本文主要是介绍第二章:huggingface的TrainingArguments与Trainner参数,希望对大家解决编程问题提供一定的参考价值,需要的开发者们随着小编来一起学习吧!
文章目录
- 前言
- 一、TrainingArguments类参数说明
- 1、TrainingArguments使用Demo
- 2、TrainingArguments参数内容与意义
- 3、TrainingArguments参数图示
- 二、Trainer类的参数说明
- 1、Trainer类使用Demo
- 2、Trainer类的初始化参数
- 3、参数内容与意义
- 4、部分参数属性说明
- 总结
前言
大模型基本使用huggingface来实现。对于不太理解其内容基本按照官网教程或相关博客等来实现。想进一步激发开源大模型在行业领域提升性能是棘手问题。该问题会涉及开源代码二次开发进行实验测试。基于此,本教程不同文字或理论介绍内容,而从源码解读其训练逻辑、权重保存、高效微调方法(LoRA)、断点续训方法、模型推理权重处理等方法。本教程所有内容完全依托huggingface源码与相关Demo验证来解读,助力大模型使用。
本篇文章说明huggingface训练参数TrainingArguments与模型Trainner参数。
一、TrainingArguments类参数说明
TrainingArguments是我们huggingfacfe创建Traner类中args的参数,用于控制模型训练等,这个TrainingArguments包含很多参数。我将在本节详细给出。
1、TrainingArguments使用Demo
通过TrainingArguments类给参数,在后期将training_args给到huggingface的Trainer类self.args中。如下使用:
training_args = TrainingArguments("simple-text-classification", # output_dir="simple-text-classification"也可以这样格式,就是输出文件夹evaluation_strategy="epoch",per_device_train_batch_size=8,per_device_eval_batch_size=8,num_train_epochs=3,logging_dir="./logs",logging_steps=100,save_steps=1000,save_total_limit=2,)
需要说明,simple-text-classification这个是输出文件夹路径,可直接给字符串,也可output_dir="simple-text-classification"使用。
2、TrainingArguments参数内容与意义
我将给出TrainingArguments所有参数内容与意义,也给出对应默认值,一般而言很多参数是不需要设置,使用默认即可。
1、output_dir (str): 模型预测和权重将被写入的输出目录。
2、overwrite_output_dir (bool, 可选, 默认为 False): 如果为 True,则覆盖输出目录的内容(重新写)。使用此选项继续训练,前提是 output_dir参数指向权重目录。
3、do_train (bool, 可选, 默认为 False): 是否进行训练。这个参数不会直接被[Trainer]使用,而是用于您的训练/评估脚本。详情请参阅示例脚本。
4、do_eval (bool, 可选): 是否在验证集上运行评估。如果 evaluation_strategy 与 "no" 不同,则设置为 True。这个参数不会直接被[Trainer]使用,而是用于您的训练/评估脚本。详情请参阅示例脚本。
5、do_predict (bool, 可选, 默认为 False): 是否在测试集上进行预测。这个参数不会直接被[Trainer]使用,而是用于您的训练/评估脚本。详情请参阅示例脚本。
6、evaluation_strategy (str 或 [~trainer_utils.IntervalStrategy], 可选, 默认为 "no"): 在训练期间采用的评估策略。可能的值为:
- "no": 在训练期间不进行评估。
- "steps": 每 eval_steps 进行一次评估(并记录)。
- "epoch": 每个epoch结束时进行一次评估。
7、prediction_loss_only (bool, 可选, 默认为 False): 在执行评估和生成预测时,仅返回损失。
8、per_device_train_batch_size (int, 可选, 默认为 8): 每个GPU/TPU核心/CPU的训练批次大小。
9、per_device_eval_batch_size (int, 可选, 默认为 8): 每个GPU/TPU核心/CPU的评估批次大小。
