本文主要是介绍《Cloud Native Data Center Networking》(云原生数据中心网络设计)读书笔记 -- 01 为什么需要一个新的网络架构,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
关于专栏
本专栏是工作之后阅读 Cloud Native Data Center Networking ( O’Reilly, 2019)的读书笔记。这本书是我在数据中心从事云网络工作的启蒙、扫盲读物。可惜,其中文版翻译并非尽善尽美,必须结合英文原版才能理解原作者要表达的观点。
部分表达参考了博客:ARTHURCHIAO’S BLOG
本章回答以下问题:
-
新型应用程序的特征是什么?
-
什么是“接入-汇聚-核心”(access-aggregation-core)架构的网络?
-
为什么“接入-汇聚-核心”网络架构不能满足新一代应用的需求?
应用网络程序的洗牌
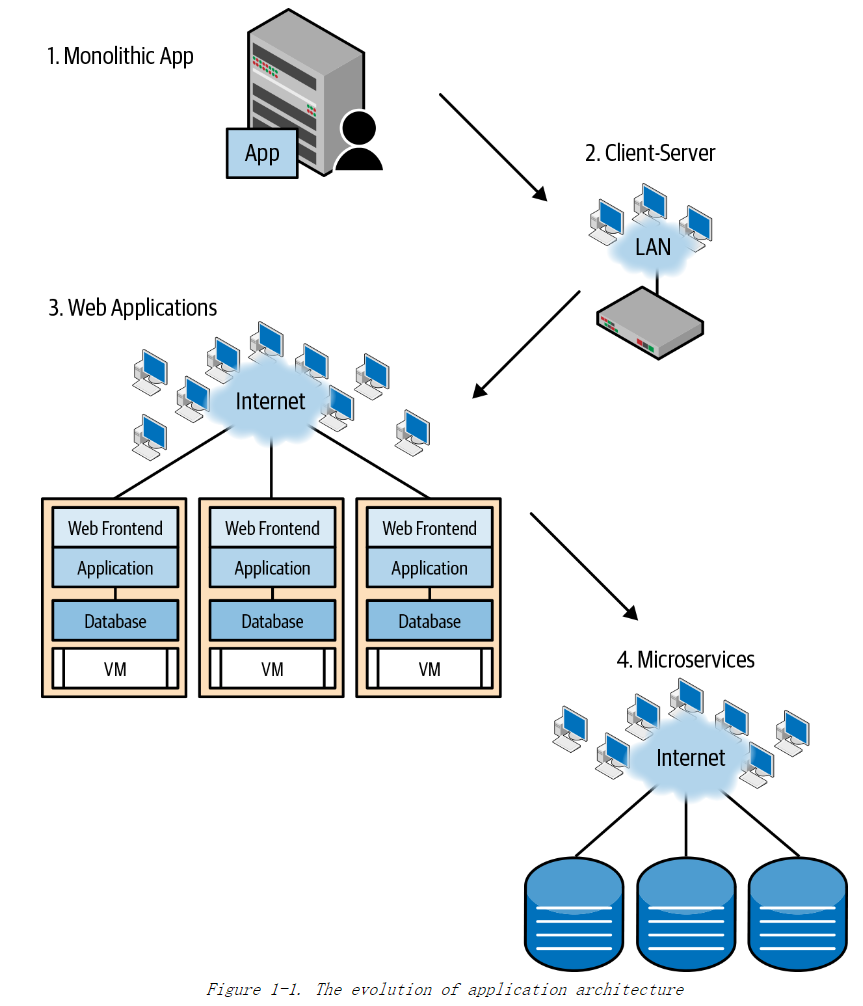
应用架构演进:
-
单体应用
- 通常部署在大型机上。
- 特定的厂商提供网络方案,协议是私有的(不是 TCP/IP 协议)。
- 以今天的眼光看,应用所需的带宽极小。
-
客户端-服务器应用
-
工作站和 PC 时代。
-
LAN 开始兴起。
充斥着各种 L2、L3 和更上层协议。
- 以太网、Token Ring、FDDI 等是比较流行的互连方式。带宽上限 100Mbps。
- TCP/IP 体系开始发展,但还没用成为主流。
-
-
Web 应用
- 以太网和 TCP/IP 一统互联网,其他绝大部分协议成为历史。
- 计算和网络虚拟化:虚拟机时代。
-
微服务(分布式应用)
- 大规模的数据处理(例如 MapReduce),数据中心网络的带宽瓶颈从南北向变成东西向,这是一个历史性的转变。
- 容器时代。
世纪之交的网络设计
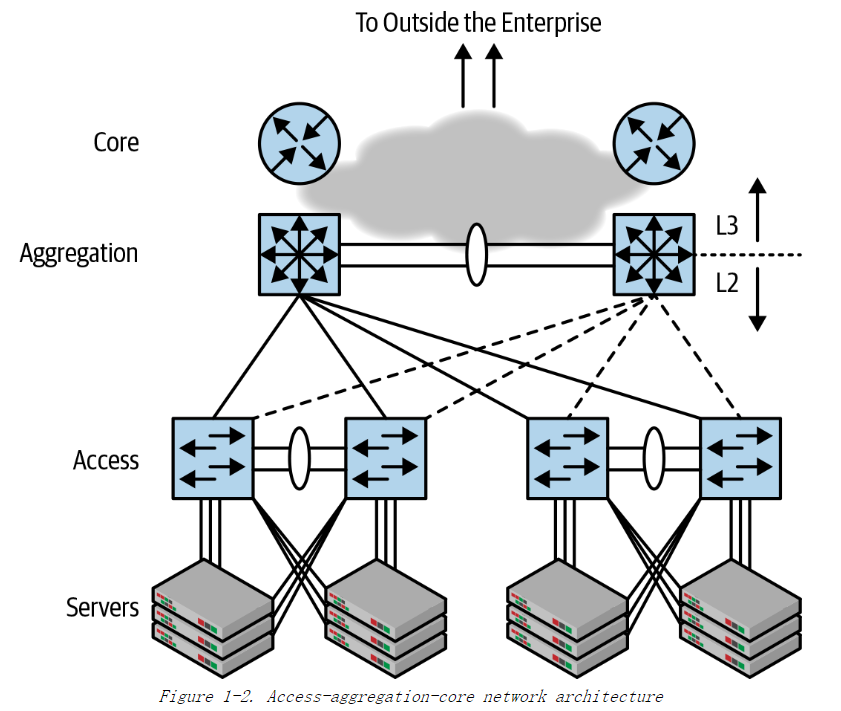
