本文主要是介绍Apple Intelligence 横空出世!它的独家秘诀在哪里?,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
在 WWDC 2024 大会上,苹果公司揭晓了自家的生成式 AI 项目——Apple Intelligence,其策略核心在于采用 ⌈ 更为聚焦的小型模型 ⌋ ,而非盲目追求大模型的普遍趋势。
横空出世的它究竟有什么过人之处?一文带你探究竟!
生成式“小”模型
苹果公司的方法论围绕着构建专门针对其操作系统和功能需求的人工智能模型,这与竞争对手所推崇的“越大越好”的理念背道而驰。通过打造规模更小、更加专业化的模型,并使用为苹果用户量身定做的数据集进行训练,苹果旨在提高 AI 决策过程的透明度以解决“黑盒”问题。
虽然苹果选择专注于“小”模型,但 Apple Intelligence 仍能覆盖广泛的请求类型,这得益于“适配器”的应用,它是专为执行不同任务和风格而设计的组件。这种方法虽然与大型模型的全面能力有所不同,但却确保了 AI 能够无缝地融入苹果生态系统的用户体验中。
第三方合作
苹果公司承认其模型存在局限性,并因此与第三方模型如 ChatGPT 合作,以实现更广泛的信息覆盖。当外部模型更适合处理特定查询时,系统会向用户发出提示,询问是否愿意将信息共享给外部应用。
这一机制 ⌈ 有助于消除用户的隐私担忧 ⌋ ,允许他们对数据分享作出选择,并提供了退出第三方平台使用的选项,尽管这可能会导致系统和 Siri 访问的数据量有所减少。
本地处理和私有云计算
苹果既依赖设备本地处理,也利用其私有云计算服务来执行 AI 任务。虽然用户通常无法明确分辨查询是在设备上还是通过云端进行处理,但苹果保证无论是在设备还是云端都遵循 ⌈ 一致的隐私保护标准 ⌋ 。
然而,某些操作始终在设备上执行,例如 Image Playground 功能,它依赖于本地存储的完整扩散模型。Image Playground 支持三种艺术风格的图像生成:动画、插图和草图,文本生成同样提供三种风格选项:友好、专业和简洁。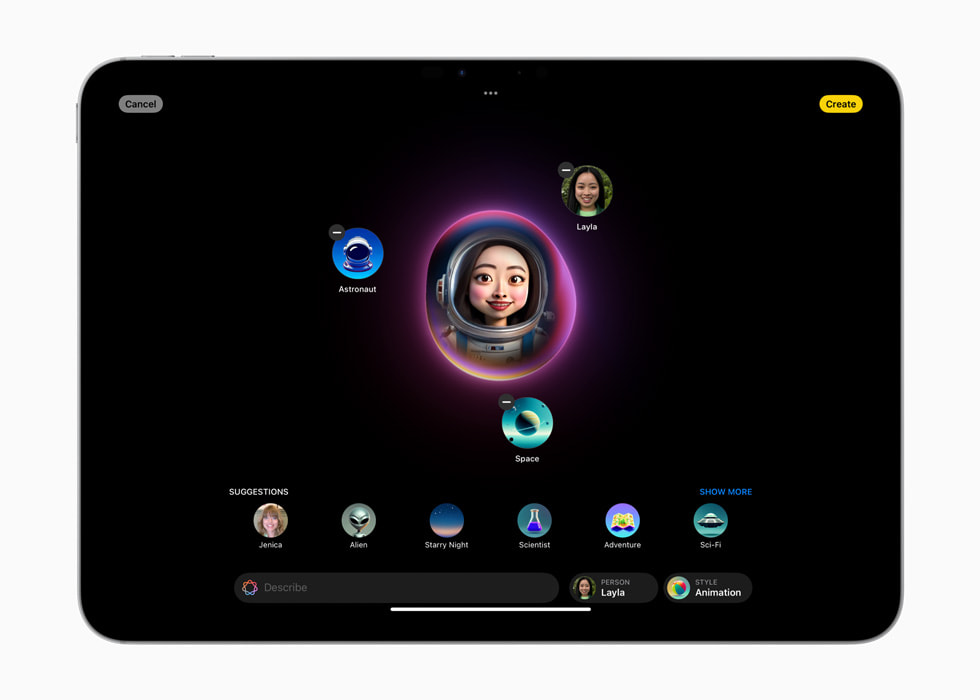
数据集管理
在数据集管理方面,苹果结合使用授权数据集和通过其网络爬虫 AppleBot 收集的公开可访问信息来训练其模型。AppleBot 作为苹果的网络爬虫,长期以来一直在为Spotlight、Siri 和 Safari 等应用提供数据。
当然,苹果也提供了一种选择机制,允许网络内容的发布者自主决定是否同意苹果使用他们的数据来训练支撑其一系列产品中生成式 AI 功能的基础模型。
开发原则
WWDC 首日,苹果公司还发布了一份白皮书——Introducing Apple’s On-Device and Server Foundation Models: 特别提到了四点苹果 AI 模型开发的原则:
特别提到了四点苹果 AI 模型开发的原则:
- 智能工具赋能:负责任地运用AI,创造满足用户特定需求的工具。
- 精准匹配用户:打造个性化产品,避免AI中的刻板印象和偏见。
- 设计谨慎周全:全程预防措施,确保AI工具安全可靠,避免潜在危害。
- 隐私至上保护:通过强大技术保障用户隐私,不使用个人数据训练模型。

自初代 Mac 以来,苹果始终以用户体验为核心—— ⌈ 追求无摩擦的极致体验,但绝不以牺牲隐私为代价 ⌋。随着新版操作系统即将面世,苹果将面临微妙的平衡——既要优化体验,又要守护隐私。
理想状态下,信息透明度应随用户需求而变化:对于绝大多数用户,系统自动选择最优路径,而对于隐私倡导者及注重细节的用户,苹果应竭力提升透明度,尤其在内容源的选择上。
在“黑盒”不可避免之处,亦应在可控范围内给予用户知情权,让技术服务于人,而非凌驾于人之上。
这篇关于Apple Intelligence 横空出世!它的独家秘诀在哪里?的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!