10、gradient_accumulation_steps (int, 可选, 默认为 1): 在执行反向传播/更新传播之前,累积梯度的更新步数。当使用梯度累积时,一次被计算为一次带有反向传播的步骤。因此,每gradient_accumulation_steps * xxx_step训练样本,将进行一次日志记录、评估、保存。
11、eval_accumulation_steps (int, 可选): 在将结果移动到CPU之前,累积输出张量的预测步数。如果未设置,将在GPU/TPU上累积所有预测结果,然后将其移动到CPU(速度更快,但需要更多内存)。
12、eval_delay (float, 可选): 经过多少steps或epoch的轮数进行第一次评估,取决于上面评估策略。
13、learning_rate (float, 可选, 默认为 5e-5): [AdamW]优化器的初始学习率。
14、weight_decay (float, 可选, 默认为 0): 应用的权重衰减(如果不为零)到所有层,除了[AdamW]优化器中的所有偏置和LayerNorm权重。
15、adam_beta1 (float, 可选, 默认为 0.9): [AdamW]优化器的beta1超参数。
16、adam_beta2 (float, 可选, 默认为 0.999): [AdamW]优化器的beta2超参数。
17、adam_epsilon (float, 可选, 默认为 1e-8): [AdamW]优化器的epsilon超参数。
18、max_grad_norm (float, 可选, 默认为 1.0): 最大梯度范数(用于梯度裁剪)。
19、num_train_epochs(float, 可选, 默认为 3.0): 执行的总训练时期数(如果不是整数,则在停止训练之前执行最后一个epoch的小数部分百分比)。我的理解如果是3.2就应该是3.0停止。
20、max_steps (int, 可选, 默认为 -1): 如果设置为正数,则执行的总训练步数。覆盖num_train_epochs。在使用有限可迭代数据集时,当所有数据用尽时,训练可能会在达到设置的步数之前停止。
21、lr_scheduler_type (str 或 [SchedulerType], 可选, 默认为 "linear"): 要使用的调度器类型。有关所有可能值,请参阅[SchedulerType]的文档。
22、warmup_ratio (float, 可选, 默认为 0.0): 用于从 0 到 learning_rate 进行线性预热的总训练步数的比率。
23、warmup_steps (int, 可选, 默认为 0): 用于从 0 到 learning_rate 进行线性预热的步数。覆盖warmup_ratio的任何效果。
24、log_level (str, 可选, 默认为 passive): 主进程上要使用的日志记录器日志级别。可能的选择是字符串形式的日志级别:‘debug’、‘info’、‘warning’、‘error’ 和 ‘critical’,以及一个 ‘passive’ 级别,它不设置任何内容并保留 Transformers 库的当前日志级别(默认为 "warning")。
25、log_level_replica (str, 可选, 默认为 "warning"): 在副本上要使用的日志记录器日志级别。与 log_level 相同的选择。
26、log_on_each_node (bool, 可选, 默认为 True): 在多节点分布式训练中,是否对每个节点使用 log_level 进行日志记录,还是仅在主节点上记录。
27、logging_dir (str, 可选): TensorBoard 日志目录。默认为 output_dir/runs/CURRENT_DATETIME_HOSTNAME。
28、logging_strategy (str 或 [~trainer_utils.IntervalStrategy], 可选, 默认为 "steps"): 训练期间采用的日志记录策略。可能的值包括:
- "no": 训练期间不进行日志记录。
- "epoch": 每个时代结束时进行日志记录。
- "steps": 每 logging_steps 进行一次日志记录。
29、logging_first_step (bool, 可选, 默认为 False): 是否记录和评估第一个 global_step。
30、logging_steps (int 或 float, 可选, 默认为 500): 如果 logging_strategy="steps",则两个日志记录之间的更新步骤数。应为介于 [0,1) 的整数或浮点数。如果小于 1,则将其解释为总训练步数的比率。
31、logging_nan_inf_filter (bool, 可选, 默认为 True): 是否过滤日志记录中的 nan 和 inf 损失值。如果设置为 True,则将过滤每一步的损失值,如果为 nan 或 inf,则取当前日志记录窗口的平均损失值代替。 logging_nan_inf_filter 仅影响损失值的日志记录,不会改变梯度计算或应用于模型的行为。
