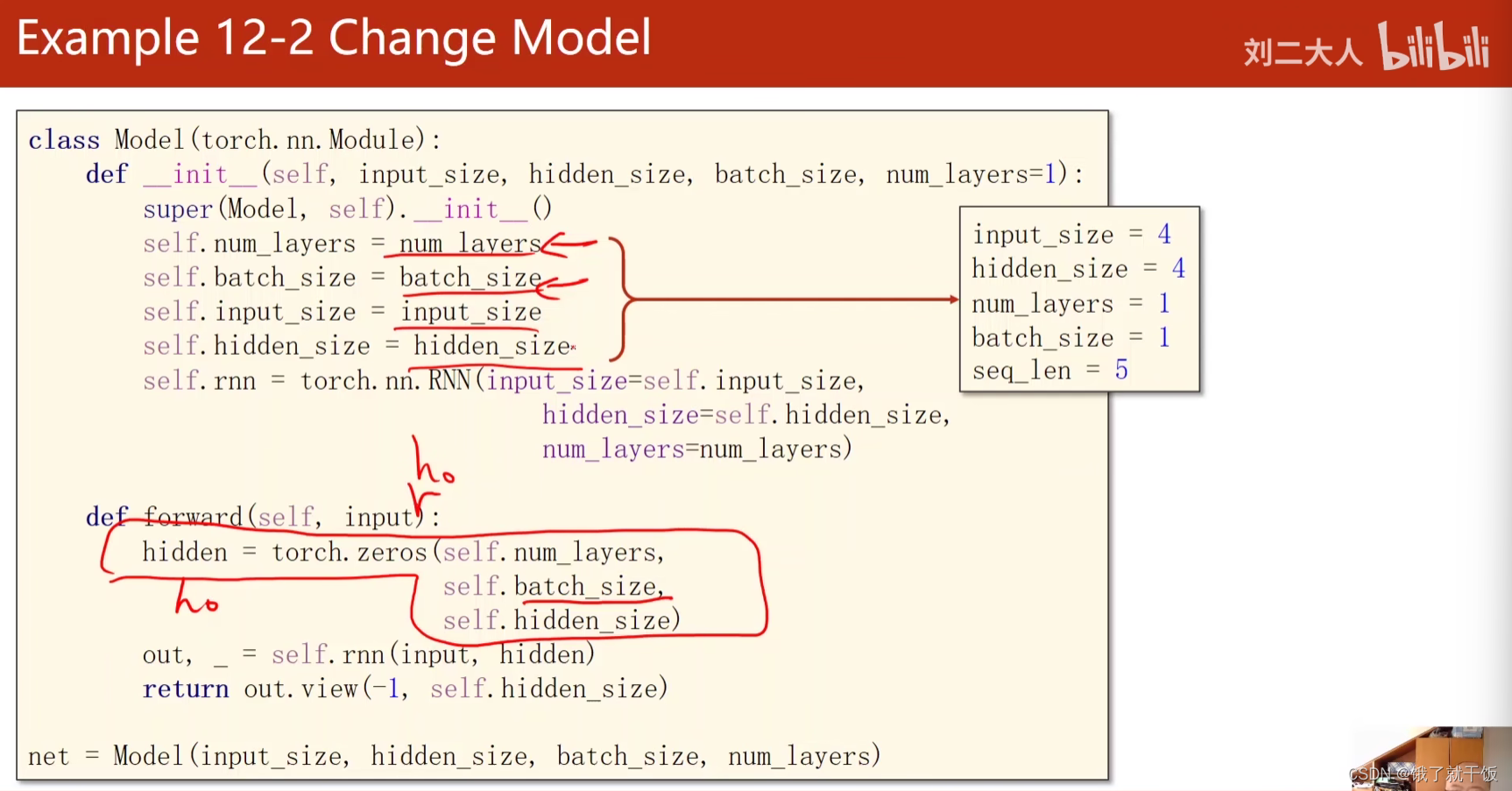

改变数据
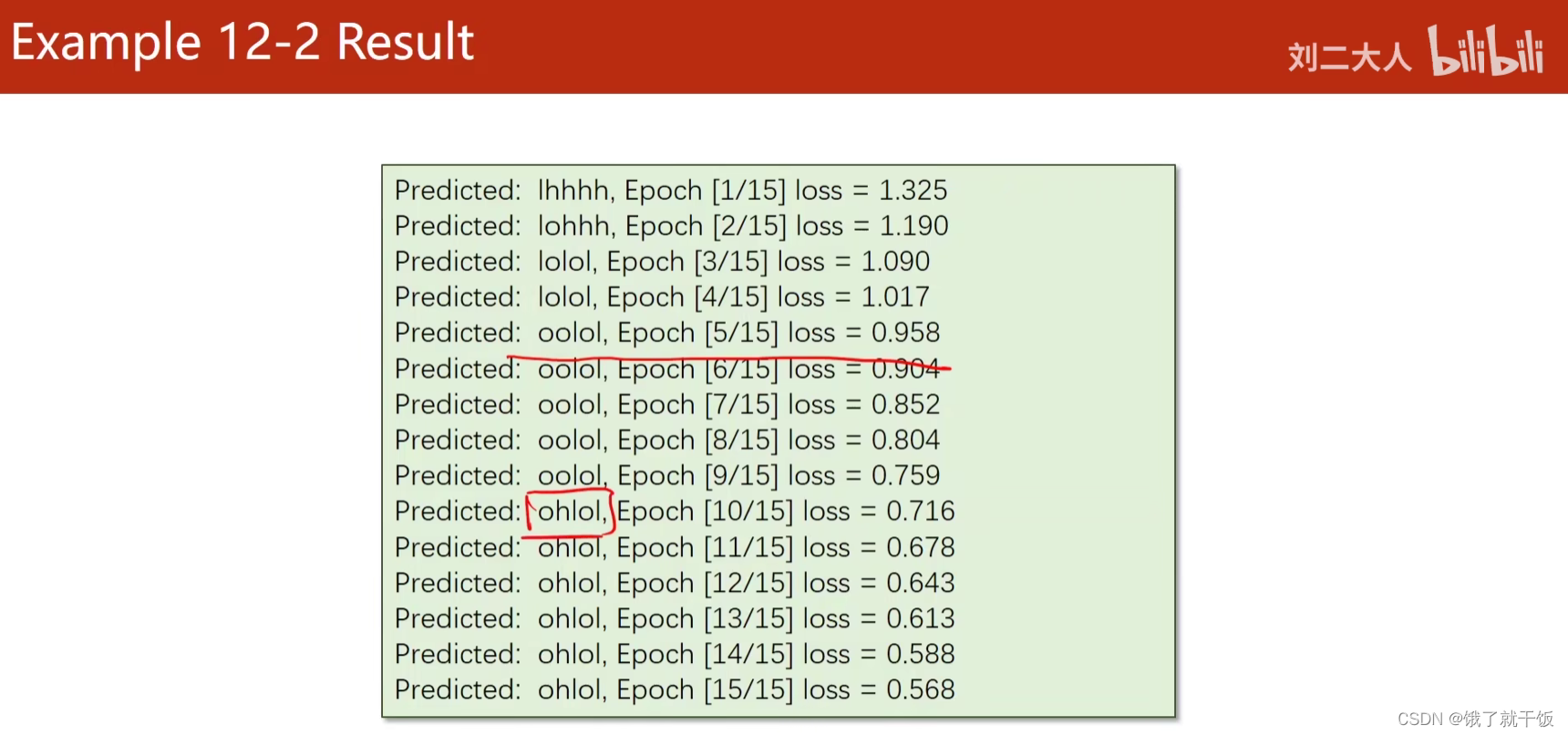
训练结果如下:
Embedding
associate:v.