本文主要是介绍【Linux内核】伙伴系统算法和slab分配器(1),希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
【Linux内核】伙伴系统算法和slab分配器(1)
目录
- 【Linux内核】伙伴系统算法和slab分配器(1)
- 伙伴系统(buddy)算法
- 伙伴系统算法基本原理
- 内存申请
- 内存回收
- 接口函数源码分析
- 内存分配接口
- 物理内存释放接口
- 规范物理内存分配行为的掩码 gfp_mask(了解即可)
作者:爱写代码的刚子
时间:2024.5.24
前言:本篇博客将会介绍Linux系统中伙伴系统算法
伙伴系统(buddy)算法
系统需要一种能够高效分配内存,同时又能减少产生碎片的算法——伙伴系统算法
大致结构:

node划分:
现代服务器上,内存和CPU都是所谓的NUMA架构(有多个CPU)
- dmidecode命令可以查看主板上插着的CPU的详细信息

在NUMA架构中node:
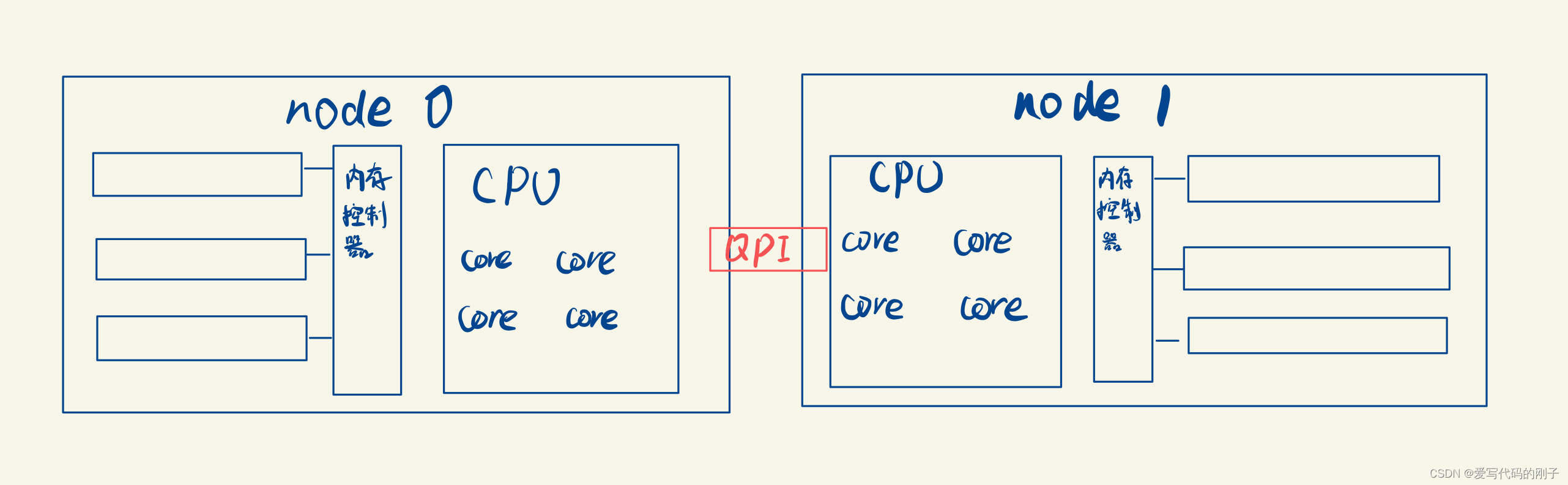
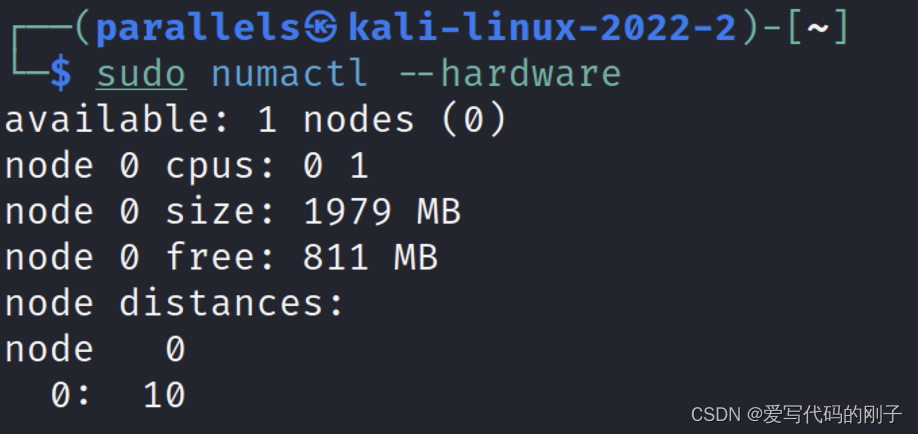
- numactl --hardware指令查看每个node情况
zone划分