32、save_strategy (str 或 [~trainer_utils.IntervalStrategy], 可选, 默认为 "steps"): 训练期间采用权重的保存策略。可能的值包括:
- "no": 训练期间不进行保存。
- "epoch": 每个时代结束时进行保存。
- "steps": 每 save_steps 进行一次保存。
33、save_steps (int 或 float, 可选, 默认为 500): 如果 save_strategy="steps",则两个权重保存间隔保存迭代数为steps。应为整数或浮点数,但浮点数介于 [0,1)范围。如果小于 1,则将其解释为总训练步数的比率。
34、save_total_limit (int, 可选): 如果传递了一个值,将限制权重总数量。将会删除 output_dir 中较旧的权重。当启用 load_best_model_at_end 时,将始终保留“最佳”权重(根据 metric_for_best_model)以及最近的权重。例如,对于 save_total_limit=5 和 load_best_model_at_end,将始终保留四个最后的权重以及最佳模型。当 save_total_limit=1 和 load_best_model_at_end 时,有可能保存两个权重:最后一个和最佳的(如果它们不同)。
35、save_safetensors (bool, 可选, 默认为 False): 对状态字典使用safetensors保存和加载,而不是默认的 torch.load 和 torch.save。
36、save_on_each_node (bool, 可选, 默认为 False): 在进行多节点分布式训练时,是否在每个节点上保存模型和权重,还是仅在主节点上保存。当不同节点使用相同的存储时,不应该激活此选项,因为文件将以相同的名称保存在每个节点上。
37、no_cuda (bool, 可选, 默认为 False): 即使可用,是否不使用 CUDA。
seed (int, 可选, 默认为 42): 在训练开始时设置的随机种子。为了确保在多次运行中的可重现性,请使用[~Trainer.model_init]函数来实例化模型,如果模型有一些随机初始化的参数。
38、data_seed (int, 可选): 用于数据采样器的随机种子。如果未设置,数据采样器的随机生成器将使用与 seed 相同的种子。这可用于确保数据采样的可重现性,与模型种子无关。
39、jit_mode_eval (bool, 可选, 默认为 False): 是否使用 PyTorch jit trace 进行推断。
40、use_ipex (bool, 可选, 默认为 False): 当可用时,是否使用 Intel PyTorch 扩展。IPEX 安装。
41、bf16 (bool, 可选, 默认为 False): 是否使用 bf16 16 位(混合)精度训练,而不是 32 位训练。需要安培或更高的 NVIDIA 架构或使用 CPU(no_cuda)。这是一个实验性的 API,它可能会改变。
42、fp16 (bool, 可选, 默认为 False): 是否使用 fp16 16 位(混合)精度训练,而不是 32 位训练。
43、fp16_opt_level (str, 可选, 默认为 ‘O1’): 对于 fp16 训练,选择的 Apex AMP 优化级别为 [‘O0’, ‘O1’, ‘O2’, 和 ‘O3’]。详细信息请参阅 Apex 文档。
44、fp16_backend (str, 可选, 默认为 "auto"): 此参数已弃用。请改用 half_precision_backend。
45、half_precision_backend (str, 可选, 默认为 "auto"): 用于混合精度训练的后端。必须是 "auto"、"cuda_amp"、"apex"、"cpu_amp" 中的一个。"auto" 将根据检测到的 PyTorch 版本使用 CPU/CUDA AMP 或 APEX,而其他选择将强制使用请求的后端。
46、bf16_full_eval (bool, 可选, 默认为 False): 是否使用完整的 bfloat16 评估,而不是 32 位。这将更快,节省内存,但可能会损害指标值。这是一个实验性的 API,它可能会改变。
47、fp16_full_eval (bool, 可选, 默认为 False): 是否使用完整的 float16 评估,而不是 32 位。这将更快,节省内存,但可能会损害指标值。
48、tf32 (bool, 可选): 是否启用 TF32 模式,在安培和更新的 GPU 架构中可用。默认值取决于 PyTorch 的版本,默认为 torch.backends.cuda.matmul.allow_tf32。有关更多详细信息,请参阅 TF32 文档。这是一个实验性的 API,它可能会改变。