联系;联合;联想;交往;表示同意;(尤指)混在一起;表明支持;
one-hot表示的缺点:
1、维度太高(字符级:字符集ASIIC 128维 单词级:几万维)
2、过于稀疏
3、硬编码的,这个词向量并不是学习出来的

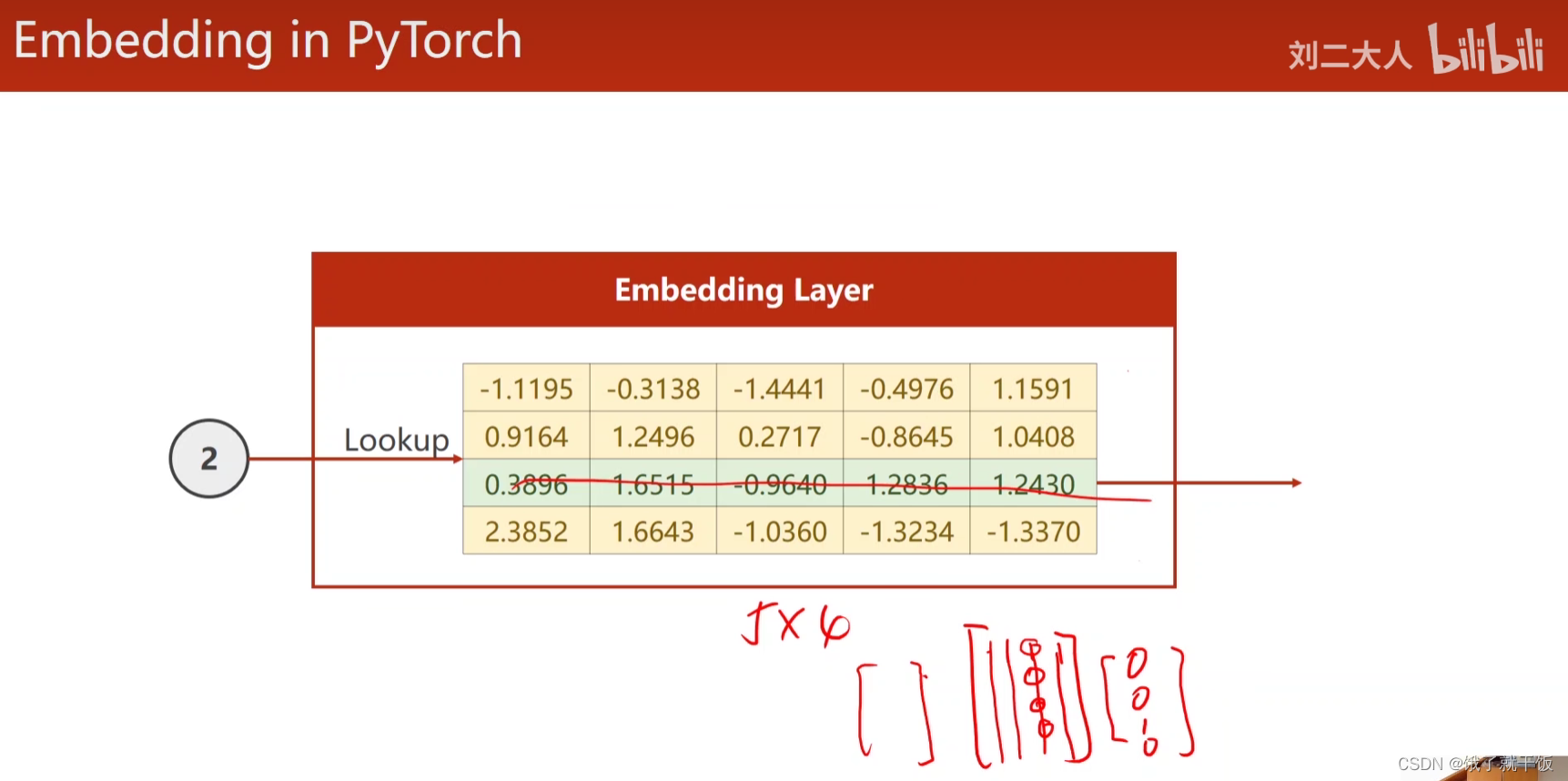