每个zone又会划分成若干个的zone(区域),zone表示内存中的一块范围。
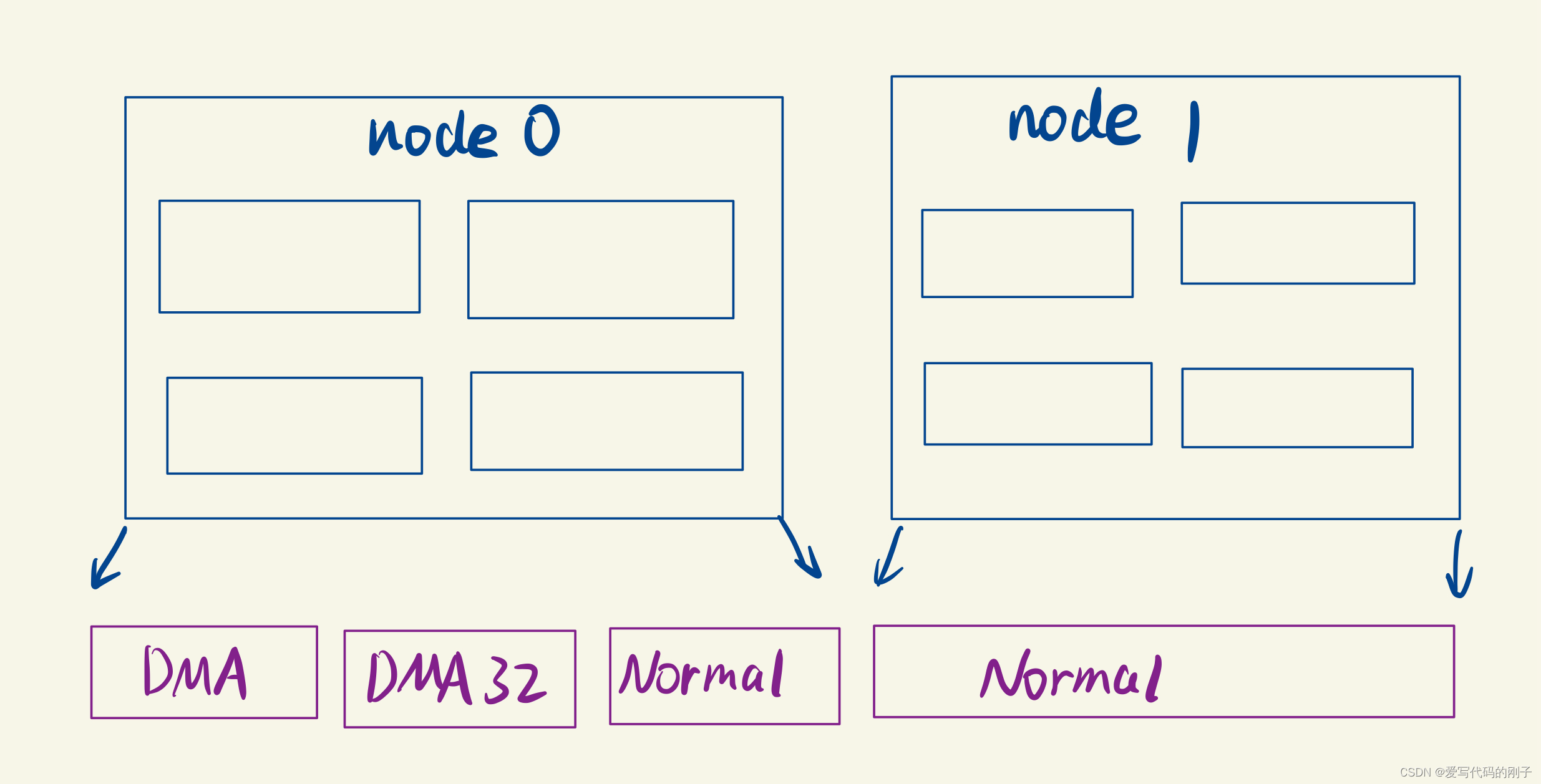
- ZONE_DMA:地址段最低的一块内存区域,供I/O设备DMA访问。
- ZONE_DMA32:用于支持32位地址总线的DMA设备,只在64位系统里才有效。
- ZONE_NORMAL:在X86-64架构下,DMA和DMA32之外的内存全部都在NORMAL的zone管理
其实还有一个ZONE_HIGHMEM,但是这是32位机时代的产物,现在用的不多
- cat /proc/zoneinfo查看zone的划分

伙伴系统算法基本原理
伙伴系统算法把所有的空闲页框分为11个块链表,每块链表中分布包含特定的连续页框地址空间,例:第0个块链表包含大小为2^0个连续的页框(4kb), 第1个块链表包含大小为2^1个连续的页框(8kb)
伙伴算法每次只能分配2的幂次页的空间,比如一次分配1页,2页,4页,8页,…,1024页(2^10)等等,每页大小一般为4K,因此,伙伴算法最多一次能够分配4M的内存空间。

伙伴算法在内核中通常用free_area结构体表示,free_list链表数组,nr_free就是当前链表中空闲页框块数量。例:free_area[2]中nr_free值为3,就是3个大小为4的页框块(16kb),总的空闲页就是3*4=12个(48kb)
#define MAX_ORDER 11
struct free_area {//链表struct list_head free_list[MIGRATE_TYPES];//页属性unsigned long nr_free;//空闲页框块数目
};
#define MAX_ORDER 11
struct zone{struct free_area freearea[MAX_ORDER];
};
内存申请
举例:需要分配16k的内存空间,算法会先从free_area[2]中查看nr_free是否为空,如果有空闲块,则从中分配,如果没有空闲块,就从它的上一级free_area[3](每块32K)中分配出16K,并将多余的内存(16K)加入到free_area[2]中去。如果free_area[3]也没有空闲,则从更上一级申请空间,依次递推,直到free_area[max_order],如果顶级都没有空间,那么就报告分配失败。
“伙伴关系”定义:
所谓“伙伴”,就是指在空闲块被分裂时,由同一个大块内存分裂出来的两个小块内存就互称“伙伴”。“伙伴”应当满足以下三个条件:
- 两个块大小相同
- 两个块地址连续
- 两个块必须是同一个大块中分离出来的
如何判断是同一块大块内存分配出来的?