49、local_rank (int, 可选, 默认为 -1): 分布式训练中进程的排名。
50、ddp_backend (str, 可选): 用于分布式训练的后端。必须是 "nccl"、"mpi"、"ccl"、"gloo" 中的一个。
51、tpu_num_cores (int, 可选): 在 TPU 上训练时,TPU 核心的数量(由启动脚本自动传递)。
52、dataloader_drop_last (bool, 可选, 默认为 False): 是否丢弃最后一个不完整的批次(如果数据集的长度不可被批次大小整除)。
53、eval_steps (int 或 float, 可选): 如果 evaluation_strategy="steps",则两次评估之间的更新步数。如果未设置,则默认为与 logging_steps 相同的值。应为介于 [0,1) 的整数或浮点数。如果小于 1,则将其解释为总训练步数的比率。
54、dataloader_num_workers (int, 可选, 默认为 0): 用于数据加载的子进程数量(仅限于 PyTorch)。0 表示数据将在主进程中加载。
55、past_index (int, 可选, 默认为 -1): 一些模型,如 TransformerXL 或 XLNet,可以利用过去的隐藏状态进行预测。如果此参数设置为正整数,则 Trainer 将使用相应的输出(通常为索引 2)作为过去状态,并在下一个训练步骤中将其作为关键字参数 mems 提供给模型。
56、run_name (str, 可选): 运行的描述符。通常用于 wandb 和 mlflow 日志记录。
57、disable_tqdm (bool, 可选): 是否禁用 Jupyter Notebook 中由 [~notebook.NotebookTrainingTracker] 产生的 tqdm 进度条和指标表。如果日志级别设置为 warn 或更低(默认为 True),则默认为 True;否则为 False。
58、remove_unused_columns (bool, 可选, 默认为 True): 是否自动删除模型前向方法未使用的列。
(注意,此行为尚未对 [TFTrainer] 实现。)
59、label_names (List[str], 可选): 您输入字典中与标签对应的键列表。
最终将默认为模型接受的参数名称列表,其中包含单词 “label”,除非使用的模型是 XxxForQuestionAnswering 中的一个,此时还将包括 ["start_positions", "end_positions"] 键。
60、load_best_model_at_end (bool, 可选, 默认为 False): 是否在训练结束时加载训练期间找到的最佳模型。当启用此选项时,最佳检查点将始终被保存。更多信息请参见 save_total_limit。 当设置为 True 时,参数 save_strategy 需要与 evaluation_strategy 相同,并且在情况下为 “steps”,save_steps 必须是 eval_steps 的整数倍。
61、metric_for_best_model (str, 可选): 与 load_best_model_at_end 结合使用,指定用于比较两个不同模型的指标。必须是评估返回的指标的名称,可以包含或不包含前缀 "eval_"。如果未指定且 load_best_model_at_end=True(使用评估损失),将默认为 "loss"。 如果设置了此值,则 greater_is_better 将默认为 True。如果您的指标在较低时更好,请不要忘记将其设置为 False。
62、greater_is_better (bool, 可选): 与 load_best_model_at_end 和 metric_for_best_model 结合使用,指定更好的模型是否应具有更大的指标。将默认为:
- 如果 metric_for_best_model 设置为不是 "loss" 或 "eval_loss" 的值,则为 True。
- 如果未设置 metric_for_best_model,或设置为 "loss" 或 "eval_loss",则为 False。
63、ignore_data_skip (bool, 可选, 默认为 False): 在恢复训练时,是否跳过周期和批次以使数据加载与上一次训练的相同阶段。如果设置为 True,训练将更快地开始(因为跳过步骤可能需要很长时间),但结果将不与中断的训练产生相同的结果。
64、sharded_ddp (bool, str 或列表[~trainer_utils.ShardedDDPOption], 可选, 默认为 False): 在分布式训练中使用来自 FairScale 的 Sharded DDP 训练(仅在分布式训练中)。这是一个实验性功能。 沿以下选项列表:
- "simple": 使用 fairscale 发布的 Sharded DDP 的第一个实例(类似于 ZeRO-2)。