Embedding层是将高维的稀疏的样本向量映射到低维的稠密的空间中,这就是降维

嵌入层降维的方式:输入一个索引,通过查表来找到对应的向量,找的方法是通过将lookup表与一个one-hot向量进行想乘,然后得出最后的嵌入向量
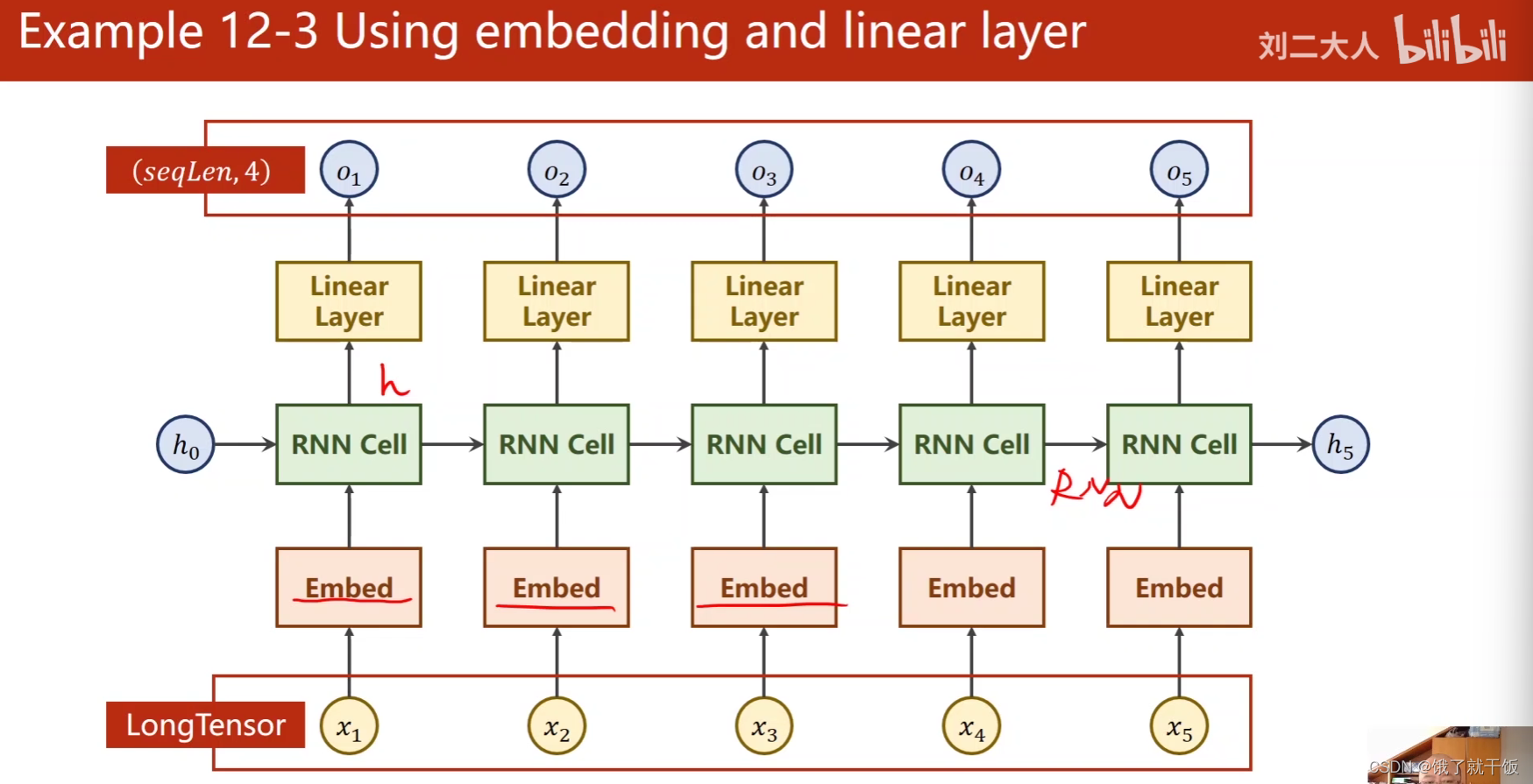
例12-3 使用embedding和线性层的RNN
有时候的输出的隐藏层h的维度与类别的维度o不一致,所以可以添加Linear Layer,将h的维度映射为o的维度