具体的操作步骤如下:
-
确定块大小:假设块大小为 2^k。
-
检查地址对齐:分别计算内存块 A 和 B 的起始地址对 2^k的对齐情况。
-
计算父节点地址:
- 设两个内存块地址分别为 A 和 B,计算父节点地址。
- 父节点地址为 min(A,B)向下取整到2^(k+1) 的倍数。
-
验证共同父节点:
- 如果计算出的父节点地址相同,则 A 和 B 是“伙伴”。
内存回收
回收是申请的逆过程,当释放一个内存块时,先在其对于的free_area链表中查找是否有伙伴存在,如果没有伙伴块,直接将释放的块插入链表头。如果有或板块的存在,则将其从链表摘下,合并成一个大块,然后继续查找合并后的块在更大一级链表中是否有伙伴的存在,直至不能合并或者已经合并至最大块2^10为止。
接口函数源码分析
内存分配接口
伙伴系统特点:分配的物理内存全部都是在物理内存上连续,分配的是2的整数幂的页,这个幂在内核中称为分配阶(如果指定分配阶为order,那么就会向伙伴系统申请2的order次幂个物理内存页)
- alloc_pages
struct page *alloc_pages(gfp_t gfp, unsigned int order);
-
输入参数:alloc_pages 函数用于分配 2 的 order 次幂个物理内存页,参数 gfp_t gfp 是内核中定义的一个用于规范物理内存分配行为的修饰符,这里我们先不展开。
-
返回值: struct page 类型的指针用于指向申请的内存块中第一个物理内存页。当系统中空闲的物理内存无法满足内存分配时,就会导致内存分配失败,alloc_pages,alloc_page 就会返回空指针 NULL 。
alloc_pages 函数用于分配多个连续的物理内存页,在内核的某些内存分配场景中有时候并不需要分配这么多的连续内存页,而是只需要分配一个物理内存页即可,于是内核又提供了 alloc_page 宏,用于这种单内存页分配的场景,我们可以看到其底层还是依赖了 alloc_pages 函数,只不过 order 指定为 0。
该宏alloc_page的定义:
#define alloc_page(gfp_mask) alloc_pages(gfp_mask, 0)
- __get_free_pages
该函数返回的是物理内存页的虚拟内存地址
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order);
__get_free_pages 函数在使用方式上和 alloc_pages 是一样的,函数参数的含义也是一样,只不过一个是返回物理内存页的虚拟内存地址,一个是直接返回物理内存页。
其实 __get_free_pages 函数的底层也是基于 alloc_pages 实现的,只不过多了一层虚拟地址转换的工作。
unsigned long __get_free_pages(gfp_t gfp_mask, unsigned int order)
{struct page *page;// 不能在高端内存中分配物理页,因为无法直接映射获取虚拟内存地址page = alloc_pages(gfp_mask & ~__GFP_HIGHMEM, order);if (!page)return 0;// 将直接映射区中的物理内存页转换为虚拟内存地址return (unsigned long) page_address(page);
}