- "zero_dp_2": 使用 fairscale 发布的 Sharded DPP 的第二个实例(FullyShardedDDP),处于 Zero-2 模式(reshard_after_forward=False)。
- "zero_dp_3": 使用 fairscale 发布的 Sharded DPP 的第二个实例(FullyShardedDDP),处于 Zero-3 模式(reshard_after_forward=True)。
- "offload": 添加 ZeRO-offload(仅与 "zero_dp_2" 和 "zero_dp_3" 兼容)。
如果传递了一个字符串,它将被空格分隔。如果传递了一个布尔值,它将被转换为一个空列表,对于 True,它将被转换为 ["simple"]。
65、fsdp (bool, str 或列表[~trainer_utils.FSDPOption], 可选, 默认为 False): 使用 PyTorch 分布式并行训练(仅限分布式训练)。沿以下选项列表:
- "full_shard": 分片参数,梯度和优化器状态。
- "shard_grad_op": 分片优化器状态和梯度。
- "offload": 将参数和梯度卸载到 CPU(仅与 "full_shard" 和 "shard_grad_op" 兼容)。
- "auto_wrap": 使用 default_auto_wrap_policy 自动递归包装层与 FSDP。
66、fsdp_config (str 或 dict, 可选): 用于 fsdp(PyTorch 分布式并行训练)的配置。值可以是深度速度 json 配置文件的位置(例如,ds_config.json),也可以是已加载的 json 文件作为 dict。 配置和其选项列表:
- fsdp_min_num_params (int, 可选, 默认为 0): 默认自动包装的 FSDP 参数的最小数量。 (仅当传递了 fsdp 字段时有用)
- fsdp_transformer_layer_cls_to_wrap (List[str], 可选): 要包装的 transformer 层类名列表(区分大小写),例如 BertLayer、GPTJBlock、T5Block … (仅当传递了 fsdp 标志时有用)
- fsdp_backward_prefetch (str, 可选): FSDP 的向后预取模式。控制何时预取下一组参数(仅当传递了 fsdp 字段时有用)。 沿以下选项列表:
- "backward_pre": 在当前参数的梯度计算之前预取下一组参数。
- "backward_post": 在当前参数的梯度计算之后预取下一组参数。
- fsdp_forward_prefetch (bool, 可选, 默认为 False): FSDP 的前向预取模式 (仅当传递了 fsdp 字段时有用)。 如果为 "True",则 FSDP 在前向传递执行中显式预取下一个即将到来的 all-gather。
- limit_all_gathers (bool, optional, defaults to False): FSDP 的 limit_all_gathers(仅在传递了 fsdp 字段时有用)。 如果为 "True",FSDP 明确同步 CPU 线程,以防止太多的在途 all-gathers。
- xla (bool, optional, defaults to False): 是否使用 PyTorch/XLA 完全分片的数据并行训练。这是一个实验性功能,其 API 可能在未来发生变化。
- xla_fsdp_settings (dict, optional): 这个值是一个存储 XLA FSDP 包装参数的字典。 有关所有选项的完整列表,请参阅这里。
- xla_fsdp_grad_ckpt (bool, optional, defaults to False): 将在每个嵌套的 XLA FSDP 包装层上使用梯度检查点。此设置仅在将 xla 标志设置为 true,并通过 fsdp_min_num_params 或 fsdp_transformer_layer_cls_to_wrap 指定自动包装策略时才能使用。
67、deepspeed (str 或 dict, 可选, 默认为 None): 使用 Deepspeed。这是一个实验性功能,其 API 可能会在未来发生变化。该值可以是 DeepSpeed 的 JSON 配置文件的路径(例如 ds_config.json),也可以是已加载的 JSON 文件作为字典。
68、label_smoothing_factor (float, 可选, 默认为 0.0): 使用的标签平滑因子。零表示不进行标签平滑,否则基础的 one-hot 编码标签将从 0 和 1 更改为 label_smoothing_factor/num_labels 和 1 - label_smoothing_factor + label_smoothing_factor/num_labels。