图1-2 展示了 20 世纪末流行的网络设计 ——“接入 - 汇聚 - 核心”架构。(access-aggregation-core)
在图 1-2 的最低层,终端(或称为计算节点) 连接到接入交换机。汇聚交换机 (也称为分发交换机) 又依次连接到核心网络,从而将接入网络连接到世界其他地方。在不同的网络中,汇聚交换机和核心交换机之间的连接方案会有所不同,但这并且不影响下面的讨论,因此在上图中没有画出这些链路。
如果只有一台汇聚交换机,该汇聚交换机发生故障时就会导致本地网络断开和外部网络的连接,因此上图中使用了两台汇聚交换机来避免单点故障。当时认为如果仅有两台汇聚交换机还不够,应该在汇聚层加入多台交换机,这样既有利于提高网络吞吐量,又具有冗余性。
汇聚交换机之间的流量通过桥接进行二层转发。在汇聚层之上则使用路由三层转发数据包。因此,汇聚层同时提供两种能力,南向 (向下层的接口) 提供桥接,而北向(向上层的接口)则提供路由。在图 1-2 中,通过在汇聚层同时标 L2和L3表明这一点,这里的L2和L3分别指的是2层网络 (桥接)和3层网络 (路由)。
网络图阅读指南
网络工程师在绘制网络图时,会把网络设备绘制在顶部,把计算节点绘制在底部。在此图中,诸如“北”和“南”之类的基本方向具有特定含义。
- 北向流量指从企业内部网路流向 Internet 的流量,首先从计算节点进入网络,然后离开企业内部网络,流向 Internet的。
- 南向流量是指从Internet返回本地计算节点的流量。
可以看到,这是经典的客户端-服务器通信模式。东西流量则指的是在同一网络中的各个服务器之间的通信流量。在客户端-服务器时代,只有很少量的东西向流量。在现代数据中心中,有很多高度集群化,分布式的应用程序,这些应用程序内部有大量的网络通信,因此东西向的流量成为现代数据中心的主要流量。
桥接(Bridging)的魅力
即使在Internet 已经迅速流行起来的时候,“接入 -汇聚 -核心”类型的网络仍然严重依赖于桥接技术。如果 IP 路由是推动Internet 发展的动力,那么企业内部的联网为什么还要使用桥接而不是路由呢?