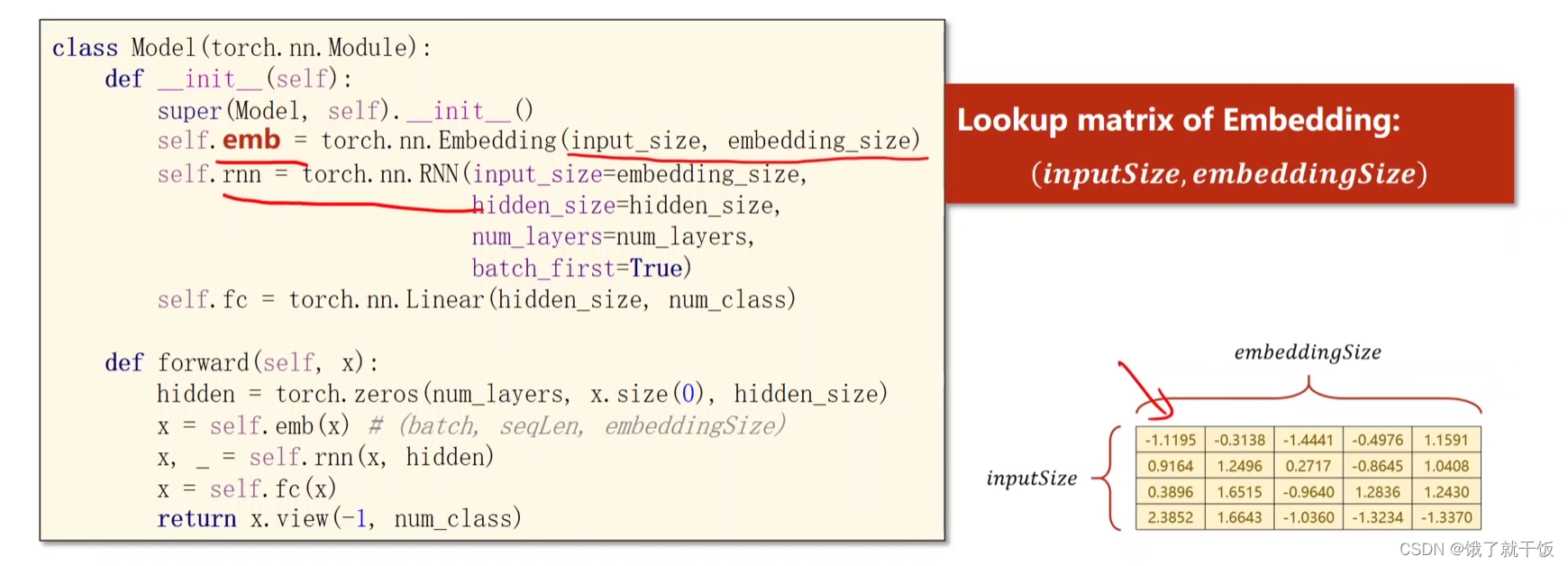

下面的batch_first = True只要知道有这种用法即可



参数配置:

输入和输出:

构造模型、损失函数、优化器

训练