69、debug (str 或 [~debug_utils.DebugOption] 的列表, 可选, 默认为 ""): 启用一个或多个调试特性。这是一个实验性功能。 可能的选项有:
- "underflow_overflow": 检测模型输入/输出中的溢出,并报告导致该事件的最后帧。
- "tpu_metrics_debug": 在 TPU 上打印调试指标。
选项应该由空格分隔。
70、optim (str 或 [training_args.OptimizerNames], 可选, 默认为 "adamw_hf"): 要使用的优化器:adamw_hf、adamw_torch、adamw_torch_fused、adamw_apex_fused、adamw_anyprecision 或 adafactor。
71、optim_args (str, 可选): 提供给 AnyPrecisionAdamW 的可选参数。
72、group_by_length (bool, 可选, 默认为 False): 是否将训练数据集中长度大致相同的样本分组在一起(以最小化应用的填充并提高效率)。仅在应用动态填充时有用。
73、length_column_name (str, 可选, 默认为 "length"): 预计算长度的列名称。如果存在该列,则根据长度进行分组将使用这些值,而不是在训练启动时计算它们。除非 group_by_length 是 True,并且数据集是 Dataset 的实例,否则将被忽略。
74、report_to (str 或 List[str], 可选, 默认为 "all"): 报告结果和日志的集成列表。支持的平台有 "azure_ml"、"comet_ml"、"mlflow"、"neptune"、"tensorboard"、"clearml" 和 "wandb"。使用 "all" 表示报告到所有安装的集成,使用 "none" 表示不报告到任何集成。
75、ddp_find_unused_parameters (bool, 可选): 在使用分布式训练时,传递给 DistributedDataParallel 的 find_unused_parameters 标志的值。如果使用梯度检查点,则默认为 False,否则为 True。
76、ddp_bucket_cap_mb (int, 可选): 在使用分布式训练时,传递给 DistributedDataParallel 的 bucket_cap_mb 标志的值。
77、ddp_broadcast_buffers (bool, 可选): 在使用分布式训练时,传递给 DistributedDataParallel 的 broadcast_buffers 标志的值。如果使用梯度检查点,则默认为 False,否则为 True。
78、dataloader_pin_memory (bool, 可选, 默认为 True): 是否将内存固定在数据加载器中。默认为 True。
79、skip_memory_metrics (bool, 可选, 默认为 True): 是否跳过将内存分析报告添加到指标中。默认情况下会跳过此操作,因为它会减慢训练和评估速度。
80、push_to_hub (bool, 可选, 默认为 False): 是否在每次保存模型时将模型推送到 Hub。如果激活了此选项,则output_dir将开始一个与存储库同步的 git 目录(由 hub_model_id 确定),并且每次触发保存时都会推送内容(取决于您的 save_strategy)。调用 [~Trainer.save_model] 也会触发推送。 如果 output_dir 存在,则它需要是要将 [Trainer] 推送到的存储库的本地克隆。
81、resume_from_checkpoint (str, 可选): 用于您的模型的有效权重文件夹的路径。此参数不是直接由 [Trainer] 使用的,而是由您的训练/评估脚本使用的。有关更多详细信息,请参阅示例脚本。
82、hub_model_id (str, 可选): 用于与本地 output_dir 保持同步的存储库的名称。它可以是一个简单的模型 ID,在这种情况下,模型将被推送到您的命名空间。否则,它应该是整个存储库名称,例如 "user_name/model",这允许您推送到您所属的组织,例如 "organization_name/model"。将默认为 user_name/output_dir_name,其中 output_dir_name 是 output_dir 的名称。 将默认为 output_dir 的名称。
83、hub_strategy (str 或 [~trainer_utils.HubStrategy], 可选, 默认为 "every_save"): 定义推送到 Hub 的内容和时间范围。可能的值包括:
- "end":在调用 [~Trainer.save_model] 方法时推送模型、其配置、分词器(如果传递给 [Trainer])和模型卡片的草稿。