主要有以下三个原因:
-
硬件交换分组转发的发展
交换芯片的出现(silicon switched packet forwarding)
- 做数据转发的芯片原先主要用在网卡,现在用于功能更强大的交换设备。
- 这种设备显然要求芯片具备更高密度的接口,而这样的芯片在当时只支持交换(bridging),不支持路由(routing)。
-
企业专用网络软件栈的兴起
- “客户端-服务器”模型所处的时代,TCP/IP 只是众多协议种的一种,并没有今天所处的统治地位。
- 但各家的协议只是在桥接层之上有所不同,而在桥接层面都是相同的。因此汇聚层以下走交换就是顺理成章也是唯一的选择。
- 接入 - 汇聚 - 核心成为了一种通用的网络架构,允许网络工程师为所有这些不同的网络协议构建一个相同网络
- 汇聚以下走交换(bridging),不区分厂商
- 汇聚以上走各家的三层协议
-
桥接技术零配置的优势
- 路由网络很难配置,甚至对某些厂商的设备来说,直到今天仍然如此。需要很多显式配置。
- 相比交换,路由的延迟更大,更消耗 CPU 资源。
- 交换网络是自学习的(self-learning),也是所谓的“零配置”(zero configurations)。
ROUTERS, BRIDGES, AND SWITCHES—相互重叠的术语
在转发芯片也开始支持路由之后,交换机的功能就不再只限制为桥接了,有些人将术语“L2 交换机”用于仅提供桥接功能的交换机,而用“L3 交换机“来指可以进行路由的交换机。现在许多供应商仍然使用这种区别来为设备的桥接端口和路由端口实行不同的定价和许可证策略。
在本书中,作者使用术语“交换”(switch)来表示路由器(router)或桥接(bridge),或者在适当的时候直接显式地指出其实现的功能
作者遵循通用的行业术语,在桥接 (链路层) 和路由层都使用数据包( packet)来代指交换的数据(因为没人使用“交换”这个词)。需要注意的是,在OSI七层标准模型中,链路层交换的是数据 (frame)而不是数据包 (package)。
自学习透明桥接是如何工作的?
一个网桥中包含多个网络接口,网桥可以将数据包从它的一个接口转发到另一个接口。 网桥的每个网卡接口都由一个制造商内置的 MAC 地址 (也称以太网地址) 标识。网桥在各个接口之间进行数据转发时,会通过侦听数据提交自动构建地址查找表,而无需任何用户配置。
在转发网络中,每个数据包都携带两个MAC地址: 源地址和目标地址。**网桥会在自身的 MAC地址表中查找目标 MAC地址,以查看其是否知道系统位于哪个接口上。**如果不知道,它将数据包发送到除接收数据包的接口以外的所有其他接口。通过这种方式,只要目标 MAC 地址存在于网络中,则数据包最终将会被传递给它。
**当网桥在自身的MAC地址表中找不到待转发数据包的目的 MAC 地址,而向所有端口发送该数据包的行为称为泛洪 (flooding)。**泛洪时网桥会进行自转发检查,防止网桥将数据包从其来源的接口发送出去。
在网桥的 MAC 地址表中查不到其目标 MAC 地址的数据包被称为未知单播数据包。除未知单播数据包之外,网桥也会对广播数据包和未知的多播数据包进行泛洪,因为这些类型的数据包必须被发送给网络上的每一个工作站端点。