出现ohlol比以前更早了,是因为使用了更厉害的模型,学习能力更强

练习1:LSTM
LSTM中的这些个门儿,实际上这么多次专业名词总会使人感觉到这个模型很难学习,实际不难,只需看公式即可
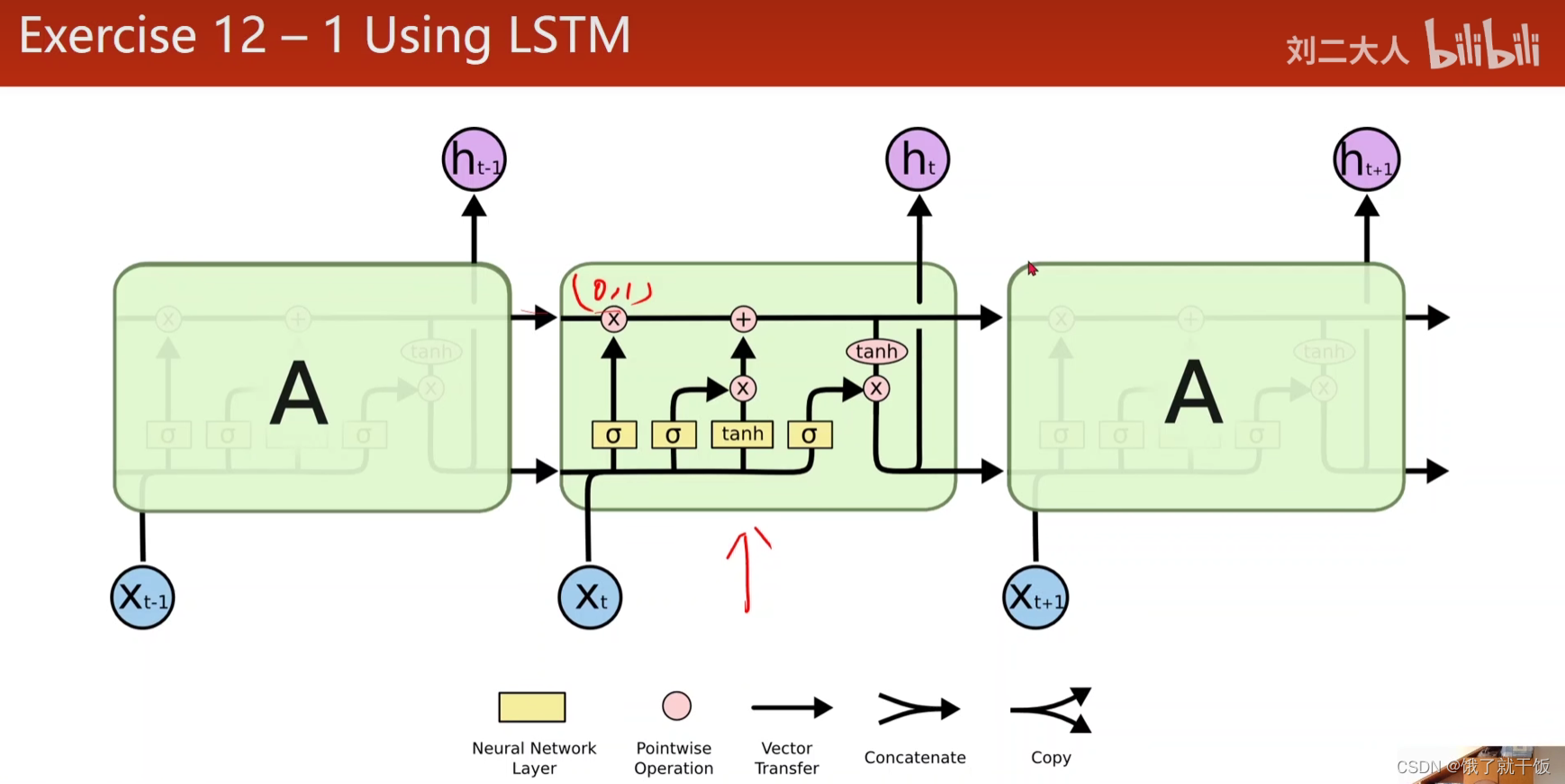

为什么有用?