page_address 函数用于将给定的物理内存页 page 转换为它的虚拟内存地址,不过这里只适用于内核虚拟内存空间中的直接映射区,因为在直接映射区中虚拟内存地址到物理内存地址是直接映射的,虚拟内存地址减去一个固定的偏移就可以直接得到物理内存地址。
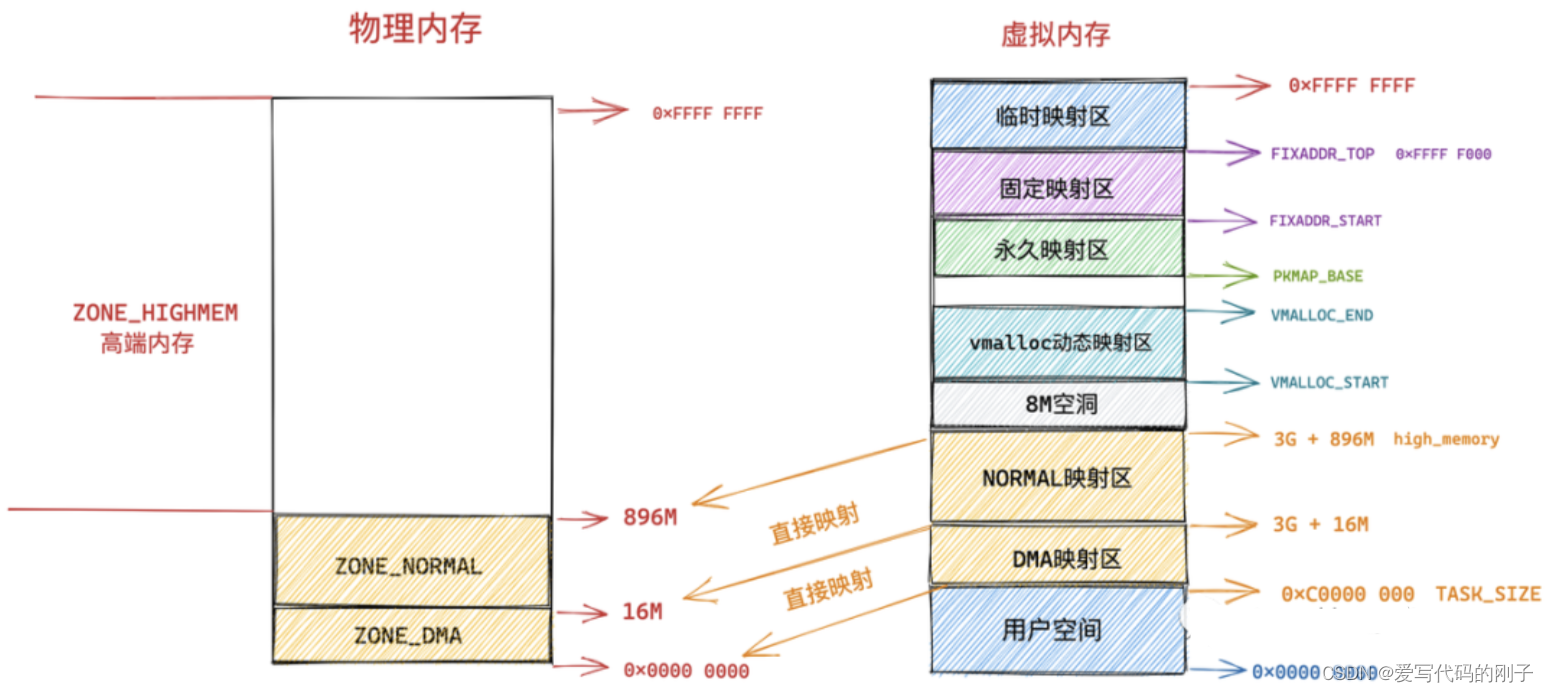
如果物理内存页处于高端内存中,则不能这样直接进行转换,在通过 alloc_pages 函数获取物理内存页 page 之后,需要调用 kmap 映射将 page 映射到内核虚拟地址空间中。
- get_zeroed_page
无论是 alloc_pages 也好还是 __get_free_pages 也好,它们申请到的内存页中包含的数据在一开始都不是空白的,而是内核随机产生的一些垃圾信息,但其实这些信息可能并不都是完全随机的,很有可能随机的包含一些敏感的信息。
这些敏感的信息可能会被一些黑客所利用,并对计算机系统产生一些危害行为,所以从使用安全的角度考虑,内核又提供了一个函数 get_zeroed_page,顾名思义,这个函数会将从伙伴系统中申请到内存页全部初始化填充为 0 ,这在分配物理内存页给用户空间使用的时候非常有用。
unsigned long get_zeroed_page(gfp_t gfp_mask)
{return __get_free_pages(gfp_mask | __GFP_ZERO, 0);
}get_zeroed_page 函数底层也依赖于 __get_free_pages,指定的分配阶 order 也是 0,表示从伙伴系统中只申请一个物理内存页并初始化填充 0 。
- __get_dma_pages
专门用于从 DMA 内存区域分配适用于 DMA 的物理内存页。其底层也是依赖于 __get_free_pages 函数。
unsigned long __get_dma_pages(gfp_t gfp_mask, unsigned int order);
物理内存释放接口
void __free_pages(struct page *page, unsigned int order);
void free_pages(unsigned long addr, unsigned int order);#define __free_page(page) __free_pages((page), 0)
#define free_page(addr) free_pages((addr), 0)
- __free_pages
同 alloc_pages 函数对应,用于释放一个或者 2 的 order 次幂个内存页,释放的物理内存区域起始地址由该区域中的第一个 page 实例指针表示,也就是参数里的 struct page *page 指针。
- free_pages
同__get_free_pages 函数对应,与 __free_pages 函数的区别是在释放物理内存时,使用了虚拟内存地址而不是 page 指针。

规范物理内存分配行为的掩码 gfp_mask(了解即可)
gfp是get free page的缩写,这个参数由3种flag组成,分别为action modifier, zone modifier,type。
参考的文章
这篇关于【Linux内核】伙伴系统算法和slab分配器(1)的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!