当一个具有 MAC地址的节点发出数据包后,网桥可以从接收到该数据包的接口上得知该 MAC地址对应的接口,这就是网桥的学习方式。下次收到目标地址为该MAC地址的数据包,网桥就只会将数据包转发到该接口。通过这种方式随着时间的推移,网桥可以构建出整个网络的转发表。这就是自学习网桥名称的由来。自学习网桥也称为透明网桥,因为数据包不需要显式地寻址到网桥就可以把数据包发送到其目的地。而在进行路由转发时,数据包的目标 MAC 地址则必须设置为路由器的接口地址。
构建可扩展的桥接网络
桥接可以为各种不同的上层协议提供一个单一的底层网络,提供更快的数据转发速度,并且只需要很少的手动配置。但在现实中,由于其学习模型和生成树协议的影响桥接还存在一些限制。
1.广播风暴和STP的影响:这是自学习的机制决定的
如果一个数据包的目的地址不在网络中,或者该数据包的目的节点不能正常工作,网桥永远无法得知这个数据包应被发向哪里。在这种情况下,即使在一个简单的三角形拓扑网络中,在网桥已经做了自转发检测的前提下,该数据包也会在网络中循环转圈。因为MAC头并不像IP头一样有一个用于防止数据包转发环路的存活时间(TTL)字段。在这种情况下,即使只有一个进入环路转发的广播数据包也会导致一个小型网络的所有可用带宽被耗尽。这种灾难被称为广播风暴,只要在网络中发送足够多目的地址不存在的数据包,就可以瘫痪整个网络。
STP 协议可以将任何一种网络拓扑转换为无环树,从而打破网络的环路,以防止广播风暴。
在“接入 - 汇聚”架构的网络中,STP 会带来问题。在这种网络中,通常选用多个汇聚交换机中的一个作为生成树的根节点。从图 1-2 可以明显看出,两个汇聚交换机和一个接入交换机构成了一个三角形的环路。STP 通过切断接入交换机和非根汇聚交换机的链路来打破循环。不幸的是,这也将导致可用的网络带宽减半,因为接入交换机只能使用其中一条到汇聚交换机的链路。如果当前的活动汇聚交换机发生故障,或接人交换机与活动汇聚交换机之间的链路发生故障,STP 将自动打开接入交换机与另一个汇聚交换机的链接,以保证网络可以正常工作。
2.泛洪带来的负担
泛洪通常是由未知的单播数据包造成的。网络一端的主机会同时接收到所有未知的单播数据包以及广播数据包和未知的多播数据包。MAC 转发表条目一般都关联了一个时长 5 分钟的计时器。如果一个 MAC 地址的主机在 5 分钟内没有和对端通信,则这个 MAC 地址所关联的转发表条目就会被从 MAC 地址转发表中删除。就会使得下一个发到此 MAC 地址的数据包泛洪转发。ARP 是一种用于解析IP 地址对应的 MAC 地址的IPV4 协议,通常使用广播进行 ARP 查询。因此,在一个有 100 个主机的网络中,每个主机至少会额外接收到 100 次 ARP 查询(来自其他99 台主机以及缺省网关查询) 。
ARP 是目前已知的一种很高效的协议,所以每秒几百个提交的处理并不会有明显的影响,但有时也并非这样。
大多数的应用程序并非像 ARP 协议那样考虑周全。这些应用会滥用广播和多播数据包,这就造成一个桥接网络上经常会传输各种数据包。