因为提供了下面这样的路径,有利于梯度传播,有了记忆单元所以减少梯度消失
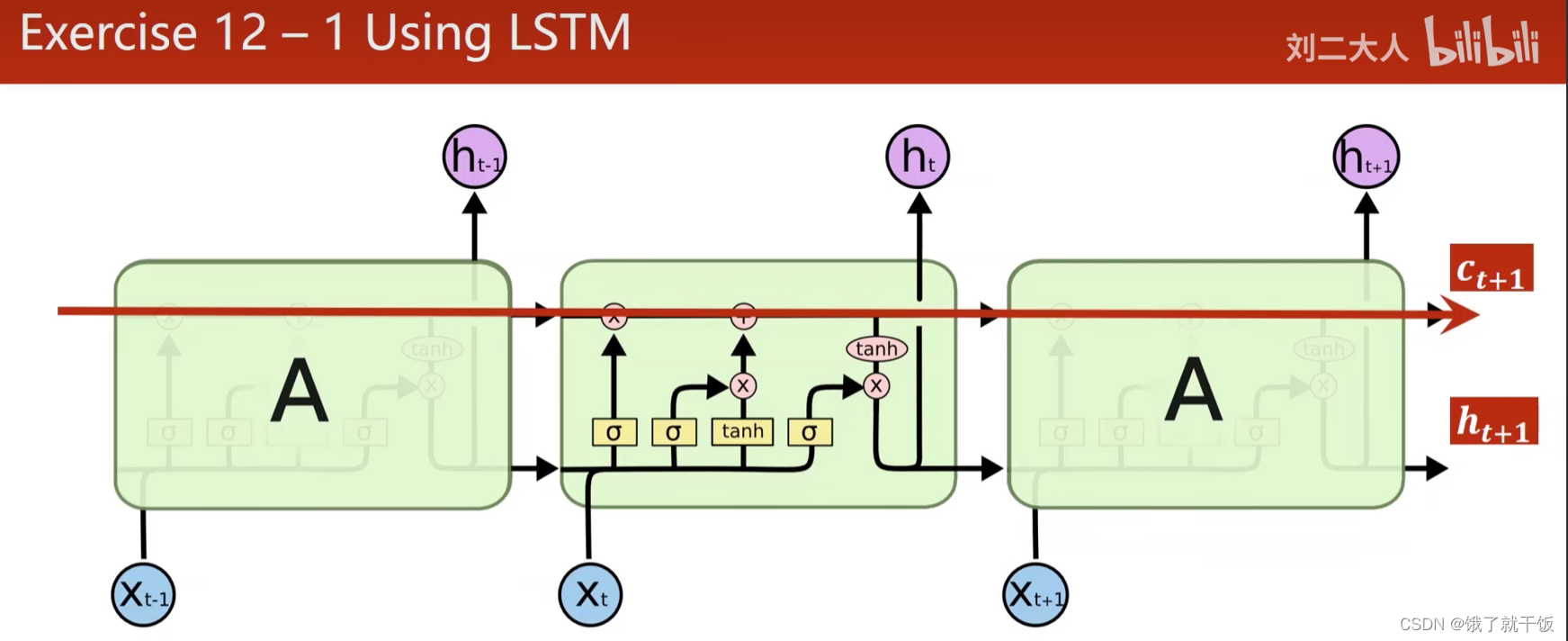

LSTM比RNN效果好得多,因为计算复杂,时间复杂度高
联系2:GRU
GRU是一个折中的方法,比LSTM的计算速度快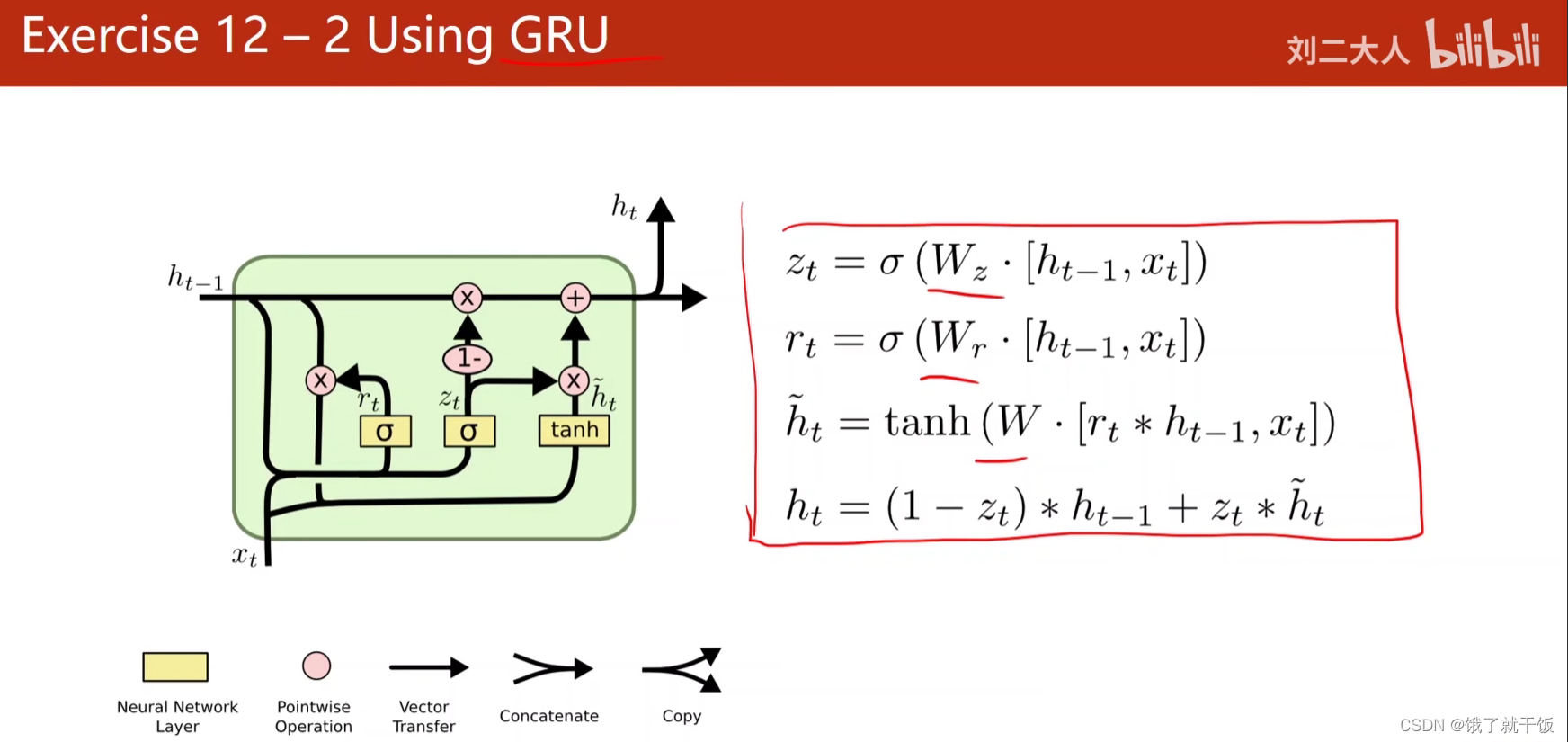

以上学习RNN需要重视的是
1、了解序列数据的维度情况
2、循环过程用到的权重共享机制
这篇关于跟着刘二大人学pytorch(第---12---节课之RNN基础篇)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