- "every_save":每次保存模型时推送模型、其配置、分词器(如果传递给 [Trainer])和模型卡片的草稿。推送是异步进行的,以避免阻塞训练,如果保存非常频繁,则只有在前一个保存完成后才会尝试新的推送。在训练结束时将使用最终模型进行最后一次推送。
- "checkpoint":类似于 "every_save",但也推送了最新的检查点到名为 last-checkpoint 的子文件夹中,这样您就可以使用 trainer.train(resume_from_checkpoint="last-checkpoint") 轻松恢复训练。
- "all_checkpoints":类似于 "checkpoint",但所有检查点都像它们出现在输出文件夹中一样推送(因此您将在最终存储库中获得每个文件夹的一个检查点文件夹)。
3、TrainingArguments参数图示
尽管上面给出大多数有用参数,但还是有些参数未说明。这里,我将以图方式呈现。当然,后期huggingface迭代可能会增改删某些参数,但架构基本不变。
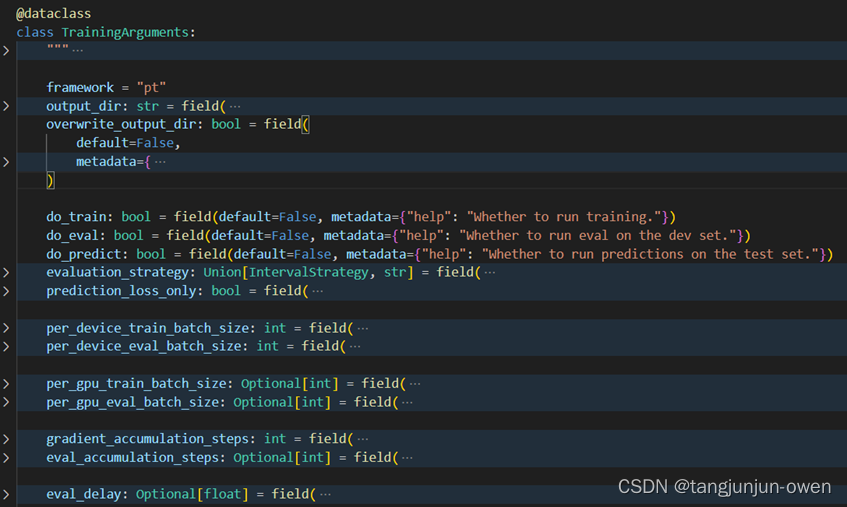
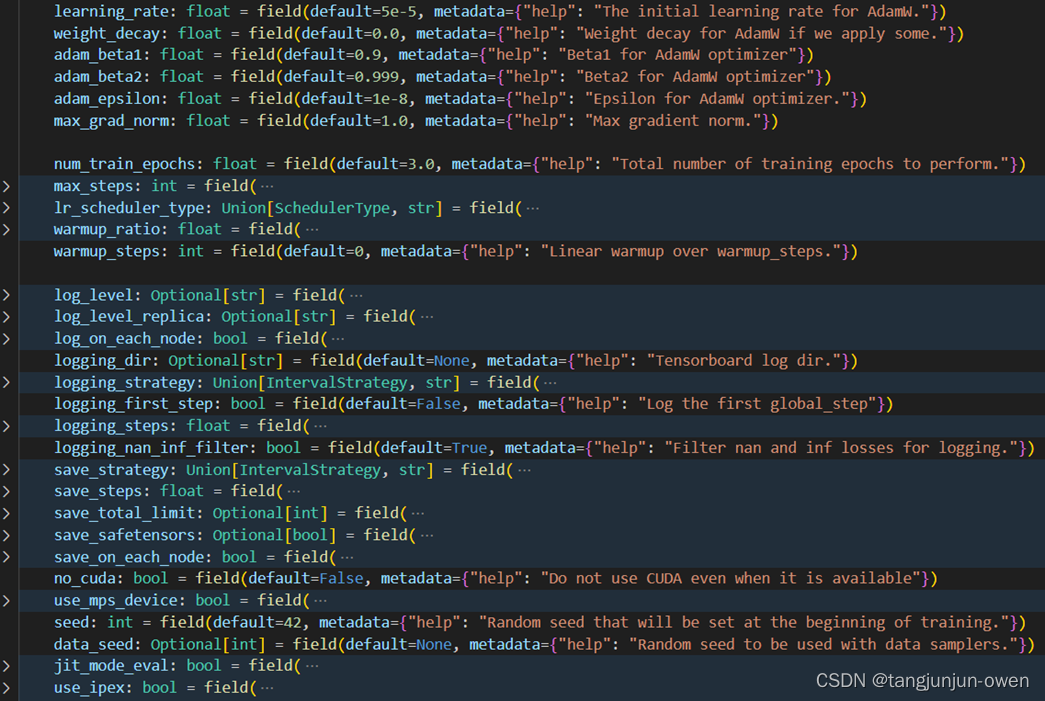
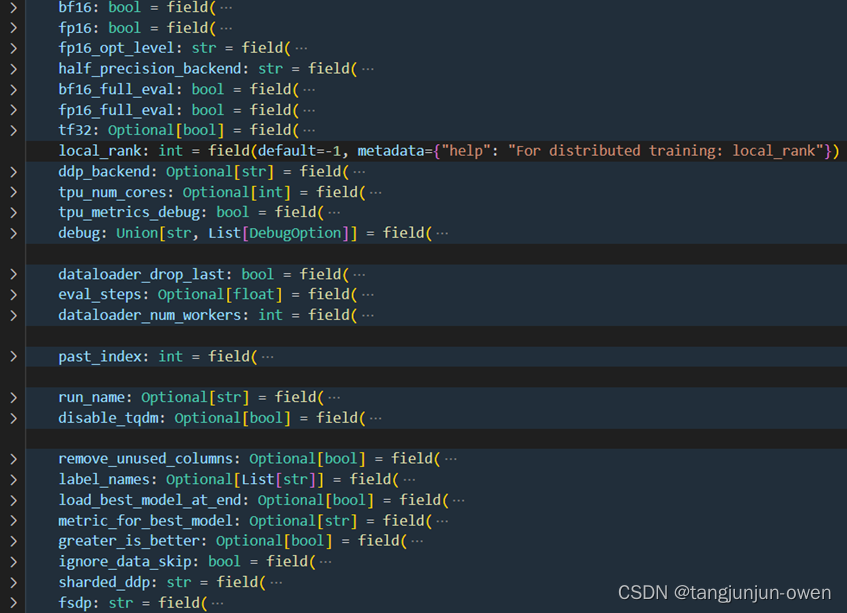
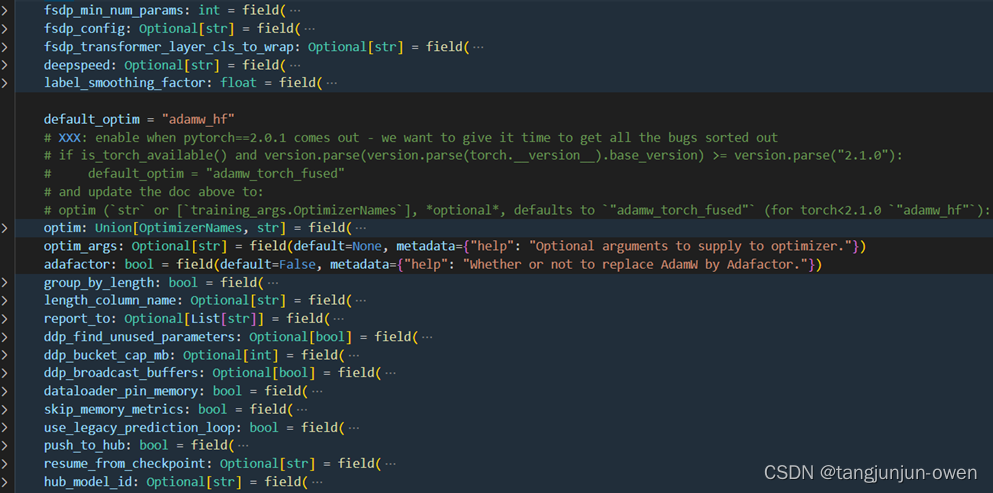
二、Trainer类的参数说明
Trainer是huggingface库用于大模型训练的类,该类涉及很多方法,包含优化器构建、学习策略、权重保存、deepspeed加速等内容。当然,我们也可以继承该类或按照此类方式直接使用,以便后续二次开发我们自己的大模型。这里,我给同学们介绍该类的参数。
1、Trainer类使用Demo
这是一个非常重要的类,很多训练相关方法都被集成在这个类中。我后面文章也会展开详细说明。
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,)
2、Trainer类的初始化参数
这里我们先给出Trainer类的init包含的参数,如下代码:
class Trainer:# Those are used as methods of the Trainer in examples.from .trainer_pt_utils import _get_learning_rate, log_metrics, metrics_format, save_metrics, save_statedef __init__(self,model: Union[PreTrainedModel, nn.Module] = None,args: TrainingArguments = None,data_collator: Optional[DataCollator] = None,train_dataset: Optional[Dataset] = None,eval_dataset: Optional[Union[Dataset, Dict[str, Dataset]]] = None,tokenizer: Optional[PreTrainedTokenizerBase] = None,model_init: Optional[Callable[[], PreTrainedModel]] = None,compute_metrics: Optional[Callable[[EvalPrediction], Dict]] = None,callbacks: Optional[List[TrainerCallback]] = None,optimizers: Tuple[torch.optim.Optimizer, torch.optim.lr_scheduler.LambdaLR] = (None, None),preprocess_logits_for_metrics: Optional[Callable[[torch.Tensor, torch.Tensor], torch.Tensor]] = None,):注:from .trainer_pt_utils import _get_learning_rate, log_metrics, metrics_format, save_metrics, save_state这句代码是导入模型相关默认内容,如训练参数。
3、参数内容与意义
在“2、Trainer类的初始化参数”已知Trainer实列化参数内容,接下来将详细说明。
1、model([PreTrainedModel]或torch.nn.Module,可选): 用于训练、评估或预测的模型。如果未提供,则必须传递model_init。
2、args([TrainingArguments],可选): 用于调整训练的参数。如果未提供,将默认为具有output_dir设置为当前目录中的名为tmp_trainer的目录的基本[TrainingArguments]实例。这个很重要!!