虚拟局城网 (VLAN)的发明解决了泛洪过多的问题。单一的物理网络在逻辑上划分成为多个小规模的网络,每一个逻辑网络由多个节点组成,而且这些节点在大多数况仅与本逻辑网络内的其他节点互相通信。每一个数据包都属于特定 VLAN,与泛洪数据包所属的同 VLAN 网络的交换机端口上。就可以允许一个企业内部的群组共享同一个物理网络,同时不会影响仍处于同一个物理网络的其他类的群组。从IP 角度看,广播包被限制在一个子网内部。因此一个 VLAN 是与一个IP子网相关联的。
什么是子网
IP 地址可以被划分成若干组连续的地址,并用形如“共同的起始位一掩码一掩码长度”这样的形式来表示。比如,在IPV4 地址中,1.1.1.0/24 代表着一个由1.1.1.0到 1.1.1.255 共 256 个地址的子网。
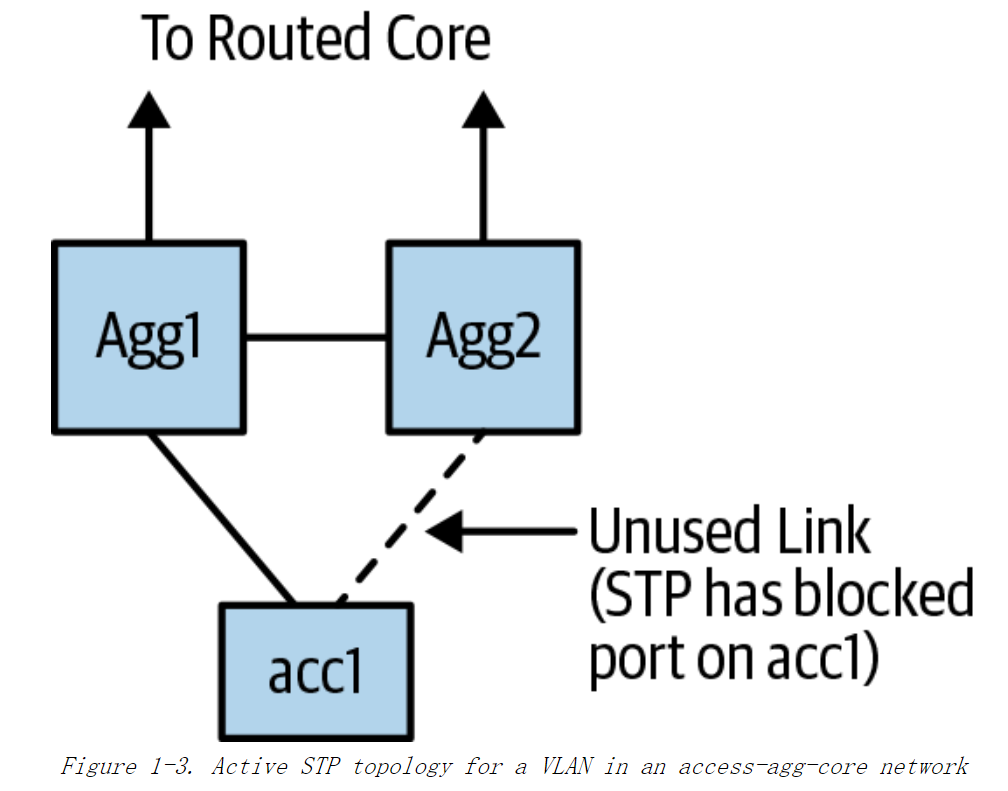
用每 VLAN 生成树来增加带宽
之前提到,接入交换机被连接到两个汇聚交换机,采用了 STP 来阻止环路的产生同时导致网络可用带宽减半。为了使两个链路同时工作,思科引入了每 VLAN 生成树 (per-VLAN spanning tree, PSTV) ,也就是说,PSTV 为每个 VLAN 构建了一个单独的生成树。例如,通过将偶数 VLAN 接入其中一个汇聚交换机,将奇数 VLAN 接入另一个汇聚交换机,PSTV 允许使用两条链路:一条用于偶数 VLAN 那一组,另一条用于奇数 VLAN 那一组。对于接入交换机的某一个 VLAN,实际生成树拓扑如图 1-3 所示。
3.IP层的冗余设计
网关配置在汇聚交换机。由于汇聚交换机代表了网络的边界,那些通过接入交换机接入并挂接在汇聚交换机之下的主机会用这些汇聚交换机作为第一跳路由器。当给一台主机分配IP地址时,第一跳路由器的 IP 地址通常也会被设置为这台主机的缺省网关。这使子网内的主机可以通过第一跳路由器与子网以外的设备通信。
为保证高可用,一组汇聚配置同一个网关。当一台主机获取到缺省网关的 IP 地址后,如果其中一台汇聚交换机发生故障,那么另一台汇聚交换机需要代替已故障的汇聚交换机,继续使用原先的默认网关 IP 地址提供服务。否则,子网内的主机就不能在汇聚交换机发生故障时与子网以外的主机进行通信。这就会让引入第二台冗余汇聚交换机的目的无法达成。因此必须设计一个解决方案,使得两台路由器支持同一个 IP 地址,但同一时间只能有一台路由器持有这个 IP 地址且处于工作状态。
考虑到图 1-3 所示的拓扑结构,每一个广播包(比如 ARP 包)都会被发送到两台汇聚交换机。除了只允许其中一台汇聚交换机在给定时间点上对广播包做出响应以外,还必须确保在汇聚交换机发生切换前后,汇聚交换机回应的 ARP 中的网关 MAC 地址保持不变。
需要协议支持,这种协议称为第一跳路由协议(First Hop Routing Protocol, FHRP)。
FHRP 原理:FHRP 允许两台路由器同时监控对方的运行状态,以确保任意时间只有一台路由器来响应查询网关IP的ARP包。
FHRP 协议举例:
- HSRP(Hot Standby Routing Protocol):FHRP 的第一个实现,思科的热备路由协议
- VRRP(Virtual Router Rundundency Protocol):目前用的最多的协议。
又如不中断业务升级 (ISSU)功能极其复杂,虽然能解决一些问题,但引入了更多问题。
接入 - 汇聚 - 核心网络架构存在的问题
- 面对广播风暴的脆弱性 —— 即便已经开启了 STP。
- 应用(applications)变了 —— 服务器之间的东西向流量开始成为瓶颈,而这种网络架构主要面向的是“客 户端-服务器”模式的南北向流量时代。
- 应用的规模显著变大,在故障、复杂性和敏捷度方面对网络提出了完全不同于以往的新需求。
现有网络架构无法解决以上问题。
不可扩展性(Unscalability)
尽管接入 - 汇聚 - 核心网络被设计成可扩展的,但是这种架构很快就达到了可伸缩的极限。这种架构的各个层级上都遇到了问题。
-
泛洪
不管架构上如何分层,自学习型网桥的这种“泛洪和学习”模型并没有可伸缩性。MAC 转发表仅仅是一个针对 VLAN 和目的MAC地址的60个比特查找表。当网络规模非常大时 (例如大规模虚拟机场景),定期地会有上百万的泛洪包,终端计算节点不堪重负。
-
VLAN 限制
传统上,1个 VLAN标识符有 12 比特,因此一个网络中最多有 4096 的VLAN。云计算来临后,4096 个 VLAN 显然是不够用的。,无法满足云计算时代的多租户需求。就算采用24 比特 VLAN标识符,但由于每个 VLAN 都会有一个 STP 实例,运行1600万个 STP实例简直是不可能的。
-
汇聚应答 ARP 的负担
汇聚负责应答 ARP。ARP 数量可能非常多,导致汇聚交换机 CPU 飙升。
-
交换机水平扩展性和 STP 限制
理论上,增加汇聚交换机数量似乎就能增加东西向带宽。但是, STP 不支持两个以上的交换机场景,否则后果无法预测。 因此汇聚交换机就固定在了两个,无法扩展。
复杂性(Complexity)
桥接网络需要很多网络协议的支持。这就包括 STP 协议及其变种协议,FHRP,链路失效侦测,以及供应商的私有
协议[例如 VLAN 中继协议 (VTP) ]。所有这些协议显著增加了桥接网络解决方案的复杂性。实际上这里的复杂性意味着当网络失效时,必须检查多个运行时组件以便来定位问题的根因。
除非接入-汇聚 -核心网络是精心设计的,否则这类网络中很容易出现拥塞。
为了说明这种情况,请再看一次图 1-3。两台汇聚交换机 Agg1和 Agg2 对于连接到接入交换机 acc1 的子网是可达的。这个子网并不局限于 acc1,而且有可能包含多个接入交换机。如果 Agg1 和 acc1 之间的链路失效,当 Agg1接收到来自于核心交换机且目的节点下挂在acc1 上的数据包时,Agg1需要通过 Agg1和 Agg2 之间的链路将此数据包发送给 Agg2,进而让 Agg2 把这个数据包转发给 acc1。这意味着 Aggl和Agg2 之间的链路带宽必须精心设计,否则如果链路上的流量由于链路失效而超出预设会造成意想不到的应用性能问题。
即使在正常情况下,也会有一半的流量会转发至备份汇聚交换机上,这台汇聚交换机与接入交换机的互联链路被阻塞,最终流量通过主备汇聚交换机互联的对等链路转发至主用汇聚交换机。