3、data_collator(DataCollator,可选): 从train_dataset或eval_dataset的元素列表形成批次的函数。如果没有提供tokenizer,将默认为[default_data_collator],否则为[DataCollatorWithPadding]的实例。
4、 train_dataset(torch.utils.data.Dataset或torch.utils.data.IterableDataset,可选): 用于训练的数据集。如果是[~datasets.Dataset],则自动删除模型forward()方法不接受的列。
5、eval_dataset(Union[torch.utils.data.Dataset,Dict[str,torch.utils.data.Dataset],可选): 用于评估的数据集。如果是[~datasets.Dataset],则自动删除模型forward()方法不接受的列。如果是字典,则将字典键预置到指标名称之前进行评估。
6、tokenizer([PreTrainedTokenizerBase],可选): 用于预处理数据的分词器。如果提供,将在批量处理输入时自动填充到最大长度,并且将与模型一起保存,以便更轻松地重新运行中断的训练或重用微调的模型。
7、model_init(Callable[[], PreTrainedModel],可选): 一个用于实例化要使用的模型的函数。如果提供,每次调用[~Trainer.train]将从该函数给出的模型的新实例开始。
8、compute_metrics(Callable[[EvalPrediction],Dict],可选): 用于计算评估指标的函数。必须接受[EvalPrediction]并返回一个字符串到指标值的字典。
9、callbacks([TrainerCallback]列表,可选): 用于自定义训练循环的回调列表。将将这些添加到详细介绍[here]的默认回调列表中。
10、optimizers(Tuple[torch.optim.Optimizer,torch.optim.lr_scheduler.LambdaLR],可选): 包含要使用的优化器和调度程序的元组。将默认为[AdamW]在您的模型上一个由[get_linear_schedule_with_warmup]控制的调度程序,由args控制。
11、preprocess_logits_for_metrics(Callable[[torch.Tensor,torch.Tensor],torch.Tensor],可选): 一个用于在每个评估步骤缓存逻辑的预处理逻辑函数。必须接受两个张量,逻辑和标签,并返回一次处理后的逻辑。此函数所做的修改将反映在compute_metrics收到的预测中。
4、部分参数属性说明
1、 model – 始终指向核心模型。如果使用transformers模型,则将是一个[PreTrainedModel]子类。
2、 model_wrapped – 始终指向最外部的模型,如果一个或多个其他模块包装了原始模型。这是应该用于正向传递的模型。例如,在DeepSpeed下,内部模型被包装在DeepSpeed中,然后再次包装在torch.nn.DistributedDataParallel中。如果内部模型未被包装,则self.model_wrapped与self.model相同。
3、 is_model_parallel – 模型是否已切换到模型并行模式(与数据并行性不同,这意味着一些模型层在不同的GPU上分割)。
4、 place_model_on_device – 是否自动将模型放置在设备上 - 如果使用模型并行或深度速度,或者如果默认的TrainingArguments.place_model_on_device被覆盖以返回False,则将设置为False。
5、 is_in_train – 模型当前是否正在运行train(例如,在train中调用evaluate时)。
总结
了解TrainingArguments不同含义或控制哪些模块。
知晓Trainer类实列化相关参数及含义。
TrainingArguments类构建参数是Trainer类实列化的参数,self.args表示。
这篇关于第二章:huggingface的TrainingArguments与Trainner参数的文章就介绍到这儿,希望我们推荐的文章对编程师们有所帮助!