STP 使得网络只能用到一半的链路带宽。
故障域(Failure Domain)
数据中心的先驱们引入一个名词叫爆炸半径(blast radius),来度量单一失效造成的影响的范围有多大。当失效越靠近失效点,则说明失效域的粒度越细,即爆炸半径越小。
接入 - 汇聚 - 核心模型容易发生粗粒度的失效。
- 单个链路的失效造成带宽减半。
- 单个汇聚交换机失效,整个网络的流量带宽减半;而且此时所有流量都会打到同组的另一台汇聚,这也会造成剩下的这台交换机失效。
- 广播风暴会使整个网络瘫痪。
不可预测性(Unpredictability)
某些普通的故障会导致整个 STP 瘫痪
欠灵活性(Inflexibility)
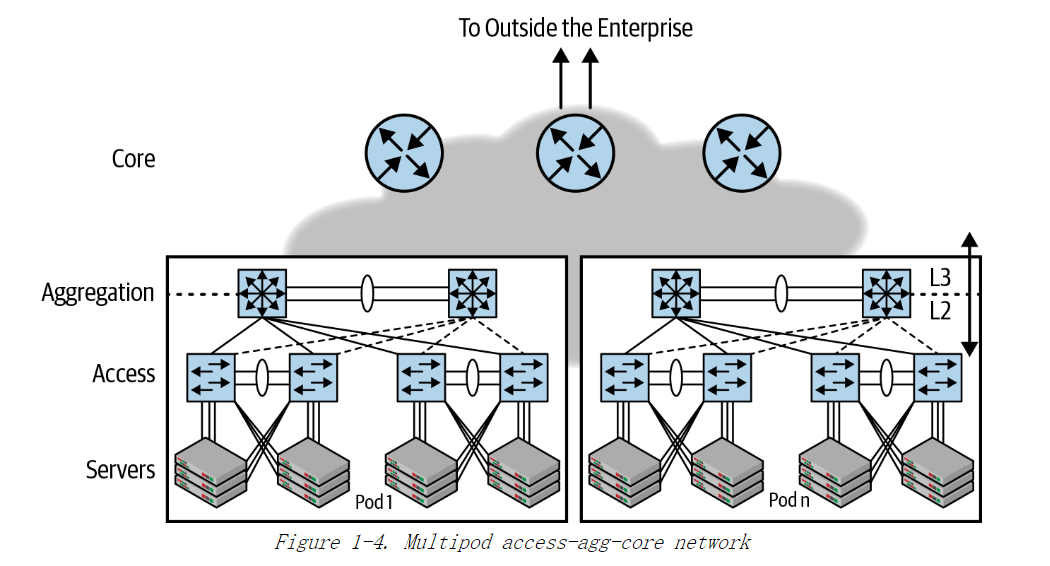
在图 1-4 中,VLAN 在汇聚交换机终结,即在交换(bridging)和路由(routing)的边界终结。
同一个 VLAN不会跨越两台成对出现的汇聚路由器,受到物理架构的限制,网络工程师无法灵活地将任意可用接口分配给用户的VLAN(需要端到端的链路都有可用接口才行)。例如,如果某个VLAN的用户分布在不同楼层或建筑物中,传统设计无法轻松地将这些用户的端口划分到同一个VLAN。
In other words, the access-agg-core design is not flexible enough to allow a network engineer to assign any available free port to a VLAN based on customer need.
欠敏捷性(Lack of Agility)
在云计算领域,不停地有租户租用云计算资源或者到期不再续租。因此快速的提供虚拟网络变得极其重要。
VLAN 需要网络中的每一个节点都被正确的配置了 VLAN 信息以便能正常工作。但是增加 VLAN 也会造成控制面的负担,这是因为根据 PVST 协议,控制面所发送的 STP 握手包的数量等于端口数乘以 VLAN 的数量。之前讨论过,单一的负载过重的控制面很容易使整个网络瘫痪因此添加或者移除 VLAN 是一个费时费力的过程,通常要持续数天。
桥接问题的解决尝试
跨设备链路汇聚(MLAG)在当代企业数据中心中有少量的使用,用于处理双归属服务器。
小结
本章中,我们看到应用程序架构的演进是如何对网络架构产生影响的。单体应用是相对(与当今的应用相比而言)简单的一类的应用,它们运行在复杂的定制硬件上,只要求网络提供简单的连接并运行专有协议即可。下一代应用是复杂的基于客户-服务器架构的应用,这些应用运行在相对简单,但需要复杂互联支撑的计算基础设施之上。当前的应用类型是复杂的大规模分布式应用,这类应用要求与以往不同的网络架构。
这篇关于《Cloud Native Data Center Networking》(云原生数据中心网络设计)读书笔记 -- 01 为什么需要一个新的网络架构的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!








